Replikering är delning av transaktionsdata över flera servrar för att säkerställa överensstämmelse mellan redundanta databasnoder. En master kommer att ta inlägg eller uppdateringar och tillämpa dem på sin datamängd, medan slavarna kommer att ändra sina data i enlighet med de ändringar som gjorts i masterdatauppsättningen. Mastern kallas vanligen för en primär och den registrerar ändringarna som görs i en Write Ahead Log (WAL). Å andra sidan hänvisas slavar till som sekundära och de replikerar sina data från REDO-loggarna - i det här fallet WAL.
Det finns minst 3 replikeringssätt i PostgreSQL:
Inbyggd replikering eller strömmande replikering.
I detta tillvägagångssätt replikeras data från den primära noden till den sekundära noden. Det kommer dock med ett antal bakslag som är:
- Svårigheter med att introducera en ny sekundär. Det kommer att kräva att du replikerar hela tillståndet, vilket kan vara resurskrävande.
- Brist på inbyggd övervakning och failover. En sekundär måste befordras till en primär i händelse av det senare misslyckandet. Ofta kan denna kampanj resultera i datainkonsekvens under primärens frånvaro.
Rekonstruerar från WAL
Det här tillvägagångssättet använder sig på något sätt av streaming-replikeringsmetoden eftersom sekundärerna rekonstrueras från en säkerhetskopia gjord av den primära. Den primära gör en fullständig säkerhetskopiering av databasen efter varje dag, förutom en inkrementell säkerhetskopiering var 60:e sekund. Fördelen med detta tillvägagångssätt är att ingen extra belastning utsätts för primären förrän sekundärerna är tillräckligt nära primären så att de börjar streama Write Ahead Log (WAL) för att hinna med den. Med detta tillvägagångssätt kan du lägga till eller ta bort repliker utan att påverka prestandan för din PostgreSQL-databas.
Volymnivåreplikering för PostgreSQL (Disk Mirroring)
Detta är ett generiskt tillvägagångssätt som inte bara gäller PostgreSQL, utan även alla relationsdatabaser. Vi kommer att använda oss av Distributed Replicated Block Device (DRBD), ett distribuerat replikerat lagringssystem för Linux. Det är tänkt att fungera genom att spegla innehållet som är lagrat i en servers lagring till en annan. En enkel illustration av strukturen visas nedan.
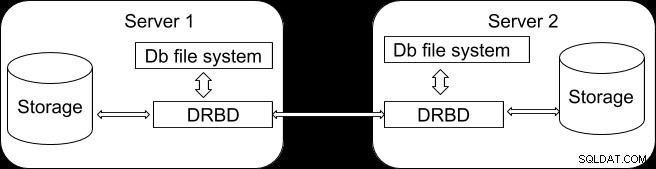
DRBD kan betraktas som en abstraktion från diskenheten som är värd för PostgreSQL-databasen, men operativsystemet kommer aldrig att veta att dess data också finns på en annan server. Med detta tillvägagångssätt kan du inte bara dela data utan även filsystemet till mer än 1 server. Skrivningar till DRBD distribueras därför bland alla servrar varvid varje server kommer att skriva information till en lokal fysisk hårddisk (blockenhet). När en skrivoperation appliceras på den primära, registreras den därefter till DRBD och distribueras sedan till de sekundära DRBD-servrarna. Å andra sidan, om sekundären tar emot skrivoperationerna genom DRBD, skrivs de sedan till den lokala fysiska enheten. Vid failover-stöd ger DRBD hög tillgänglighet av data eftersom informationen delas mellan en primär och många sekundära noder som är radade synkront på blocknivå.
DRBD-konfigurationen skulle kräva en extra resurs känd som Heartbeat, som vi kommer att diskutera i en annan artikel, för att förbättra stödet för automatisk failover. Paketet hanterar i princip gränssnittet på de flera servrarna och konfigurerar automatiskt en av de sekundära servrarna till primär i händelse av fel.
Installation och konfiguration av DRBD
Den föredragna metoden för att installera DRBD är att använda de förbyggda binära installationspaketen. Se till att kärnversionen av paketen matchar din aktiva nuvarande kärna.
Konfigurationsfilerna för alla noder som är primära eller sekundära bör vara identiska. Om det också är nödvändigt för dig att uppgradera din kärnversion, se till att motsvarande kernel-module-drdb är tillgänglig för din nya kärnversion.
DRBD-inställningar för primär nod
Detta är det första steget där du måste skapa en DRBD-blockenhet och ett filsystem med vilket du kan lagra dina data. Konfigurationsfilen finns på /etc/drbd.conf. Filen definierar ett antal parametrar för DRBD-konfigurationen som inkluderar:blockstorlekar, säkerhetsinformationsdefinition för de DRBD-enheter som du vill skapa och uppdateringsfrekvens. Konfigurationerna kan begränsas till att vara globala eller knutna till en viss resurs. De inblandade stegen är:
-
Synkroniseringshastighet som definierar hastigheten med vilken enheter länkas synkront i bakgrunden efter ett diskbyte, ett fel eller en initial installation. Detta kan ställas in genom att redigera hastighetsparametern i syncerblocket:
syncer{ rate 15M } -
Autentiseringsinställning för att säkerställa att endast värdar med samma delade hemlighet kan gå med i DRBD-nodgruppen. Lösenordet är en hash-utbytesmekanism som stöds i DRBD.
cram-hmac-alg “sha1” shared-secret “hash-password-string” -
Konfigurera värdinformation. Nodinformationen såsom värden finns i var och en av nodernas drbd.conf-fil. Några av parametrarna som ska konfigureras är:
- Adress:IP-adress och portnummer för värden som har DRBD-enheten.
- Enhet:Sökvägen till den logiska blockeringsenheten som skapats av DRBD.
- Disk:Det hänvisar till blockeringsenheten som lagrar data.
- Meta-disk:Den lagrar metadata för DRBD-enheten. Dess storlek kan vara upp till 128MB. Du kan ställa in den som den interna disken så att DRBD använder fysisk blockeringsenhet för att lagra denna information i de sista delarna av disken.
En enkel konfiguration för den primära:
on drbd-one { device /dev/drbd0; disk /dev/sdd1; address 192.168.103.40:8080; meta-disk internal; }Konfigurationen måste upprepas med sekundärerna med IP-adressen som matchar dess korrespondentvärd.
on drbd-two { device /dev/drbd0; disk /dev/sdd1; address 192.168.103.41:8080; meta-disk internal; } -
Skapa metadata för enheterna med detta kommando:
Denna process är obligatorisk innan du startar den primära noden.$ drbdadm create create-md all - Starta DRBD med detta kommando:
Detta gör det möjligt för DRBD att starta, initiera och skapa de DRBD-definierade enheterna.$ /etc/init.d/drbd start - Markera den nya enheten som primär och initiera enheten med detta kommando:
Skapa ett filsystem på blockeringsenheten för att göra en standardblockenhet skapad av DRBD användbar.$ drbdadm -- --overwrite-data-of-peer primary all - Gör den primära redo för användning genom att montera filsystemet. Dessa kommandon bör förbereda det åt dig:
$ mkdir /mnt/drbd $ mount /dev/drbd0 /mnt/drbd $ echo “DRBD Device” > /mnt/drbd/example_file
DRBD-inställning för den sekundära noden
Du kan använda samma steg ovan förutom att skapa filsystemet på en sekundär nod eftersom informationen automatiskt överförs från den primära noden.
-
Kopiera filen /etc/drbd.conf från den primära noden till den sekundära noden. Den här filen innehåller den information och den konfiguration som behövs.
-
Skapa DRBD-metadata på den underliggande diskenheten med kommandot:
$ drbdadm create-md all -
Starta DRBD med kommandot:
DRBD kommer att börja kopiera data från den primära noden till den sekundära noden, och tiden beror på storleken på data som ska överföras. Om du tittar på filen /proc/drbd kan du se framstegen.$ /etc/init.d/drbd start$ cat /proc/drbd version: 8.0.0 (api:80/proto:80) SVN Revision: 2947 build by example@sqldat.com, 2018-08-24 16:43:05 0: cs:SyncSource st:Primary/Secondary ds:UpToDate/Inconsistent C r--- ns:252284 nr:0 dw:0 dr:257280 al:0 bm:15 lo:0 pe:7 ua:157 ap:0 [==>.................] sync'ed: 12.3% (1845088/2097152)K finish: 0:06:06 speed: 4,972 (4,580) K/sec resync: used:1/31 hits:15901 misses:16 starving:0 dirty:0 changed:16 act_log: used:0/257 hits:0 misses:0 starving:0 dirty:0 changed:0 -
Övervaka synkroniseringen med hjälp av bevakningskommandot vid specifika intervall
$ watch -n 10 ‘cat /proc/drbd‘
DRBD-installationshantering
För att hålla reda på DRBD-enhetens status använder vi /proc/drbd.
Du kan ställa in tillståndet för alla lokala enheter att vara primärt med kommandot
$ drbdadm primary allGör en primär enhet sekundär
$ drbdadm secondary allFör att koppla bort DRBD-noder
$ drbdadm disconnect allÅteranslut DRBD-noderna
$ drbd connect allKonfigurera PostgreSQL för DRBD
Detta innebär att välja en enhet för vilken PostgreSQL kommer att lagra data. För en ny installation kan du välja att installera PostgreSQL helt och hållet på DRBD-enheten eller en datakatalog som ska finnas på det nya filsystemet och måste vara i den primära noden. Detta beror på att den primära noden är den enda som får montera ett DRBD-enhetsfilsystem som läs/skriv. Postgres-datafilerna arkiveras ofta i /var/lib/pgsql medan konfigurationsfilerna lagras i /etc/sysconfig/pgsql.
Konfigurera PostgreSQL för att använda den nya DRBD-enheten
-
Om du har någon som kör PostgreSQL, stoppa dem med detta kommando:
$ /etc/init.d/postgresql -9.0 -
Uppdatera DRBD-enheten med konfigurationsfilerna med hjälp av kommandona:
$ mkdir /mnt/drbd/pgsql/sysconfig $ cp /etc/sysconfig/pgsql/* /mnt/drbd/pgsql/sysconfig -
Uppdatera DRBD med PostgreSQL-datakatalog och systemfiler med:
$ cp -pR /var/lib/pgsql /mnt/drbd/pgsql/data -
Skapa en symbolisk länk till den nya konfigurationskatalogen på DRBD-enhetens filsystem från /etc/sysconfig/pgsql med kommandot:
$ ln -s /mnt/drbd/pgsql/sysconfig /etc/sysconfig/pgsql -
Ta bort katalogen /var/lib/pgsql, avmontera /mnt/drbd/pgsql och montera drbd-enheten till /var/lib/pgsql.
-
Starta PostgreSQL med kommandot:
$ /etc/init.d/postgresql -9.0 start
PostgreSQL-data bör nu finnas på filsystemet som körs på din DRBD-enhet under den konfigurerade enheten. Innehållet i databaserna kopieras också till den sekundära DRBD-noden men det kan inte nås eftersom DRBD-enheten som arbetar i den sekundära noden kan vara frånvarande.
Viktiga funktioner med DRBD-metoden
- Inställningsparametrarna är mycket anpassningsbara.
- Befintliga distributioner kan enkelt konfigureras med DRBD utan någon dataförlust.
- Läsbegäranden är lika balanserade
- Autentiseringen med delad hemlighet säkrar konfigurationen och dess data.