När vi jobbar inom IT-branschen har vi säkert hört ordet "failover" många gånger, men det kan också väcka frågor som:Vad är egentligen en failover? Vad kan vi använda det till? Är det viktigt att ha det? Hur kan vi göra det?
Även om de kan verka ganska grundläggande frågor, är det viktigt att ta hänsyn till dem i vilken databasmiljö som helst. Och oftare än inte tar vi inte hänsyn till grunderna...
Till att börja med, låt oss titta på några grundläggande begrepp.
Vad är failover?
Failover är förmågan hos ett system att fortsätta fungera även om något fel inträffar. Det antyder att systemets funktioner övertas av sekundära komponenter om de primära komponenterna misslyckas.
När det gäller PostgreSQL finns det olika verktyg som låter dig implementera ett databaskluster som är motståndskraftigt mot fel. En redundansmekanism som är tillgänglig inbyggt i PostgreSQL är replikering. Och nyheten i PostgreSQL 10 är implementeringen av logisk replikering.
Vad är replikering?
Det är processen att kopiera och hålla data uppdaterade i en eller flera databasnoder. Den använder ett koncept med en masternod som tar emot ändringarna och slavnoder där de replikeras.
Vi har flera sätt att kategorisera replikering:
- Synkron replikering:Det sker ingen förlust av data även om vår masternod går förlorad, men commits i mastern måste vänta på en bekräftelse från slaven, vilket kan påverka prestandan.
- Asynkron replikering:Det finns en risk för dataförlust om vi skulle förlora vår huvudnod. Om repliken av någon anledning inte uppdateras vid tidpunkten för incidenten kan informationen som inte har kopierats gå förlorad.
- Fysisk replikering:Diskblock kopieras.
- Logisk replikering:Streaming av dataändringarna.
- Warm Standby-slavar:De stöder inte anslutningar.
- Hot Standby Slaves:Stöd för skrivskyddade anslutningar, användbart för rapporter eller frågor.
Vad används failover till?
Det finns flera möjliga användningsområden för failover. Låt oss se några exempel.
Migrering
Om vi vill migrera från ett datacenter till ett annat genom att minimera vår stilleståndstid kan vi använda failover.
Anta att vår master är i datacenter A och vi vill migrera våra system till datacenter B.
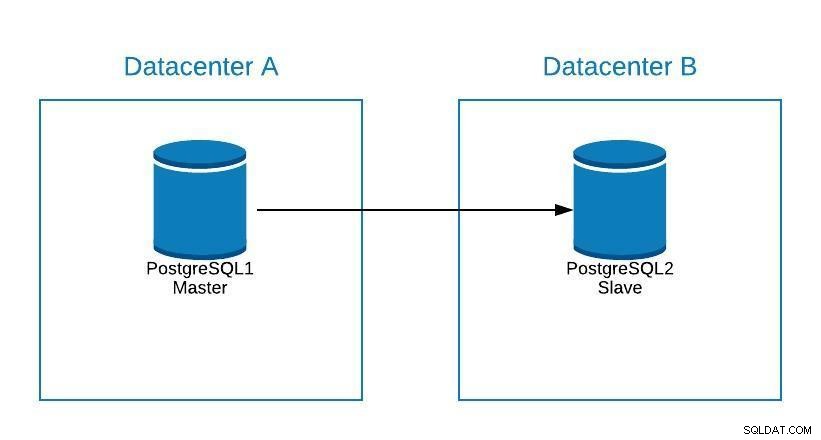 Migreringsdiagram 1
Migreringsdiagram 1 Vi kan skapa en replik i datacenter B. När den väl är synkroniserad måste vi stoppa vårt system, marknadsföra vår replik till ny master och failover, innan vi pekar vårt system mot den nya mastern i datacenter B.
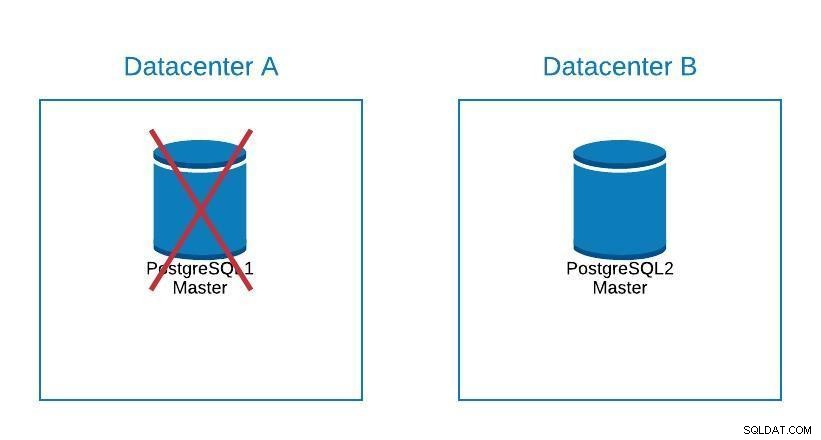 Migreringsdiagram 2
Migreringsdiagram 2 Failover handlar inte bara om databasen, utan också applikationen/applikationerna. Hur vet de vilken databas de ska ansluta till? Vi vill absolut inte behöva modifiera vår applikation, eftersom detta bara kommer att förlänga vår stilleståndstid.. Så, vi kan konfigurera en lastbalanserare så att när vi tar ner vår master så kommer den automatiskt att peka på nästa server som marknadsförs.
Ett annat alternativ är användningen av DNS. Genom att marknadsföra masterrepliken i det nya datacentret ändrar vi direkt IP-adressen för värdnamnet som pekar på mastern. På så sätt slipper vi att behöva modifiera vår applikation, och även om det inte kan göras automatiskt är det ett alternativ om vi inte vill implementera en lastbalanserare.
Att ha en enda lastbalanseringsinstans är inte bra eftersom det kan bli en enda felpunkt. Därför kan du även implementera failover för lastbalanseraren, med hjälp av en tjänst som keepalved. På det här sättet, om vi har problem med vår primära lastbalanserare, är keepalived ansvarig för att migrera IP:n till vår sekundära lastbalanserare, och allt fortsätter att fungera transparent.
Underhåll
Om vi måste utföra något underhåll på vår postgreSQL-masterdatabasserver kan vi marknadsföra vår slav, utföra uppgiften och rekonstruera en slav på vår gamla master.
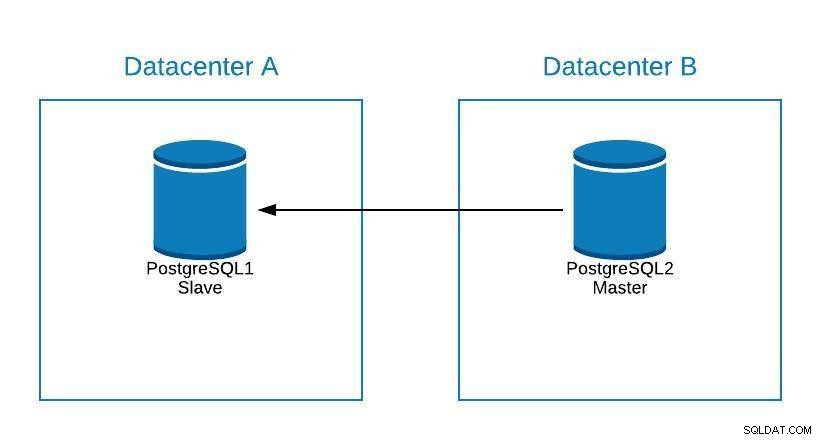 Underhållsdiagram 1
Underhållsdiagram 1 Efter detta kan vi repromovera den gamla mästaren och upprepa rekonstruktionsprocessen för slaven, och återgå till det ursprungliga tillståndet.
Underhållsdiagram 2 På så sätt kunde vi arbeta på vår server utan att riskera att vara offline eller förlora information när vi utför underhåll.
Uppgradera
Även om PostgreSQL 11 inte är tillgänglig ännu, skulle det tekniskt sett vara möjligt att uppgradera från PostgreSQL version 10, med logisk replikering, eftersom det kan göras med andra motorer.
Stegen skulle vara desamma som att migrera till ett nytt datacenter (se migreringsavsnittet), bara att vår slav skulle vara i PostgreSQL 11.
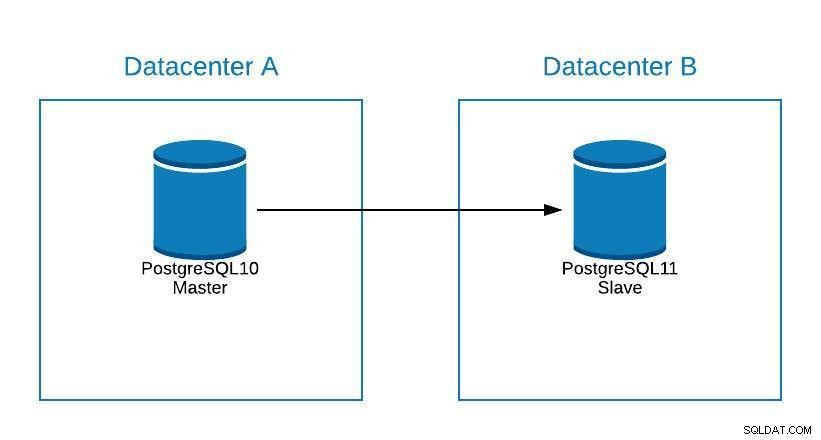 Uppgraderingsdiagram 1
Uppgraderingsdiagram 1 Frågor
Den viktigaste funktionen för failover är att minimera vår stilleståndstid eller undvika förlust av information när vi har problem med vår huvuddatabas.
Om vi av någon anledning förlorar vår huvuddatabas kan vi utföra en failover för att främja vår slav till master och hålla våra system igång.
För att göra detta förser PostgreSQL oss inte med någon automatiserad lösning. Vi kan göra det manuellt, eller automatisera det med hjälp av ett skript eller ett externt verktyg.
För att främja vår slav till mästare:
-
Kör pg_ctl promotion
bash-4.2$ pg_ctl promote -D /var/lib/pgsql/10/data/ waiting for server to promote.... done server promoted - Skapa en fil trigger_fil som vi måste ha lagt till i recovery.conf i vår datakatalog.
bash-4.2$ cat /var/lib/pgsql/10/data/recovery.conf standby_mode = 'on' primary_conninfo = 'application_name=pgsql_node_0 host=postgres1 port=5432 user=replication password=****' recovery_target_timeline = 'latest' trigger_file = '/tmp/failover.trigger' bash-4.2$ touch /tmp/failover.trigger
För att implementera en failover-strategi måste vi planera den och noggrant testa genom olika felscenarier. Eftersom misslyckanden kan hända på olika sätt, och lösningen bör helst fungera för de flesta vanliga scenarierna. Om vi letar efter ett sätt att automatisera detta kan vi ta en titt på vad ClusterControl har att erbjuda.
ClusterControl för PostgreSQL-failover
ClusterControl har ett antal funktioner relaterade till PostgreSQL-replikering och automatiserad failover.
Lägg till slav
Om vi vill lägga till en slav i ett annat datacenter, antingen som en tillfällighet eller för att migrera dina system, kan vi gå till Cluster Actions och välja Lägg till replikeringsslav.
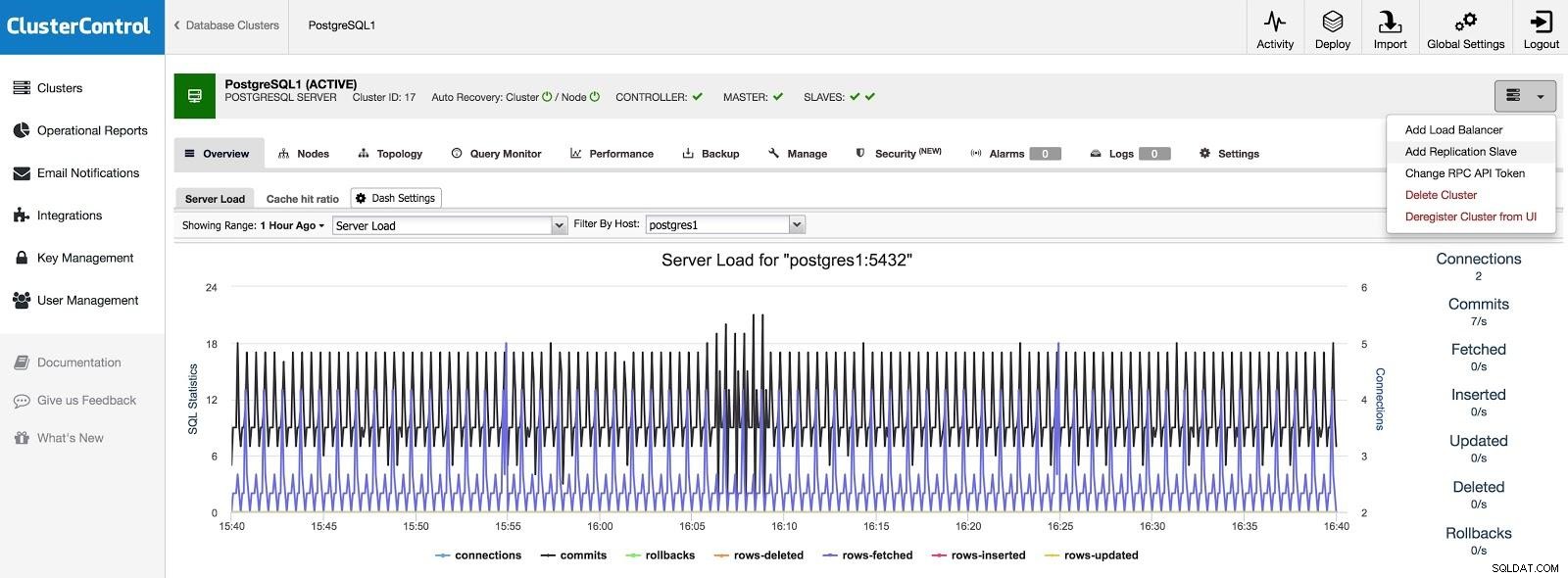 ClusterControl Lägg till slav 1
ClusterControl Lägg till slav 1 Vi måste ange några grundläggande data, såsom IP eller värdnamn, datakatalog (valfritt), synkron eller asynkron slav. Vi borde ha vår slav igång efter några sekunder.
Om du använder ett annat datacenter rekommenderar vi att du skapar en asynkron slav, eftersom latensen annars kan påverka prestandan avsevärt.
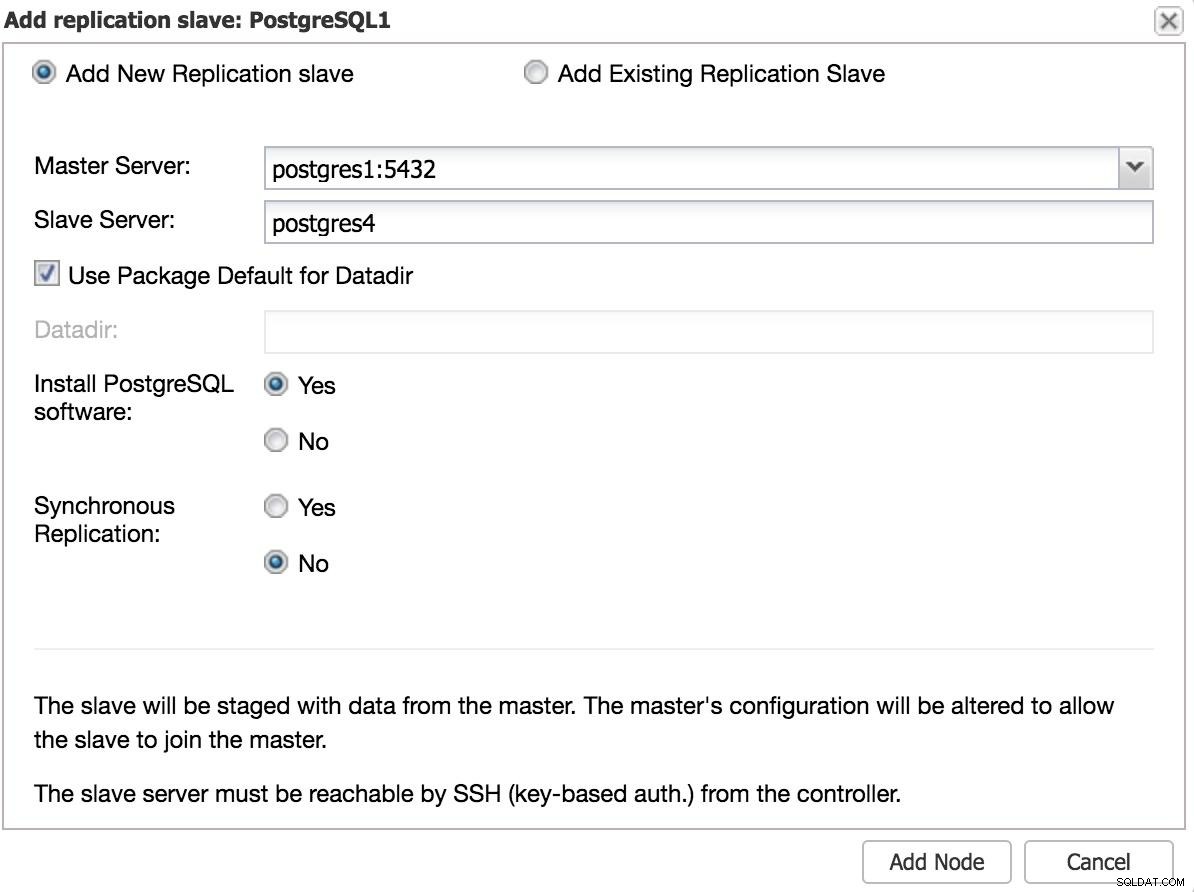 ClusterControl Lägg till slav 2
ClusterControl Lägg till slav 2 Manuell failover
Med ClusterControl kan failover göras manuellt eller automatiskt.
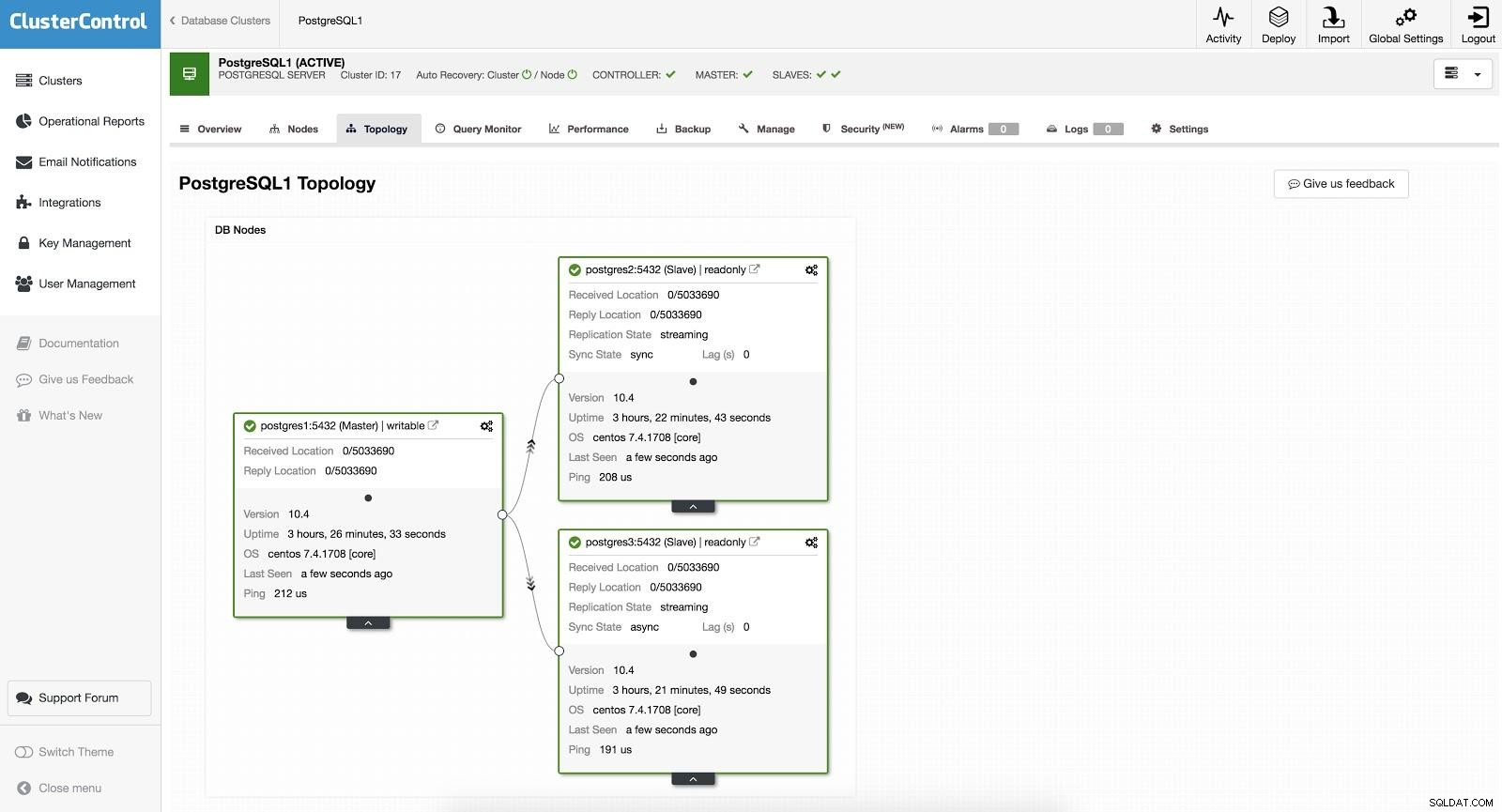 ClusterControl Failover 1
ClusterControl Failover 1 För att utföra en manuell failover, gå till ClusterControl -> Välj Cluster -> Noder, och i Action Node för en av våra slavar, välj "Promote Slave". På detta sätt, efter några sekunder, blir vår slav herre, och det som var vår herre tidigare, förvandlas till en slav.
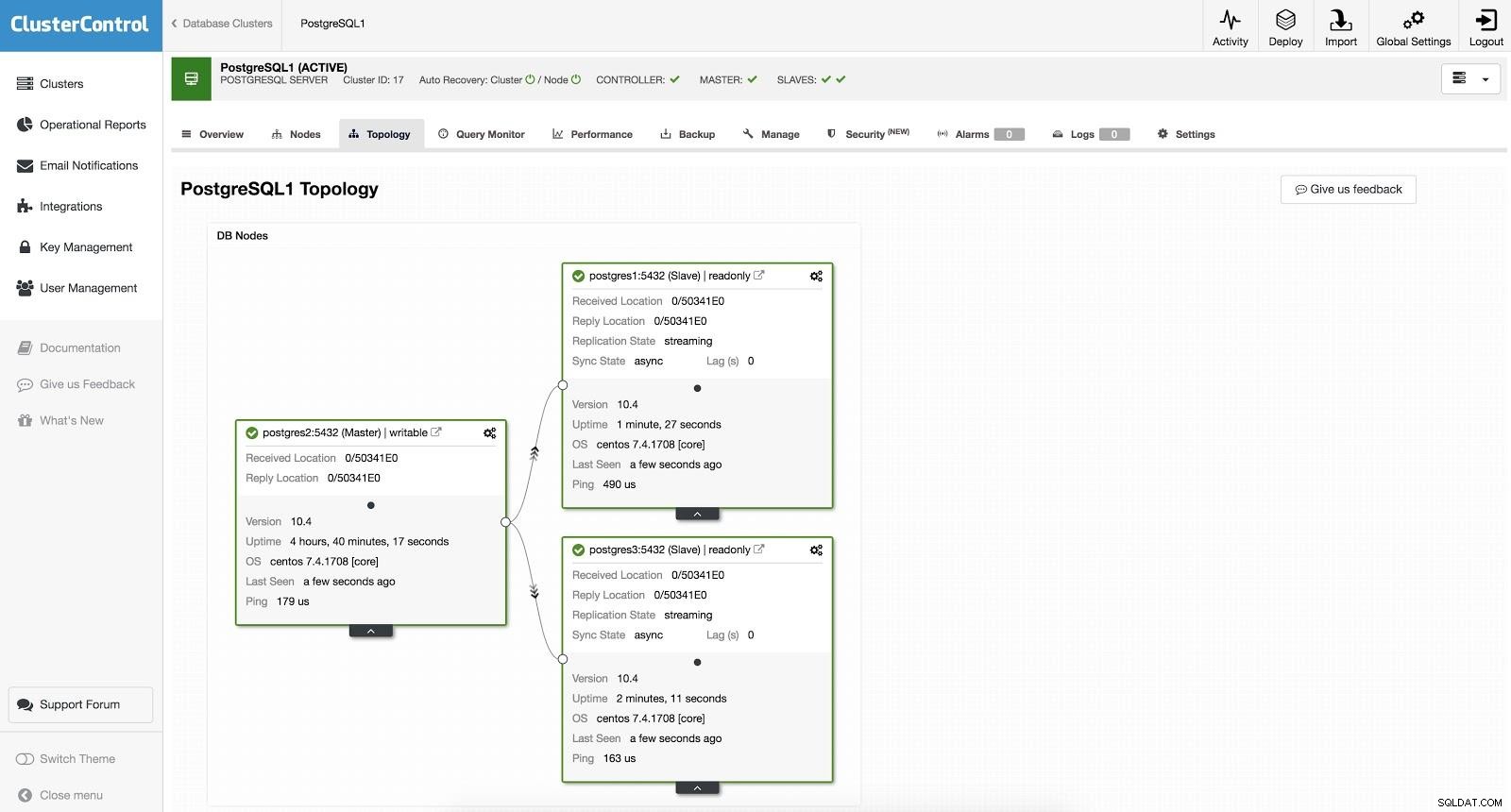 ClusterControl Failover 2
ClusterControl Failover 2 Ovanstående är användbart för uppgifterna migrering, underhåll och uppgraderingar som vi såg tidigare.
Automatisk failover
I fallet med automatisk failover upptäcker ClusterControl fel i mastern och marknadsför en slav med de senaste data som ny master. Det fungerar också på resten av slavarna att få dem att replikera från den nya mastern.
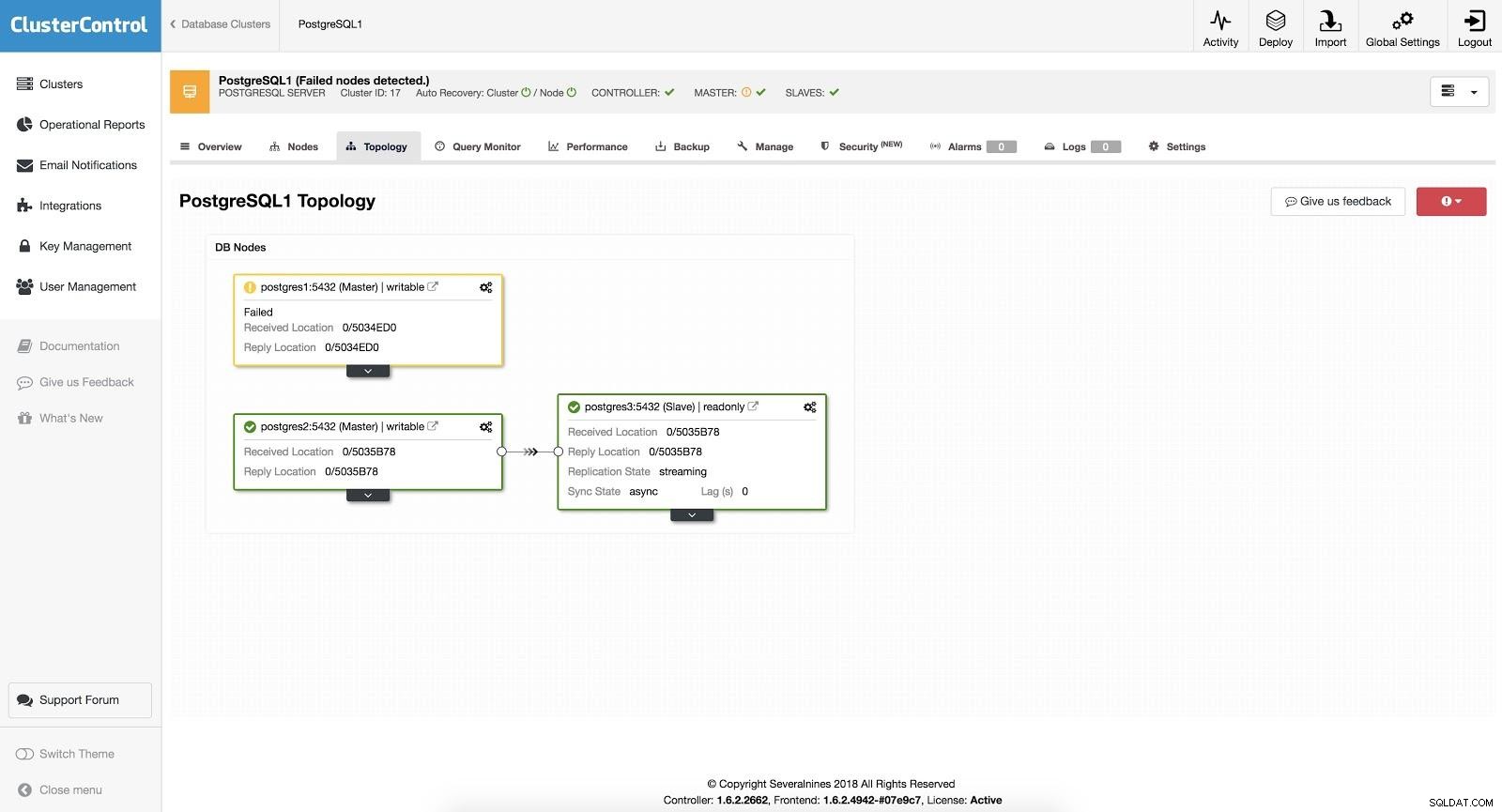 ClusterControl Failover 3
ClusterControl Failover 3 Med alternativet "Autorecovery" PÅ kommer vår ClusterControl att utföra en automatisk failover samt meddela oss om problemet. På så sätt kan våra system återhämta sig på några sekunder och utan vår inblandning.
Cluster Control erbjuder oss möjligheten att konfigurera en vitlista/svartlista för att definiera hur vi vill att våra servrar ska beaktas (eller inte tas med i beräkningen) när vi bestämmer oss för en masterkandidat.
Av de som är tillgängliga enligt ovanstående konfiguration kommer ClusterControl att välja den mest avancerade slaven, och för detta ändamål använder pg_current_xlog_location (PostgreSQL 9+) eller pg_current_wal_lsn (PostgreSQL 10+) beroende på versionen av vår databas.
ClusterControl utför också flera kontroller av failover-processen för att undvika några vanliga misstag. Ett exempel är att om vi lyckas återställa vår gamla misslyckade master så kommer den INTE att återinföras automatiskt till klustret, varken som en master eller som en slav. Vi måste göra det manuellt. Detta kommer att undvika risken för dataförlust eller inkonsekvens i fallet att vår slav (som vi marknadsförde) var försenad vid tidpunkten för felet. Vi kanske också vill analysera problemet i detalj, men när vi lägger till det i vårt kluster skulle vi eventuellt förlora diagnostisk information.
Dessutom, om failover misslyckas, görs inga ytterligare försök, manuellt ingripande krävs för att analysera problemet och utföra motsvarande åtgärder. Detta för att undvika situationen där ClusterControl, som hög tillgänglighetshanterare, försöker marknadsföra nästa slav och nästa. Det kan finnas ett problem, och vi vill inte göra saken värre genom att försöka flera failovers.
Lastbalanserare
Som vi nämnde tidigare är lastbalanseraren ett viktigt verktyg att överväga för vår failover, speciellt om vi vill använda automatisk failover i vår databastopologi.
För att failover ska vara transparent för både användaren och applikationen behöver vi en komponent däremellan, eftersom det inte räcker för att främja en master till en slav. För detta kan vi använda HAProxy + Keepalived.
Vad är HAProxy?
HAProxy är en lastbalanserare som distribuerar trafik från ett ursprung till en eller flera destinationer och kan definiera specifika regler och/eller protokoll för denna uppgift. Om någon av destinationerna slutar svara markeras den som offline och trafiken skickas till resten av de tillgängliga destinationerna. Detta förhindrar att trafik skickas till en otillgänglig destination och förhindrar att denna trafik går förlorad genom att dirigera den till en giltig destination.
Vad är Keepalived?
Keepalved låter dig konfigurera en virtuell IP inom en aktiv/passiv grupp av servrar. Denna virtuella IP tilldelas en aktiv "Primär" server. Om den här servern misslyckas migreras IP:n automatiskt till den "sekundära" servern som visade sig vara passiv, vilket gör att den kan fortsätta arbeta med samma IP på ett transparent sätt för våra system.
För att implementera denna lösning med ClusterControl började vi som om vi skulle lägga till en slav. Gå till Cluster Actions och välj Add Load Balancer (se ClusterControl Lägg till slav 1-bild).
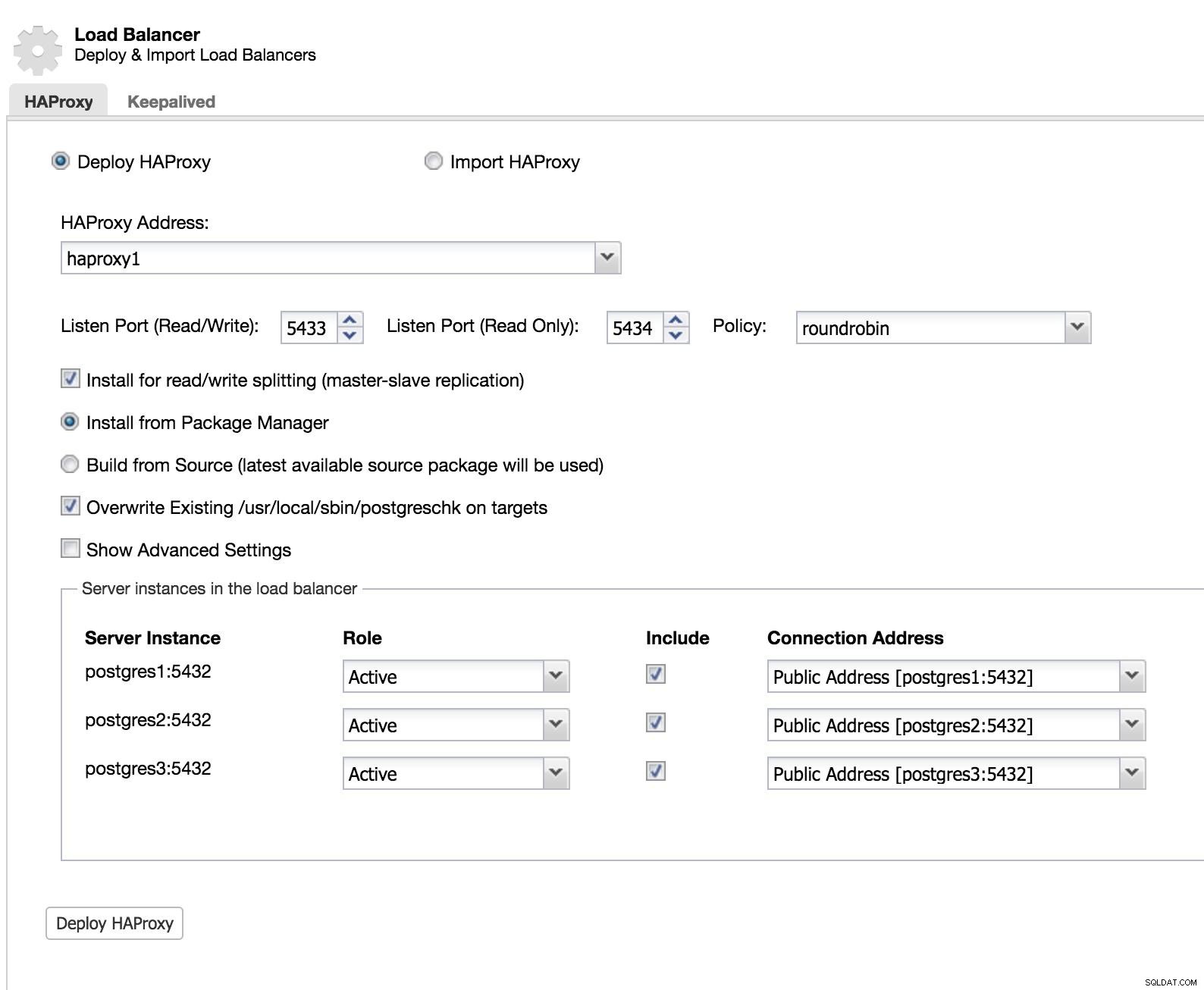 ClusterControl Load Balancer 1
ClusterControl Load Balancer 1 Vi lägger till informationen om vår nya lastbalanserare och hur vi vill att den ska bete sig (policy).
Om vi vill implementera failover för vår lastbalanserare måste vi konfigurera minst två instanser.
Sedan kan vi konfigurera Keepalived (Välj Cluster -> Hantera -> Load Balancer -> Keepalived).
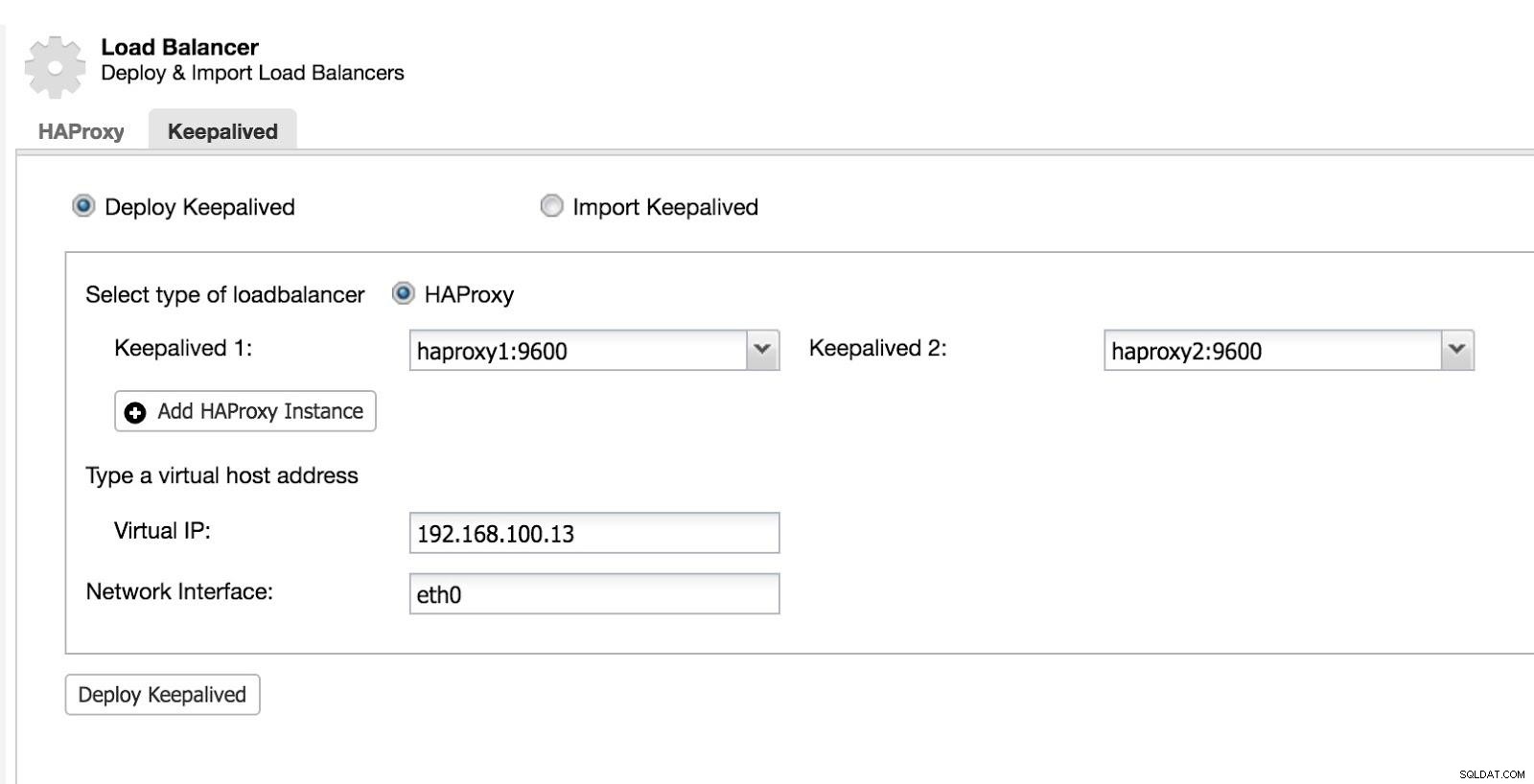 ClusterControl Load Balancer 2
ClusterControl Load Balancer 2 Efter detta har vi följande topologi:
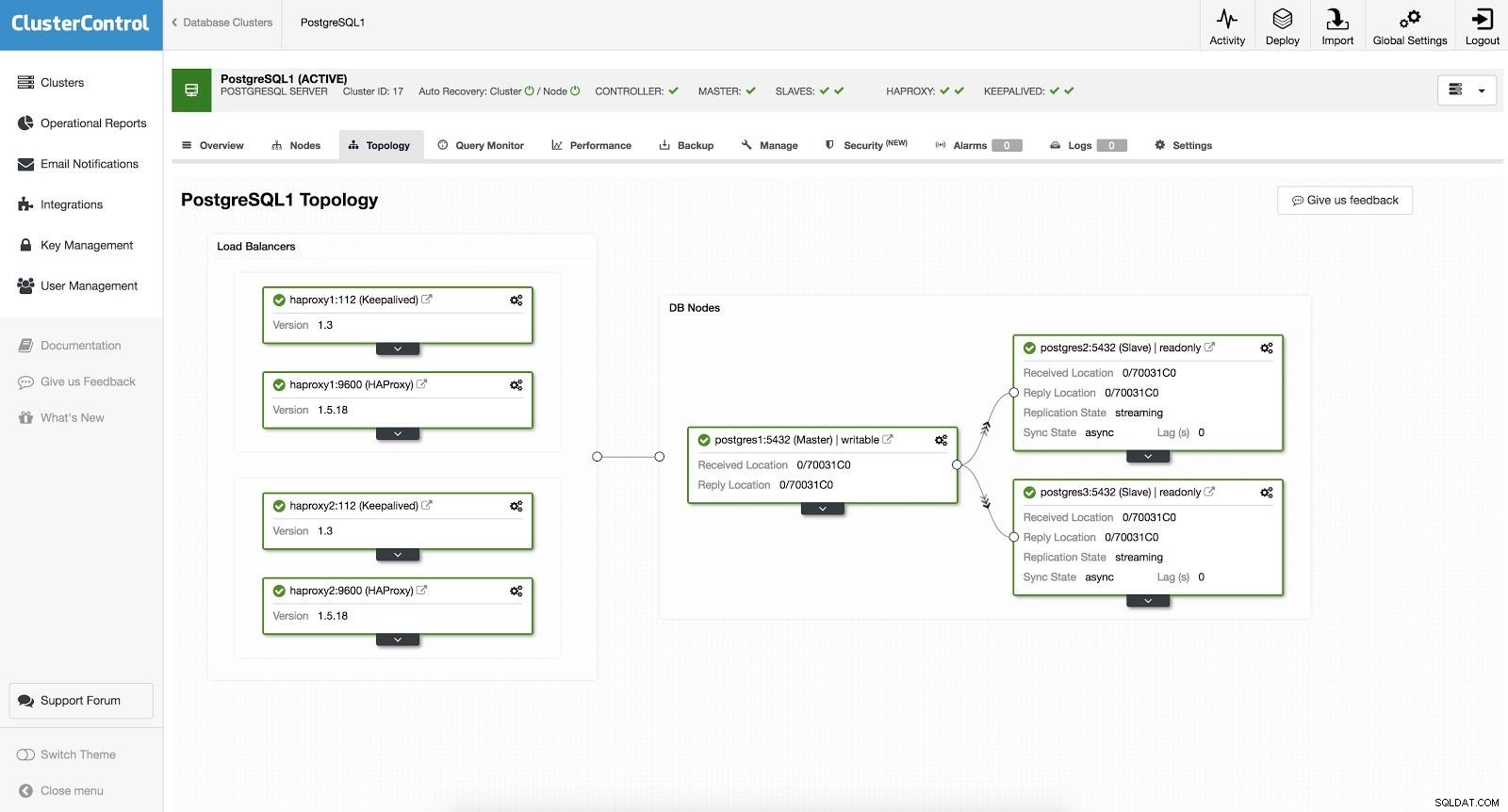 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 HAProxy är konfigurerad med två olika portar, en läs-skriv- och en skrivskyddad.
I vår läs-skrivport har vi vår masterserver som online och resten av våra noder som offline. I skrivskyddsporten har vi både befälhavaren och slavarna online. På så sätt kan vi balansera lästrafiken mellan våra noder. När du skriver kommer läs-skrivporten att användas, som pekar på mastern.
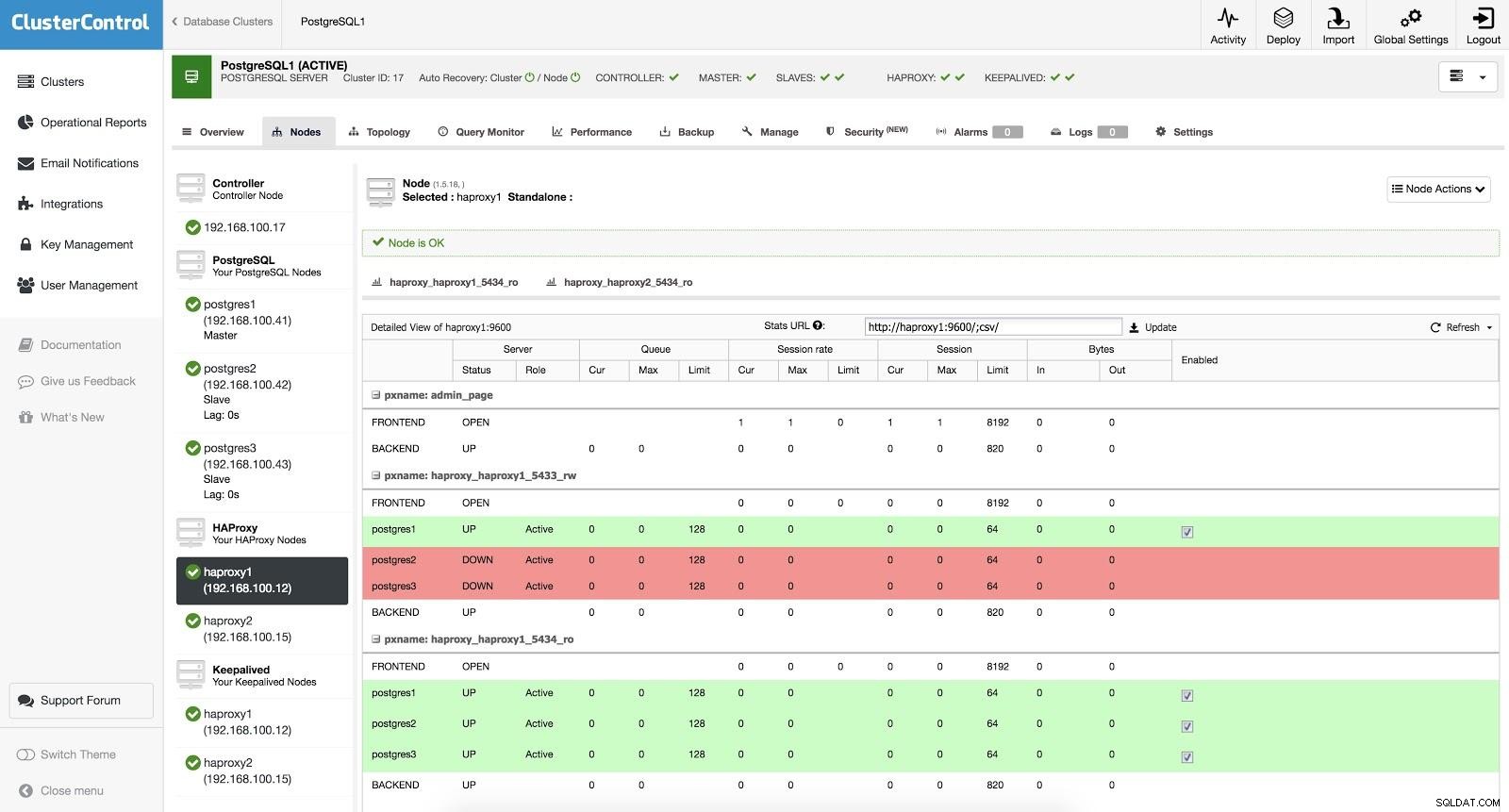 ClusterControl Load Balancer 3
ClusterControl Load Balancer 3 När HAProxy upptäcker att en av våra noder, antingen master eller slav, inte är tillgänglig, markeras den automatiskt som offline. HAProxy kommer inte att skicka någon trafik till den. Denna kontroll görs av hälsokontrollskript som är konfigurerade av ClusterControl vid tidpunkten för distributionen. Dessa kontrollerar om instanserna är uppe, om de genomgår återställning eller är skrivskyddade.
När ClusterControl marknadsför en slav till mästare, markerar vår HAProxy den gamla mastern som offline (för båda portarna) och lägger den befordrade noden online (i läs-skrivporten). På så sätt fortsätter våra system att fungera normalt.
Om vår aktiva HAProxy (som är tilldelad en virtuell IP-adress som våra system ansluter till) misslyckas, migrerar Keepalved denna IP till vår passiva HAProxy automatiskt. Det betyder att våra system sedan kan fortsätta att fungera normalt.
Slutsats
Som vi kunde se är failover en grundläggande del av varje produktionsdatabas. Det kan vara användbart när du utför vanliga underhållsuppgifter eller migrering. Vi hoppas att den här bloggen har varit användbar som en introduktion till ämnet, så att du kan fortsätta forska och skapa dina egna failover-strategier.