SQL Server har traditionellt hållit sig undan från att tillhandahålla inbyggda lösningar på några av de vanligare statistiska frågorna, som att beräkna en median. Enligt WikiPedia beskrivs "medianen som det numeriska värdet som skiljer den högre hälften av ett urval, en population eller en sannolikhetsfördelning, från den nedre halvan. Medianen för en ändlig lista med tal kan hittas genom att ordna alla observationer från lägsta värde till högsta värde och välj det mellersta. Om det finns ett jämnt antal observationer finns det inget enskilt mittvärde; medianen definieras då vanligtvis som medelvärdet av de två mittersta värdena."
När det gäller en SQL Server-fråga är det viktigaste du tar bort från det att du måste "ordna" (sortera) alla värden. Att sortera i SQL Server är vanligtvis en ganska dyr operation om det inte finns ett stödjande index, och att lägga till ett index för att stödja en operation som förmodligen inte efterfrågas så ofta kanske inte är värt besväret.
Låt oss undersöka hur vi vanligtvis har löst detta problem i tidigare versioner av SQL Server. Låt oss först skapa en mycket enkel tabell så att vi kan se att vår logik är korrekt och härleda en korrekt median. Vi kan testa följande två tabeller, en med ett jämnt antal rader och den andra med ett udda antal rader:
CREATE TABLE dbo.EvenRows ( id INT PRIMARY KEY, val INT );
CREATE TABLE dbo.OddRows ( id INT PRIMARY KEY, val INT );
INSERT dbo.EvenRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4
UNION ALL SELECT 8, 9;
INSERT dbo.OddRows(id,val)
SELECT 1, 6
UNION ALL SELECT 2, 11
UNION ALL SELECT 3, 4
UNION ALL SELECT 4, 4
UNION ALL SELECT 5, 15
UNION ALL SELECT 6, 14
UNION ALL SELECT 7, 4;
DECLARE @Median DECIMAL(12, 2); Bara från tillfällig observation kan vi se att medianen för tabellen med udda rader bör vara 6, och för den jämna tabellen bör den vara 7,5 ((6+9)/2). Så nu ska vi se några lösningar som har använts under åren:
SQL Server 2000
I SQL Server 2000 var vi begränsade till en mycket begränsad T-SQL-dialekt. Jag undersöker dessa alternativ för jämförelse eftersom vissa människor där ute fortfarande kör SQL Server 2000, och andra kan ha uppgraderat, men eftersom deras medianberäkningar skrevs "förr i tiden" kan koden fortfarande se ut så här idag.
2000_A – max en halva, min för den andra
Detta tillvägagångssätt tar det högsta värdet från de första 50 procenten, det lägsta värdet från de sista 50 procenten och dividerar dem sedan med två. Detta fungerar för jämna eller udda rader eftersom, i det jämna fallet, är de två värdena de två mittersta raderna, och i det udda fallet är de två värdena faktiskt från samma rad.
SELECT @Median = (
(SELECT MAX(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val, id) AS t)
+ (SELECT MIN(val) FROM
(SELECT TOP 50 PERCENT val
FROM dbo.EvenRows ORDER BY val DESC, id DESC) AS b)
) / 2.0; 2000_B – #temp tabell
Det här exemplet skapar först en #temp-tabell och använder samma typ av matematik som ovan, bestämmer de två "mitten" raderna med hjälp av en sammanhängande IDENTITY kolumnen sorterad efter valkolumnen. (Orden för tilldelning av IDENTITY värden kan bara litas på på grund av MAXDOP inställning.)
CREATE TABLE #x
(
i INT IDENTITY(1,1),
val DECIMAL(12, 2)
);
CREATE CLUSTERED INDEX v ON #x(val);
INSERT #x(val)
SELECT val
FROM dbo.EvenRows
ORDER BY val OPTION (MAXDOP 1);
SELECT @Median = AVG(val)
FROM #x AS x
WHERE EXISTS
(
SELECT 1
FROM #x
WHERE x.i - (SELECT MAX(i) / 2.0 FROM #x) IN (0, 0.5, 1)
);
SQL Server 2005, 2008, 2008 R2
SQL Server 2005 introducerade några intressanta nya fönsterfunktioner, såsom ROW_NUMBER() , som kan hjälpa till att lösa statistiska problem som median lite enklare än vi kunde i SQL Server 2000. Dessa tillvägagångssätt fungerar alla i SQL Server 2005 och senare:
2005_A – duellerande radnummer
Det här exemplet använder ROW_NUMBER() för att gå upp och ner värdena en gång i varje riktning, hittar sedan "mitten" en eller två rader baserat på den beräkningen. Detta är ganska likt det första exemplet ovan, med enklare syntax:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT val,
ra = ROW_NUMBER() OVER (ORDER BY val, id),
rd = ROW_NUMBER() OVER (ORDER BY val DESC, id DESC)
FROM dbo.EvenRows
) AS x
WHERE ra BETWEEN rd - 1 AND rd + 1; 2005_B – radnummer + antal
Den här är ganska lik ovanstående, med en enda beräkning av ROW_NUMBER() och sedan använda det totala COUNT() för att hitta "mitten" en eller två rader:
SELECT @Median = AVG(1.0 * Val)
FROM
(
SELECT val,
c = COUNT(*) OVER (),
rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.EvenRows
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2); 2005_C – variation på radnummer + antal
Fellow MVP Itzik Ben-Gan visade mig den här metoden, som ger samma svar som ovanstående två metoder, men på ett väldigt lite annorlunda sätt:
SELECT @Median = AVG(1.0 * val)
FROM
(
SELECT o.val, rn = ROW_NUMBER() OVER (ORDER BY o.val), c.c
FROM dbo.EvenRows AS o
CROSS JOIN (SELECT c = COUNT(*) FROM dbo.EvenRows) AS c
) AS x
WHERE rn IN ((c + 1)/2, (c + 2)/2);
SQL Server 2012
I SQL Server 2012 har vi nya fönsterfunktioner i T-SQL som gör att statistiska beräkningar som median kan uttryckas mer direkt. För att beräkna medianen för en uppsättning värden kan vi använda PERCENTILE_CONT() . Vi kan också använda det nya "paging"-tillägget till ORDER BY klausul (OFFSET / FETCH ).
2012_A – ny distributionsfunktion
Denna lösning använder en mycket enkel beräkning med distribution (om du inte vill ha medelvärdet mellan de två mittersta värdena vid ett jämnt antal rader).
SELECT @Median = PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY val) OVER () FROM dbo.EvenRows;
2012_B – personsökningstrick
Det här exemplet implementerar en smart användning av OFFSET / FETCH (och inte precis en som den var avsedd för) – vi flyttar helt enkelt till raden som är en före halva räkningen, och tar sedan nästa en eller två rader beroende på om räkningen var udda eller jämn. Tack till Itzik Ben-Gan för att du påpekade detta tillvägagångssätt.
DECLARE @c BIGINT = (SELECT COUNT(*) FROM dbo.EvenRows);
SELECT AVG(1.0 * val)
FROM (
SELECT val FROM dbo.EvenRows
ORDER BY val
OFFSET (@c - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @c % 2) ROWS ONLY
) AS x;
Men vilken presterar bäst?
Vi har verifierat att ovanstående metoder ger de förväntade resultaten på vårt lilla bord, och vi vet att SQL Server 2012-versionen har den renaste och mest logiska syntaxen. Men vilken ska du använda i din hektiska produktionsmiljö? Vi kan bygga en mycket större tabell från systemmetadata och se till att vi har gott om dubbletter av värden. Det här skriptet kommer att producera en tabell med 10 000 000 icke-unika heltal:
USE tempdb; GO CREATE TABLE dbo.obj(id INT IDENTITY(1,1), val INT); CREATE CLUSTERED INDEX x ON dbo.obj(val, id); INSERT dbo.obj(val) SELECT TOP (10000000) o.[object_id] FROM sys.all_columns AS c CROSS JOIN sys.all_objects AS o CROSS JOIN sys.all_objects AS o2 WHERE o.[object_id] > 0 ORDER BY c.[object_id];
På mitt system bör medianen för denna tabell vara 146 099 561. Jag kan beräkna detta ganska snabbt utan en manuell stickprovskontroll på 10 000 000 rader genom att använda följande fråga:
SELECT val FROM
(
SELECT val, rn = ROW_NUMBER() OVER (ORDER BY val)
FROM dbo.obj
) AS x
WHERE rn IN (4999999, 5000000, 5000001); Resultat:
val rn ---- ---- 146099561 4999999 146099561 5000000 146099561 5000001
Så nu kan vi skapa en lagrad procedur för varje metod, verifiera att var och en producerar rätt utdata och sedan mäta prestandamått som varaktighet, CPU och läsningar. Vi kommer att utföra alla dessa steg med den befintliga tabellen, och även med en kopia av tabellen som inte drar nytta av det klustrade indexet (vi släpper det och återskapar tabellen som en hög).
Jag har skapat sju procedurer som implementerar frågemetoderna ovan. För korthetens skull kommer jag inte att lista dem här, men var och en heter dbo.Median_<version> , t.ex. dbo.Median_2000_A , dbo.Median_2000_B , etc. motsvarande de ovan beskrivna tillvägagångssätten. Om vi kör dessa sju procedurer med den kostnadsfria SQL Sentry Plan Explorer, här är vad vi observerar i termer av varaktighet, CPU och läsningar (observera att vi kör DBCC FREEPROCCACHE och DBCC DROPCLEANBUFFERS mellan körningarna):
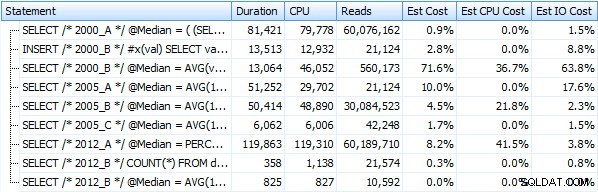
Och dessa mätvärden förändras inte mycket alls om vi arbetar mot en hög istället. Den största procentuella förändringen var den metod som ändå blev snabbast:personsökningstricket med OFFSET / FETCH:
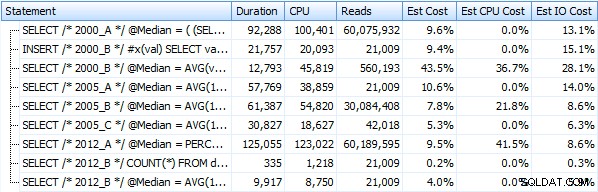
Här är en grafisk representation av resultaten. För att göra det mer tydligt markerade jag den långsammaste spelaren i rött och den snabbaste inriktningen i grönt.
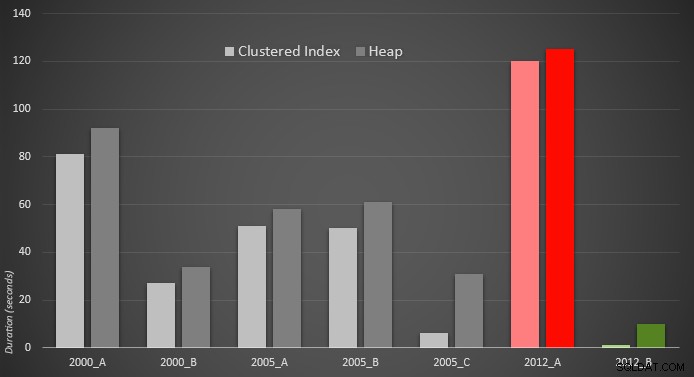
Jag blev förvånad över att se att i båda fallen PERCENTILE_CONT() – som designades för den här typen av beräkningar – är faktiskt sämre än alla andra tidigare lösningar. Jag antar att det bara visar att även om nyare syntax ibland kan göra vår kodning lättare, garanterar det inte alltid att prestandan kommer att förbättras. Jag blev också förvånad över att se OFFSET / FETCH visa sig vara så användbar i scenarier som vanligtvis inte tycks passa dess syfte – paginering.
Jag hoppas i alla fall att jag har visat vilket tillvägagångssätt du bör använda, beroende på din version av SQL Server (och att valet bör vara detsamma oavsett om du har ett stödjande index för beräkningen eller inte).