Borttagning och förebyggande av indexfragmentering har länge varit en del av normala databasunderhållsoperationer, inte bara i SQL Server, utan på många plattformar. Indexfragmentering påverkar prestanda av många anledningar, och de flesta talar om effekterna av slumpmässiga små I/O-block som fysiskt kan hända med diskbaserad lagring som något som bör undvikas. Det allmänna bekymret kring indexfragmentering är att det påverkar prestanda för skanningar genom att begränsa storleken på läs-förut-I/O. Det är baserat på denna begränsade förståelse för problemen som indexfragmentering orsakar att vissa människor har börjat cirkulera tanken att indexfragmentering inte spelar någon roll med Solid State Storage-enheter (SSD) och att du bara kan ignorera indexfragmentering framöver.
Så är dock inte fallet av flera skäl. Den här artikeln kommer att förklara och demonstrera ett av dessa skäl:att indexfragmentering kan negativt påverka valet av exekveringsplan för frågor. Detta beror på att indexfragmentering i allmänhet leder till att ett index har fler sidor (dessa extra sidor kommer från siddelning operationer, som beskrivs i det här inlägget på den här webbplatsen), och därför anses användningen av det indexet ha en högre kostnad av SQL Servers frågeoptimerare.
Låt oss titta på ett exempel.
Det första vi behöver göra är att bygga en lämplig testdatabas och datauppsättning för att undersöka hur indexfragmentering kan påverka valet av frågeplan i SQL Server. Följande skript kommer att skapa en databas med två tabeller med identiska data, en kraftigt fragmenterad och en minimalt fragmenterad.
USE master;
GO
DROP DATABASE FragmentationTest;
GO
CREATE DATABASE FragmentationTest;
GO
USE FragmentationTest;
GO
CREATE TABLE GuidHighFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidHighFragmentation_LastName
ON GuidHighFragmentation(LastName);
GO
CREATE TABLE GuidLowFragmentation
(
UniqueID UNIQUEIDENTIFIER DEFAULT NEWSEQUENTIALID() PRIMARY KEY,
FirstName nvarchar(50) NOT NULL,
LastName nvarchar(50) NOT NULL
);
GO
CREATE NONCLUSTERED INDEX IX_GuidLowFragmentation_LastName
ON GuidLowFragmentation(LastName);
GO
INSERT INTO GuidHighFragmentation (FirstName, LastName)
SELECT TOP 100000 a.name, b.name
FROM master.dbo.spt_values AS a
CROSS JOIN master.dbo.spt_values AS b
WHERE a.name IS NOT NULL
AND b.name IS NOT NULL
ORDER BY NEWID();
GO 70
INSERT INTO GuidLowFragmentation (UniqueID, FirstName, LastName)
SELECT UniqueID, FirstName, LastName
FROM GuidHighFragmentation;
GO
ALTER INDEX ALL ON GuidLowFragmentation REBUILD;
GO Efter att ha byggt om indexet kan vi titta på fragmenteringsnivåerna med följande fråga:
SELECT
OBJECT_NAME(ps.object_id) AS table_name,
i.name AS index_name,
ps.index_id,
ps.index_depth,
avg_fragmentation_in_percent,
fragment_count,
page_count,
avg_page_space_used_in_percent,
record_count
FROM sys.dm_db_index_physical_stats(
DB_ID(),
NULL,
NULL,
NULL,
'DETAILED') AS ps
JOIN sys.indexes AS i
ON ps.object_id = i.object_id
AND ps.index_id = i.index_id
WHERE index_level = 0;
GO Resultat:

Här kan vi se att vår GuidHighFragmentation tabellen är 99 % fragmenterad och använder 31 % mer sidutrymme än GuidLowFragmentation tabell i databasen, trots att de har samma 7 000 000 rader med data. Om vi utför en grundläggande aggregeringsfråga mot var och en av tabellerna och jämför exekveringsplanerna på en standardinstallation (med standardkonfigurationsalternativ och -värden) av SQL Server med SentryOne Plan Explorer:
-- Aggregate the data from both tables SELECT LastName, COUNT(*) FROM GuidLowFragmentation GROUP BY LastName; GO SELECT LastName, COUNT(*) FROM GuidHighFragmentation GROUP BY LastName; GO


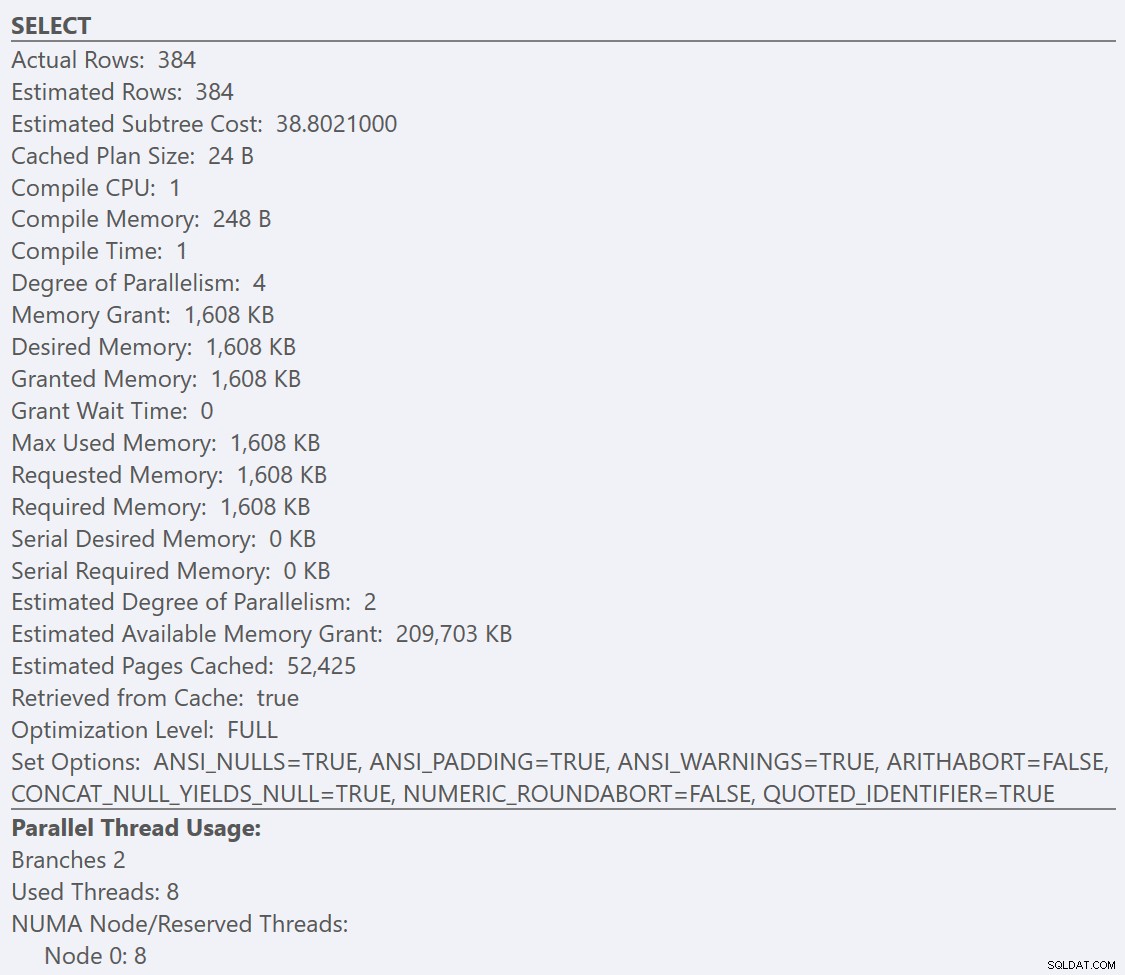

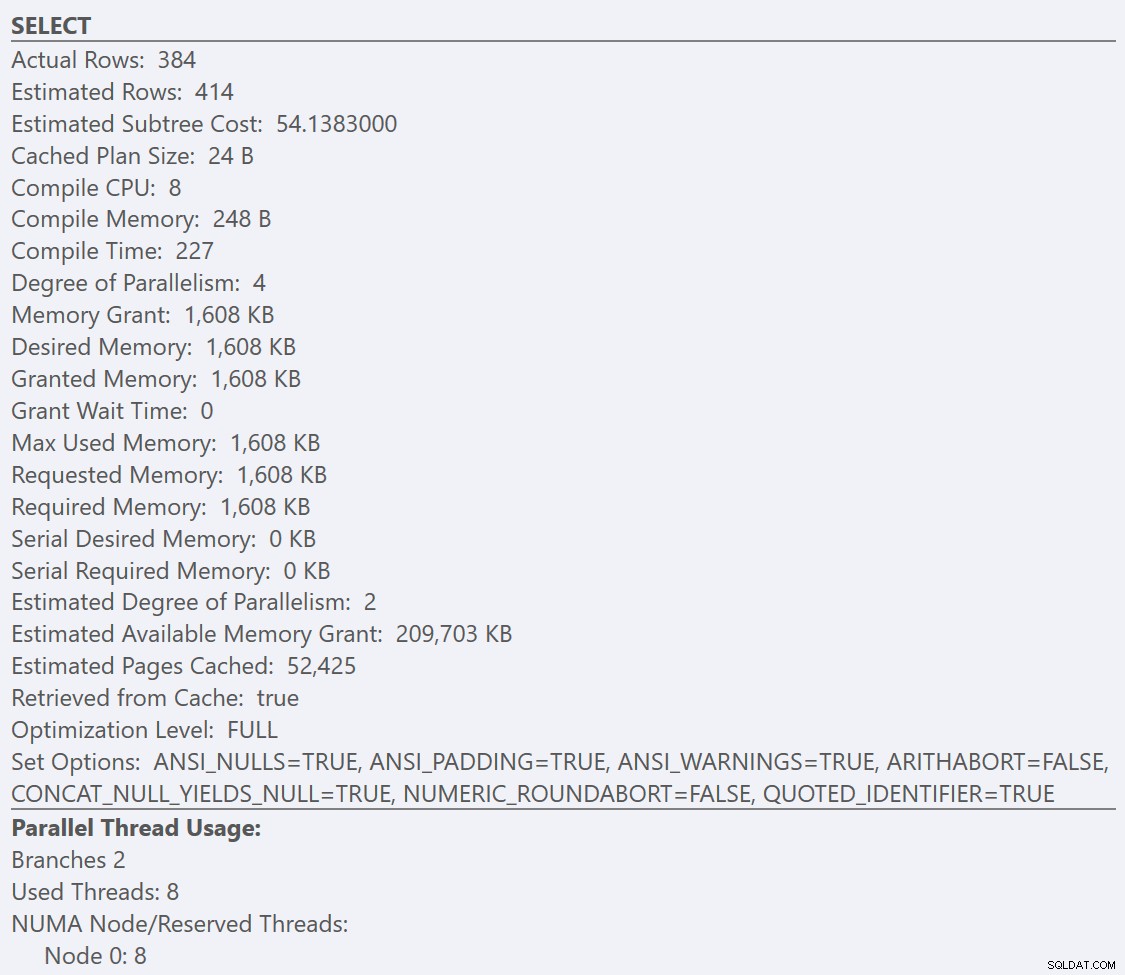
Om vi tittar på verktygstipsen från SELECT operatör för varje plan, planen för GuidLowFragmentation tabellen har en frågekostnad på 38,80 (den tredje raden ner från toppen av verktygstipset) jämfört med en frågekostnad på 54,14 för planen för GuidHighFragmentation-planen.
Under en standardkonfiguration för SQL Server kommer båda dessa frågor att generera en parallell exekveringsplan eftersom den uppskattade frågekostnaden är högre än "kostnadströskeln för parallellism" sp_configure-alternativet standard på 5. Detta beror på att frågeoptimeraren först producerar en seriell plan (som bara kan köras av en enda tråd) när planen för en fråga kompileras. Om den uppskattade kostnaden för den seriella planen överstiger det konfigurerade värdet för "kostnadströskel för parallellism", genereras en parallell plan och cachelagras istället.
Men vad händer om alternativet 'kostnadströskel för parallellism' sp_configure inte är inställt på standardvärdet 5 och är högre? Det är en bästa praxis (och en korrekt sådan) att öka det här alternativet från den låga standarden 5 till var som helst från 25 till 50 (eller till och med mycket högre) för att förhindra att små frågor medför extra omkostnader för att gå parallellt.
EXEC sys.sp_configure N'show advanced options', N'1'; RECONFIGURE; GO EXEC sys.sp_configure N'cost threshold for parallelism', N'50'; RECONFIGURE; GO EXEC sys.sp_configure N'show advanced options', N'0'; RECONFIGURE; GO
Efter att ha följt riktlinjerna för bästa praxis och ökat "kostnadströskeln för parallellism" till 50, resulterar en omkörning av frågorna i samma exekveringsplan för GuidHighFragmentation tabellen, men GuidLowFragmentation frågas seriekostnad, 44,68, ligger nu under värdet för "kostnadströskel för parallellism" (kom ihåg att dess uppskattade parallellkostnad var 38,80), så vi får en seriell exekveringsplan:
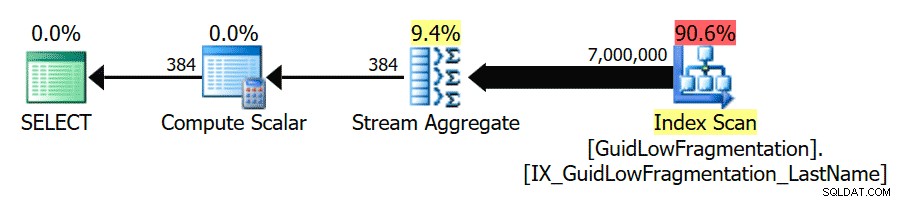
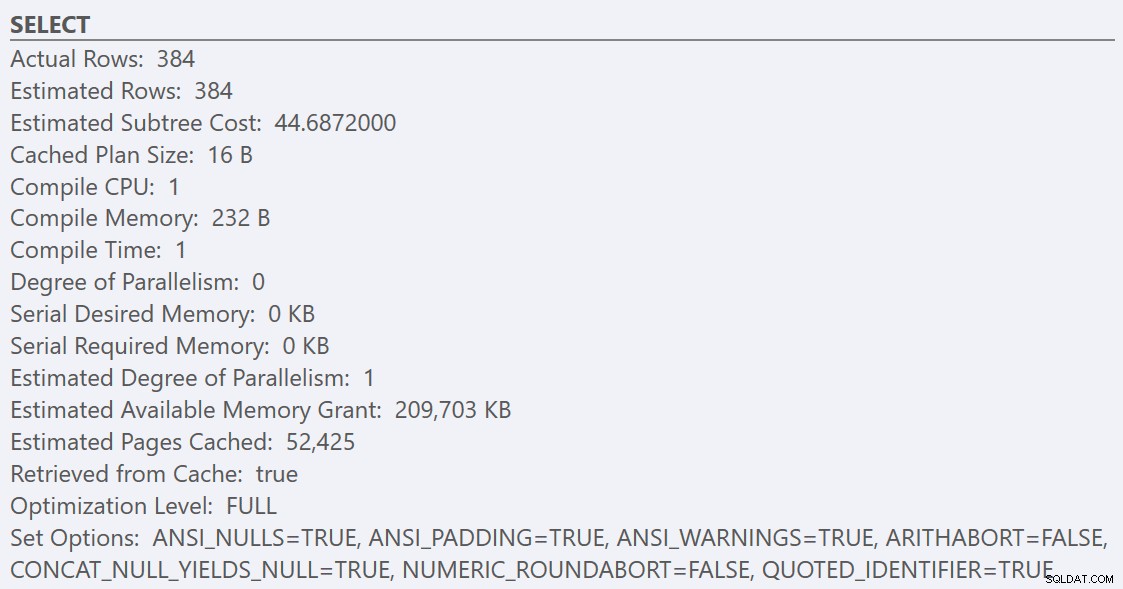
Det ytterligare sidutrymmet i GuidHighFragmentation klustrade index höll kostnaden över bästa praxis-inställningen för "kostnadströskel för parallellism" och resulterade i en parallell plan.
Föreställ dig nu att detta var ett system där du följde riktlinjerna för bästa praxis och initialt konfigurerade 'kostnadströskeln för parallellism' till ett värde av 50. Sen följde du senare det missriktade rådet att helt och hållet ignorera indexfragmentering.
Istället för att detta är en grundläggande fråga är det mer komplext, men om det också körs väldigt ofta på ditt system, och som ett resultat av indexfragmentering, tippar sidräkningen kostnaden över till en parallell plan, kommer den att använda mer CPU och påverka den totala arbetsbelastningen som ett resultat.
Vad gör du? Ökar du 'kostnadströskeln för parallellism' så att frågan upprätthåller en seriell exekveringsplan? Antyder du frågan med OPTION(MAXDOP 1) och bara tvingar den till en seriell exekveringsplan?
Tänk på att indexfragmentering sannolikt inte bara påverkar en tabell i din databas, nu när du ignorerar den helt; Det är troligt att många klustrade och icke-klustrade index är fragmenterade och har ett högre antal sidor än nödvändigt, så kostnaderna för många I/O-operationer ökar som ett resultat av den utbredda indexfragmenteringen, vilket leder till potentiellt många ineffektiva frågor planer.
Sammanfattning
Du kan inte bara ignorera indexfragmentering helt som vissa kanske vill att du ska tro. Bland andra nackdelar med att göra detta kommer de ackumulerade kostnaderna för att köra frågor att komma ikapp dig, med frågeplansförskjutningar eftersom frågeoptimeraren är en kostnadsbaserad optimerare och därför med rätta anser att de fragmenterade indexen är dyrare att använda.
Frågorna och scenariot här är uppenbarligen konstruerade, men vi har sett förändringar i exekveringsplanen orsakade av fragmentering i verkliga livet på klientsystem.
Du måste se till att du tar itu med indexfragmentering för de index där fragmentering orsakar problem med arbetsbelastningsprestanda, oavsett vilken hårdvara du använder.