Den här artikeln är den fjärde delen i en serie om tabelluttryck. I del 1 och del 2 behandlade jag den konceptuella behandlingen av härledda tabeller. I del 3 började jag ta upp optimeringsöverväganden för härledda tabeller. Denna månad täcker jag ytterligare aspekter av optimering av härledda tabeller; specifikt fokuserar jag på substitution/unnesting av härledda tabeller.
I mina exempel kommer jag att använda exempeldatabaser som heter TSQLV5 och PerformanceV5. Du kan hitta skriptet som skapar och fyller i TSQLV5 här, och dess ER-diagram här. Du kan hitta skriptet som skapar och fyller i PerformanceV5 här.
Unnesting/substitution
Avkapsling/ersättning av tabelluttryck är en process där man tar en fråga som involverar kapsling av tabelluttryck, och som om man ersätter den med en fråga där den kapslade logiken elimineras. Jag bör betona att det i praktiken inte finns någon faktisk process där SQL Server konverterar den ursprungliga frågesträngen med den kapslade logiken till en ny frågesträng utan kapslingen. Vad som faktiskt händer är att frågeanalysprocessen producerar ett initialt träd av logiska operatorer som nära återspeglar den ursprungliga frågan. Sedan tillämpar SQL Server transformationer på det här frågeträdet, eliminerar några av de onödiga stegen, kollapsar flera steg till färre steg och flyttar runt operatörerna. I sina transformationer, så länge som vissa villkor är uppfyllda, kan SQL Server flytta saker över vad som ursprungligen var tabelluttrycksgränser – ibland effektivt som om man skulle eliminera de kapslade enheterna. Allt detta i ett försök att hitta en optimal plan.
I den här artikeln täcker jag både fall där sådan odling äger rum, såväl som hämmande hämmare. Det vill säga när du använder vissa frågeelement förhindrar det att SQL Server kan flytta logiska operatorer i frågeträdet, vilket tvingar den att bearbeta operatorerna baserat på gränserna för tabelluttrycken som används i den ursprungliga frågan.
Jag börjar med att demonstrera ett enkelt exempel där härledda tabeller blir okapslade. Jag ska också visa ett exempel på en hämmande hämmare. Jag kommer sedan att prata om ovanliga fall där unnesting kan vara oönskat, vilket resulterar i antingen fel eller prestandaförsämring, och visar hur man förhindrar unnesting i dessa fall genom att använda en unnesting-inhibitor.
Följande fråga (vi kallar den fråga 1) använder flera kapslade lager av härledda tabeller, där vart och ett av tabelluttrycken tillämpar grundläggande filtreringslogik baserad på konstanter:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Som du kan se filtrerar vart och ett av tabelluttrycken ett intervall av beställningsdatum som börjar med ett annat datum. SQL Server tar bort denna flerskiktiga frågelogik, vilket gör det möjligt för den att sedan slå samman de fyra filtreringspredikaten till ett enda som representerar skärningspunkten mellan alla fyra predikaten.
Undersök planen för fråga 1 som visas i figur 1.
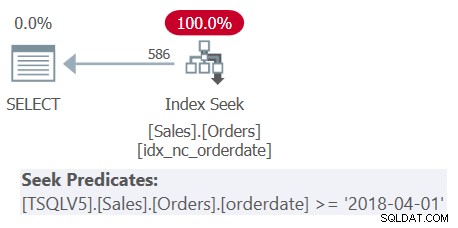 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Observera att alla fyra filtreringspredikaten slogs samman till ett enda predikat som representerar skärningspunkten mellan de fyra. Planen tillämpar en sökning i indexet idx_nc_orderdate baserat på det enda sammanslagna predikatet som sökpredikatet. Detta index definieras på orderdate (explicit), orderid (implicit på grund av närvaron av ett klustrat index på orderid) som indexnycklarna.
Observera också att även om alla tabelluttryck använder SELECT * och endast den yttersta frågan projicerar de två intressanta kolumnerna:orderdate och orderid, anses ovannämnda index täcka. Som jag förklarade i del 3, för optimeringsändamål som indexval, ignorerar SQL Server kolumnerna från tabelluttrycken som i slutändan inte är relevanta. Kom dock ihåg att du måste ha behörighet för att fråga i dessa kolumner.
Som nämnts, kommer SQL Server att försöka avhjälpa tabelluttryck, men kommer att undvika avvecklingen om den snubblar in i en hämmare för avveckling. Med ett visst undantag som jag kommer att beskriva senare, kommer användningen av TOP eller OFFSET FETCH att hämma unnesting. Anledningen är att ett försök att avnesta ett tabelluttryck med TOP eller OFFSET FETCH kan resultera i en ändring av den ursprungliga frågans betydelse.
Som ett exempel, överväg följande fråga (vi kallar den fråga 2):
SELECT orderid, orderdate
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Det inmatade antalet rader till TOP-filtret är ett BIGINT-typat värde. I det här exemplet använder jag det maximala BIGINT-värdet (2^63 – 1, beräkna i T-SQL med SELECT POWER(2., 63) – 1). Även om du och jag vet att vår ordertabell aldrig kommer att ha så många rader, och därför är TOP-filtret verkligen meningslöst, måste SQL Server ta hänsyn till den teoretiska möjligheten för att filtret ska vara meningsfullt. Följaktligen tar SQL Server inte bort tabelluttrycken i den här frågan. Planen för fråga 2 visas i figur 2.
 Figur 2:Plan för fråga 2
Figur 2:Plan för fråga 2
Inhibitorerna för ohälsa hindrade SQL Server från att kunna slå samman filtreringspredikaten, vilket gjorde att planformen mer liknade den konceptuella frågan. Det är dock intressant att observera att SQL Server fortfarande ignorerade kolumnerna som i slutändan inte var relevanta för den yttersta frågan och därför kunde använda det täckande indexet på orderdate, orderid.
För att illustrera varför TOP och OFFSET-FETCH är hämmande hämmare, låt oss ta en enkel predikat-pushdown-optimeringsteknik. Predikat pushdown betyder att optimeraren skjuter ett filterpredikat till en tidigare punkt jämfört med den ursprungliga punkten som den visas i den logiska frågebehandlingen. Anta till exempel att du har en fråga med både en inre koppling och ett WHERE-filter baserat på en kolumn från en av sidorna av kopplingen. När det gäller logisk frågebehandling är det meningen att WHERE-filtret ska utvärderas efter sammanfogningen. Men ofta trycker optimeraren filterpredikatet till ett steg före sammanfogningen, eftersom detta lämnar sammanfogningen med färre rader att arbeta med, vilket vanligtvis resulterar i en mer optimal plan. Kom dock ihåg att sådana omvandlingar endast är tillåtna i de fall där innebörden av den ursprungliga frågan bevaras, i den meningen att du är garanterad att få rätt resultatuppsättning.
Tänk på följande kod, som har en yttre fråga med ett WHERE-filter mot en härledd tabell, som i sin tur är baserad på ett tabelluttryck med ett TOP-filter:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders ) AS D
WHERE orderdate >= '20180101'; Denna fråga är naturligtvis icke-deterministisk på grund av avsaknaden av en ORDER BY-sats i tabelluttrycket. När jag körde det råkade SQL Server komma åt de tre första raderna med orderdatum tidigare än 2018, så jag fick en tom uppsättning som utdata:
orderid orderdate ----------- ---------- (0 rows affected)
Som nämnts förhindrade användningen av TOP i tabelluttrycket att tabelluttrycket odlas/ersätts här. Hade SQL Server avnestat tabelluttrycket, skulle ersättningsprocessen ha resulterat i motsvarigheten till följande fråga:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101';
Den här frågan är också icke-deterministisk på grund av avsaknaden av ORDER BY-sats, men den har helt klart en annan innebörd än den ursprungliga frågan. Om tabellen Sales.Orders har minst tre beställningar gjorda under 2018 eller senare – och det gör den – kommer denna fråga nödvändigtvis att returnera tre rader, till skillnad från den ursprungliga frågan. Här är resultatet som jag fick när jag körde den här frågan:
orderid orderdate ----------- ---------- 10400 2018-01-01 10401 2018-01-01 10402 2018-01-02 (3 rows affected)
Om den icke-deterministiska karaktären hos ovanstående två frågor förvirrar dig, här är ett exempel med en deterministisk fråga:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderid ) AS D
WHERE orderdate >= '20170708'
ORDER BY orderid; Tabelluttrycket filtrerar de tre beställningarna med de lägsta ordningens ID:n. Den yttre frågan filtrerar sedan från de tre beställningarna endast de som gjordes den 8 juli 2017 eller senare. Det visar sig att det bara finns en kvalificerande beställning. Den här frågan genererar följande utdata:
orderid orderdate ----------- ---------- 10250 2017-07-08 (1 row affected)
Antag att SQL Server urholkade tabelluttrycket i den ursprungliga frågan, med ersättningsprocessen som resulterar i följande frågemotsvarighet:
SELECT TOP (3) orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20170708' ORDER BY orderid;
Innebörden av denna fråga är annorlunda än den ursprungliga frågan. Den här frågan filtrerar först de beställningar som gjordes den 8 juli 2017 eller senare och filtrerar sedan de tre översta bland dem med lägst beställnings-ID. Den här frågan genererar följande utdata:
orderid orderdate ----------- ---------- 10250 2017-07-08 10251 2017-07-08 10252 2017-07-09 (3 rows affected)
För att undvika att ändra innebörden av den ursprungliga frågan, tillämpar inte SQL Server unnesting/substitution här.
De två sista exemplen involverade en enkel blandning av WHERE- och TOP-filtrering, men det kan finnas ytterligare motstridiga element som ett resultat av odling. Tänk till exempel om du har olika ordningsspecifikationer i tabelluttrycket och den yttre frågan, som i följande exempel:
SELECT orderid, orderdate
FROM ( SELECT TOP (3) *
FROM Sales.Orders
ORDER BY orderdate DESC, orderid DESC ) AS D
ORDER BY orderid; Du inser att om SQL Server avkapslade tabelluttrycket och kollapsade de två olika ordningsspecifikationerna till en, skulle den resulterande frågan ha haft en annan betydelse än den ursprungliga frågan. Det skulle antingen ha filtrerat fel rader eller visat resultatraderna i fel presentationsordning. Kort och gott, du inser varför det säkra för SQL Server att göra är att undvika att tabelluttryck som är baserade på TOP- och OFFSET-FETCH-frågor odlas/ersätts.
Jag nämnde tidigare att det finns ett undantag från regeln att användningen av TOP och OFFSET-FETCH förhindrar unnesting. Det är då du använder TOP (100) PERCENT i ett kapslat tabelluttryck, med eller utan en ORDER BY-sats. SQL Server inser att det inte finns någon riktig filtrering på gång och optimerar alternativet. Här är ett exempel som visar detta:
SELECT orderid, orderdate
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM ( SELECT TOP (100) PERCENT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; TOP-filtret ignoreras, unnesting äger rum och du får samma plan som den som visades tidigare för fråga 1 i figur 1.
När du använder OFFSET 0 ROWS utan FETCH-sats i ett kapslat tabelluttryck, pågår det heller ingen riktig filtrering. Så teoretiskt sett kunde SQL Server också ha optimerat det här alternativet och aktiverat unnesting, men när detta skrivs gör det inte det. Här är ett exempel som visar detta:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D1
WHERE orderdate >= '20180201'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D2
WHERE orderdate >= '20180301'
ORDER BY (SELECT NULL) OFFSET 0 ROWS ) AS D3
WHERE orderdate >= '20180401'; Du får samma plan som den som visades tidigare för fråga 2 i figur 2, vilket visar att ingen odling ägde rum.
Tidigare har jag förklarat att processen för avveckling/substitution egentligen inte genererar en ny frågesträng som sedan optimeras, utan snarare har att göra med transformationer som SQL Server tillämpar på trädet av logiska operatorer. Det finns en skillnad mellan hur SQL Server optimerar en fråga med kapslade tabelluttryck jämfört med en faktisk logiskt likvärdig fråga utan kapsling. Användningen av tabelluttryck som härledda tabeller, såväl som underfrågor, förhindrar enkel parameterisering. Återkalla fråga 1 som visades tidigare i artikeln:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Eftersom frågan använder härledda tabeller, sker ingen enkel parameterisering. Det vill säga, SQL Server ersätter inte konstanterna med parametrar och optimerar sedan frågan, snarare optimerar frågan med konstanterna. Med predikat baserade på konstanter kan SQL Server slå samman de korsande perioderna, vilket i vårt fall resulterade i ett enda predikat i planen, som visats tidigare i figur 1.
Tänk sedan på följande fråga (vi kallar den fråga 3), som är en logisk motsvarighet till fråga 1, men där du själv tillämpar avvecklingen:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401';
Planen för denna fråga visas i figur 3.
 Figur 3:Plan för fråga 3
Figur 3:Plan för fråga 3
Denna plan anses säker för enkel parameterisering, så konstanterna ersätts med parametrar, och följaktligen slås inte predikaten samman. Motivationen för parametrisering är naturligtvis att öka sannolikheten för planåteranvändning när man kör liknande frågor som bara skiljer sig i de konstanter som de använder.
Som nämnts förhindrade användningen av härledda tabeller i fråga 1 enkel parameterisering. På samma sätt skulle användningen av subqueries förhindra enkel parameterisering. Till exempel, här är vår tidigare fråga 3 med ett meningslöst predikat baserat på en underfråga som lagts till i WHERE-satsen:
SELECT orderid, orderdate FROM Sales.Orders WHERE orderdate >= '20180101' AND orderdate >= '20180201' AND orderdate >= '20180301' AND orderdate >= '20180401' AND (SELECT 42) = 42;
Den här gången sker ingen enkel parameterisering, vilket gör det möjligt för SQL Server att slå samman de korsande perioderna som representeras av predikaten med konstanterna, vilket resulterar i samma plan som visas tidigare i figur 1.
Om du har frågor med tabelluttryck som använder konstanter, och det är viktigt för dig att SQL Server parametriserade koden, och av någon anledning inte kan parametrisera den själv, kom ihåg att du har möjligheten att använda forcerad parametrisering med en planguide. Som ett exempel skapar följande kod en sådan planguide för fråga 3:
DECLARE @stmt AS NVARCHAR(MAX), @params AS NVARCHAR(MAX);
EXEC sys.sp_get_query_template
@querytext = N'SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= ''20180101'' ) AS D1
WHERE orderdate >= ''20180201'' ) AS D2
WHERE orderdate >= ''20180301'' ) AS D3
WHERE orderdate >= ''20180401'';',
@templatetext = @stmt OUTPUT,
@parameters = @params OUTPUT;
EXEC sys.sp_create_plan_guide
@name = N'TG1',
@stmt = @stmt,
@type = N'TEMPLATE',
@module_or_batch = NULL,
@params = @params,
@hints = N'OPTION(PARAMETERIZATION FORCED)'; Kör fråga 3 igen efter att ha skapat planguiden:
SELECT orderid, orderdate
FROM ( SELECT *
FROM ( SELECT *
FROM ( SELECT *
FROM Sales.Orders
WHERE orderdate >= '20180101' ) AS D1
WHERE orderdate >= '20180201' ) AS D2
WHERE orderdate >= '20180301' ) AS D3
WHERE orderdate >= '20180401'; Du får samma plan som den som visas tidigare i figur 3 med de parametriserade predikaten.
När du är klar, kör följande kod för att släppa planguiden:
EXEC sys.sp_control_plan_guide @operation = N'DROP', @name = N'TG1';
Förhindra odling
Kom ihåg att SQL Server tar bort tabelluttryck av optimeringsskäl. Målet är att öka sannolikheten för att hitta en plan med lägre kostnad jämfört med utan unnesting. Det är sant för de flesta omvandlingsregler som tillämpas av optimeraren. Det kan dock finnas några ovanliga fall där du skulle vilja förhindra odling. Detta kan antingen vara för att undvika fel (ja, i vissa ovanliga fall kan avveckling resultera i fel) eller av prestandaskäl att tvinga fram en viss planform, liknande att använda andra prestationstips. Kom ihåg att du har ett enkelt sätt att förhindra odling genom att använda TOP med ett mycket stort antal.
Exempel för att undvika fel
Jag börjar med ett fall där avveckling av tabelluttryck kan resultera i fel.
Tänk på följande fråga (vi kallar den fråga 4):
SELECT orderid, productid, discount FROM Sales.OrderDetails WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) AND 1.0 / discount > 10.0;
Det här exemplet är lite konstruerat i den meningen att det är lätt att skriva om det andra filterpredikatet så att det aldrig skulle resultera i ett fel (rabatt <0,1), men det är ett praktiskt exempel för mig att illustrera min poäng. Rabatter är icke-negativa. Så även om det finns orderrader med noll rabatt, är det meningen att frågan ska filtrera bort dessa (det första filterpredikatet säger att rabatten måste vara större än minimirabatten i tabellen). Det finns dock ingen garanti för att SQL Server kommer att utvärdera predikaten i skriftlig ordning, så du kan inte räkna med en kortslutning.
Undersök planen för fråga 4 som visas i figur 4.
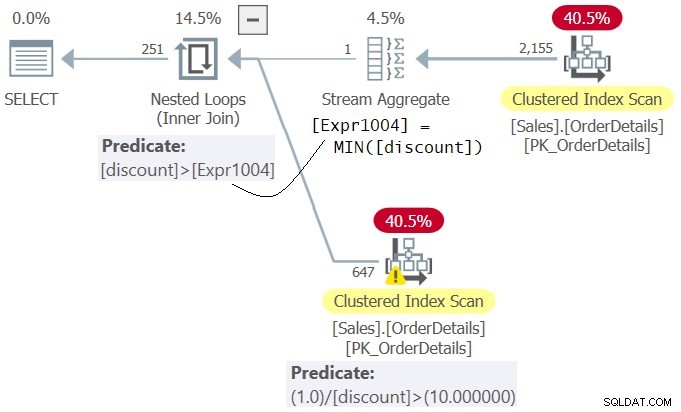 Figur 4:Plan för fråga 4
Figur 4:Plan för fråga 4
Observera att i planen utvärderas predikatet 1.0 / rabatt> 10.0 (andra i WHERE-satsen) före predikatrabatten>
Msg 8134, Level 16, State 1 Divide by zero error encountered.
Du kanske tänker att du kan undvika felet genom att använda en härledd tabell, separera filtreringsuppgifterna till en inre och en yttre, som så:
SELECT orderid, productid, discount
FROM ( SELECT *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; SQL Server tillämpar dock avveckling av den härledda tabellen, vilket resulterar i samma plan som visades tidigare i figur 4, och följaktligen misslyckas även denna kod med ett divideringsfel med noll:
Msg 8134, Level 16, State 1 Divide by zero error encountered.
En enkel korrigering här är att introducera en hämmare som inte nästlar sig (vi kallar den här lösningen för fråga 5):
SELECT orderid, productid, discount
FROM ( SELECT TOP (9223372036854775807) *
FROM Sales.OrderDetails
WHERE discount > (SELECT MIN(discount) FROM Sales.OrderDetails) ) AS D
WHERE 1.0 / discount > 10.0; Planen för fråga 5 visas i figur 5.
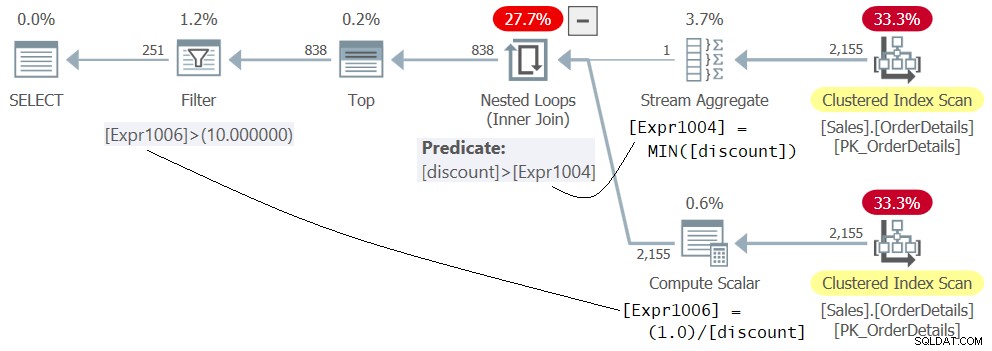 Figur 5:Plan för fråga 5
Figur 5:Plan för fråga 5
Bli inte förvirrad av det faktum att uttrycket 1.0 / rabatt visas i den inre delen av operatören Nested Loops, som om det utvärderades först. Detta är bara definitionen av medlemmen Expr1006. Den faktiska utvärderingen av predikatet Expr1006> 10.0 tillämpas av filteroperatorn som det sista steget i planen efter att raderna med den lägsta rabatten filtrerades bort av operatören Nested Loops tidigare. Den här lösningen körs utan fel.
Exempel av prestandaskäl
Jag fortsätter med ett fall där att tabelluttryck lösas upp kan skada prestandan.
Börja med att köra följande kod för att byta kontext till PerformanceV5-databasen och aktivera STATISTICS IO och TIME:
USE PerformanceV5; SET STATISTICS IO, TIME ON;
Tänk på följande fråga (vi kallar den fråga 6):
SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid;
Optimizern identifierar ett stödjande täckande index med shipperid och orderdate som ledande nycklar. Så det skapar en plan med en ordnad skanning av indexet följt av en orderbaserad Stream Aggregate-operator, som visas i planen för fråga 6 i figur 6.
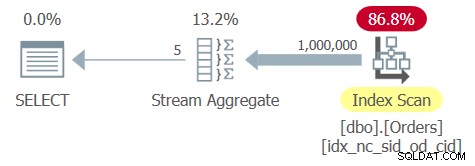 Figur 6:Plan för fråga 6
Figur 6:Plan för fråga 6
Tabellen Order har 1 000 000 rader och grupperingskolumnen shipperid är mycket tät – det finns bara 5 distinkta avsändar-ID, vilket resulterar i 20 % densitet (genomsnittlig procent per distinkt värde). Att tillämpa en fullständig genomsökning av registerbladet innebär att läsa några tusen sidor, vilket resulterar i en körtid på ungefär en tredjedels sekund på mitt system. Här är prestandastatistiken som jag fick för körningen av den här frågan:
CPU time = 344 ms, elapsed time = 346 ms, logical reads = 3854
Indexträdet är för närvarande tre nivåer djupt.
Låt oss skala antalet beställningar med en faktor på 1 000 till 1 000 000 000, men fortfarande med endast 5 distinkta avsändare. Antalet sidor i indexbladet skulle växa med en faktor 1 000, och indexträdet skulle troligen resultera i en extra nivå (fyra nivåer djupa). Denna plan har linjär skalning. Du skulle sluta med nära 4 000 000 logiska läsningar och en körtid på några minuter.
När du behöver beräkna ett MIN- eller MAX-aggregat mot en stor tabell, med mycket hög densitet i grupperingskolumnen (viktigt!), och ett stödjande B-trädindex inskrivet på grupperingskolumnen och aggregeringskolumnen, finns det en mycket mer optimal planform än den i figur 6. Föreställ dig en planform som skannar den lilla uppsättningen av avsändar-ID:n från något index på avsändartabellen, och i en slinga tillämpar för varje avsändare en sökning mot det stödjande indexet på order för att få aggregatet. Med 1 000 000 rader i tabellen skulle 5 sökningar innebära 15 läsningar. Med 1 000 000 000 rader skulle 5 sökningar innebära 20 läsningar. Med en biljon rader, totalt 25 läsningar. Helt klart en mycket mer optimal plan. Du kan faktiskt uppnå en sådan plan genom att fråga tabellen avsändare och få aggregatet med hjälp av en skalär aggregatunderfråga mot order, som så (vi kallar den här lösningen för fråga 7):
SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid = S.shipperid) AS maxod FROM dbo.Shippers AS S;
Planen för denna fråga visas i figur 7.
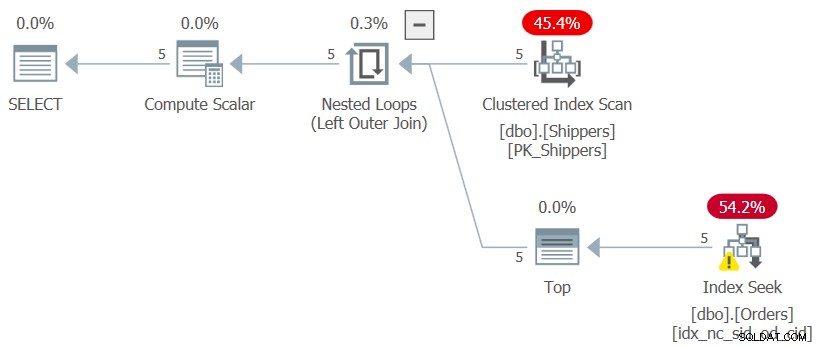 Figur 7:Plan för fråga 7
Figur 7:Plan för fråga 7
Den önskade planformen har uppnåtts och prestandasiffrorna för utförandet av denna fråga är försumbara som förväntat:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Så länge som grupperingskolumnen är mycket tät blir storleken på tabellen Order praktiskt taget obetydlig.
Men vänta ett ögonblick innan du går och firar. Det finns ett krav på att endast behålla de avsändare vars maximala relaterade beställningsdatum i tabellen Order är 2018 eller senare. Låter som ett tillräckligt enkelt tillägg. Definiera en härledd tabell baserad på fråga 7 och använd filtret i den yttre frågan, som så (vi kallar den här lösningen för fråga 8):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Tyvärr tar SQL Server bort den härledda tabellfrågan, såväl som underfrågan, och konverterar aggregeringslogiken till motsvarigheten till den grupperade frågelogiken, med shipperid som grupperingskolumn. Och sättet som SQL Server vet för att optimera en grupperad fråga är baserat på en enda passage över indata, vilket resulterar i en plan som mycket liknar den som visas tidigare i figur 6, bara med det extra filtret. Planen för fråga 8 visas i figur 8.
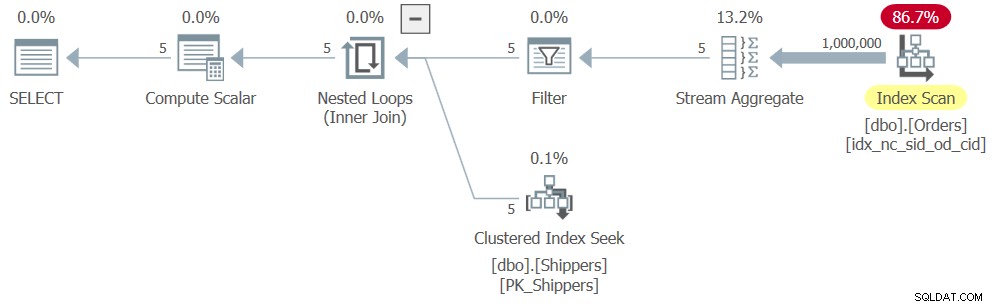 Figur 8:Plan för fråga 8
Figur 8:Plan för fråga 8
Följaktligen är skalningen linjär och prestandasiffrorna liknar de för fråga 6:
CPU time = 328 ms, elapsed time = 325 ms, logical reads = 3854
Lösningen är att introducera en hämmande hämmare. Detta kan göras genom att lägga till ett TOP-filter till tabelluttrycket som den härledda tabellen är baserad på (vi kallar den här lösningen för fråga 9):
SELECT shipperid, maxod
FROM ( SELECT TOP (9223372036854775807) S.shipperid,
(SELECT MAX(O.orderdate)
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Planen för denna fråga visas i figur 9 och har den önskade planformen med sökorden:
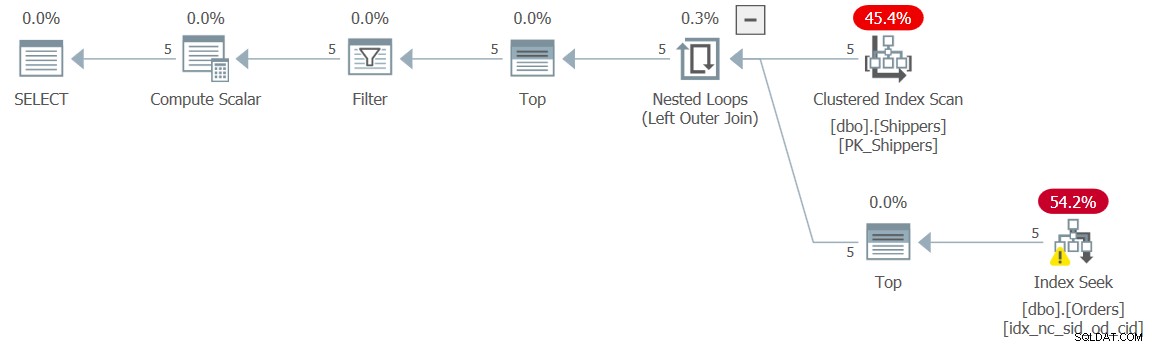 Figur 9:Plan för fråga 9
Figur 9:Plan för fråga 9
Prestandasiffrorna för denna exekvering är då naturligtvis försumbara:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
Ännu ett alternativ är att förhindra att underfrågan lösgörs, genom att ersätta MAX-aggregatet med ett motsvarande TOP (1)-filter, som så (vi kallar den här lösningen för fråga 10):
SELECT shipperid, maxod
FROM ( SELECT S.shipperid,
(SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC) AS maxod
FROM dbo.Shippers AS S ) AS D
WHERE maxod >= '20180101'; Planen för denna fråga visas i figur 10 och har återigen den önskade formen med sökningarna.
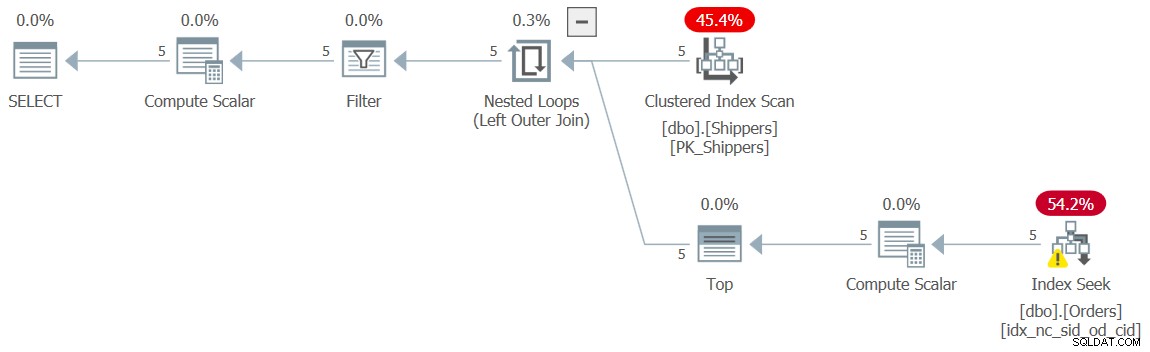 Figur 10:Plan för fråga 10
Figur 10:Plan för fråga 10
Jag fick de välbekanta försumbara prestandasiffrorna för den här exekveringen:
CPU time = 0 ms, elapsed time = 0 ms, logical reads = 15
När du är klar kör du följande kod för att sluta rapportera resultatstatistik:
SET STATISTICS IO, TIME OFF;
Sammanfattning
I den här artikeln fortsatte jag diskussionen jag startade förra månaden om optimering av härledda tabeller. Den här månaden fokuserade jag på att lösa ut härledda tabeller. Jag förklarade att typiskt odling resulterar i en mer optimal plan jämfört med utan odling, men täckte också exempel där det inte är önskvärt. Jag visade ett exempel där unnesting resulterade i ett fel samt ett exempel som resulterade i prestandaförsämring. Jag demonstrerade hur man förhindrar unnesting genom att applicera en unnesting-hämmare som TOP.
Nästa månad fortsätter jag att utforska namngivna tabelluttryck, och flyttar fokus till CTE:er.