Om du inte har sett den har vi precis släppt ClusterControl 1.7.5 med stora förbättringar och nya användbara funktioner. Några av funktionerna inkluderar Cluster Wide Maintenance, stöd för version CentOS 8 och Debian 10, PostgreSQL 12 Support, MongoDB 4.2 och Percona MongoDB v4.0-stöd, samt den nya MySQL Freeze Frame.
Vänta, men vad är en MySQL Freeze Frame? Är detta något nytt för MySQL?
Det är inte något nytt inom själva MySQL-kärnan. Det är en ny funktion som vi har lagt till i ClusterControl 1.7.5 som är specifik för MySQL-databaser. MySQL Freeze Frame i ClusterControl 1.7.5 kommer att täcka följande saker:
- Ögonblicksbild av MySQL-status före klusterfel.
- Ögonblicksbild av MySQL-processlistan före klusterfel (kommer snart).
- Inspektera klusterincidenter i driftsrapporter eller från s9s kommandoradsverktyg.
Detta är värdefull information som kan hjälpa till att spåra buggar och fixa dina MySQL/MariaDB-kluster när det går söderut. I framtiden planerar vi att även inkludera ögonblicksbilder av SHOW ENGINE InnoDB-statusvärdena. Så håll utkik efter våra framtida utgåvor.
Observera att den här funktionen fortfarande är i betaläge, vi förväntar oss att samla in fler datauppsättningar när vi arbetar med våra användare. I den här bloggen kommer vi att visa dig hur du använder den här funktionen, särskilt när du behöver mer information när du diagnostiserar ditt MySQL/MariaDB-kluster.
ClusterControl om hantering av klusterfel
För klusterfel gör ClusterControl ingenting om inte automatisk återställning (kluster/nod) är aktiverad precis som nedan:

När det är aktiverat kommer ClusterControl att försöka återställa en nod eller återställa klustret genom att tar upp hela klustertopologin.
För MySQL, till exempel i en master-slave-replikering, måste den ha minst en master vid varje given tidpunkt, oavsett antalet tillgängliga slav(ar). ClusterControl försöker korrigera topologin minst en gång för replikeringskluster, men ger fler försök för multimasterreplikering som NDB Cluster och Galera Cluster. Nodåterställning försöker återställa en misslyckad databasnod, t.ex. när processen avbröts (onormal avstängning), eller processen drabbades av en OOM (Out-of-Memory). ClusterControl kommer att ansluta till noden via SSH och försöka få fram MySQL. Vi har tidigare bloggat om hur ClusterControl utför automatisk databasåterställning och failover, så besök den artikeln för att lära dig mer om systemet för automatisk återställning av ClusterControl.
I den tidigare versionen av ClusterControl <1.7.5 utlöste dessa återställningsförsök larm. Men en sak som våra kunder missade var en mer komplett incidentrapport med tillståndsinformation precis innan klusterfelet. Tills vi insåg denna brist och lade till den här funktionen i ClusterControl 1.7.5. Vi kallade det "MySQL Freeze Frame". MySQL Freeze Frame erbjuder, när detta skrivs, en kort sammanfattning av incidenter som leder till klustertillståndsförändringar precis före kraschen. Viktigast av allt, det inkluderar i slutet av rapporten listan över värdar och deras MySQL Global Status-variabler och -värden.
Hur skiljer sig MySQL Freeze Frame från automatisk återställning?
MySQL Freeze Frame är inte en del av den automatiska återställningen av ClusterControl. Oavsett om automatisk återställning är inaktiverad eller aktiverad kommer MySQL Freeze Frame alltid att fungera så länge som ett kluster- eller nodfel har upptäckts.
Hur fungerar MySQL Freeze Frame?
I ClusterControl finns det vissa tillstånd som vi klassificerar som olika typer av klusterstatus. MySQL Freeze Frame genererar en incidentrapport när dessa två tillstånd utlöses:
- CLUSTER_DEGRADED
- CLUSTER_FAILURE
I ClusterControl är en CLUSTER_DEGRADED när du kan skriva till ett kluster, men en eller flera noder är nere. När detta händer kommer ClusterControl att generera incidentrapporten.
För CLUSTER_FAILURE, även om dess nomenklatur förklarar sig själv, är det tillståndet där ditt kluster misslyckas och inte längre kan bearbeta läsningar eller skrivningar. Då är det ett CLUSTER_FAILURE-tillstånd. Oavsett om en automatisk återställningsprocess försöker åtgärda problemet eller om den är inaktiverad, genererar ClusterControl incidentrapporten.
Hur aktiverar du MySQL Freeze Frame?
ClusterControls MySQL Freeze Frame är aktiverad som standard och genererar bara en incidentrapport endast när tillstånden CLUSTER_DEGRADED eller CLUSTER_FAILURE utlöses eller påträffas. Så det finns inget behov hos användaren att ställa in någon ClusterControl-konfiguration, ClusterControl kommer att göra det automatiskt åt dig.
Hitta MySQL Freeze Frame Incident Report
När detta skrivs finns det fyra sätt du kan hitta incidentrapporten på. Dessa kan hittas genom att göra följande avsnitt nedan.
Använda fliken Driftrapporter
Driftsrapporterna från de tidigare versionerna används endast för att skapa, schemalägga eller lista de driftsrapporter som har genererats av användare. Sedan version 1.7.5 har vi inkluderat incidentrapporten som genererats av vår MySQL Freeze Frame-funktion. Se exemplet nedan:
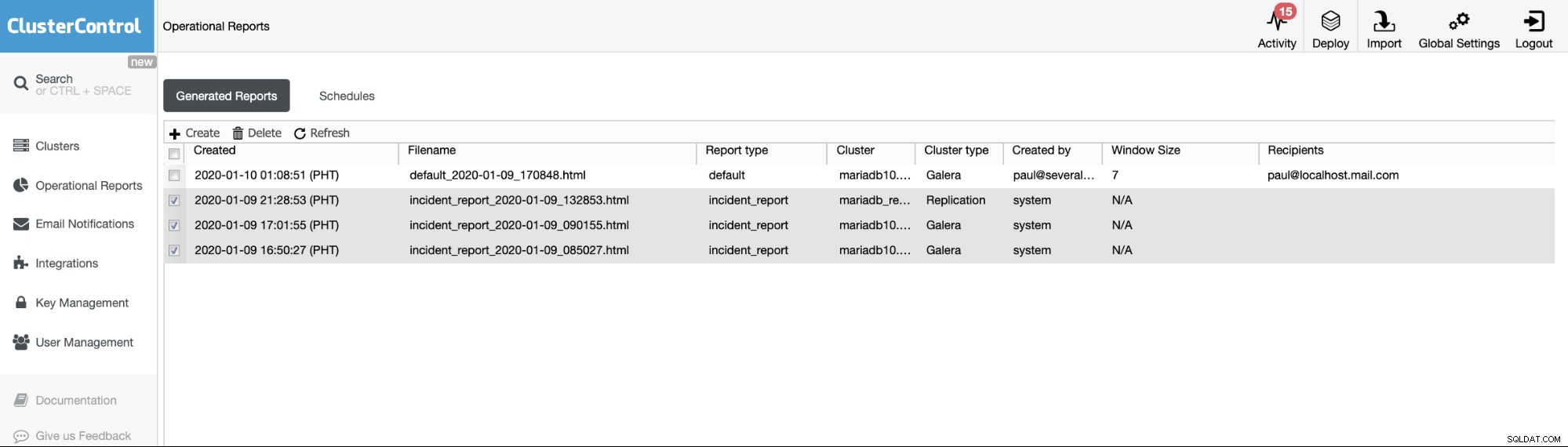
De markerade objekten eller objekten med rapporttyp ==incident_report, är incidenten rapporter genererade av MySQL Freeze Frame-funktionen i ClusterControl.
Använda felrapporter
Genom att välja klustret och skapa en felrapport, d.v.s. gå igenom denna process:
Använda s9s CLI-kommandoraden
I en genererad incidentrapport innehåller den instruktioner eller tips om hur du kan använda detta med s9s CLI-kommando. Nedan är vad som visas i incidentrapporten:
Tips! Genom att använda s9s CLI-verktyget kan du enkelt hantera data i den här rapporten, t.ex.:
s9s report --list --long
s9s report --cat --report-id=NSå om du vill hitta och generera en felrapport kan du använda detta tillvägagångssätt:
[example@sqldat.com ~]$ s9s report --list --long --cluster-id=60
ID CID TYPE CREATED TITLE
19 60 incident_report 16:50:27 Incident Report - Cluster Failed
20 60 incident_report 17:01:55 Incident ReportOm jag vill greppa wsrep_*-variablerna på en specifik värd kan jag göra följande:
[example@sqldat.com ~]$ s9s report --cat --report-id=20 --cluster-id=60|sed -n '/WSREP.*/p'|sed 's/ */ /g'|grep '192.168.10.80'|uniq -d
| WSREP_APPLIER_THREAD_COUNT | 4 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_CONF_ID | 18446744073709551615 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_SIZE | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_CLUSTER_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_DELAYED | 27ac86a9-3254-11ea-b104-bb705eb13dde:tcp://192.168.10.100:4567:1,9234d567-3253-11ea-92d3-b643c178d325:tcp://192.168.10.90:4567:1,9234d567-3253-11ea-92d4-b643c178d325:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25e-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b25f-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b260-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b261-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b262-cfcbda888ea9:tcp://192.168.10.90:4567:1,9e93ad58-3241-11ea-b263-cfcbda888ea9:tcp://192.168.10.90:4567:1,b0b7cb15-3241-11ea-bdbc-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbd-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbe-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdbf-1a21deddc100:tcp://192.168.10.100:4567:1,b0b7cb15-3241-11ea-bdc0-1a21deddc100:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b321-9a836d562a47:tcp://192.168.10.100:4567:1,dea553aa-32b9-11ea-b322-9a836d562a47:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ab-e298880f3348:tcp://192.168.10.100:4567:1,e27f4eff-3256-11ea-a3ac-e298880f3348:tcp://192.168.10.100:4567:1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_GCOMM_UUID | 781facbc-3241-11ea-8a22-d74e5dcf7e08 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LAST_COMMITTED | 443 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_CACHED_DOWNTO | 98 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_RECV_QUEUE_MAX | 2 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_LOCAL_STATE_UUID | 7c7a9d08-2d72-11ea-9ef3-a2551fd9f58d | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROTOCOL_VERSION | 10 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_PROVIDER_VERSION | 26.4.3(r4535) | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED | 112 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_RECEIVED_BYTES | 14413 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPLICATED_BYTES | 40592 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_DATA_BYTES | 31734 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS | 86 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_REPL_KEYS_BYTES | 2752 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_ROLLBACKER_THREAD_COUNT | 1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_THREAD_COUNT | 5 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |
| WSREP_EVS_REPL_LATENCY | 4.508e-06/4.508e-06/4.508e-06/0/1 | 192.168.10.80:3306 | 2020-01-09 08:50:24 |Manuell lokalisering via systemfilsökväg
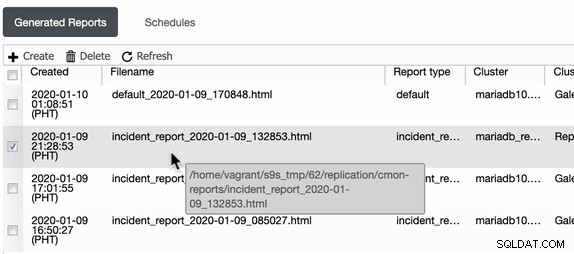
ClusterControl genererar dessa incidentrapporter i den värd där ClusterControl körs. ClusterControl skapar en katalog i /home/
Finns det några faror eller varningar när du använder MySQL Freeze Frame?
ClusterControl ändrar eller modifierar inte något i dina MySQL-noder eller -kluster. MySQL Freeze Frame kommer bara att läsa VIS GLOBAL STATUS (från och med denna tidpunkt) vid specifika intervall för att spara poster eftersom vi inte kan förutsäga tillståndet för en MySQL-nod eller -kluster när den kan krascha eller när den kan ha hårdvaru- eller diskproblem. Det är inte möjligt att förutsäga detta, så vi sparar värdena och därför kan vi generera en incidentrapport om en viss nod går ner. I så fall är faran med detta nära ingen. Det kan teoretiskt lägga till en serie klientförfrågningar till servern/servrarna i fall några lås hålls i MySQL, men vi har inte märkt det ännu. Serien av tester visar inte detta så vi skulle vara glada om du kan låta oss känner till eller lämna in ett supportärende om problem uppstår.
Det finns vissa situationer där en incidentrapport kanske inte kan samla in globala statusvariabler om ett nätverksproblem var problemet innan ClusterControl fryste en specifik ram för att samla in data. Det är helt rimligt eftersom det inte finns något sätt att ClusterControl kan samla in data för vidare diagnos eftersom det inte finns någon anslutning till noden i första hand.
Till sist kanske du undrar varför inte alla variabler visas i avsnittet GLOBAL STATUS? Under tiden ställer vi in ett filter där tomma eller 0 värden exkluderas i incidentrapporten. Anledningen är att vi vill spara lite diskutrymme. När dessa incidentrapporter inte längre behövs kan du ta bort dem via Fliken Driftsrapporter.
Testar MySQL Freeze Frame-funktionen
Vi tror att du är sugen på att testa den här och se hur den fungerar. Men snälla, se till att du inte kör eller testar detta i en live- eller produktionsmiljö. Vi kommer att täcka två faser av scenarier i MySQL/MariaDB, en för master-slave setup och en för Galera-typ setup.
Scenario för Master-Slave Setup-test
I en master-slave-installation är det enkelt och enkelt att prova.
Steg ett
Se till att du har inaktiverat lägena för automatisk återställning (kluster och nod), som nedan:

så den kommer inte att försöka fixa testscenariot.
Steg två
Gå till din masternod och försök ställa in skrivskyddad:
example@sqldat.com[mysql]> set @@global.read_only=1;
Query OK, 0 rows affected (0.000 sec)Steg tre
Den här gången slogs ett larm och så en genererad incidentrapport. Se nedan hur mitt kluster ser ut:

och larmet utlöstes:

och incidentrapporten genererades:

Galera Cluster Setup Test Scenario
För Galera-baserad installation måste vi se till att klustret inte längre är tillgängligt, det vill säga ett klusteromfattande fel. Till skillnad från Master-Slave-testet kan du låta Auto Recovery aktiveras eftersom vi kommer att leka med nätverksgränssnitt.
Obs:För den här installationen, se till att du har flera gränssnitt om du testar noderna i en fjärrinstans eftersom du inte kan få upp gränssnittet när du går ner i det gränssnittet där du är ansluten.
Steg ett
Skapa ett Galera-kluster med tre noder (till exempel genom att använda vagrant)
Steg två
Ge kommandot (precis som nedan) för att simulera nätverksproblem och gör detta till alla noder
[example@sqldat.com ~]# ifdown eth1
Device 'eth1' successfully disconnected.Steg tre
Nu tog den ner mitt kluster och har detta tillstånd:

larmde,

och det genererar en incidentrapport:

För ett exempel på incidentrapport kan du använda den här råfilen och spara den som html.
Det är ganska enkelt att försöka, men igen, vänligen gör detta endast i en miljö som inte är levande och inte producerad.
Slutsats
MySQL Freeze Frame i ClusterControl kan vara till hjälp vid diagnostisering av krascher. Vid felsökning behöver du en mängd information för att fastställa orsaken och det är precis vad MySQL Freeze Frame tillhandahåller.