I min tidigare artikel startade jag en ny serie om spärrar genom att förklara vad de är, varför de behövs och mekaniken för hur de fungerar, och jag rekommenderar starkt att du läser den artikeln före den här. I den här artikeln ska jag diskutera FGCB_ADD_REMOVE-spärren och visa hur det kan vara en flaskhals.
Vad är FGCB_ADD_REMOVE-spärren?
De flesta låsklassnamn är knutna direkt till datastrukturen som de skyddar. FGCB_ADD_REMOVE-låset skyddar en datastruktur som kallas en FGCB, eller filgruppskontrollblock, och det kommer att finnas en av dessa låsningar för varje online-filgrupp i varje onlinedatabas i en SQL Server-instans. Närhelst en fil i en filgrupp läggs till, släpps, växer eller krymper, måste spärren förvärvas i EX-läge, och när man räknar ut nästa fil att allokera från, måste spärren förvärvas i SH-läge för att förhindra eventuella filgruppsändringar. (Kom ihåg att omfattningstilldelningar för en filgrupp utförs på en round-robin-basis genom filerna i filgruppen, och ta även hänsyn till proportionell fyllning , vilket jag förklarar här.)
Hur blir spärren en flaskhals?
Det vanligaste scenariot när denna spärr blir en flaskhals är följande:
- Det finns en databas med en enda fil, så alla tilldelningar måste komma från den ena datafilen
- Autotillväxtinställningen för filen är inställd på mycket liten (kom ihåg, före SQL Server 2016 var standardinställningen för autotillväxt för datafiler 1 MB!)
- Det finns många samtidiga operationer som kräver utrymme för att tilldelas (t.ex. en konstant insättningsbelastning från många klientanslutningar)
I det här fallet, även om det bara finns en fil, måste en tråd som kräver en allokering fortfarande skaffa FGCB_ADD_REMOVE-spärren i SH-läge. Den försöker sedan allokera från den enstaka datafilen, inser att det inte finns något utrymme och skaffar sedan spärren i EX-läge så att den sedan kan växa filen.
Låt oss föreställa oss att åtta trådar som körs på åtta separata schemaläggare alla försöker allokera samtidigt, och alla inser att det inte finns något utrymme i filen så de behöver utöka den. De kommer var och en att försöka få tag i spärren i EX-läge. Endast en av dem kommer att kunna förvärva den och den kommer att fortsätta att växa filen och de andra kommer att behöva vänta, med en väntetyp av LATCH_EX och en resursbeskrivning av FGCB_ADD_REMOVE plus minnesadressen för spärren.
De sju väntande trådarna finns i låsets först-in-först-ut (FIFO) väntekö. När tråden som utför filtillväxten är klar släpper den spärren och ger den till den första väntande tråden. Den här nya ägaren av spärren går för att odla filen och upptäcker att den redan har odlats och att det inte finns något att göra. Så den släpper spärren och ger den till nästa väntande tråd. Och så vidare.
De sju väntande trådarna väntade alla på spärren i EX-läge men slutade med att de inte gjorde någonting när de fick spärren, så alla sju trådarna slösade i princip bort förfluten tid, med tiden som slösades bort ökade lite för varje tråd ju längre ner FIFO-väntkön var det.
Visar flaskhalsen
Nu ska jag visa dig det exakta scenariot ovan, med hjälp av utökade händelser. Jag har skapat en enfilsdatabas med en liten inställning för autotillväxt och hundratals samtidiga anslutningar som helt enkelt infogar data i en tabell.
Jag kan använda följande utökade evenemangssession för att se vad som händer:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Sessionen spårar när en tråd kommer in i spärrens väntekö, när den lämnar kön (dvs. när den beviljas spärren) och när en datafiltillväxt inträffar. Genom att använda kausalitetsspårning kan vi se en tidslinje för åtgärderna för varje tråd.
Med SQL Server Management Studio kan jag välja alternativet Watch Live Data för den utökade händelsesessionen och se all utökad händelseaktivitet. Om du vill göra detsamma, högerklicka i Live Data-fönstret på ett av kolumnnamnen högst upp och ändra de valda kolumnerna så att de blir enligt nedan:
Jag lät arbetsbelastningen pågå i några minuter för att nå ett stabilt tillstånd och såg sedan ett perfekt exempel på scenariot jag beskrev ovan:
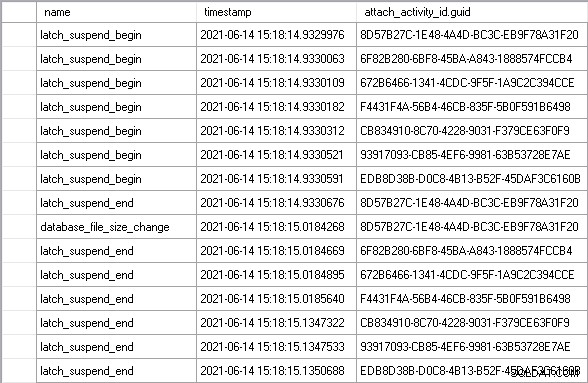
Använda attach_activity_id.guid värden för att identifiera olika trådar, kan vi se att sju trådar börjar vänta på spärren inom 61,5 mikrosekunder. Tråden med GUID-värdet som börjar 8D57 skaffar låset i EX-läge (latch_suspend_end händelse) och sedan omedelbart växer filen (database_file_size_change händelse). 8D57-gängan släpper sedan spärren och ger den i EX-läge till 6F82-gängan, som väntade i 85 millisekunder. Det har ingenting att göra så det ger spärren till 672B-gängan. Och så vidare, tills EDB8-tråden får spärren, efter att ha väntat i 202 millisekunder.
Totalt väntade de sex trådarna som väntade utan anledning i nästan 1 sekund. En del av den tiden är signalväntetid, där även om tråden har beviljats spärren, måste den fortfarande flyttas upp till toppen av schemaläggarens körbara kö innan den kan komma in i processorn och exekvera kod. Du kan säga att det här inte är ett rättvist mått på den tid som ägnas åt att vänta på spärren, men det är det absolut, eftersom signalväntetiden inte skulle ha uppstått om tråden inte hade behövt vänta i första hand.
Dessutom kanske du tror att en fördröjning på 200 millisekunder inte är så mycket, men allt beror på prestationsservicenivåavtalen för arbetsbelastningen i fråga. Vi har flera högvolymklienter där om en batch tar mer än 200 millisekunder att köra, är det inte tillåtet i produktionssystemet!
Sammanfattning
Om du övervakar väntetider på din server och du märker att LATCH_EX är en av de vanligaste väntetiderna, kan du använda koden i det här inlägget så se om FGCB_ADD_REMOVE är en av de skyldiga.
Det enklaste sättet att se till att din arbetsbelastning inte träffar en FGCB_ADD_REMOVE flaskhals är att se till att det inte finns några inställningar för autotillväxt för datafiler som är konfigurerade med standardinställningarna före SQL Server 2016. I sys.master_files vy, 1MB standard visas som en datafil (type_desc kolumn inställd på ROWS) med is_percent_growth kolumn inställd på 0, och tillväxtkolumn inställd på 128.
Att ge en rekommendation för vad autogrow bör ställas in på är en helt annan diskussion, men nu känner du till en potentiell prestandapåverkan från att inte ändra standardinställningarna i tidigare versioner.