Python är väldigt populärt nu för tiden. Eftersom Python är ett allmänt programmeringsspråk kan det också användas för att utföra ETL-processen (Extract, Transform, Load). Olika ETL-moduler finns tillgängliga, men idag kommer vi att hålla fast vid kombinationen av Python och MySQL. Vi kommer att använda Python för att anropa lagrade procedurer och förbereda och köra SQL-satser.
Vi kommer att använda två liknande men olika tillvägagångssätt. Först kommer vi att anropa lagrade procedurer som kommer att göra hela jobbet, och efter det kommer vi att analysera hur vi kan göra samma process utan lagrade procedurer genom att använda MySQL-kod i Python.
Redo? Innan vi gräver in, låt oss titta på datamodellen – eller datamodellerna, eftersom det finns två av dem i den här artikeln.
Datamodellerna
Vi behöver två datamodeller, en för att lagra vår verksamhetsdata och den andra för att lagra vår rapportdata.
Den första modellen visas på bilden ovan. Denna modell används för att lagra operativa (live)data för en prenumerationsbaserad verksamhet. För mer inblick i den här modellen, vänligen ta en titt på vår tidigare artikel, Skapa en DWH, del ett:A Subscription Business Data Model.
Att separera drifts- och rapporteringsdata är vanligtvis ett mycket klokt beslut. För att uppnå den separationen måste vi skapa ett datalager (DWH). Det har vi redan gjort; du kan se modellen på bilden ovan. Denna modell beskrivs också i detalj i inlägget Skapa en DWH, del två:En affärsdatamodell för prenumeration.
Slutligen måste vi extrahera data från livedatabasen, omvandla den och ladda in den i vår DWH. Vi har redan gjort detta med SQL-lagrade procedurer. Du kan hitta en beskrivning av vad vi vill uppnå tillsammans med några kodexempel i Skapa ett datalager, del 3:En prenumerationsaffärsdatamodell.
Om du behöver ytterligare information om DWH rekommenderar vi att du läser dessa artiklar:
- Stjärnschemat
- Snöflingaschemat
- Stjärnschema vs. Snowflake Schema.
Vår uppgift idag är att ersätta SQL-lagrade procedurer med Python-kod. Vi är redo att göra lite Python-magi. Låt oss börja med att endast använda lagrade procedurer i Python.
Metod 1:ETL med hjälp av lagrade procedurer
Innan vi börjar beskriva processen är det viktigt att nämna att vi har två databaser på vår server.
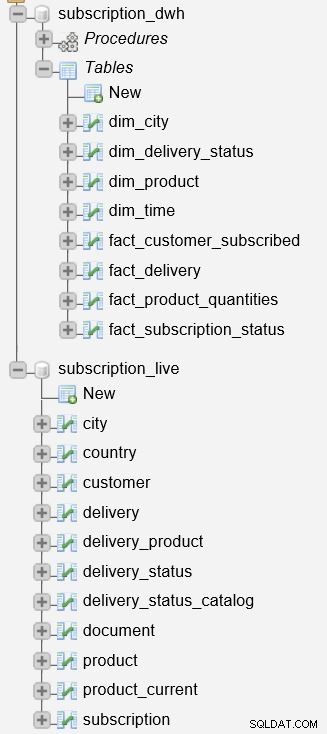
subscription_live databasen används för att lagra transaktions-/livedata, medan subscription_dwh är vår rapporteringsdatabas (DWH).
Vi har redan beskrivit de lagrade procedurerna som används för att uppdatera dimensions- och faktatabeller. De kommer att läsa data från subscription_live databas, kombinera den med data i subscription_dwh databas och infoga ny data i subscription_dwh databas. Dessa två procedurer är:
p_update_dimensions– Uppdaterar dimensionstabellernadim_timeochdim_city.p_update_facts– Uppdaterar två faktatabeller,fact_customer_subscribedochfact_subscription_status.
Om du vill se den fullständiga koden för dessa procedurer, läs Skapa ett datalager, del 3:En affärsdatamodell för prenumeration.
Nu är vi redo att skriva ett enkelt Python-skript som kommer att ansluta till servern och utföra ETL-processen. Låt oss först ta en titt på hela skriptet (etl_procedures.py ). Sedan ska vi förklara de viktigaste delarna.
# import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor() # I update dimensions cursor.callproc('subscription_dwh.p_update_dimensions') print('Dimension tables updated.') # II update facts cursor.callproc('subscription_dwh.p_update_facts') print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_procedures.py
Importera moduler och ansluta till databasen
Python använder moduler för att lagra definitioner och uttalanden. Du kan använda en befintlig modul eller skriva din egen. Att använda befintliga moduler kommer att förenkla ditt liv eftersom du använder förskriven kod, men att skriva din egen modul är också mycket användbart. När du avslutar Python-tolken och kör den igen, kommer du att förlora funktioner och variabler som du tidigare har definierat. Naturligtvis vill du inte skriva samma kod om och om igen. För att undvika det kan du lagra dina definitioner i en modul och importera den till Python.
Tillbaka till etl_procedures.py . I vårt program börjar vi med att importera MySQL Connector:
# import MySQL connector import mysql.connector
MySQL Connector för Python används som en standardiserad drivrutin som ansluter till en MySQL-server/databas. Du måste ladda ner den och installera den om du inte har gjort det tidigare. Förutom att ansluta till databasen, erbjuder den ett antal metoder och egenskaper för att arbeta med en databas. Vi kommer att använda några av dem, men du kan kontrollera hela dokumentationen här.
Därefter måste vi ansluta till vår databas:
# connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') cursor = connection.cursor()
Den första raden ansluter till en server (i det här fallet ansluter jag till min lokala dator) med dina referenser (ersätt
connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1', database=' ')
Jag har avsiktligt bara anslutit till en server och inte till en specifik databas eftersom jag kommer att använda två databaser på samma server.
Nästa kommando – print – är här bara ett meddelande om att vi lyckades ansluta. Även om det inte har någon programmeringsbetydelse, kan det användas för att felsöka koden om något gick fel i skriptet.
Den sista raden i denna del är:
cursor =connection.cursor()
Cursors are the handler structure used to work with the data. We’ll use them for retrieving data from the database (SELECT), but also to modify the data (INSERT, UPDATE, DELETE). Before using a cursor, we need to create it. And that is what this line does.
Anropsprocedurer
Den föregående delen var generell och kunde användas för andra databasrelaterade uppgifter. Följande del av koden är specifikt för ETL:anropa våra lagrade procedurer med cursor.callproc kommando. Det ser ut så här:
# 1. update dimensions
cursor.callproc('subscription_dwh.p_update_dimensions')
print('Dimension tables updated.')
# 2. update facts
cursor.callproc('subscription_dwh.p_update_facts')
print('Fact tables updated.')
Anropsprocedurer är ganska självförklarande. Efter varje samtal lades ett utskriftskommando till. Återigen, detta ger oss bara ett meddelande om att allt gick okej.
Bekräfta och stäng
Den sista delen av skriptet genomför databasändringarna och stänger alla använda objekt:
# commit & close connection
cursor.close()
connection.commit()
connection.close()
print('Disconnected from database.')
Anropsprocedurer är ganska självförklarande. Efter varje samtal lades ett utskriftskommando till. Återigen, detta ger oss bara ett meddelande om att allt gick okej.
Att engagera sig är viktigt här; utan det kommer det inte att göras några ändringar i databasen, även om du anropade en procedur eller körde en SQL-sats.
Köra skriptet
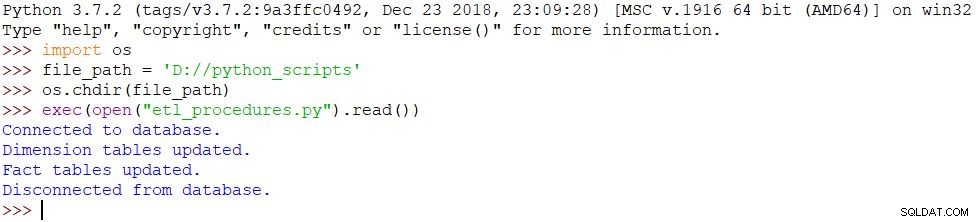
Det sista vi behöver göra är att köra vårt skript. Vi kommer att använda följande kommandon i Python Shell för att uppnå det:
import osfile_path ='D://python_scripts'os.chdir(file_path)exec(open("etl_procedures.py").read())Skriptet exekveras och alla ändringar görs i databasen i enlighet därmed. Resultatet kan ses på bilden nedan.
Metod 2:ETL med Python och MySQL
Metoden som presenteras ovan skiljer sig inte mycket från metoden att anropa lagrade procedurer direkt i MySQL. Den enda skillnaden är att nu har vi ett manus som kommer att göra hela jobbet åt oss.
Vi skulle kunna använda ett annat tillvägagångssätt:att lägga allt i Python-skriptet. Vi kommer att inkludera Python-satser, men vi kommer också att förbereda SQL-frågor och köra dem i databasen. Källdatabasen (live) och destinationsdatabasen (DWH) är desamma som i exemplet med lagrade procedurer.
Innan vi går in i det här, låt oss ta en titt på det fullständiga skriptet (etl_queries.py ):
from datetime import date # import MySQL connector import mysql.connector # connect to server connection = mysql.connector.connect(user='', password=' ', host='127.0.0.1') print('Connected to database.') # 1. update dimensions # 1.1 update dim_time # date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"' # test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) result = cursor.fetchall() yesterday_subscription_count = int(result[0][0]) if yesterday_subscription_count == 0: yesterday_year = 'YEAR("' + str(yesterday) + '")' yesterday_month = 'MONTH("' + str(yesterday) + '")' yesterday_week = 'WEEK("' + str(yesterday) + '")' yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")' query = ( "INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) " " VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())") cursor.execute(query) # 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query) print('Dimension tables updated.') # 2. update facts # 2.1 update customers subscribed # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_customer_subscribed`.* " "FROM subscription_dwh.`fact_customer_subscribed` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_customer_subscribed`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_customer_subscribed`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " " SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN customer_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN customer_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN customer_live.active = 1 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN customer_live.active = 0 AND DATE(customer_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) # 2.2 update subscription statuses # delete old data for the same date query = ( "DELETE subscription_dwh.`fact_subscription_status`.* " "FROM subscription_dwh.`fact_subscription_status` " "INNER JOIN subscription_dwh.`dim_time` ON subscription_dwh.`fact_subscription_status`.`dim_time_id` = subscription_dwh.`dim_time`.`id` " "WHERE subscription_dwh.`dim_time`.`time_date` = " + yesterday_str) cursor.execute(query) # insert new data query = ( "INSERT INTO subscription_dwh.`fact_subscription_status`(`dim_city_id`, `dim_time_id`, `total_active`, `total_inactive`, `daily_new`, `daily_canceled`, `ts`) " "SELECT city_dwh.id AS dim_ctiy_id, time_dwh.id AS dim_time_id, SUM(CASE WHEN subscription_live.active = 1 THEN 1 ELSE 0 END) AS total_active, SUM(CASE WHEN subscription_live.active = 0 THEN 1 ELSE 0 END) AS total_inactive, SUM(CASE WHEN subscription_live.active = 1 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_new, SUM(CASE WHEN subscription_live.active = 0 AND DATE(subscription_live.time_updated) = @time_date THEN 1 ELSE 0 END) AS daily_canceled, MIN(NOW()) AS ts " "FROM subscription_live.`customer` customer_live " "INNER JOIN subscription_live.`subscription` subscription_live ON subscription_live.customer_id = customer_live.id " "INNER JOIN subscription_live.`city` city_live ON customer_live.city_id = city_live.id " "INNER JOIN subscription_live.`country` country_live ON city_live.country_id = country_live.id " "INNER JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "INNER JOIN subscription_dwh.dim_time time_dwh ON time_dwh.time_date = " + yesterday_str + " " "GROUP BY city_dwh.id, time_dwh.id") cursor.execute(query) print('Fact tables updated.') # commit & close connection cursor.close() connection.commit() connection.close() print('Disconnected from database.')
etl_queries.py
Importera moduler och ansluta till databasen
Återigen måste vi importera MySQL med följande kod:
import mysql.connector
Vi importerar även datetime-modulen, som visas nedan. Vi behöver detta för datumrelaterade operationer i Python:
from datetime import date
Processen för att ansluta till databasen är densamma som i föregående exempel.
Uppdatera dimensionen dim_time
För att uppdatera dim_time tabell måste vi kontrollera om värdet (för gårdagen) redan finns i tabellen. Vi måste använda Pythons datumfunktioner (istället för SQL) för att göra detta:
# date - yesterday yesterday = date.fromordinal(date.today().toordinal()-1) yesterday_str = '"' + str(yesterday) + '"'
Den första kodraden returnerar gårdagens datum i datumvariabeln, medan den andra raden lagrar detta värde som en sträng. Vi behöver detta som en sträng eftersom vi kommer att sammanfoga den med en annan sträng när vi bygger SQL-frågan.
Därefter måste vi testa om detta datum redan är i dim_time tabell. Efter att ha deklarerat en markör förbereder vi SQL-frågan. För att köra frågan använder vi cursor.execute kommando:
# test if date is already in the table cursor = connection.cursor() query = ( "SELECT COUNT(*) " "FROM subscription_dwh.dim_time " "WHERE time_date = " + yesterday_str) cursor.execute(query) '"'
Vi lagrar frågeresultatet i resultatet variabel. Resultatet kommer att ha antingen 0 eller 1 rader, så vi kan testa den första kolumnen i den första raden. Den kommer att innehålla antingen en 0 eller en 1. (Kom ihåg att vi bara kan ha samma datum en gång i en dimensionstabell.)
Om datumet inte redan finns i tabellen, förbereder vi strängarna som kommer att ingå i SQL-frågan:
result = cursor.fetchall()
yesterday_subscription_count = int(result[0][0])
if yesterday_subscription_count == 0:
yesterday_year = 'YEAR("' + str(yesterday) + '")'
yesterday_month = 'MONTH("' + str(yesterday) + '")'
yesterday_week = 'WEEK("' + str(yesterday) + '")'
yesterday_weekday = 'WEEKDAY("' + str(yesterday) + '")'
Slutligen bygger vi en fråga och kör den. Detta kommer att uppdatera dim_time tabell efter att den har begåtts. Observera att jag har använt hela sökvägen till tabellen, inklusive databasnamnet (subscription_dwh ).
query = (
"INSERT INTO subscription_dwh.`dim_time`(`time_date`, `time_year`, `time_month`, `time_week`, `time_weekday`, `ts`) "
" VALUES (" + yesterday_str + ", " + yesterday_year + ", " + yesterday_month + ", " + yesterday_week + ", " + yesterday_weekday + ", Now())")
cursor.execute(query)
Uppdatera dimensionen dim_city
Uppdaterar dim_city tabellen är ännu enklare eftersom vi inte behöver testa någonting innan insättningen. Vi kommer faktiskt att inkludera det testet i SQL-frågan.
# 1.2 update dim_city query = ( "INSERT INTO subscription_dwh.`dim_city`(`city_name`, `postal_code`, `country_name`, `ts`) " "SELECT city_live.city_name, city_live.postal_code, country_live.country_name, Now() " "FROM subscription_live.city city_live " "INNER JOIN subscription_live.country country_live ON city_live.country_id = country_live.id " "LEFT JOIN subscription_dwh.dim_city city_dwh ON city_live.city_name = city_dwh.city_name AND city_live.postal_code = city_dwh.postal_code AND country_live.country_name = city_dwh.country_name " "WHERE city_dwh.id IS NULL") cursor.execute(query)
Här förbereder vi en exekvering av SQL-frågan. Lägg märke till att jag återigen har använt de fullständiga sökvägarna till tabeller, inklusive namnen på båda databaserna (subscription_live och subscription_dwh ).
Uppdatera faktatabellerna
Det sista vi behöver göra är att uppdatera våra faktatabeller. Processen är nästan densamma som att uppdatera dimensionstabeller:vi förbereder frågor och kör dem. Dessa frågor är mycket mer komplexa, men de är desamma som de som används i de lagrade procedurerna.
Vi har lagt till en förbättring jämfört med de lagrade procedurerna:ta bort befintlig data för samma datum i faktatabellen. Detta gör att vi kan köra ett skript flera gånger för samma datum. I slutet måste vi genomföra transaktionen och stänga alla objekt och anslutningen.
Köra skriptet
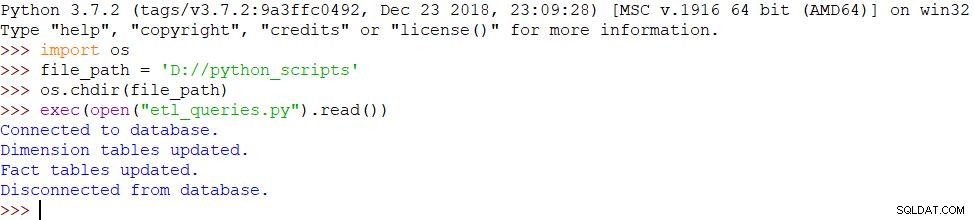
Vi har en mindre förändring i den här delen, som kallar ett annat skript:
- import os
- file_path = 'D://python_scripts'
- os.chdir(file_path)
- exec(open("etl_queries.py").read())
Eftersom vi har använt samma meddelanden och skriptet slutförts framgångsrikt, är resultatet detsamma:
Hur skulle du använda Python i ETL?
Idag såg vi ett exempel på att utföra ETL-processen med ett Python-skript. Det finns andra sätt att göra detta, t.ex. ett antal open source-lösningar som använder Python-bibliotek för att arbeta med databaser och utföra ETL-processen. I nästa artikel kommer vi att leka med en av dem. Under tiden får du gärna dela din upplevelse med Python och ETL.