Den här artikeln är den 7:e delen av en serie om namngivna tabelluttryck. I del 5 och del 6 täckte jag de konceptuella aspekterna av vanliga tabelluttryck (CTEs). Den här och nästa månad fokuserar jag på optimeringsöverväganden för CTE.
Jag börjar med att snabbt se över det obehagliga konceptet med namngivna tabelluttryck och demonstrera dess tillämpbarhet på CTE. Jag kommer sedan att fokusera på uthållighetsöverväganden. Jag kommer att prata om persistensaspekter av rekursiva och icke-rekursiva CTE:er. Jag ska förklara när det är vettigt att hålla sig till CTE:er jämfört med när det faktiskt är mer meningsfullt att arbeta med tillfälliga tabeller.
I mina exempel kommer jag att fortsätta använda exempeldatabaserna TSQLV5 och PerformanceV5. Du kan hitta skriptet som skapar och fyller i TSQLV5 här, och dess ER-diagram här. Du kan hitta skriptet som skapar och fyller i PerformanceV5 här.
Utbyte/upplösande
I del 4 av serien, som fokuserade på optimering av härledda tabeller, beskrev jag en process för att lösa ut/substitution av tabelluttryck. Jag förklarade att när SQL Server optimerar en fråga som involverar härledda tabeller, tillämpar den transformationsregler på det initiala trädet av logiska operatorer som produceras av parsern, vilket möjligen flyttar saker runt vad som ursprungligen var tabelluttrycksgränser. Detta händer i den grad att när du jämför en plan för en fråga med hjälp av härledda tabeller med en plan för en fråga som går direkt mot de underliggande bastabellerna där du själv tillämpade nästningslogiken, så ser de likadana ut. Jag beskrev också en teknik för att förhindra unnesting med TOP-filtret med ett mycket stort antal rader som input. Jag visade ett par fall där den här tekniken var ganska praktisk – ett där målet var att undvika fel och ett annat av optimeringsskäl.
TL;DR-versionen av substitution/unnesting av CTE:er är att processen är densamma som den är med härledda tabeller. Om du är nöjd med detta uttalande kan du gärna hoppa över det här avsnittet och hoppa direkt till nästa avsnitt om Persistens. Du kommer inte att missa något viktigt som du inte har läst tidigare. Men om du är som jag vill du förmodligen ha bevis på att det verkligen är fallet. Sedan vill du antagligen fortsätta att läsa det här avsnittet och testa koden som jag använder när jag återbesöker nyckelexempel som jag tidigare demonstrerat med härledda tabeller och konverterar dem till CTE:er.
I del 4 demonstrerade jag följande fråga (vi kallar den fråga 1):
ANVÄND TSQLV5; SELECT orderid, orderdate FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sales.Orders WHERE orderdate>='20180101' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D1 WHERE orderdate>='20180201' ) AS D2 WHERE orderdate>='20180301' WHERE orderdatum>='20180401';
Frågan involverar tre kapslingsnivåer av härledda tabeller, plus en yttre fråga. Varje nivå filtrerar olika beställningsdatum. Planen för fråga 1 visas i figur 1.
 Figur 1:Exekveringsplan för fråga 1
Figur 1:Exekveringsplan för fråga 1
Planen i figur 1 visar tydligt att avveckling av de härledda tabellerna ägde rum eftersom alla filterpredikat slogs samman till ett enda omfattande filterpredikat.
Jag förklarade att du kan förhindra odlingsprocessen genom att använda ett meningsfullt TOP-filter (i motsats till TOP 100 PROCENT) med ett mycket stort antal rader som indata, som följande fråga visar (vi kallar det fråga 2):
SELECT orderid, orderdate FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) *FROM (VÄLJ TOP (9223372036854775807)) * FROM ( SELECT TOP (9223372036854775807) Orders DERE FRANKRIKE Från 15807) *Orders WROMFrån 2012-08-2012. 20180201' ) AS D2 WHERE orderdate>='20180301' ) AS D3 WHERE orderdate>='20180401';
Planen för fråga 2 visas i figur 2.
 Figur 2:Exekveringsplan för fråga 2
Figur 2:Exekveringsplan för fråga 2
Planen visar tydligt att odling inte ägde rum eftersom man effektivt kan se de härledda tabellgränserna.
Låt oss prova samma exempel med CTE. Här är fråga 1 konverterad för att använda CTE:
MED C1 AS ( VÄLJ * FRÅN Försäljning. Ordrar DÄR orderdatum>='20180101' ), C2 AS ( VÄLJ * FRÅN C1 DÄR orderdatum>='20180201' ), C3 AS ( VÄLJ * FRÅN C2 VAR orderdatum>=' 20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Du får exakt samma plan som visades tidigare i figur 1, där du kan se att häckning ägde rum.
Här är fråga 2 konverterad för att använda CTE:
MED C1 AS ( VÄLJ TOP (9223372036854775807) * FROM Sales.Orders WHERE orderdate>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * FROM C1 WHERE orderdate, C1 WHERE TOP (9223372036854775807) * FROM C2 WHERE orderdate>='20180301' ) SELECT orderid, orderdate FROM C3 WHERE orderdate>='20180401';
Du får samma plan som visat tidigare i figur 2, där du kan se att odling inte ägde rum.
Låt oss sedan återgå till de två exemplen som jag använde för att demonstrera det praktiska i tekniken för att förhindra odling – bara den här gången med hjälp av CTE.
Låt oss börja med den felaktiga frågan. Följande fråga försöker returnera beställningsrader med en rabatt som är större än den lägsta rabatten och där den ömsesidiga rabatten är större än 10:
VÄLJ orderid, productid, discount FROM Sales.OrderDetails WHERE rabatt> (VÄLJ MIN(rabatt) FROM Sales.OrderDetails) OCH 1,0 / rabatt> 10,0;
Minsta rabatt kan inte vara negativ, utan är snarare noll eller högre. Så du tänker förmodligen att om en rad har en nollrabatt bör det första predikatet utvärderas till falskt, och att en kortslutning bör förhindra försöket att utvärdera det andra predikatet och på så sätt undvika ett fel. Men när du kör den här koden får du ett divideringsfel med noll:
Msg 8134, Level 16, State 1, Rad 99 Dividera med noll fel påträffat.
Problemet är att även om SQL Server stöder ett kortslutningskoncept på den fysiska bearbetningsnivån, finns det ingen garanti för att den kommer att utvärdera filterpredikaten i skriven ordning från vänster till höger. Ett vanligt försök att undvika sådana fel är att använda ett namngivet tabelluttryck som hanterar den del av filtreringslogiken som du vill ska utvärderas först, och låta den yttre frågan hantera filtreringslogiken som du vill ska utvärderas efter det. Här är försöket med lösningen med en CTE:
MED C AS ( VÄLJ * FRÅN Sales.OrderDetails WHERE rabatt> (VÄLJ MIN(rabatt) FRÅN Sales.OrderDetails) ) VÄLJ orderid, productid, discount FROM C WHERE 1,0 / rabatt> 10,0;
Tyvärr resulterar dock avvecklingen av tabelluttrycket i en logisk motsvarighet till den ursprungliga lösningsfrågan, och när du försöker köra den här koden får du ett divideringsfel med noll igen:
Msg 8134, Level 16, State 1, Line 108 Divider with noll fel påträffat.
Genom att använda vårt trick med TOP-filtret i den inre frågan, förhindrar du att tabelluttrycket odlas, så här:
MED C AS ( VÄLJ TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE rabatt> (VÄLJ MIN(rabatt) FROM Sales.OrderDetails) ) VÄLJ orderid, productid, rabatt FROM C WHERE 1,0 / rabatt> 10.0>Den här gången körs koden utan några fel.
Låt oss gå vidare till exemplet där du använder tekniken för att förhindra unnesting av optimeringsskäl. Följande kod returnerar endast avsändare med ett maximalt beställningsdatum som är den 1 januari 2018 eller senare:
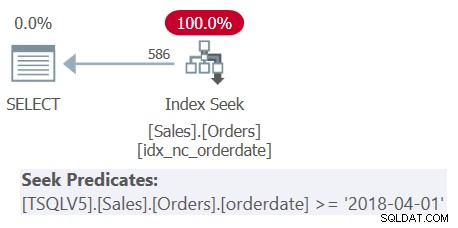
ANVÄND PerformanceV5; MED C AS ( VÄLJ S.shipperid, (VÄLJ MAX(O.orderdatum) FRÅN dbo.Order AS O. WHERE O.shipperid =S.shipperid) SOM maxod FRÅN dbo.Shippers AS S ) VÄLJ shipperid, maxod FRÅN C WHERE maxod> ='20180101';Om du undrar varför inte använda en mycket enklare lösning med en grupperad fråga och ett HAVING-filter, har det att göra med densiteten för shipperid-kolumnen. Ordertabellen har 1 000 000 beställningar, och försändelserna av dessa beställningar hanterades av fem avsändare, vilket innebär att varje avsändare i genomsnitt hanterade 20 % av beställningarna. Planen för en grupperad fråga som beräknar det maximala beställningsdatumet per avsändare skulle skanna alla 1 000 000 rader, vilket resulterade i tusentals sidläsningar. Faktum är att om du bara markerar CTE:s inre fråga (vi kallar det fråga 3) och beräknar det maximala orderdatumet per avsändare och kontrollerar dess utförandeplan, får du planen som visas i figur 3.
Figur 3:Exekveringsplan för fråga 3
Planen skannar fem rader i det klustrade indexet på avsändare. Per avsändare tillämpar planen en sökning mot ett täckande index på beställningar, där (avsändare, orderdatum) är de ledande nycklarna för index, som går direkt till sista raden i varje avsändarsektion på bladnivå för att dra det maximala beställningsdatumet för det aktuella befraktare. Eftersom vi bara har fem avsändare finns det bara fem indexsökoperationer, vilket resulterar i en mycket effektiv plan. Här är de prestandamått som jag fick när jag körde CTE:s inre fråga:
varaktighet:0 ms, CPU:0 ms, läser:15Men när du kör den kompletta lösningen (vi kallar den fråga 4) får du en helt annan plan, som visas i figur 4.
Figur 4:Utförandeplan för fråga 4
Det som hände är att SQL Server avkapslade tabelluttrycket och konverterade lösningen till en logisk motsvarighet till en grupperad fråga, vilket resulterade i en fullständig genomsökning av indexet på order. Här är prestandasiffrorna som jag fick för den här lösningen:
varaktighet:316 ms, CPU:281 ms, läsning:3854Vad vi behöver här är att förhindra att tabelluttrycket odlas, så att den inre frågan optimeras med sök mot indexet på order, och för att den yttre frågan bara ska resultera i ett tillägg av en filteroperator i planen. Du uppnår detta med vårt trick genom att lägga till ett TOP-filter till den inre frågan, som så (vi kallar den här lösningen för fråga 5):
MED C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid , maxod FROM C WHERE maxod>='20180101';Planen för denna lösning visas i figur 5.
Figur 5:Exekveringsplan för fråga 5
Planen visar att den önskade effekten uppnåddes, och följaktligen bekräftar prestationssiffrorna detta:
varaktighet:0 ms, CPU:0 ms, läser:15Så, våra tester bekräftar att SQL Server hanterar substitution/unnesting av CTE:er precis som det gör för härledda tabeller. Det betyder att du inte bör föredra det ena framför det andra på grund av optimeringsskäl, snarare på grund av konceptuella skillnader som är viktiga för dig, som diskuteras i del 5.
Ihärdighet
En vanlig missuppfattning om CTE:er och namngivna tabelluttryck i allmänhet är att de fungerar som en sorts persistensvehikel. Vissa tror att SQL Server behåller resultatuppsättningen av den inre frågan till en arbetstabell, och att den yttre frågan faktiskt interagerar med den arbetstabellen. I praktiken kvarstår inte vanliga icke-rekursiva CTE:er och härledda tabeller. Jag beskrev den unnesting-logik som SQL Server tillämpar när man optimerar en fråga som involverar tabelluttryck, vilket resulterar i en plan som interagerar direkt med de underliggande bastabellerna. Observera att optimeraren kan välja att använda arbetstabeller för att bevara mellanliggande resultatuppsättningar om det är vettigt att göra det antingen av prestandaskäl eller andra, som Halloween-skydd. När den gör det ser du Spool- eller Index Spool-operatörer i planen. Sådana val är dock inte relaterade till användningen av tabelluttryck i frågan.
Rekursiva CTE
Det finns ett par undantag där SQL Server behåller tabelluttryckets data. En är användningen av indexerade vyer. Om du skapar ett klustrade index på en vy, behåller SQL Server den inre frågans resultatuppsättning i vyns klustrade index och håller det synkroniserat med eventuella ändringar i de underliggande bastabellerna. Det andra undantaget är när du använder rekursiva frågor. SQL Server måste bevara de mellanliggande resultatuppsättningarna för ankaret och de rekursiva frågorna i en spool så att den kan komma åt den sista omgångens resultatuppsättning representerad av den rekursiva referensen till CTE-namnet varje gång den rekursiva medlemmen exekveras.
För att demonstrera detta använder jag en av de rekursiva frågorna från del 6 i serien.
Använd följande kod för att skapa tabellen Employees i tempdb-databasen, fylla i den med exempeldata och skapa ett stödjande index:
STÄLL IN NOCOUNT PÅ; ANVÄND tempdb; SLIPP TABELL OM FINNS dbo.Anställda; GÅ SKAPA TABELL dbo.Employees ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENCER dbo.Employees, empid VARCHAR(25)
NOLL MON NULL ( NOT NULL MON NULL) CHECK; INSERT INTO dbo.Employees(empid, mgrid, anställningsnamn, lön) VALUES(1, NULL, 'David' , $10000.00), (2, 1, 'Eitan' , $7000.00), (3, 1, 'Ina' , $7500.00) , (4, 2, 'Seraph' , $5000.00), (5, 2, 'Jiru' , $5500.00), (6, 2, 'Steve', $4500.00), (7, 3, 'Aaron' , $5000.00), ( 8, 5, 'Lilach' , $3500.00), (9, 7, 'Rita', $3000.00), (10, 5, 'Sean', $3000.00), (11, 7, 'Gabriel', $3000.00), (12, 9, 'Emilia' , $2000.00), (13, 9, 'Michael', $2000.00), (14, 9, 'Didi', $1500.00); SKAPA UNIKT INDEX idx_unc_mgrid_empid PÅ dbo.Employees(mgrid, empid) INCLUDE(empname, lön); GÅJag använde följande rekursiva CTE för att returnera alla underordnade till en rothanterare för inmatningsunderträd, med anställd 3 som indatahanterare i det här exemplet:
DECLARE @root AS INT =3; MED C AS ( VÄLJ empid, mgrid, empname FRÅN dbo. Anställda VAR empid =@root UNION ALLA VÄLJ S.empid, S.mgrid, S.empname FRÅN C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) VÄLJ empid, mgrid, empname FRÅN C;Planen för den här frågan (vi kallar den fråga 6) visas i figur 6.
Figur 6:Exekveringsplan för fråga 6
Observera att det allra första som händer i planen, till höger om root SELECT-noden, är skapandet av en B-trädbaserad arbetstabell representerad av Index Spool-operatorn. Den övre delen av planen hanterar ankarmedlemmens logik. Den hämtar indatamedarbetarraderna från det klustrade indexet på anställda och skriver det till spoolen. Den nedre delen av planen representerar den rekursiva medlemmens logik. Den exekveras upprepade gånger tills den returnerar en tom resultatuppsättning. Den yttre inmatningen till Nested Loops-operatören hämtar managers från föregående omgång från spolen (Table Spool-operatör). Den inre ingången använder en Index Seek-operator mot ett icke-klustrat index som skapats på Employees(mgrid, empid) för att få direkt underordnade till cheferna från föregående omgång. Resultatuppsättningen för varje exekvering av den nedre delen av planen skrivs också till indexspolen. Lägg märke till att allt som allt skrevs 7 rader till spolen. En som returnerades av ankarmedlemmen och 6 till som returnerades av alla avrättningar av den rekursiva medlemmen.
För övrigt är det intressant att lägga märke till hur planen hanterar standardgränsen för maxrekursion, som är 100. Observera att den nedre Compute Scalar-operatören fortsätter att öka en intern räknare som kallas Expr1011 med 1 för varje exekvering av den rekursiva medlemmen. Sedan sätter Assert-operatören en flagga till noll om denna räknare överstiger 100. Om detta händer stoppar SQL Server exekveringen av frågan och genererar ett fel.
När man inte ska fortsätta
Tillbaka till icke-rekursiva CTE:er, som normalt inte blir bestående, det är upp till dig att ta reda på ur ett optimeringsperspektiv när det är bra att använda dem kontra faktiska persistensverktyg som tillfälliga tabeller och tabellvariabler istället. Jag ska gå igenom ett par exempel för att visa när varje tillvägagångssätt är mer optimalt.
Låt oss börja med ett exempel där CTE:er fungerar bättre än tillfälliga tabeller. Det är ofta fallet när du inte har flera utvärderingar av samma CTE, snarare kanske bara en modulär lösning där varje CTE utvärderas endast en gång. Följande kod (vi kallar den fråga 7) frågar ordertabellen i prestandadatabasen, som har 1 000 000 rader, för att returnera beställningsår under vilka mer än 70 olika kunder har lagt beställningar:
ANVÄND PerformanceV5; MED C1 AS ( VÄLJ ÅR(orderdatum) SOM beställningsår, custid FRÅN dbo.Order ), C2 AS ( VÄLJ beställningsår, COUNT(DISTINCT custid) SOM numcusts FROM C1 GROUP BY orderyear ) SELECT orderyear, numcusts FROM C2 WHERE numcusts> 70; /pre>Den här frågan genererar följande utdata:
orderyear numcusts ------------------ ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Jag körde den här koden med SQL Server 2019 Developer Edition och fick planen som visas i figur 7.
Figur 7:Utförandeplan för fråga 7
Lägg märke till att avvecklingen av CTE:n resulterade i en plan som hämtar data från ett index på ordertabellen och inte involverar någon spoolning av CTE:s inre frågeresultatuppsättning. Jag fick följande prestandanummer när jag körde den här frågan på min dator:
varaktighet:265 ms, CPU:828 ms, läser:3970, skriver:0Låt oss nu prova en lösning som använder tillfälliga tabeller istället för CTE (vi kallar det lösning 8), som så:
SELECT YEAR(orderdate) AS orderyear, custid INTO #T1 FROM dbo.Orders; SELECT orderyear, COUNT(DISTINCT custid) AS numcusts INTO #T2 FROM #T1 GROUP BY orderyear; VÄLJ beställningsår, numcusts FRÅN #T2 WHERE numcusts> 70; SLIPP TABELL #T1, #T2;Planerna för denna lösning visas i figur 8.
Figur 8:Planer för lösning 8
Lägg märke till att tabellinfogningsoperatorerna skriver resultatuppsättningarna till de temporära tabellerna #T1 och #T2. Den första är särskilt dyr eftersom den skriver 1 000 000 rader till #T1. Här är prestationssiffrorna som jag fick för det här utförandet:
varaktighet:454 ms, CPU:1517 ms, läser:14359, skriver:359Som du kan se är lösningen med CTE:erna mycket mer optimal.
När ska man fortsätta
Så är det så att en modulär lösning som endast innebär en enda utvärdering av varje CTE alltid är att föredra framför att använda tillfälliga tabeller? Inte nödvändigtvis. I CTE-baserade lösningar som involverar många steg, och resulterar i utarbetade planer där optimeraren behöver tillämpa massor av kardinalitetsuppskattningar på många olika punkter i planen, kan du sluta med ackumulerade felaktigheter som resulterar i suboptimala val. En av teknikerna för att försöka ta itu med sådana fall är att bevara vissa mellanliggande resultatuppsättningar själv i tillfälliga tabeller, och till och med skapa index på dem om det behövs, vilket ger optimeraren en nystart med ny statistik, vilket ökar sannolikheten för bättre kvalitativa uppskattningar av kardinalitet som förhoppningsvis leda till mer optimala val. Huruvida detta är bättre än en lösning som inte använder tillfälliga tabeller är något som du måste testa. Ibland är det värt det att kompromissa med extra kostnad för bestående mellanliggande resultatuppsättningar för att få bättre kvalitet på kardinalitetsuppskattningar.
Ett annat typiskt fall där användning av tillfälliga tabeller är det föredragna tillvägagångssättet är när den CTE-baserade lösningen har flera utvärderingar av samma CTE, och CTE:s inre fråga är ganska dyr. Tänk på följande CTE-baserade lösning (vi kallar den Query 9), som matchar för varje orderår och månad ett annat orderår och månad som har närmast orderantal:
WITH OrdCount AS ( SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numbers FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate) ) SELECT O1.orderyear, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FRÅN OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders FRÅN OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2;Den här frågan genererar följande utdata:
orderyear ordermonth nummorders orderyear2 ordermonth2 nummorders2 ----------- ------------------ ------------------ --- ----------- ---------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 1 2056 4 2056 2015 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 201 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 211855 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 ROWS AV)Planen för fråga 9 visas i figur 9.
Figur 9:Utförandeplan för fråga 9
Den övre delen av planen motsvarar instansen av OrdCount CTE som kallas O1. Denna referens resulterar i en utvärdering av CTE OrdCount. Den här delen av planen hämtar raderna från ett index i ordertabellen, grupperar dem efter år och månad, och sammanställer antalet order per grupp, vilket resulterar i 49 rader. Den nedre delen av planen motsvarar den korrelerade härledda tabellen O2, som appliceras per rad från O1, och exekveras därför 49 gånger. Varje exekvering frågar efter OrdCount CTE och resulterar därför i en separat utvärdering av CTE:s inre fråga. Du kan se att den nedre delen av planen skannar alla rader från indexet på Order, grupper och aggregerar dem. Du får i princip totalt 50 utvärderingar av CTE, vilket resulterar i att 50 gånger skanna de 1 000 000 raderna från order, gruppera och aggregera dem. Det låter inte som en särskilt effektiv lösning. Här är prestandamåtten som jag fick när jag körde den här lösningen på min dator:
varaktighet:16 sekunder, CPU:56 sekunder, läser:130404, skriver:0Med tanke på att det bara är några dussin månader inblandade, vad som skulle vara mycket effektivare är att använda en tillfällig tabell för att lagra resultatet av en enda aktivitet som grupperar och aggregerar raderna från beställningar, och sedan har både yttre och inre indata av APPLY-operatören interagerar med den temporära tabellen. Här är lösningen (vi kallar det lösning 10) med en tillfällig tabell istället för CTE:
SELECT YEAR(orderdate) AS orderyear, MONTH(orderdate) AS ordermonth, COUNT(*) AS numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(orderdate), MONTH(orderdate); SELECT O1.orderyear, O1.ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM #OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth , O2.numorders FRÅN #OrdCount AS O2 WHERE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; SLIPP TABELL #OrdCount;Här är det inte mycket mening med att indexera den temporära tabellen, eftersom TOP-filtret är baserat på en beräkning i dess beställningsspecifikation, och därför är en sortering oundviklig. Det kan dock mycket väl vara så att det i andra fall, med andra lösningar, även skulle vara relevant för dig att överväga att indexera dina tillfälliga tabeller. I vilket fall som helst visas planen för denna lösning i figur 10.
Figur 10:Exekveringsplaner för lösning 10
Observera i den översta planen hur tunga lyft som involverar att skanna 1 000 000 rader, gruppera och aggregera dem, bara sker en gång. 49 rader skrivs till den temporära tabellen #OrdCount, och sedan interagerar den nedre planen med den temporära tabellen för både de yttre och inre ingångarna för Nested Loops-operatören, som hanterar APPLY-operatorns logik.
Här är prestandasiffrorna som jag fick för utförandet av den här lösningen:
varaktighet:0,392 sekunder, CPU:0,5 sekunder, läser:3636, skriver:3Den är snabbare i storleksordningar än den CTE-baserade lösningen.
Vad händer härnäst?
I den här artikeln började jag täckningen av optimeringsöverväganden relaterade till CTE. Jag visade att processen för avveckling/substitution som äger rum med härledda tabeller fungerar på samma sätt med CTE. Jag diskuterade också det faktum att icke-rekursiva CTE:er inte blir bestående och förklarade att när persistens är en viktig faktor för prestanda för din lösning måste du hantera det själv genom att använda verktyg som tillfälliga tabeller och tabellvariabler. Nästa månad kommer jag att fortsätta diskussionen genom att täcka ytterligare aspekter av CTE-optimering.