Detta är den sista delen av en serie i fem delar som tar en djupdykning i hur parallella planer för SQL Server-radläge börjar köras. Del 1 initierade exekveringskontext noll för den överordnade uppgiften, och del 2 skapade frågesökningsträdet. Del 3 startade sökfrågan, utförde någon tidig fas bearbetning och startade de första ytterligare parallella uppgifterna i gren C. Del 4 beskrev utbytessynkronisering och uppstart av parallellplansgrenar C &D.
Branch B Parallel Tasks Start
En påminnelse om grenarna i denna parallella plan (klicka för att förstora):
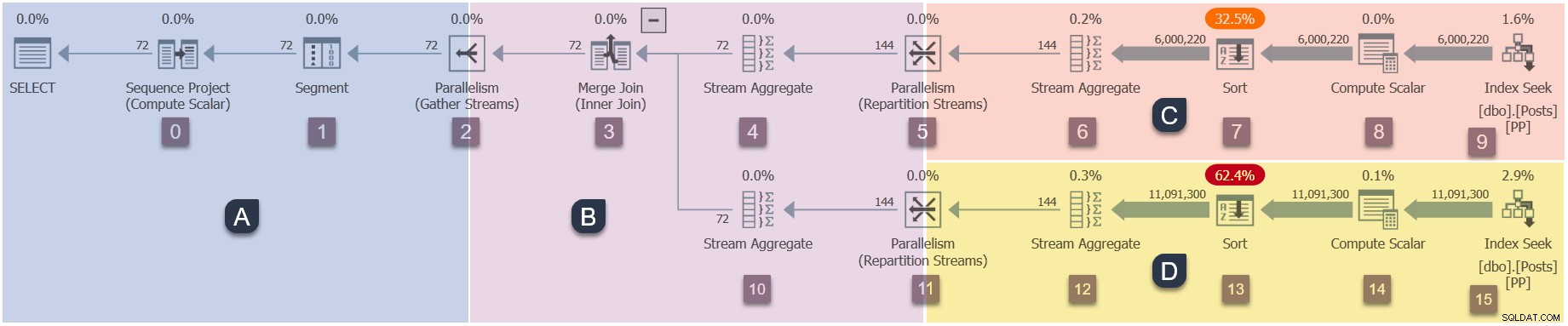
Detta är det fjärde steget i exekveringssekvensen:
- Gren A (föräldrauppgift).
- Gren C (ytterligare parallella uppgifter).
- Gren D (ytterligare parallella uppgifter).
- Gren B (ytterligare parallella uppgifter).
Den enda tråden som är aktiv just nu (inte avstängd på CXPACKET ) är förälderuppgiften , som är på konsumentsidan av ompartitionsströmutbytet vid nod 11 i gren B:
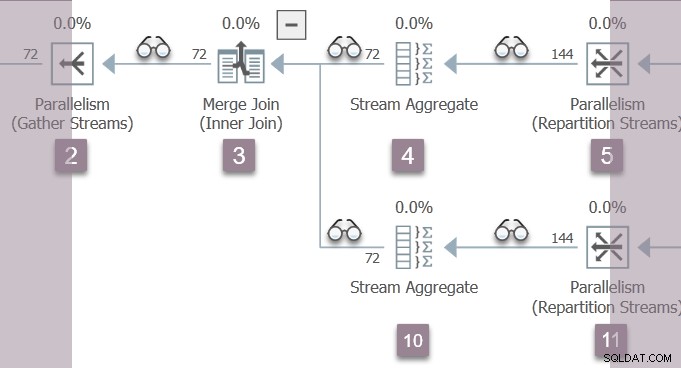
Den överordnade uppgiften återvänder nu från kapslade tidiga faser samtal, inställning av förfluten tid och CPU-tider i profiler allt eftersom. Första och sista aktiva tider är inte uppdateras under tidig bearbetning. Kom ihåg att dessa nummer registreras mot exekveringskontext noll – de parallella uppgifterna för gren B existerar inte ännu.
föräldrauppgiften stiger upp trädet från nod 11, genom strömaggregatet vid nod 10 och sammanslagningssammanfogningen vid nod 3, tillbaka till samlaströmsutbytet vid nod 2.
Bearbetningen i tidig fas är nu klar .
Med den ursprungliga EarlyPhases anropa nod 2 samla strömmar byt äntligen slutförd återgår den överordnade uppgiften till att öppna den växeln (du kanske nästan kommer ihåg det samtalet från direkt i början av den här serien). Den öppna metoden vid nod 2 anropar nu CQScanExchangeNew::StartAllProducers för att skapa de parallella uppgifterna för filial B.
föräldrauppgiften nu väntar på CXPACKET hos konsumenten sidan av noden 2 samla strömmar utbyta. Denna väntetid kommer att fortsätta tills de nyskapade gren B-uppgifterna har slutfört sina kapslade Open samtal och återvände för att slutföra öppnandet av producentsidan av samla strömmar-börsen.
Gren B parallella uppgifter öppna
De två nya parallella uppgifterna i Branch B börjar hos producenten sidan av noden 2 samla strömmar utbyta. Efter den vanliga iterativa exekveringsmodellen i radläget anropar de:
CQScanXProducerNew::Open(producentsidan av nod 2 öppen).CQScanProfileNew::Open(profilerare för nod 3).CQScanMergeJoinNew::Open(nod 3 sammanfoga sammanfogning).CQScanProfileNew::Open(profilerare för nod 4).CQScanStreamAggregateNew::Open(sammanlagd ström av nod 4).CQScanProfileNew::Open(profilerare för nod 5).CQScanExchangeNew::Open(utbyte av ompartitionsströmmar).
De parallella uppgifterna följer båda den yttre (övre) ingången till sammanfogningen, precis som den tidiga bearbetningen gjorde.
Slutföra utbytet
När Branch B-uppgifterna kommer till konsumenten sidan av ompartitionsströmmarna utbyter vid nod 5, varje uppgift:
- Registrerar sig med utbytesporten (
CXPort). - Skapar rören (
CXPipe) som kopplar denna uppgift till en eller flera producentsidouppgifter (beroende på typ av utbyte). Den nuvarande växeln är en ompartitionsström, så varje konsumentuppgift har två rör (vid DOP 2). Varje konsument kan få rader från någon av de två tillverkarna. - Lägger till en
CXPipeMergeför att sammanfoga rader från flera rör (eftersom detta är ett orderbevarande utbyte). - Skapar radpaket (förvirrande namn
CXPacket) används för flödeskontroll och för att buffra rader över utbytesrören. Dessa allokeras från tidigare beviljat frågeminne.
När båda parallella uppgifterna på konsumentsidan har slutfört det arbetet, är nod 5-växeln redo att gå. De två konsumenterna (i Branch B) och de två producenterna (i Branch C) har alla öppnat utbytesporten, så nod 5 CXPACKET väntar slut .
Checkpoint
Som det ser ut:
- Den överordnade uppgiften i Gren A väntar på
CXPACKETpå konsumentsidan av nod 2 samlar strömmar utbyte. Denna väntan kommer att fortsätta tills båda nod 2-producenterna återvänder och öppnar börsen. - De två parallella uppgifterna i Brench B är körbara . De har precis öppnat konsumentsidan av utbytet för ompartitionsströmmar vid nod 5.
- De två parallella uppgifterna i gren C har precis släppts från deras
CXPACKETvänta och är nu körbara . De två strömaggregaten vid nod 6 (en per parallell uppgift) kan börja aggregera rader från de två sorteringarna vid nod 7. Kom ihåg att indexsöken vid nod 9 stängdes för en tid sedan, när sorteringarna avslutade sin inmatningsfas. - De två parallella uppgifterna i gren D är väntar på
CXPACKETpå producentsidan av uppdelningen strömmar utbyte vid nod 11. De väntar på att konsumentsidan av nod 11 ska öppnas av de två parallella uppgifterna i Branch B. Indexsöken har stängts och sorterna är redo att övergå till deras utgångsfas.
Flera aktiva grenar
Detta är första gången vi har haft flera grenar (B och C) aktiva samtidigt, vilket kan vara svårt att diskutera. Lyckligtvis är designen av demofrågan sådan att strömaggregaten i gren C bara kommer att producera ett fåtal rader. Det lilla antalet smala utdatarader passar lätt i radpaketets buffertar vid nod 5 byter uppdelningsströmmar. Branch C-uppgifterna kan därför fortsätta med sitt arbete (och så småningom stängas) utan att vänta på att nod 5 ompartitionsströmmar konsumentsidan ska hämta några rader.
Bekvämt betyder detta att vi kan låta de två parallella uppgifterna i Branch C köras i bakgrunden utan att oroa oss för dem. Vi behöver bara bry oss om vad de två parallella uppgifterna i gren B gör.
Öppningen av filial B är klar
En påminnelse om gren B:
De två parallella arbetarna i gren B återvänder från sin Open anropar till nod 5 ompartitionsströmutbyte. Detta tar dem tillbaka genom strömmen aggregeras vid nod 4, till sammanfogningen vid nod 3.
Eftersom vi stiger trädet i Open metod registrerar profilerna ovanför nod 5 och nod 4 senast aktiva tid, samt ackumulering av förfluten tid och CPU-tider (per uppgift). Vi kör inte tidiga faser av den överordnade uppgiften nu, så siffrorna som registreras för körningskontext noll påverkas inte.
Vid sammanfogningen börjar de två parallella uppgifterna i gren B fallande den inre (nedre) ingången, som tar dem genom strömaggregatet vid nod 10 (och ett par profiler) till konsumentsidan av uppdelningsströmmarnas utbyte vid nod 11.
Gren D återupptar körningen
En upprepning av gren C-händelserna vid nod 5 inträffar nu vid nod 11 ompartitionsströmmarna. Konsumentsidan av nod 11 växeln är fullbordad och öppnad. De två producenterna i Branch D avslutar sin CXPACKET väntar och blir körbar på nytt. Vi låter Branch D-uppgifterna köras i bakgrunden och placerar deras resultat i utbytesbuffertar.
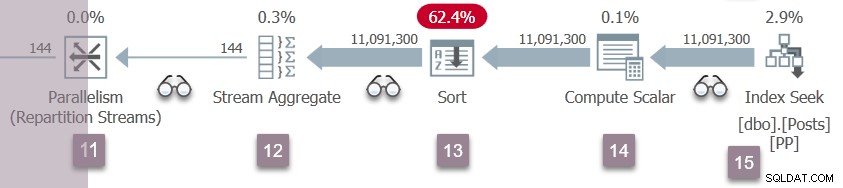
Det finns nu sex parallella uppgifter (två vardera i grenarna B, C och D) som tillsammans delar tid på de två schemaläggare som tilldelats ytterligare parallella uppgifter i den här frågan.
Öppningen av filial A slutförs
De två parallella uppgifterna i gren B återgår från sin Open anropar vid nod 11 ompartitionsströmmar utbyte, upp förbi nod 10 strömaggregatet, genom sammanslagningen vid nod 3, och tillbaka till producentsidan av samla strömmarna vid nod 2. Profiler senast aktiv och ackumulerade förflutna &CPU-tider uppdateras när vi stiger upp i trädet i kapslad Open metoder.
Hos producenten sidan av samlingsströmutbytet synkroniserar de två parallella uppgifterna i Branch B och öppnar utbytesporten och väntar sedan på CXPACKET för konsumentsidan att öppna.
föräldrauppgiften väntar på konsumentsidan av samla strömmar är nu släppt från dess CXPACKET vänta, vilket gör att den kan slutföra öppningen av utbytesporten på konsumentsidan. Detta frigör i sin tur producenterna från deras (korta) CXPACKET vänta. Samlingsströmmarna för nod 2 har nu öppnats av alla ägare.
Slutföra sökfrågan
föräldrauppgiften stiger nu upp i frågesökningsträdet från samlingsströmbörsen och återvänder från Open samtal på växeln, segment och sekvensprojekt operatörer i filial A.
Detta slutför öppningen frågesökningsträdet, initierade allt detta för ett tag sedan av anropet till CQueryScan::StartupQuery . Alla grenar av parallellplanen har nu börjat exekvera.
Återkommande rader
Exekveringsplanen är redo att börja returnera rader som svar på GetRow anrop vid root i frågeskanningsträdet, initierat av ett anrop till CQueryScan::GetRow . Jag tänker inte gå in i detalj, eftersom det är strikt utanför ramarna för en artikel om hur parallella planer startar upp .
Ändå är den korta sekvensen:
- Den överordnade uppgiften anropar
GetRowpå sekvensprojektet, som anroparGetRowpå segmentet som anroparGetRowpå konsumenten sidan av samla strömmar utbyte. - Om det inte finns några tillgängliga rader på börsen än, väntar den överordnade uppgiften på
CXCONSUMER. - Under tiden har de oberoende körande parallella uppgifterna i Branch B rekursivt anropat
GetRowfrån producenten sidan av samla strömmar utbyte. - Rader levereras till gren B av konsumentsidorna av ompartitionsströmutbytena vid noderna 5 och 12.
- Grenerna C och D bearbetar fortfarande rader från sina sorter genom sina respektive flödesaggregat. Uppgifter i gren B kan behöva vänta på
CXCONSUMERvid ompartitionsströmmar nod 5 och 12 för att ett komplett paket med rader ska bli tillgängligt. - Rader som kommer från den kapslade
GetRowanrop i gren B sätts samman till radpaket hos producenten sidan av samla strömmar utbyte. - Den överordnade uppgiftens
CXCONSUMERvänta på konsumentsidan av insamlingsströmmarna slutar när ett paket blir tillgängligt. - En rad i taget bearbetas sedan genom de överordnade operatörerna i gren A och slutligen vidare till klienten.
- Så småningom tar raderna slut och en kapslad
Closesamtalet krusar ner i trädet, över växlingarna, och parallell körning tar slut.
Sammanfattning och slutanteckningar
Först, en sammanfattning av exekveringssekvensen för denna speciella parallella exekveringsplan:
- Föräldrauppgiften öppnar gren A . Tidig fas bearbetningen börjar vid utbytet av samla strömmar.
- Anrop i den tidiga fasen av överordnad uppgift går ner i skanningsträdet till indexsökningen vid nod 9, och stiger sedan tillbaka till ompartitioneringsväxeln vid nod 5.
- Den överordnade uppgiften startar parallella uppgifter för Gren C , väntar sedan medan de läser in alla tillgängliga rader i blockeringssorteringsoperatorerna vid nod 7.
- Tidiga fasanrop stiger till sammanfogningen och går sedan ned den inre ingången till växeln vid nod 11.
- Uppgifter för Branch D startas precis som för gren C, medan den överordnade uppgiften väntar vid nod 11.
- Tidiga fasanrop återvänder från nod 11 så långt som insamlingsströmmarna. Den tidiga fasen slutar här.
- Den överordnade uppgiften skapar parallella uppgifter för Gren B , och väntar tills öppningen av gren B är klar.
- Gren B-uppgifter når nod 5-ompartitionsströmmarna, synkroniserar, slutför utbytet och släpper Branch C-uppgifter för att börja aggregera rader från sorteringarna.
- När Branch B-uppgifter når nod 12 ompartitionsströmmar synkroniserar de, slutför utbytet och släpper Branch D-uppgifter för att börja aggregera rader från sorteringen.
- Gren B-uppgifter återgår till insamlingsströmmarna utbyter och synkroniseras, vilket frigör den överordnade uppgiften från väntan. Den överordnade uppgiften är nu redo att starta processen med att returnera rader till klienten.
Du kanske skulle vilja se genomförandet av denna plan i Sentry One Plan Explorer. Se till att aktivera alternativet "Med Live Query Profile" för insamling av faktisk plan. Det fina med att köra frågan direkt i Plan Explorer är att du kommer att kunna gå igenom flera inspelningar i din egen takt och till och med spola tillbaka. Den kommer också att visa en grafisk sammanfattning av I/O, CPU och väntetider synkroniserade med profildata för direkta frågeprofiler.
Ytterligare anteckningar
Att stiga upp i frågesökningsträdet under tidig fasbehandling ställer in första och sista aktiva tider vid varje profileringsiterator för den överordnade uppgiften, men ackumulerar inte förfluten tid eller CPU-tid. Går upp i trädet under Open och GetRow anropar en parallell uppgift anger senaste aktiva tid, och ackumulerar förfluten tid och CPU-tid vid varje profileringsiterator per uppgift.
Bearbetning i tidig fas är specifik för parallellplaner i radläge. Det är nödvändigt att säkerställa att utbyten initieras i rätt ordning och att alla parallella maskiner fungerar korrekt.
Föräldrauppgiften utför inte alltid hela den tidiga bearbetningen. Tidiga faser börjar vid ett rotutbyte, men hur dessa samtal navigerar i trädet beror på iteratorerna som påträffas. Jag valde en sammanfogning för den här demon eftersom den råkar kräva bearbetning i tidig fas för båda ingångarna.
Tidiga faser vid (till exempel) en parallell hash-join sprider sig endast nedåt i build-ingången. När hash-kopplingen övergår till sin sondfas öppnar den iteratorer på den ingången, inklusive eventuella utbyten. En annan omgång av tidig fas bearbetning initieras, hanterad av (exakt) en av de parallella uppgifterna, som spelar rollen som överordnad uppgift.
När tidig fasbehandling stöter på en parallell gren som innehåller en blockerande iterator, startar den de ytterligare parallella uppgifterna för den grenen och väntar på att dessa producenter ska slutföra sin öppningsfas. Den grenen kan också ha underordnade grenar, som hanteras på samma sätt, rekursivt.
Vissa grenar i en parallellplan i radläge kan behöva köras på en enda tråd (t.ex. på grund av ett globalt aggregat eller topp). Dessa "seriella zoner" körs också på en extra "parallell" uppgift, den enda skillnaden är att det bara finns en uppgift, exekveringskontext och arbetare för den grenen. Tidig fasbehandling fungerar likadant oavsett antalet uppgifter som tilldelats en filial. Till exempel, en "seriell zon" rapporterar tidpunkter för den överordnade uppgiften (eller en parallell uppgift som spelar den rollen) såväl som den enstaka ytterligare uppgiften. Detta visar sig i showplan som data för "tråd 0" (tidiga faser) såväl som "tråd 1" (tilläggsuppgiften).
Avslutande tankar
Allt detta representerar verkligen ett extra lager av komplexitet. Avkastningen på den investeringen är i runtime resursanvändning (främst trådar och minne), minskade synkroniseringsväntningar, ökad genomströmning, potentiellt korrekta prestandamått och en minimerad chans för parallella dödlägen inom sökning.
Även om radläges-parallellism till stor del har överskuggats av den mer moderna batch-mode-parallellexekveringsmotorn, har radlägesdesignen fortfarande en viss skönhet. De flesta iteratorer får låtsas att de fortfarande kör i en serieplan, med nästan all synkronisering, flödeskontroll och schemaläggning som hanteras av utbyten. Den omsorg och uppmärksamhet som framgår av implementeringsdetaljer som tidig fasbearbetning gör att även de största parallella planerna kan genomföras framgångsrikt utan att frågedesignern tänker för mycket på de praktiska svårigheterna.