Varje PostgreSQL-utgåva kommer med några större funktionsförbättringar, men det som är lika intressant är att varje utgåva också förbättrar sina tidigare funktioner.
Eftersom PostgreSQL 13 är planerad att släppas snart är det dags att kolla vilka funktioner och förbättringar som communityn ger oss. En sådan förbättring utan brus är "Logisk replikeringsförbättring för partitionering."
Låt oss förstå denna funktionsförbättring med ett pågående exempel.
Terminologi
Två termer som är viktiga för att förstå denna funktion är:
- Partitionstabeller
- Logisk replikering
Partitionstabeller
Ett sätt att dela upp ett stort bord i flera fysiska delar för att uppnå fördelar som:
- Förbättrad frågeprestanda
- Snabbare uppdateringar
- Snabbare massladdningar och raderingar
- Ordna sällan använda data på långsamma hårddiskar
Några av dessa fördelar uppnås genom partitionsbeskärning (d.v.s. frågeplanerare som använder partitionsdefinition för att avgöra om en partition ska skannas eller inte) och det faktum att en partition är ganska lättare att passa i ändligt minne jämfört med ett stort bord.
En tabell är partitionerad på basis av:
- Lista
- Hash
- Räckvidd

Logisk replikering
Som namnet antyder är detta en replikeringsmetod där data replikeras stegvis baserat på deras identitet (t.ex. nyckel). Det liknar inte WAL eller fysiska replikeringsmetoder där data skickas byte för byte.
Baserat på ett utgivare-prenumerantmönster måste datakällan definiera en utgivare medan målet måste registreras som prenumerant. De intressanta användningsfallen för detta är:
- Selektiv replikering (endast en del av databasen)
- Skriver samtidigt till två instanser av databasen där data replikeras
- Replikering mellan olika operativsystem (t.ex. Linux och Windows)
- Finanserad säkerhet vid replikering av data
- Utlöser exekvering när data kommer till mottagarsidan
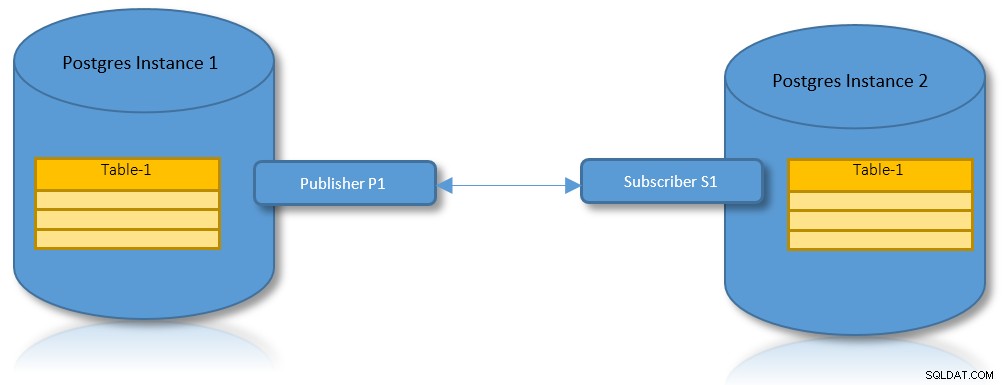
Logisk replikering för partitioner
Med fördelarna med både logisk replikering och partitionering är det ett praktiskt användningsfall att ha ett scenario där en partitionerad tabell måste replikeras över två PostgreSQL-instanser.
Följande är stegen för att etablera och markera förbättringen som görs i PostgreSQL 13 i detta sammanhang.
Inställningar
Tänk på en konfiguration med två noder för att köra två olika instanser som innehåller en partitionerad tabell:
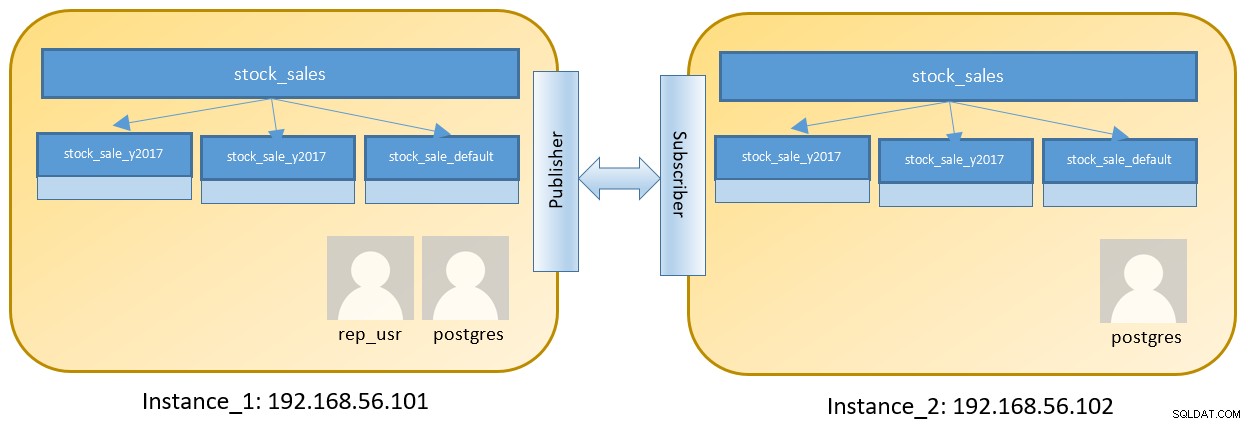
Steg på Instance_1 är enligt nedan efter inloggning på 192.168.56.101 som postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startInställning av 'wal_level' är specifikt inställd på 'logisk' för att indikera att logisk replikering kommer att användas för att replikera data från denna instans. Konfigurationsfilen 'pg_hba.conf' har också ändrats för att tillåta anslutningar från 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Även om postgres-rollen skapas som standard i databasen Instance_1, bör en separat användare också skapas som har begränsad åtkomst – vilket begränsar omfattningen endast för en given tabell.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;Nästan liknande inställningar krävs på Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startDet bör noteras att eftersom Instance_2 inte kommer att vara en datakälla för någon annan nod, behöver wal_level-inställningar såväl som filen pg_hba.conf inga extra inställningar. Onödigt att säga att pg_hba.conf kan behöva uppdateras enligt produktionsbehov.
Logisk replikering stöder inte DDL, vi måste skapa en tabellstruktur på Instance_2 också. Skapa en partitionerad tabell med hjälp av partitionen ovan för att skapa samma tabellstruktur på Instance_2 också.
Inställning av logisk replikering
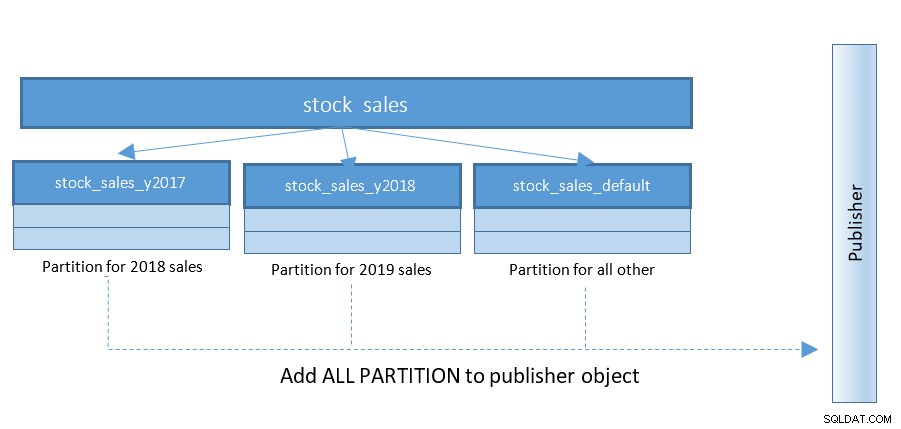
Inställning av logisk replikering blir mycket enklare med PostgreSQL 13. Fram till PostgreSQL 12 var strukturen som nedan:
Med PostgreSQL 13 blir publicering av partitioner mycket enklare. Se diagrammet nedan och jämför med föregående diagram:
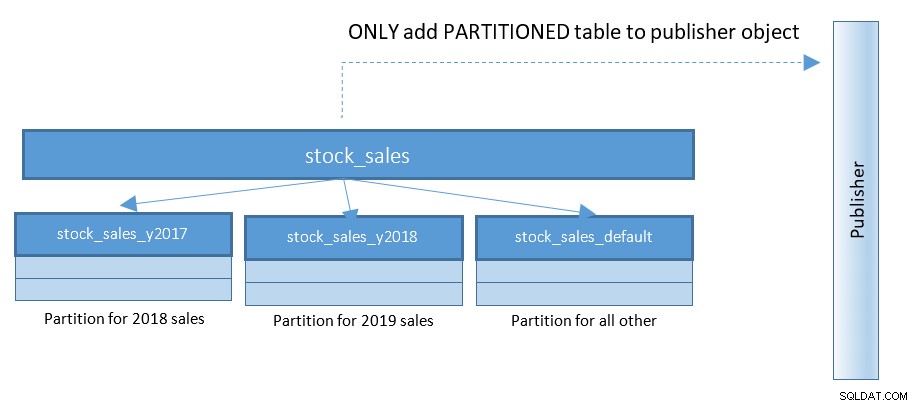
Med inställningar som rasar med 100-tals och 1000-tals partitionerade tabeller – denna lilla förändring förenklar saker i stor utsträckning.
I PostgreSQL 13 kommer uttalandena för att skapa en sådan publikation att vara:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Konfigurationsparametern publish_via_partition_root är ny i PostgreSQL 13, vilket gör att mottagarnoden kan ha en något annorlunda bladhierarki. Bara publicering skapas på partitionerade tabeller i PostgreSQL 12, kommer att returnera felmeddelanden som nedan:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Om vi ignorerar begränsningarna för PostgreSQL 12 och fortsätter med den här funktionen på PostgreSQL 13, måste vi etablera prenumerant på Instance_2 med följande uttalanden:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Kontrollerar om det verkligen fungerar
Vi är i stort sett klara med hela installationen, men låt oss köra ett par tester för att se om saker och ting fungerar.
I Instance_1, infoga flera rader och se till att de skapas i flera partitioner:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Kontrollera data på Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Låt oss nu kontrollera om logisk replikering fungerar även om bladnoderna inte är samma på mottagarsidan.
Lägg till ytterligare en partition på Instance_1 och infoga post:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Kontrollera data på Instance_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Andra partitioneringsfunktioner i PostgreSQL 13
Det finns även andra förbättringar i PostgreSQL 13 som är relaterade till partitionering, nämligen:
- Förbättringar i Join mellan partitionerade tabeller
- Partitionerade tabeller stöder nu FÖRE utlösare på radnivå
Slutsats
Jag kommer definitivt att kolla in de ovan nämnda två kommande funktionerna i min nästa uppsättning bloggar. Tills dess en tankeställare – med den kombinerade kraften av partitionering och logisk replikering, seglar PostgreSQL närmare en master-master-setup?