
Det här är inte heller bra fragmentering
Förra månaden skrev jag om oväntad klustrad indexfragmentering, så den här gången skulle jag vilja diskutera några av de saker du kan göra för att undvika att indexfragmentering inträffar. Jag antar att du har läst det tidigare inlägget och är bekant med termerna jag definierade där, och under resten av den här artikeln, när jag säger "fragmentering" syftar jag på både den logiska fragmenteringen och problem med låg siddensitet.
Välj en bra klusternyckel
Den dyraste datastrukturen att arbeta på för att ta bort fragmentering är det klustrade indexet för en tabell, eftersom det är den största strukturen eftersom den innehåller all tabelldata. Ur ett fragmenteringsperspektiv är det vettigt att välja en klusternyckel som matchar tabellens infogningsmönster, så det finns ingen möjlighet att en infogning sker på en sida där det inte finns något utrymme och därmed orsaka en siddelning och introducerar fragmentering.
Vad som utgör den bästa klusternyckeln för en given tabell är en fråga för mycket debatt, men i allmänhet kommer du inte att gå fel om din klusternyckel har följande enkla egenskaper:
- Smal (dvs. så få kolumner som möjligt)
- Statisk (dvs. du uppdaterar den aldrig)
- Unik
- Ständigt ökande
Det är den ständigt ökande egenskapen som är den viktigaste för att förhindra fragmentering, eftersom den undviker slumpmässiga infogningar som kan orsaka siddelning på redan fulla sidor. Exempel på ett sådant nyckelval är kolumner för int-identitet och bigint-identitet, eller till och med en sekventiell GUID från NEWSEQUENTIALID()-funktionen.
Med dessa typer av nycklar kommer nya rader att ha ett nyckelvärde som garanterat är högre än alla andra i tabellen, och därför kommer den nya radens insättningspunkt att vara i slutet av sidan längst till höger i den klustrade indexstrukturen. Så småningom kommer de nya raderna att fylla upp den sidan och ytterligare en sida kommer att läggas till på höger sida av indexet, men utan att någon skadlig siddelning inträffar.
Nu, om du har en klustrad indexnyckel som inte ökar ständigt, kan det vara en mycket komplex och obehaglig procedur att ändra den till en ständigt ökande, så oroa dig inte – istället kan du använda en fyllningsfaktor som jag diskuterar nedan.
Förresten, för en mycket djupare insikt i att välja en klusternyckel och alla konsekvenser av den, kolla in Kimberlys Clustering Key-bloggkategori (läs nerifrån och upp).
Uppdatera inte indexnyckelkolumner
Närhelst en nyckelkolumn uppdateras är det inte bara en enkel uppdatering på plats, även om många ställen online och i böcker säger att det är det (de har fel). En nyckelkolumn kan inte uppdateras på plats eftersom det nya nyckelvärdet då skulle innebära att raden ligger i fel nyckelordning för indexet. Istället översätts en nyckelkolumnuppdatering till en radradering plus en hel radinfogning med det nya nyckelvärdet. Om sidan där den nya raden ska infogas inte har tillräckligt med utrymme kommer en siddelning att ske, vilket orsakar fragmentering.
Att undvika uppdateringar av nyckelkolumner bör vara lätt att göra för det klustrade indexet, eftersom det är en dålig design som kräver uppdatering av klusternyckeln för en tabellrad. För icke-klustrade index är det dock oundvikligt om uppdateringar av tabellen råkar involvera kolumner där det finns ett icke-klustrat index. I dessa fall måste du använda en fyllnadsfaktor.
Uppdatera inte kolumner med variabel längd
Det här är lättare sagt än gjort. Om du måste använda kolumner med variabel längd och det är möjligt att de uppdateras, är det möjligt att de kan växa och därför kräver mer utrymme för den uppdaterade raden, vilket leder till en siddelning om sidan redan är full.
Det finns några saker du kan göra för att undvika fragmentering i det här fallet:
- Använd en fyllnadsfaktor
- Använd en kolumn med fast längd istället, om overheaden för alla extra utfyllnadsbytes är ett mindre problem än fragmentering eller användning av en fyllningsfaktor
- Använd ett platshållarvärde för att "reservera" utrymme för kolumnen – det här är ett knep som du kan använda om programmet går in i en ny rad och sedan kommer tillbaka för att fylla i några av detaljerna, vilket orsakar kolumnexpansion med variabel längd
- Utför en radera plus infogning istället för en uppdatering
Använd en fyllningsfaktor
Som du kan se är många av sätten att undvika fragmentering obehagliga eftersom de involverar applikations- eller schemaändringar, så att använda en fyllningsfaktor är ett enkelt sätt att mildra fragmentering.
En indexfyllningsfaktor är en inställning för indexet som anger hur mycket tomt utrymme som ska lämnas på varje sida på bladnivå när indexet skapas, byggs om eller omorganiseras. Tanken är att det finns tillräckligt med ledigt utrymme på sidan för att tillåta slumpmässiga infogningar eller radtillväxt (från en versionstagg som läggs till eller uppdaterade kolumner med variabel längd) utan att sidan fylls upp och kräver en siddelning. Men så småningom kommer sidan att fyllas upp, och därför måste det lediga utrymmet periodvis uppdateras genom att bygga om eller omorganisera indexet (allmänt kallat att utföra indexunderhåll). Tricket är att hitta rätt fyllningsfaktor att använda, tillsammans med rätt periodicitet för indexunderhåll.
Du kan läsa mer om att sätta en fyllnadsfaktor i MSDN här. Gå inte i fällan att ställa in fyllfaktorn för hela instansen (med sp_configure) eftersom det betyder att alla index kommer att byggas om eller omorganiseras med det fyllfaktorvärdet, även de index som inte har några fragmenteringsproblem. Du vill inte att dina stora klustrade index, med fina ständigt ökande nycklar, alla ska ha 30 % av sitt utrymme på bladnivå bortkastat för att förbereda sig för slumpmässiga insättningar som aldrig kommer att hända. Det är mycket bättre att ta reda på vilka index som faktiskt påverkas av fragmentering och bara ställa in en fyllningsfaktor för dessa.
Det finns inget rätt svar eller magisk formel jag kan ge dig för detta. Den allmänt accepterade praxisen är att införa en fyllningsfaktor på 70 (vilket innebär att 30 % ledigt utrymme lämnas) för de index där fragmentering är ett problem, övervaka hur snabbt fragmentering sker och sedan ändra antingen fyllningsfaktorn eller indexunderhållsfrekvensen (eller båda).
Ja, det betyder att du medvetet slösar utrymme i indexen för att undvika fragmentering, men det är en bra avvägning att göra med tanke på hur dyra siddelningar är och hur skadlig fragmentering kan vara för prestanda. Och ja, trots vad vissa kanske säger är detta fortfarande viktigt även om du använder SSD-enheter.
Sammanfattning
Det finns några enkla saker du kan göra för att undvika att fragmentering inträffar, men så fort du kommer in i icke-klustrade index, eller använder ögonblicksbildsisolering eller läsbara sekundärer, får fragmentering upp sitt fula huvud och du måste försöka förhindra det.
Tänk nu inte att du ska sätta en fyllnadsfaktor på 70 på alla dina instanser – du måste välja och ställa in dem noggrant, som jag beskrev ovan.
Och glöm inte SQL Sentry Fragmentation Manager, som du kan använda (som ett tillägg till Performance Advisor) för att ta reda på var fragmenteringsproblemen finns och sedan åtgärda dem. Till exempel, på fliken Index kan du enkelt sortera dina index efter högsta fragmentering först (och, om du vill, tillämpa ett filter på radräkningskolumnen för att ignorera dina mindre tabeller):
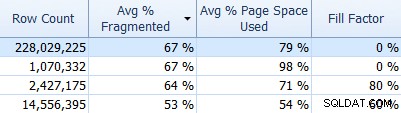
Och se sedan om dessa index använder standardfyllningsfaktorn (0%), eller kanske en icke-standardfyllningsfaktor, vilket kanske inte passar bra för dina data och DML-mönster. Jag låter dig gissa vilka i skärmdumpen ovan jag skulle vara mest intresserad av att undersöka. Att implementera lämpligare indexfyllningsfaktorer är det enklaste sättet att lösa eventuella problem du upptäcker.