Historiskt sett har den svåraste uppgiften när man arbetar med PostgreSQL varit att hantera uppgraderingarna. Det mest intuitiva uppgraderingssättet du kan tänka dig är att generera en replika i en ny version och utföra en failover av applikationen i den. Med PostgreSQL var detta helt enkelt inte möjligt på ett inbyggt sätt. För att utföra uppgraderingar behövde du tänka på andra sätt att uppgradera, som att använda pg_upgrade, dumpning och återställning, eller använda några tredjepartsverktyg som Slony eller Bucardo, alla har sina egna varningar.
Varför var detta? På grund av hur PostgreSQL implementerar replikering.
PostgreSQL inbyggda strömmande replikering är vad som kallas fysisk:den kommer att replikera ändringarna på en byte-för-byte-nivå, vilket skapar en identisk kopia av databasen på en annan server. Den här metoden har många begränsningar när du tänker på en uppgradering, eftersom du helt enkelt inte kan skapa en replik i en annan serverversion eller ens i en annan arkitektur.
Så det är här PostgreSQL 10 blir en game changer. Med dessa nya versioner 10 och 11 implementerar PostgreSQL inbyggd logisk replikering som, till skillnad från fysisk replikering, kan replikera mellan olika huvudversioner av PostgreSQL. Detta öppnar naturligtvis en ny dörr för uppgraderingsstrategier.
Låt oss i den här bloggen se hur vi kan uppgradera vår PostgreSQL 10 till PostgreSQL 11 med noll driftstopp med hjälp av logisk replikering. Först av allt, låt oss gå igenom en introduktion till logisk replikering.
Vad är logisk replikering?
Logisk replikering är en metod för att replikera dataobjekt och deras ändringar, baserat på deras replikeringsidentitet (vanligtvis en primärnyckel). Den är baserad på ett publicerings- och prenumerationsläge, där en eller flera prenumeranter prenumererar på en eller flera publikationer på en förlagsnod.
En publikation är en uppsättning ändringar som genereras från en tabell eller en grupp av tabeller (även kallad replikeringsuppsättning). Noden där en publikation definieras kallas utgivare. Ett abonnemang är nedströmssidan av logisk replikering. Noden där en prenumeration definieras kallas abonnenten, och den definierar kopplingen till en annan databas och uppsättning publikationer (en eller flera) som den vill prenumerera på. Prenumeranter hämtar data från de publikationer de prenumererar på.
Logisk replikering är byggd med en arkitektur som liknar fysisk strömmande replikering. Det implementeras av "walsender" och "apply" processer. Walsender-processen startar logisk avkodning av WAL och laddar standardinsticksprogrammet för logisk avkodning. Insticksprogrammet omvandlar ändringarna som läses från WAL till det logiska replikeringsprotokollet och filtrerar data enligt publikationsspecifikationen. Data överförs sedan kontinuerligt med hjälp av strömmande replikeringsprotokoll till appliceringsarbetaren, som mappar data till lokala tabeller och tillämpar de individuella ändringarna allt eftersom de tas emot, i en korrekt transaktionsordning.
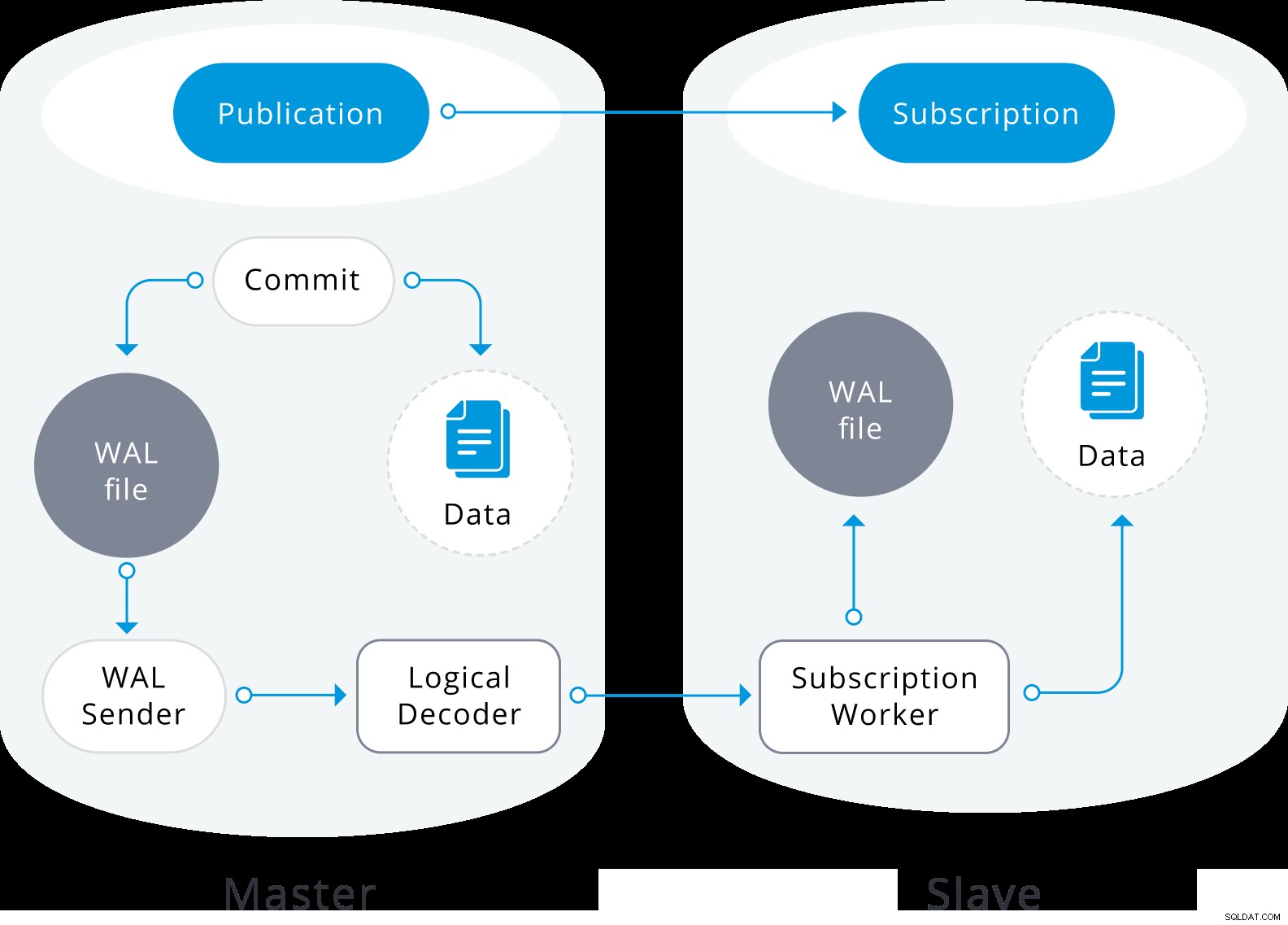 Logiskt replikeringsdiagram
Logiskt replikeringsdiagram Logisk replikering börjar med att ta en ögonblicksbild av data i utgivardatabasen och kopiera den till abonnenten. De initiala uppgifterna i de befintliga prenumererade tabellerna är ögonblicksbilder och kopieras i en parallell instans av en speciell typ av appliceringsprocess. Denna process kommer att skapa sin egen temporära replikeringsplats och kopiera befintliga data. När befintlig data har kopierats går arbetaren in i synkroniseringsläge, vilket säkerställer att tabellen förs upp till ett synkroniserat tillstånd med den huvudsakliga appliceringsprocessen genom att strömma alla ändringar som hände under den första datakopieringen med hjälp av standard logisk replikering. När synkroniseringen är gjord, återförs kontrollen av replikeringen av tabellen till huvudappliceringsprocessen där replikeringen fortsätter som vanligt. Ändringarna på utgivaren skickas till prenumeranten när de sker i realtid.
Du kan hitta mer om logisk replikering i följande bloggar:
- En översikt över logisk replikering i PostgreSQL
- PostgreSQL-strömmande replikering vs logisk replikering
Hur man uppgraderar PostgreSQL 10 till PostgreSQL 11 med logisk replikering
Så nu när vi vet vad den här nya funktionen handlar om kan vi fundera på hur vi kan använda den för att lösa uppgraderingsproblemet.
Vi kommer att konfigurera logisk replikering mellan två olika huvudversioner av PostgreSQL (10 och 11), och naturligtvis, efter att du har fått detta att fungera, är det bara en fråga om att utföra en applikationsfelövergång till databasen med den nyare versionen.
Vi kommer att utföra följande steg för att få logisk replikering att fungera:
- Konfigurera utgivarnoden
- Konfigurera prenumerantnoden
- Skapa prenumerantanvändaren
- Skapa en publikation
- Skapa tabellstrukturen i prenumeranten
- Skapa prenumerationen
- Kontrollera replikeringsstatusen
Så låt oss börja.
På utgivarsidan kommer vi att konfigurera följande parametrar i postgresql.conf-filen:
- lyssna_adresser:Vilka IP-adresser att lyssna på. Vi kommer att använda '*' för alla.
- wal_level:Bestämmer hur mycket information som skrivs till WAL. Vi kommer att ställa in den på logisk.
- max_replication_slots:Anger det maximala antalet replikeringsplatser som servern kan stödja. Den måste ställas in på minst det antal prenumerationer som förväntas ansluta, plus en viss reserv för tabellsynkronisering.
- max_wal_senders:Anger det maximala antalet samtidiga anslutningar från standby-servrar eller strömmande basbackupklienter. Den bör ställas in på minst samma som max_replication_slots plus antalet fysiska repliker som är anslutna samtidigt.
Tänk på att vissa av dessa parametrar krävde en omstart av PostgreSQL-tjänsten för att tillämpas.
Filen pg_hba.conf måste också justeras för att tillåta replikering. Vi måste tillåta replikeringsanvändaren att ansluta till databasen.
Så baserat på detta, låt oss konfigurera vår utgivare (i det här fallet vår PostgreSQL 10-server) enligt följande:
- postgresql.conf:
listen_addresses = '*' wal_level = logical max_wal_senders = 8 max_replication_slots = 4 - pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD host all rep 192.168.100.144/32 md5
Vi måste ändra användaren (i vårt exempel rep), som kommer att användas för replikering, och IP-adressen 192.168.100.144/32 för den IP som motsvarar vår PostgreSQL 11.
På abonnentsidan kräver det också att max_replication_slots ställs in. I det här fallet bör den ställas in på åtminstone antalet prenumerationer som kommer att läggas till abonnenten.
De andra parametrarna som också måste ställas in här är:
- max_logical_replication_workers:Anger det maximala antalet logiska replikeringsarbetare. Detta inkluderar både appliceringsarbetare och tabellsynkroniseringsarbetare. Logiska replikeringsarbetare tas från poolen som definieras av max_worker_processes. Den måste ställas in på åtminstone antalet prenumerationer, återigen plus en viss reserv för tabellsynkroniseringen.
- max_worker_processes:Anger det maximala antalet bakgrundsprocesser som systemet kan stödja. Den kan behöva justeras för att passa replikeringsarbetare, åtminstone max_logical_replication_workers + 1. Den här parametern kräver en PostgreSQL-omstart.
Så vi måste konfigurera vår prenumerant (i detta fall vår PostgreSQL 11-server) enligt följande:
- postgresql.conf:
listen_addresses = '*' max_replication_slots = 4 max_logical_replication_workers = 4 max_worker_processes = 8
Eftersom denna PostgreSQL 11 snart kommer att bli vår nya master bör vi överväga att lägga till parametrarna wal_level och archive_mode i detta steg för att undvika en ny omstart av tjänsten senare.
wal_level = logical
archive_mode = onDessa parametrar kommer att vara användbara om vi vill lägga till en ny replikeringsslav eller för att använda PITR-säkerhetskopior.
I förlaget måste vi skapa användaren som vår prenumerant kommer att ansluta till:
world=# CREATE ROLE rep WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLERollen som används för replikeringsanslutningen måste ha attributet REPLIKATION. Åtkomst för rollen måste konfigureras i pg_hba.conf och den måste ha LOGIN-attributet.
För att kunna kopiera den initiala datan måste rollen som används för replikeringsanslutningen ha SELECT-behörigheten på en publicerad tabell.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep;
GRANTVi skapar publicering pub1 i utgivarnoden, för alla tabeller:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONAnvändaren som ska skapa en publikation måste ha CREATE-privilegiet i databasen, men för att skapa en publikation som publicerar alla tabeller automatiskt måste användaren vara en superanvändare.
För att bekräfta den skapade publikationen kommer vi att använda katalogen pg_publication. Denna katalog innehåller information om alla publikationer som skapats i databasen.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+------
pubname | pub1
pubowner | 16384
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | tKolumnbeskrivningar:
- Pubname:Namn på publikationen.
- Pubägare:Ägaren till publikationen.
- puballtables:Om sant, inkluderar denna publikation automatiskt alla tabeller i databasen, inklusive alla som kommer att skapas i framtiden.
- pubinsert:Om sant, replikeras INSERT-operationer för tabeller i publikationen.
- pubupdate:Om sant, replikeras UPDATE-operationer för tabeller i publikationen.
- pubdelete:Om sant, replikeras DELETE-operationerna för tabeller i publikationen.
Eftersom schemat inte är replikerat måste vi ta en säkerhetskopia i PostgreSQL 10 och återställa den i vår PostgreSQL 11. Säkerhetskopieringen kommer endast att tas för schemat, eftersom informationen kommer att replikeras i den första överföringen.
I PostgreSQL 10:
$ pg_dumpall -s > schema.sqlI PostgreSQL 11:
$ psql -d postgres -f schema.sqlNär vi väl har vårt schema i PostgreSQL 11 skapar vi prenumerationen och ersätter värdena för värd, dbname, användare och lösenord med de som motsvarar vår miljö.
PostgreSQL 11:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=192.168.100.143 dbname=world user=rep password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONOvanstående startar replikeringsprocessen, som synkroniserar det ursprungliga tabellinnehållet i tabellerna i publikationen och sedan börjar replikera inkrementella ändringar av dessa tabeller.
Användaren som skapar en prenumeration måste vara en superanvändare. Ansökningsprocessen för prenumeration kommer att köras i den lokala databasen med privilegier som en superanvändare.
För att verifiera den skapade prenumerationen kan vi använda then pg_stat_subscription katalog. Den här vyn kommer att innehålla en rad per prenumeration för huvudarbetaren (med null PID om arbetaren inte körs), och ytterligare rader för arbetare som hanterar den initiala datakopian av de prenumererade tabellerna.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16428
subname | sub1
pid | 1111
relid |
received_lsn | 0/172AF90
last_msg_send_time | 2018-12-05 22:11:45.195963+00
last_msg_receipt_time | 2018-12-05 22:11:45.196065+00
latest_end_lsn | 0/172AF90
latest_end_time | 2018-12-05 22:11:45.195963+00Kolumnbeskrivningar:
- subid:OID för prenumerationen.
- undernamn:Namn på prenumerationen.
- pid:Process-ID för prenumerationsarbetarprocessen.
- relid:OID för relationen som arbetaren synkroniserar; null för huvudarbetaren.
- received_lsn:Senaste framskrivningsloggplats mottagen, startvärdet för detta fält är 0.
- last_msg_send_time:Skicka tidpunkten för det senaste meddelandet mottaget från ursprungs-WAL-avsändaren.
- last_msg_receipt_time:Mottagningstidpunkt för det senaste meddelandet mottaget från ursprungs-WAL-avsändaren.
- latest_end_lsn:Senaste framskrivningsloggplatsen rapporterades till ursprunglig WAL-avsändare.
- latest_end_time:Tidpunkten för den senaste loggplatsen för att skriva framåt rapporterade till ursprungs-WAL-avsändaren.
För att verifiera statusen för replikering i mastern kan vi använda pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 1178
usesysid | 16427
usename | rep
application_name | sub1
client_addr | 192.168.100.144
client_hostname |
client_port | 58270
backend_start | 2018-12-05 22:11:45.097539+00
backend_xmin |
state | streaming
sent_lsn | 0/172AF90
write_lsn | 0/172AF90
flush_lsn | 0/172AF90
replay_lsn | 0/172AF90
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncKolumnbeskrivningar:
- pid:Process-ID för en WAL-avsändarprocess.
- usesysid:OID för användaren som loggat in på denna WAL-avsändarprocess.
- användarnamn:Namnet på användaren som loggat in på denna WAL-avsändarprocess.
- application_name:Namnet på programmet som är anslutet till denna WAL-avsändare.
- client_addr:IP-adressen för klienten som är ansluten till denna WAL-avsändare. Om det här fältet är null indikerar det att klienten är ansluten via en Unix-socket på servermaskinen.
- client_hostname:Värdnamn för den anslutna klienten, som rapporterats av en omvänd DNS-sökning av client_addr. Det här fältet kommer endast att vara icke-null för IP-anslutningar och endast när log_hostname är aktiverat.
- client_port:TCP-portnummer som klienten använder för kommunikation med denna WAL-avsändare, eller -1 om en Unix-socket används.
- backend_start:Tid då denna process startade.
- backend_xmin:Detta vänteläges xmin-horisont rapporteras av hot_standby_feedback.
- tillstånd:Aktuellt WAL-avsändarläge. De möjliga värdena är:start, catchup, streaming, backup och stopping.
- sent_lsn:Senaste förskrivningsloggplats skickad på den här anslutningen.
- write_lsn:Senast skriv-ahead-loggplats som skrevs till disken av denna standby-server.
- flush_lsn:Senast skriv-ahead-loggplats rensades till disken av denna standby-server.
- replay_lsn:Senaste framskrivningsloggplatsen spelades om i databasen på denna standby-server.
- write_lag:Tid som förflutit mellan att den senaste WAL tömdes lokalt och att man fick ett meddelande om att denna standby-server har skrivit det (men ännu inte tömt det eller tillämpat det).
- flush_lag:Tid som förflutit från att den senaste WAL tömdes lokalt och mottagande av meddelande om att denna standby-server har skrivit och tömt den (men ännu inte tillämpat den).
- replay_lag:Tid som förflutit från det att senaste WAL tömdes lokalt och mottagande av meddelande om att denna standby-server har skrivit, tömt och tillämpat den.
- sync_priority:Prioritet för denna standby-server för att väljas som synkron standby i en prioritetsbaserad synkron replikering.
- sync_state:Synkront tillstånd för denna standby-server. De möjliga värdena är async, potential, sync, quorum.
För att verifiera när den första överföringen är klar kan vi se PostgreSQL-loggen på abonnenten:
2018-12-05 22:11:45.096 UTC [1111] LOG: logical replication apply worker for subscription "sub1" has started
2018-12-05 22:11:45.103 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2018-12-05 22:11:45.114 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2018-12-05 22:11:45.156 UTC [1112] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2018-12-05 22:11:45.162 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2018-12-05 22:11:45.168 UTC [1113] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2018-12-05 22:11:45.206 UTC [1114] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedEller kontrollera variabeln srsubstate i katalogen pg_subscription_rel. Den här katalogen innehåller tillståndet för varje replikerad relation i varje prenumeration.
world=# SELECT * FROM pg_subscription_rel;
-[ RECORD 1 ]---------
srsubid | 16428
srrelid | 16387
srsubstate | r
srsublsn | 0/172AF20
-[ RECORD 2 ]---------
srsubid | 16428
srrelid | 16393
srsubstate | r
srsublsn | 0/172AF58
-[ RECORD 3 ]---------
srsubid | 16428
srrelid | 16400
srsubstate | r
srsublsn | 0/172AF90Kolumnbeskrivningar:
- srsubid:Referens till prenumeration.
- srrelid:Referens till relation.
- srsubstate:Tillståndskod:i =initialisera, d =data kopieras, s =synkroniserad, r =klar (normal replikering).
- srsublsn:Avsluta LSN för s- och r-tillstånd.
Vi kan infoga några testposter i vår PostgreSQL 10 och validera att vi har dem i vår PostgreSQL 11:
PostgreSQL 10:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 11:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)Vid det här laget har vi allt redo för att peka vår applikation till vår PostgreSQL 11.
För detta måste vi först och främst bekräfta att vi inte har replikeringsfördröjning.
På mastern:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0Och nu behöver vi bara ändra vår slutpunkt från vår applikation eller lastbalanserare (om vi har en) till den nya PostgreSQL 11-servern.
Om vi har en lastbalanserare som HAProxy kan vi konfigurera den med PostgreSQL 10 som aktiv och PostgreSQL 11 som backup, på detta sätt:
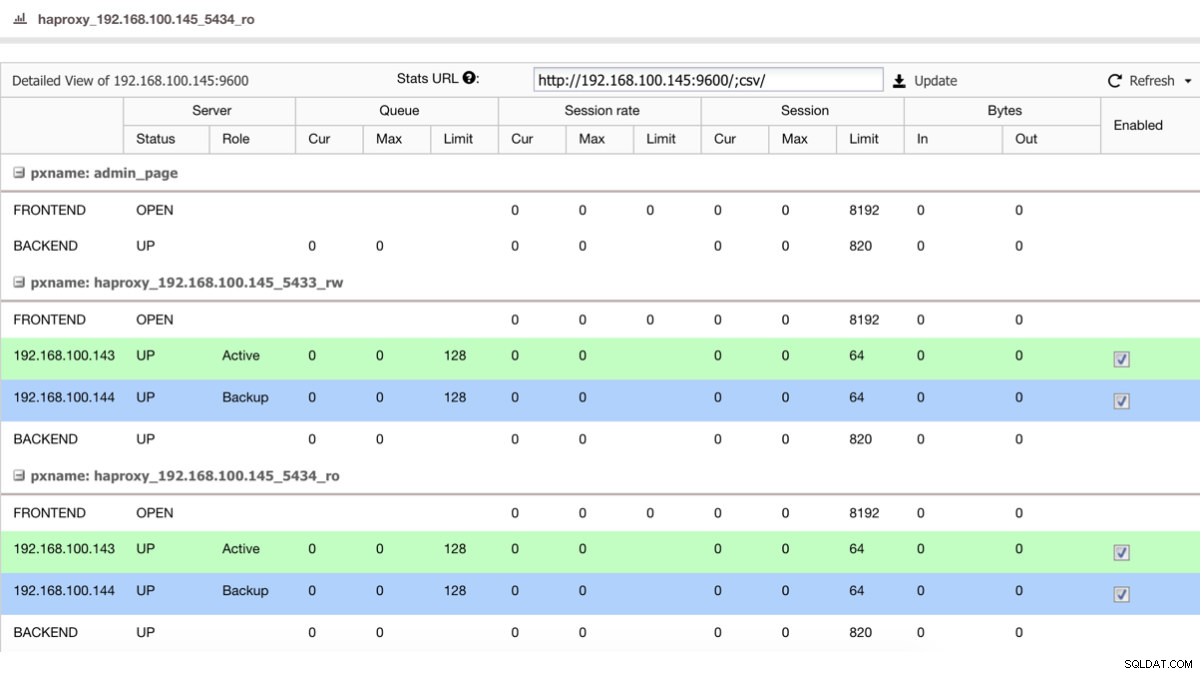 HAProxy Status View
HAProxy Status View Så om du bara stänger av mastern i PostgreSQL 10, börjar backupservern, i detta fall i PostgreSQL 11, ta emot trafiken på ett transparent sätt för användaren/applikationen.
I slutet av migreringen kan vi ta bort prenumerationen i vår nya master i PostgreSQL 11:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONOch kontrollera att den har tagits bort korrekt:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Begränsningar
Innan du använder den logiska replikeringen, tänk på följande begränsningar:
- Databasschemat och DDL-kommandon replikeras inte. Det initiala schemat kan kopieras med pg_dump --schema-only.
- Sekvensdata replikeras inte. Data i serie- eller identitetskolumner som backas upp av sekvenser kommer att replikeras som en del av tabellen, men själva sekvensen skulle fortfarande visa startvärdet på abonnenten.
- Replikering av TRUNCATE-kommandon stöds, men viss försiktighet måste iakttas vid trunkering av grupper av tabeller som är anslutna med främmande nycklar. Vid replikering av en trunkeringsåtgärd kommer abonnenten att trunkera samma grupp av tabeller som trunkerades på utgivaren, antingen explicit specificerat eller implicit insamlat via CASCADE, minus tabeller som inte är en del av prenumerationen. Detta kommer att fungera korrekt om alla berörda tabeller är en del av samma prenumeration. Men om några tabeller som ska trunkeras på abonnenten har främmande nyckellänkar till tabeller som inte är en del av samma (eller någon) prenumeration, kommer tillämpningen av trunkeringsåtgärden på abonnenten att misslyckas.
- Stora objekt replikeras inte. Det finns ingen lösning för det, annat än att lagra data i vanliga tabeller.
- Replikering är endast möjlig från bastabeller till bastabeller. Det vill säga att tabellerna på publikationen och på prenumerationssidan måste vara normala tabeller, inte vyer, materialiserade vyer, partitionsrottabeller eller främmande tabeller. När det gäller partitioner kan du replikera en partitionshierarki en-till-en, men du kan för närvarande inte replikera till en annan partitionerad inställning.
Slutsats
Att hålla din PostgreSQL-server uppdaterad genom att utföra regelbundna uppgraderingar har varit en nödvändig men svår uppgift fram till PostgreSQL 10-versionen.
I den här bloggen gjorde vi en kort introduktion till logisk replikering, en PostgreSQL-funktion som introducerades i version 10, och vi har visat dig hur den kan hjälpa dig att klara den här utmaningen med en strategi utan driftstopp.