De flesta OLTP-arbetsbelastningar involverar slumpmässig disk I/O-användning. Genom att veta att diskar (inklusive SSD) har långsammare prestanda än att använda RAM, använder databassystem cachning för att öka prestandan. Cachning handlar om att lagra data i minnet (RAM) för snabbare åtkomst vid en senare tidpunkt.
PostgreSQL använder också cachelagring av sina data i ett utrymme som kallas shared_buffers. I den här bloggen kommer vi att utforska den här funktionen för att hjälpa dig att öka prestandan.
Grundläggande om PostgreSQL-cache
Innan vi går djupare in i begreppet cachelagring, låt oss ta en titt på grunderna.
I PostgreSQL är data organiserad i form av sidor med storleken 8KB, och varje sådan sida kan innehålla flera tuppel (beroende på storleken på tuppel). En förenklad representation kan se ut som nedan:
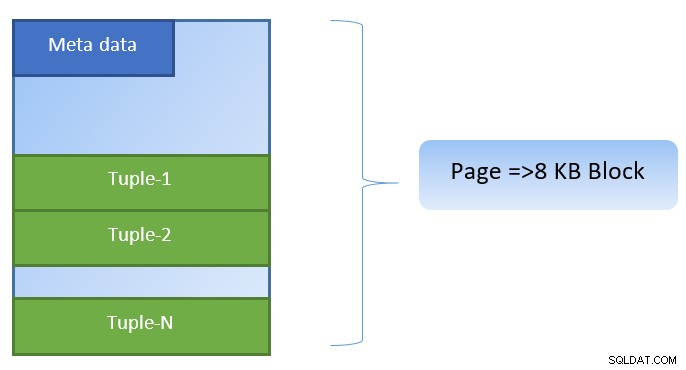
PostgreSQL cachar följande för att påskynda dataåtkomst:
- Data i tabeller
- Index
- Frågeexekveringsplaner
Medan cachingplanen för frågeexekveringsplanen fokuserar på att spara CPU-cykler; cachning för tabelldata och indexdata är fokuserad för att spara kostsam disk I/O-drift.
PostgreSQL låter användare definiera hur mycket minne de vill reservera för att hålla sådan cache för data. Den relevanta inställningen är shared_buffers i konfigurationsfilen postgresql.conf. Det ändliga värdet för shared_buffers definierar hur många sidor som kan cachelagras vid varje tidpunkt.
När en fråga exekveras, söker PostgreSQL efter sidan på disken som innehåller den relevanta tupeln och skjuter den i shared_buffers-cachen för åtkomst i sidled. Nästa gång samma tuppel (eller någon tupel på samma sida) behöver nås, kan PostgreSQL spara disk IO genom att läsa den i minnet.
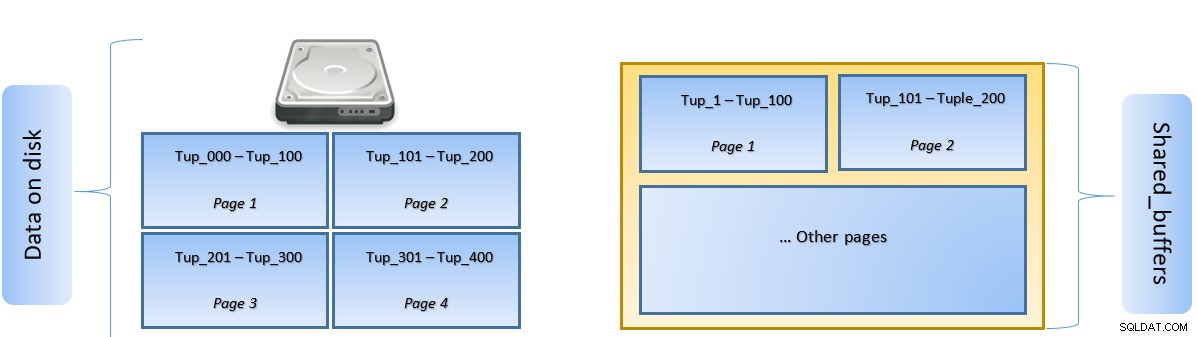
I ovanstående figur, sida-1 och sida-2 för en viss tabellen har cachats. Om en användarfråga behöver komma åt tuples mellan Tuple-1 och Tuple-200, kan PostgreSQL hämta den från RAM-minnet själv.
Men om frågan behöver åtkomst till Tuples 250 till 350, måste den göra disk I/O för Sida 3 och Sida 4. All ytterligare åtkomst för Tuple 201 till 400 kommer att hämtas från cachen och disk I/O kommer inte att behövas – vilket gör sökningen snabbare.
På en hög nivå följer PostgreSQL LRU-algoritmen (senast använd) för att identifiera sidorna som måste vräkas från cachen. Med andra ord, en sida som bara nås en gång har högre chanser att vräkas (jämfört med en sida som nås flera gånger), ifall en ny sida behöver hämtas av PostgreSQL till cachen.
PostgreSQL-cache i aktion
Låt oss köra ett exempel och se hur cachen påverkar prestandan.
Starta PostgreSQL och håll shared_buffer inställd på standard 128 MB
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startAnslut till servern och skapa en dummy-tabell tblDummy och ett index på c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Fylla dummydata med 200 000 tupler, så att det finns 10 000 unika p_id och för varje p_id finns det 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Starta om servern för att rensa cacheminnet. Kör nu en fråga och kontrollera hur lång tid det tar att utföra samma
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msKontrollera sedan blocken som läses från disken
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0I exemplet ovan fanns det 1000 block som lästes från disken för att hitta count tuples där c_id =1. Det tog 160 ms sedan det var disk I/O involverad för att hämta dessa poster från disken.
Körningen går snabbare om samma fråga körs om, eftersom alla block fortfarande finns i PostgreSQL-serverns cache i detta skede
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 msoch blockerar läsning från disken kontra från cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000Det är uppenbart ovanifrån att eftersom alla block lästes från cachen och ingen disk I/O krävdes. Detta gav därför också resultaten snabbare.
Ställa in storleken på PostgreSQL-cachen
Storleken på cachen måste ställas in i en produktionsmiljö i enlighet med mängden tillgängligt RAM-minne samt de frågor som krävs för att köras.
Som ett exempel – shared_buffer på 128 MB kanske inte räcker för att cachelagra all data, om frågan skulle hämta fler tuplar:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Ändra shared_buffer till 1024MB för att öka heap_blks_hit.
Faktiskt, med tanke på frågorna (baserade på c_id), om data omorganiseras, kan ett bättre cacheträffförhållande också uppnås med en mindre shared_buffer.
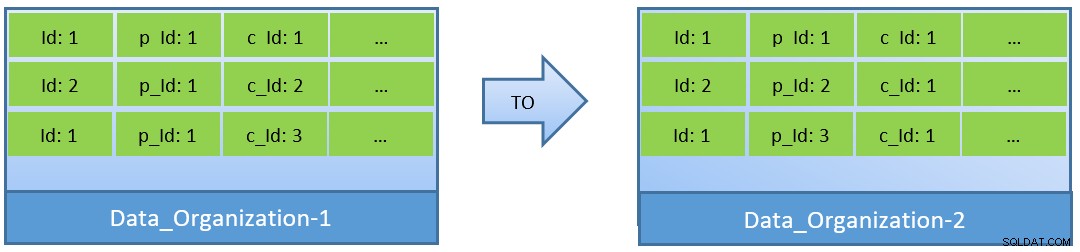
I Data_Organization-1 kommer PostgreSQL att behöva 1000 blockläsningar (och cacheförbrukning ) för att hitta c_id=1. Å andra sidan, för Data_Organisation-2, för samma fråga, behöver PostgreSQL endast 104 block.
Färre block som krävs för samma fråga förbrukar så småningom mindre cache och håller också körningstiden för frågor optimerad.
Slutsats
Medan shared_buffer upprätthålls på PostgreSQL-processnivå, tas även kärnnivåcachen i beaktande för att identifiera optimerade frågeexekveringsplaner. Jag kommer att ta upp detta ämne i en senare serie bloggar.