När en fråga körs, försöker SQL Server-optimeraren hitta den bästa frågeplanen baserat på befintliga index och tillgänglig senaste statistik under en rimlig tid, naturligtvis, om denna plan inte redan är lagrad i serverns cache. Om nej, exekveras frågan enligt denna plan och planen lagras i serverns cache. Om planen redan har byggts för den här frågan, exekveras frågan enligt den befintliga planen.
Vi är intresserade av följande fråga:
Under sammanställning av en frågeplan, vid sortering av möjliga index, om servern inte hittar det bästa indexet, markeras det saknade indexet i frågeplanen, och servern för statistik över sådana index:hur många gånger servern skulle använda detta index och hur mycket den här frågan skulle kosta.
I den här artikeln kommer vi att analysera dessa saknade index – hur man hanterar dem.
Låt oss överväga detta på ett särskilt exempel. Skapa ett par tabeller i vår databas på en lokal och testserver:
[expandera titel =”Kod”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/expand]
Strukturen är enkel och består av två tabeller. Den första tabellen kallas order med sådana fält som en identifierare, datum för försäljning och säljare. Den andra är orderinformation, där vissa varor anges med pris och kvantitet.
Titta på en enkel fråga och dess plan:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
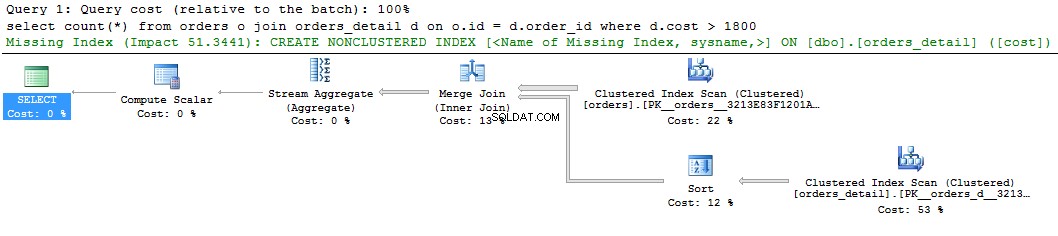
Vi kan se en grön hint om det saknade indexet på den grafiska visningen av frågeplanen. Om du högerklickar på det och väljer "Saknade indexdetaljer ...", kommer det att finnas texten i det föreslagna indexet. Det enda man kan göra är att ta bort kommentarerna i texten och ge indexet ett namn. Skriptet är redo att köras.
Vi kommer inte att bygga indexet vi fick från tipset från SSMS. Istället kommer vi att se om detta index kommer att rekommenderas av dynamiska vyer kopplade till saknade index. Synpunkterna är följande:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
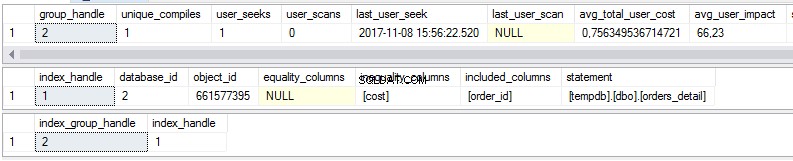
Som vi kan se finns det en del statistik om saknade index i den första vyn:
- Hur många gånger skulle en sökning utföras om det föreslagna indexet fanns?
- Hur många gånger skulle en skanning utföras om det föreslagna indexet fanns?
- Senaste datum och tid då vi använde indexet
- Den aktuella verkliga kostnaden för frågeplanen utan det föreslagna indexet.
Den andra vyn är indextexten:
- Databas
- Objekt/tabell
- Sorterade kolumner
- Kolumner har lagts till för att öka indextäckningen
Den tredje vyn är kombinationen av den första och andra vyn.
Följaktligen är det inte svårt att få ett skript som skulle generera ett skript för att skapa saknade index från dessa dynamiska vyer. Skriptet är som följer:
[expand title="Kod"]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/expand]
För indexeffektivitet matas de saknade indexen ut. Den perfekta lösningen är när denna resultatuppsättning inte returnerar något. I vårt exempel kommer resultatuppsättningen att returnera minst ett index:

När det inte finns tid och du inte känner för att ta itu med klientbuggarna, körde jag frågan, kopierade den första kolumnen och körde den på servern. Efter detta fungerade allt bra.
Jag rekommenderar att du behandlar informationen på dessa index medvetet. Till exempel, om systemet rekommenderar följande index:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
Och dessa index används för sökningen, det är ganska uppenbart att det är mer logiskt att ersätta dessa index med ett som täcker alla tre föreslagna:
create index ix_1 on tbl1 (a,b) include (c,d)
Därför gör vi en översyn av de saknade indexen innan vi distribuerar dem till produktionsservern. Fastän…. Återigen, till exempel, distribuerade jag de förlorade indexen till TFS-servern, vilket ökade den totala prestandan. Det tog minimal tid att utföra denna optimering. Men när jag bytte från TFS 2015 till TFS 2017 stod jag inför problemet att det inte fanns någon uppdatering på grund av dessa nya index. Ändå kan de lätt hittas av masken
select * from sys.indexes where name like 'ix[_]2017%'
Användbart verktyg:
dbForge Index Manager – praktiskt SSMS-tillägg för att analysera status för SQL-index och åtgärda problem med indexfragmentering.