Jag skrev nyligen ett inlägg om DISTINCT och GROUP BY. Det var en jämförelse som visade att GROUP BY generellt sett är ett bättre alternativ än DISTINCT. Det finns på en annan sida, men kom tillbaka till sqlperformance.com direkt efter...
En av frågejämförelserna som jag visade i det inlägget var mellan en GROUP BY och DISTINCT för en underfråga, vilket visar att DISTINCT är mycket långsammare, eftersom den måste hämta produktnamnet för varje rad i försäljningstabellen, snarare än bara för varje olika produkt-ID. Detta är ganska tydligt från frågeplanerna, där du kan se att i den första frågan arbetar Aggregate på data från bara en tabell, snarare än på resultaten av sammanfogningen. Åh, och båda frågorna ger samma 266 rader.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID;
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od;

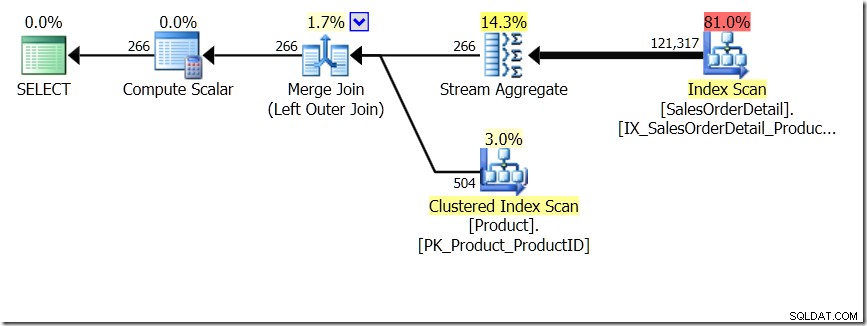
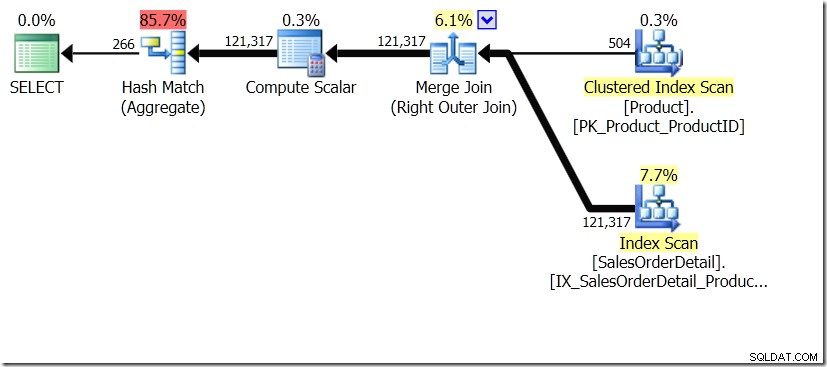
Nu har det påpekats, inklusive av Adam Machanic (@adammachanic) i en tweet som hänvisar till Aarons inlägg om GROUP BY v DISTINCT att de två frågorna är väsentligt olika, att man faktiskt frågar efter uppsättningen distinkta kombinationer på resultaten av sub-query, snarare än att köra sub-query över de distinkta värden som skickas in. Det är vad vi ser i planen och är anledningen till att prestandan är så annorlunda.
Saken är den att vi alla skulle anta att resultaten kommer att vara identiska.
Men det är ett antagande och det är inte bra.
Jag kommer för ett ögonblick att föreställa mig att frågeoptimeraren har kommit på en annan plan. Jag använde tips för detta, men som ni vet kan frågeoptimeraren välja att skapa planer i alla möjliga former av alla möjliga skäl.
select od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
group by od.ProductID
option (loop join);
select distinct od.ProductID,
(select Name
from Production.Product p
where p.ProductID = od.ProductID) as ProductName
from Sales.SalesOrderDetail od
option (loop join);
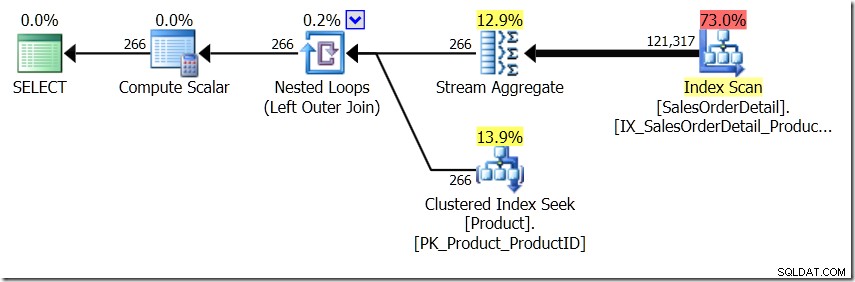
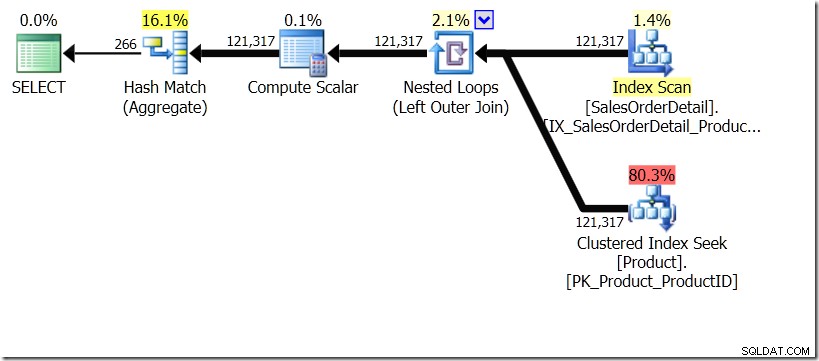
I den här situationen gör vi antingen 266 sökningar i produkttabellen, en för varje produkt-ID som vi är intresserade av, eller 121 317 sökningar. Så om vi funderar på ett visst produkt-ID vet vi att vi kommer att få tillbaka ett enda namn från det första. Och vi antar att vi kommer att få tillbaka ett enda namn för det produkt-ID:t, även om vi måste be om det hundra gånger. Vi antar bara att vi kommer att få samma resultat tillbaka.
Men vad händer om vi inte gör det?
Det här låter som en sak på isoleringsnivå, så låt oss använda NOLOCK när vi träffar produkttabellen. Och låt oss köra (i ett annat fönster) ett skript för att ändra texten i namnkolumnerna. Jag kommer att göra det om och om igen för att försöka få några av ändringarna mellan min fråga.
update Production.Product set Name = cast(newid() as varchar(36)); go 1000
Nu är mina resultat annorlunda. Planerna är desamma (förutom antalet rader som kommer ut från Hash Aggregate i den andra frågan), men mina resultat är annorlunda.
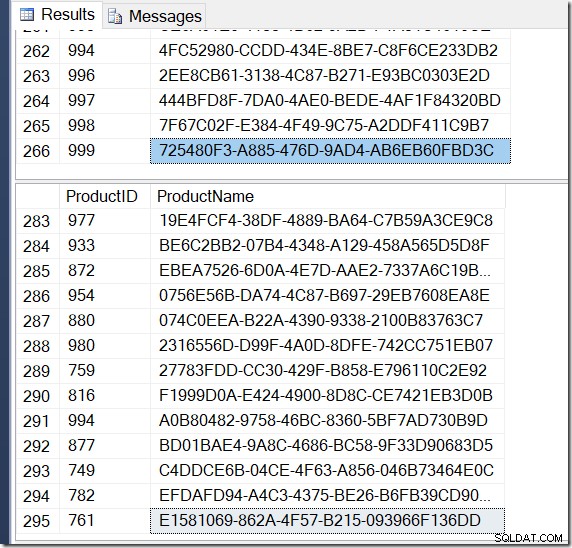
Visst, jag har fler rader med DISTINCT, eftersom den hittar olika namnvärden för samma produkt-ID. Och jag har inte nödvändigtvis 295 rader. Om jag kör det, kanske jag får 273, eller 300, eller möjligen, 121 317.
Det är inte svårt att hitta ett exempel på ett produkt-ID som visar flera namnvärden, vilket bekräftar vad som händer.

För att säkerställa att vi inte ser dessa rader i resultaten måste vi helt klart antingen INTE använda DISTINCT eller också använda en strängare isoleringsnivå.
Saken är den att även om jag nämnde att jag använde NOLOCK för det här exemplet så behövde jag det inte. Denna situation uppstår även med READ COMMITTED, som är standardisoleringsnivån på många SQL Server-system.
Du förstår, vi behöver isoleringsnivån REPEATABLE READ för att undvika denna situation, för att hålla låsen på varje rad när den har lästs. Annars kan en separat tråd ändra data, som vi såg.
Men... jag kan inte visa att resultaten är fixade, eftersom jag inte kunde undvika ett dödläge i frågan.
Så låt oss ändra villkoren genom att se till att vår andra fråga är ett mindre problem. Istället för att uppdatera hela tabellen åt gången (vilket är mycket mindre troligt i den verkliga världen ändå), låt oss bara uppdatera en enskild rad åt gången.
declare @id int = 1; declare @maxid int = (select count(*) from Production.Product); while (@id < @maxid) begin with p as (select *, row_number() over (order by ProductID) as rn from Production.Product) update p set Name = cast(newid() as varchar(36)) where rn = @id; set @id += 1; end go 100
Nu kan vi fortfarande demonstrera problemet under en lägre isoleringsnivå, till exempel LÄS ENGÅNGAD eller LÄS OBJEKTAD (även om du kan behöva köra frågan flera gånger om du får 266 första gången, eftersom chansen att uppdatera en rad under sökningen är mindre), och nu kan vi visa att REPEATABLE READ fixar det (oavsett hur många gånger vi kör frågan).
REPETERBAR LÄS gör vad det står på burken. När du har läst en rad i en transaktion är den låst för att se till att du kan upprepa läsningen och få samma resultat. De lägre isoleringsnivåerna tar inte ut dessa lås förrän du försöker ändra data. Om din frågeplan aldrig behöver upprepa en läsning (som är fallet med formen på våra GROUP BY-planer), kommer du inte att behöva REPETERBAR LÄS.
Förmodligen borde vi alltid använda de högre isoleringsnivåerna, såsom REPEATBAR LÄS eller SERIALISERBAR, men allt handlar om att ta reda på vad våra system behöver. Dessa nivåer kan introducera oönskad låsning, och SNAPSHOT-isoleringsnivåer kräver versionshantering som också kommer med ett pris. För mig tycker jag att det är en avvägning. Om jag ber om en fråga som kan påverkas av att data ändras, kan jag behöva höja isoleringsnivån ett tag.
Helst uppdaterar du helt enkelt inte data som just har lästs och som kan behöva läsas igen under sökningen, så att du inte behöver REPETERBAR LÄS. Men det är definitivt värt att förstå vad som kan hända, och inse att detta är den typen av scenario när DISTINCT och GROUP BY kanske inte är samma sak.
@rob_farley