IRI levererar nu också suddiga sökfunktioner, både i sina kostnadsfria databas- och profileringsverktyg för platta filer, och som tillgängliga fältfunktionsbibliotek i IRI CoSort, FieldShield och Voracity för att förbättra datakvalitet, säkerhet och MDM-kapacitet. Det här är den första i en serie artiklar om IRIs fuzzy search-lösningar som täcker deras tillämpning för förbättring av datakvalitet.
Introduktion
Sannheten eller tillförlitligheten hos data för ett av de stora V-orden (tillsammans med volym, variation, hastighet och värde) som IRI et al pratar om i samband med data- och företagsinformationshantering. Generellt definierar IRI data i tvivel som att de har ett eller flera av dessa attribut:
- Låg kvalitet eftersom den är inkonsekvent, felaktig eller ofullständig
- Tvetydig (tänk MDM), oprecis (ostrukturerad) eller vilseledande (sociala medier)
- Partiskt (enkätfråga), bullrigt (överflödigt eller förorenat) eller onormalt (avvikande värden)
- Ogiltig av någon annan anledning (är uppgifterna korrekta och korrekta för dess avsedda användning?)
- Osäkert – innehåller det PII eller hemligheter, och är det ordentligt maskerat, reversibelt etc.?
Den här artikeln fokuserar endast på nya otydliga söklösningar för det första problemet, datakvalitet. Andra artiklar i den här bloggen diskuterar hur IRI-programvaran tar itu med de andra fyra sanningsproblemen; be om hjälp att hitta dem om du inte kan.
Om fuzzy sökning
Luddiga sökningar hittar ord eller fraser (värden) som liknar, men inte nödvändigtvis identiska, med andra ord eller fraser (värden). Den här typen av sökning har många användningsområden, som att hitta sekvensfel, stavfel, transponerade tecken och annat som vi kommer att ta upp senare.
Att utföra en suddig sökning efter ungefärliga ord eller fraser kan hjälpa till att hitta data som kan vara en dubblett av tidigare lagrad data. Användarinmatning eller automatisk korrigering kan dock ha ändrat data på något sätt för att få posterna att verka oberoende.
Resten av artikeln kommer att täcka fyra suddiga sökfunktioner som IRI nu stöder, hur du använder dem för att söka igenom data och returnerar dessa poster som ungefärligt sökvärdet.
1. Levenshtein
Levenshtein-algoritmen fungerar genom att ta två ord eller fraser och räkna hur många redigeringssteg det kommer att ta för att förvandla ett ord eller en fras till ett annat. Ju färre steg det kommer att ta, desto mer sannolikt är ordet eller frasen en matchning. Stegen som Levenshtein-funktionen kan ta är:
- Infoga av ett tecken i ordet eller frasen
- Radering av ett tecken från ordet eller frasen
- Ersättning av ett tecken i ett ord eller en fras med ett annat
Följande är ett CoSort SortCL-program (jobbskript) som visar hur du använder Levenshteins fuzzy sökfunktion:
/INFILE=LevenshteinSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=LevenshteinOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_levenshtein(NAME, "Barney Oakley"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Det finns två delar som måste användas för att producera det önskade resultatet.
FS_Result=fs_levenshtein(NAME, "Barney Oakley")
Denna rad anropar funktionen fs_levenshtein och lagrar resultatet i fältet FS_RESULT. Funktionen tar två ingångsparametrar:
- Fältet att köra den otydliga sökningen på (NAME i vårt exempel)
- Strängen som inmatningsfältet kommer att jämföras med ("Barney Oakley" i vårt exempel).
/INCLUDE WHERE FS_RESULT GT 50
Den här raden jämför fältet FS_RESULT och kontrollerar om det är större än 50, sedan matas endast poster med ett FS_RESULT på mer än 50 ut. Följande visar resultatet från vårt exempel.

Som resultatet visar är denna typ av sökning användbar för att hitta:
- Sammanfogade namn
- Bruser
- Stavningsfel
- Transponerade tecken
- Transskriptionsfel
- Skrivfel
Levenshtein-funktionen är därför också användbar för att identifiera vanliga datainmatningsfel. Det tar dock längst tid att prestera av de fyra algoritmerna, eftersom det jämför varje tecken i en sträng med varje tecken i den andra.
2. Tärningskoefficient
Tärningskoefficienten, eller tärningsalgoritmen, delar upp ord eller fraser i teckenpar, jämför dessa par och räknar matchningarna. Ju fler matchningar orden har, desto mer sannolikt är själva ordet en matchning.
Följande SortCL-skript visar den fuzzy sökfunktionen för tärningskoefficienten.
/INFILE=DiceSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=DiceOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(FS_RESULT=fs_dice(NAME, "Robert Thomas Smith"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE FS_RESULT GT 50
Det finns två delar som måste användas för att ge oss önskat resultat.
FS_Result=fs_dice(NAME, "Robert Thomas Smith")
Denna rad anropar funktionen fs_dice och lagrar resultatet i fältet FS_RESULT. Funktionen tar två ingångsparametrar:
- Fältet att köra den otydliga sökningen på (NAME i vårt exempel).
- Strängen som inmatningsfältet kommer att jämföras med ("Robert Thomas Smith" i vårt exempel).
/INCLUDE WHERE FS_RESULT GT 50
Den här raden jämför fältet FS_RESULT och kontrollerar om det är större än 50, sedan matas endast poster med ett FS_RESULT på mer än 50 ut. Följande visar resultatet från vårt exempel.
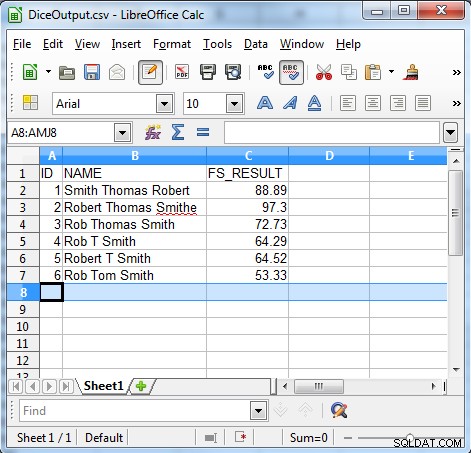
Som resultatet visar är tärningskoefficientalgoritmen användbar för att hitta inkonsekventa data som:
- Sekvensfel
- Ofrivilliga korrigeringar
- Skeknamn
- Initialer och smeknamn
- Oförutsägbar användning av initialer
- Lokalisering
Tärningsalgoritmen är snabbare än Levenshtein, men kan bli mindre exakt när det finns många enkla fel som stavfel.
3. Metaphone och 4. Soundex
Metaphone- och Soundex-algoritmerna jämför ord eller fraser baserat på deras fonetiska ljud. Soundex gör detta genom att läsa igenom ordet eller frasen och titta på enskilda karaktärer, medan Metaphone tittar på både enskilda karaktärer och teckengrupper. Sedan ger båda koder baserade på ordets stavning och uttal.
Följande SortCL-skript demonstrerar Soundex och Metasphones sökfunktioner:
/INFILE=SoundexSample.dat /PROCESS=RECORD /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR="\t") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR="\t") /REPORT /OUTFILE=SoundexOutput.csv /PROCESS=CSV /FIELD=(ID, TYPE=ASCII, POSITION=1, SEPARATOR=",") /FIELD=(NAME, TYPE=ASCII, POSITION=2, SEPARATOR=",") /FIELD=(SE_RESULT=fs_soundex(NAME, "John"), POSITION=3, SEPARATOR=",") /FIELD=(MP_RESULT=fs_metaphone(NAME, "John"), POSITION=3, SEPARATOR=",") /INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
I varje fall finns det tre delar som måste användas för att ge oss den önskade effekten.
SE_RESULT=fs_soundex(NAME, "John") MP_RESULT=fs_metaphone(NAME, "John")
Linjen anropar funktionen och lagrar resultatet i fältet RESULTAT. Funktionerna tar båda två indataparametrar:
- Fältet att köra den otydliga sökningen på (NAME i vårt exempel)
- Xtringen som inmatningsfältet kommer att jämföras med ("John" i vårt exempel)
/INCLUDE WHERE (SE_RESULT GT 0) OR (MP_RESULT GT 0)
Den här raden jämför SE_RESULT och MP_RESULT-fälten och kontrollerar och returnerar raden om någon är större än 0.
Soundex returnerar antingen 100 för en matchning eller 0 om det inte är en matchning. Metaphone har mer specifika resultat och ger 100 för en stark match, 66 för en normal match och 33 för en mindre match.
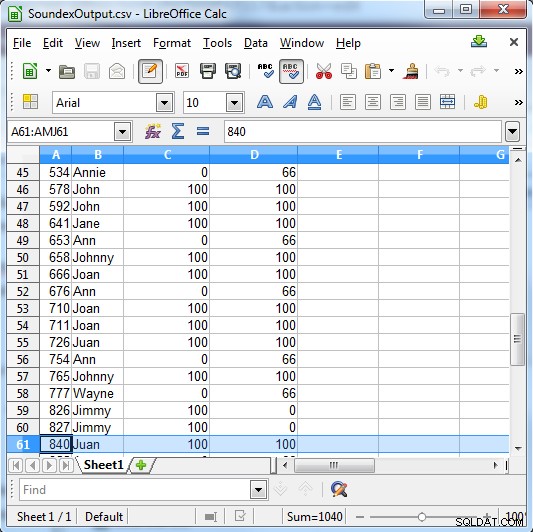
Kolumn C visar Soundex-resultaten. Ckolumn D visar Metaphone-resultaten
Som resultatet visar är denna typ av sökning användbar för att hitta:
- Fonetiska fel
Skicka feedback om den här artikeln nedan, och om du är intresserad av att använda dessa funktioner vänligen kontakta din IRI-representant. Se vår nästa artikel om hur du använder dessa algoritmer i guiden för datakonsolidering (kvalitet) IRI Workbench.