"Waitstats hjälper oss att identifiera prestationsrelaterade räknare. Men vänteinformation i sig är inte tillräckligt för att korrekt diagnostisera prestandaproblem. Kökomponenten i vår metodik kommer från Performance Monitor-räknare, som ger en bild av systemets prestanda ur en resurssynpunkt.”Tom Davidson, Öppnar Microsofts Performance-Tuning Toolbox
SQL Server Pro Magazine, december 2003
Waits and Queues har använts som en metod för prestandajustering av SQL Server sedan Tom Davidson publicerade artikeln ovan samt den välkända SQL Server 2005 Waits and Queues whitepaper 2006. När den tillämpas i kombination med resursmått kan väntan vara värdefull för bedöma vissa prestandaegenskaper hos arbetsbelastningen och hjälpa till att styra inställningsinsatser. Waits-data dyker upp av många SQL Server-lösningar för prestandaövervakning, och jag har varit en förespråkare för att justera med denna metod sedan början. Tillvägagångssättet var inflytelserik i designen av SQL Sentrys prestandainstrumentpanel, som presenterar väntetider flankerade av köer (nyckel resursmått) för att ge en heltäckande bild av serverns prestanda.
Vissa verkar dock ha missat Davidsons poäng angående vikten av resurser och förlitar sig nästan helt på väntan för att presentera en bild av frågeprestanda och systemets hälsa. Väntestatistik kommer direkt från SQL Server-motorn och är lätt att konsumera och kategorisera. Väntande frågor betyder väntande applikationer och användare, och ingen gillar att vänta! Det är lättare att evangelisera stämning med väntetider som den unika lösningen för att göra frågor och applikationer snabbare än att berätta hela historien, som är mer involverad.
Tyvärr kan ett väntefokuserat tillvägagångssätt för att utesluta resursanalys vilseleda och i värsta fall lämna dig flygande blind. SentryOne-teammedlemmarna Kevin Kline och Steve Wright har tidigare berört detta här och här. I det här inlägget ska jag ta en djupare dykning i några nyare undersökningar som möjliggjorts av Query Store som har kastat nytt ljus över hur bristfällig vänteexklusiv justering verkligen kan vara.
De vanligaste frågorna som inte var
Nyligen kontaktade en SentryOne-kund mig angående prestationsproblem med deras SentryOne-databas. Det finns en enda SQL Server-databas i hjärtat av varje SentryOne-övervakningsmiljö, och den här kunden övervakade cirka 600 servrar med vår programvara. I den omfattningen är det inte ovanligt att se enstaka frågeprestandaproblem och göra lite justeringar, och några förmodade nya frågor i arbetsbelastningen var källan till deras oro.
Jag deltog i en skärmdelningssession för att ta en titt, och kunden gav mig först data från ett annat system som också övervakade SentryOne-databasen. Systemet använde ett vänteläge på frågenivå och visade två lagrade procedurer som ansvarade för ungefär hälften av väntan på SQL Sentry-databasservern. Detta var ovanligt eftersom dessa två procedurer alltid körs väldigt snabbt och aldrig har varit tecken på ett verkligt prestandaproblem i vår databas. Förbryllad bytte jag över till SQL Sentry för att se vad det skulle visa oss och blev förvånad över att se att proceduren #1 i det andra systemet under samma intervall var #6, #7 och #8 vad gäller total varaktighet, CPU och logisk lyder respektive:
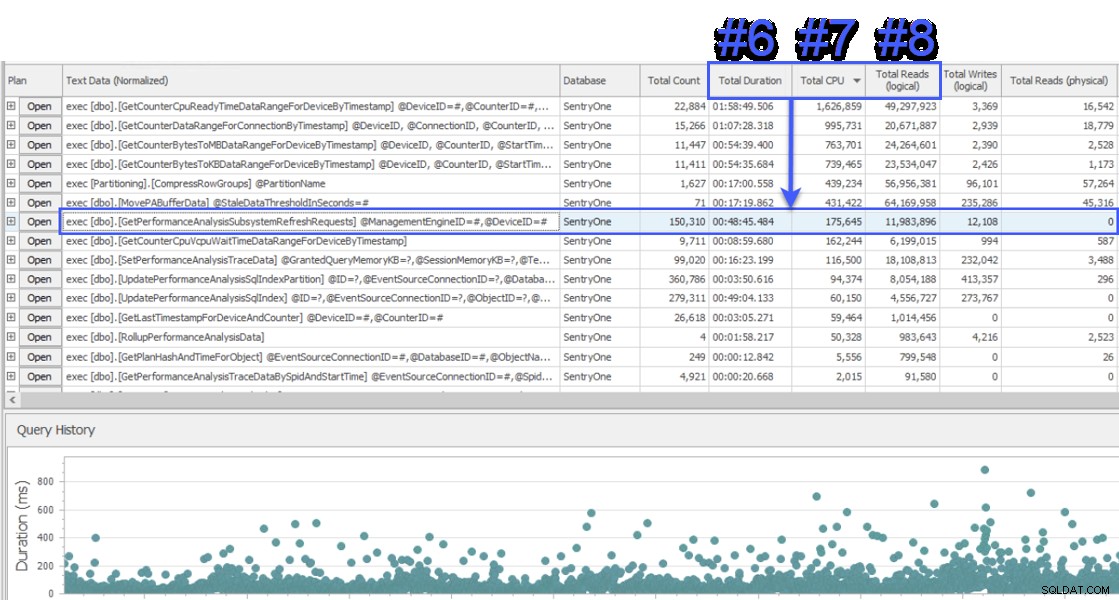 SQL Sentrys "Top SQL"-vy
SQL Sentrys "Top SQL"-vy
Ur resursförbrukningssynpunkt innebar detta att frågorna ovanför representerade 75 % av den totala varaktigheten, 87 % av den totala CPU:n och 88 % av logiska läsningar. Dessutom var proceduren #2 i det andra systemet inte ens bland de 30 bästa i SQL Sentry, på något sätt! Dessa två frågor var långt ifrån topp 2, och de frågor som stod för de flesta av de faktiska förbrukningen i systemet var kraftigt underrepresenterad.
Jag hade alltid antagit att det fanns en starkare korrelation mellan de bästa servitörerna och de bästa resurskonsumenterna men hade aldrig gjort en direkt jämförelse på frågenivå som denna, så dessa resultat var minst sagt överraskande. Mitt intresse väckte, jag bestämde mig för att undersöka om denna situation var typisk eller onormal.
Query Store 2017 till räddning
I SQL Server 2017 och senare fångar Query Store väntetider på frågenivå utöver frågeresursförbrukningen. Erin Stellato gjorde ett bra inlägg på Query Store waits här. Det är lägre omkostnader och mer exakt än att fråga väntar DMV:er varje sekund i hopp om att fånga frågor under flygning, standardmetoden som används av andra verktyg, inklusive det tidigare nämnda.
SQL Sentry har alltid fångat väntetider men på SQL Server-instansnivå, på grund av dessa farhågor om overhead och noggrannhet. Detaljerade frågeväntningar är tillgängliga på begäran via integrerad Plan Explorer, och vi utvärderar att utöka väntan på instansnivå med data på frågenivå från Query Store, när det är tillgängligt.
För denna strävan tog jag hjälp av SentryOne Product Advisory Council, en grupp SentryOne-kunder, partners och vänner i branschen som deltar i en privat Slack-kanal. Jag delade det här skriptet för att dumpa de föregående 8 timmarna av data från Query Store och fick tillbaka resultat för 11 produktionsservrar i flera vertikaler inklusive finansiella tjänster, spelpublicering, träningsspårning och försäkring.
Väntekategorier för Query Store dokumenteras här. Alla kategorier ingick i analysen förutom dessa, som togs bort av de angivna skälen:
- Parallellism – Det kan blåsa upp en frågas väntetid betydligt längre än dess faktiska varaktighet eftersom flera trådar kan kasta bort de associerade väntetiderna, vilket förvirrar korrelationen med varaktighet och andra mätvärden. Vidare, även om CXPACKET/CXCONSUMER-delningen är användbar, betyder CXPACKET fortfarande bara att du har parallellism och inte nödvändigtvis är problematisk eller handlingsbar.
- CPU – Signalväntetid kan vara till hjälp för att fastställa CPU-flaskhalsar via korrelation med resursväntningar, men Query Store inkluderar för närvarande endast SOS_SCHEDULER_YIELD i denna kategori, vilket inte är en väntan i traditionell mening som tas upp här. Det lämpar sig inte för enkel jämförelse eller korrelation, särskilt när SQL Server är på en virtuell dator som lever på en överprenumererad värd. Till exempel, på en server var Query Store CPU-väntningar 227 % av den totala CPU-tiden för alla frågor utan någon parallellitet, vilket inte borde vara möjligt.
- Användarvänta och Inaktiv – Dessa kategorier består uteslutande av timer- och köväntningar och uteslöts av samma anledning som man alltid bör utesluta dessa typer – de är ofarliga och skapar bara brus.
För övrigt talade jag nyligen med pappan till Query Store, Conor Cunningham, om sannolikheten för framtida förändringar av Query Store-väntetyperna och -kategorierna och han indikerade att det verkligen var möjligt... så vi måste hålla ett öga på det.
Analysresultat TL;DR
Efter omfattande analys har jag bekräftat att resultaten som observerats på kundsystemet inte är onormala, utan snarare vanliga. Detta innebär att om du är beroende av ett väntefokuserat verktyg för att övervaka och justera dina arbetsbelastningar, är det stor sannolikhet att du fokuserar på fel frågor och saknar de som är ansvariga för de flesta av frågans varaktighet och resursförbrukning på ett system. Eftersom CPU- och IO-förbrukning direkt översätts till serverhårdvara och molnutgifter är detta betydande.
De flesta frågor väntar inte
En intressant och viktig upptäckt som jag kommer att täcka först är att de flesta frågor inte genererar några väntan alls. Av totalt 56 438 förfrågningar på alla servrar hade endast 9 781 (17 %) någon väntetid och endast 8 092 (14 %) hade väntetid från betydande typer. Om du bara använder väntar för att avgöra vilka frågor som ska optimeras, kommer du att missa de flesta frågorna i arbetsbelastningen.
Korrelera väntan och resurser
Jag analyserade hur väntetider relaterar till resursförbrukning genom att rangordna alla frågor på varje system efter väntan och resurser och använda rangorden för att beräkna en Spearmans korrelation. Vad vi i slutändan försöker avgöra är om de främsta servitörerna tenderar att vara de bästa konsumenterna. Det visar sig att de inte gör det.
Tabell 1 visar de färgskalade korrelationskoefficienterna för genomsnittlig sökfråga tid till andra mått – ett värde på 1,00 (mörkblått) representerar data som är perfekt korrelerad. Som du kan se är korrelationen med väntetider och andra mått över de flesta servrarna inte stark, och för en server finns det en negativ korrelation med de flesta mått.
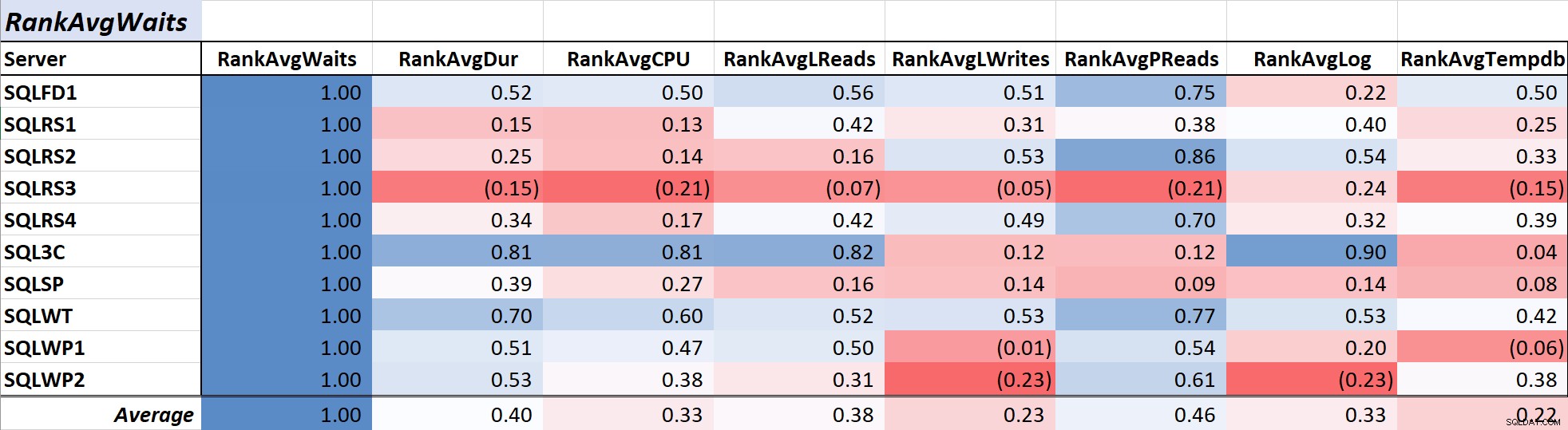 Tabell 1:Korrelation med genomsnittlig sökväntetid (ms)
Tabell 1:Korrelation med genomsnittlig sökväntetid (ms)
Frågans varaktighet är ofta ett primärt problem för DBA:er och utvecklare eftersom det översätts direkt till användarupplevelsen, och tabell 2 visar korrelationen mellan genomsnittlig frågelängd och de andra åtgärderna. Korrelationen med varaktighet och de två primära resursmåtten, CPU och logiska läsningar, är ganska stark vid 0,97 respektive 0,75.
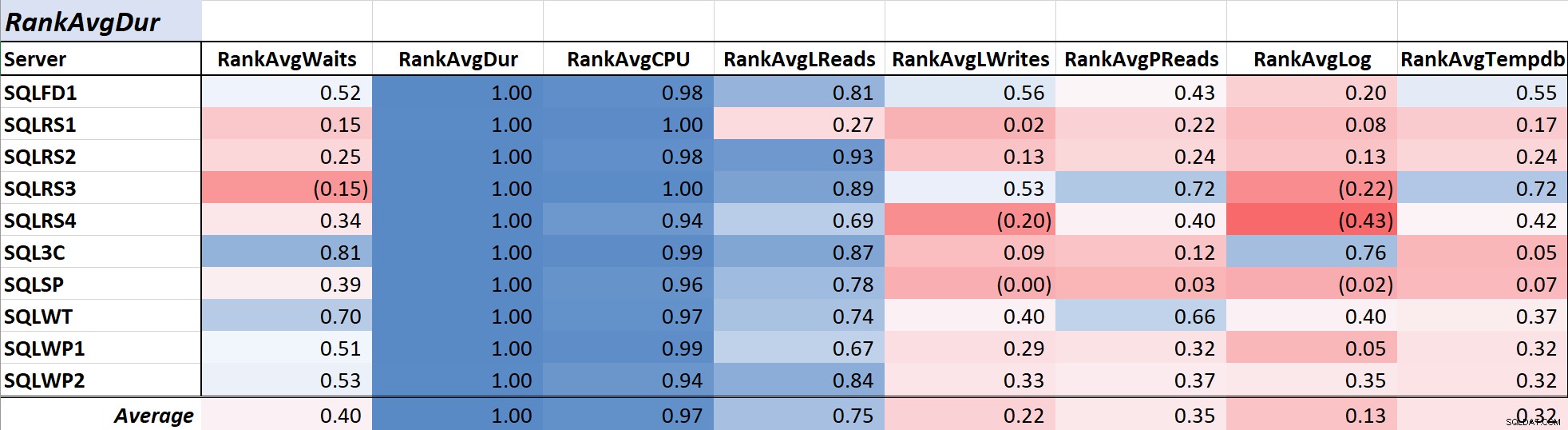 Tabell 2:Korrelation med genomsnittlig frågelängd (ms)
Tabell 2:Korrelation med genomsnittlig frågelängd (ms)
Eftersom logiska läsningar alltid använder CPU, och, liksom varaktighet, CPU mäts i millisekunder, är detta förhållande inte förvånande. Resultaten överensstämmer med tanken att om du vill att dina databasapplikationer ska köras så snabbt som möjligt, kommer fokus på att minska fråge-CPU och logiska läsningar att vara effektivare för att minska varaktigheten än att bara använda väntetider. Lyckligtvis är att göra det via bättre frågedesign, indexering etc. vanligtvis ett enklare förslag än att direkt minska väntetiden för sökfrågan. Kollega Aaron Bertrand presenterar på ett effektivt sätt några av varningarna när man stämmer med väntar här.
% av total väntetid
Därefter tittade jag på om frågorna med högst väntetid tenderar att stå för den största resursförbrukningen. Vi vill avgöra om det vi såg på kundsystemet är atypiskt, där de två översta väntande frågorna representerade en relativt liten andel av den totala resursförbrukningen.
Diagram 1 nedan visar procentandelen av total CPU och logiska läsningar för varje server som står för av frågorna som representerar 75 % av den totala väntetiden. Endast en server hade en resurs som översteg 75 % – läser på SQLRS3. I övrigt tog de frågor som svarade för 75 % av väntetiden mindre än 75 % av resurserna – ofta mycket mindre. Detta återspeglar vad vi såg på kundsystemet och överensstämmer med korrelationsanalysen.
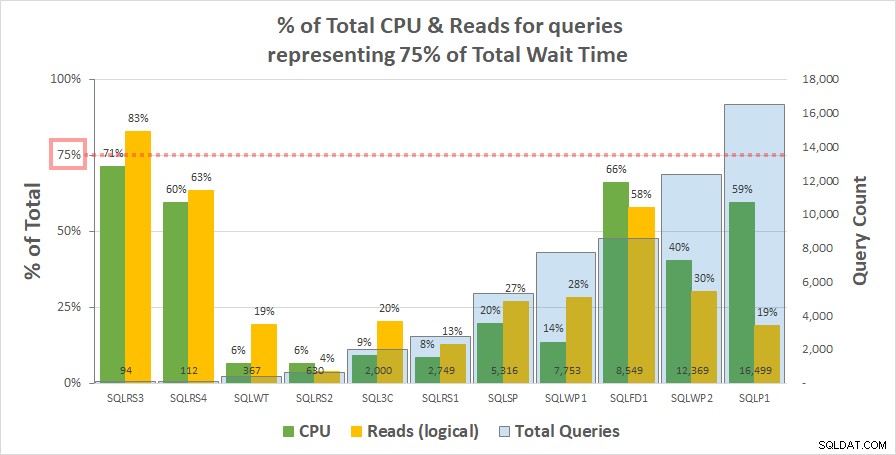 Diagram 1
Diagram 1
Observera att det verkar finnas ett samband med det totala antalet frågor i arbetsbelastningen. Detta representeras av den ljusblå kolumnserien på den sekundära y-axeln och diagrammet sorteras stigande efter denna serie. De två servrarna med de högsta resursmåtten vid 75 % av väntan hade också minst frågor (SQLRS3 och SQLRS4). Ju mindre arbetsbelastningen är desto större är den potentiella påverkan av ett litet antal frågor, och visst, på båda servrarna stod bara två frågor för de flesta av väntan och resurser. Ett sätt att se på detta är att väntan hjälper mest att identifiera dina tyngsta frågor när du minst behöver det.
Väntetid och frågelängd
Slutligen utvärderade jag procentandelen av total väntetid till total frågelängd på varje system. Tabell 3 har kolumner för:
- Total frågelängd i ms
- Total väntetid ms – rå
- Total väntetid ms – utan parallellism, tomgång och användarväntningar (Rev1)
- Total väntetid ms – utan parallellism, tomgång, användarväntningar och CPU (Rev2)
- Procentandelen av varaktigheten för de tre väntetidskolumnerna, med datastaplar
- Totalt antal unika frågor, med datafält
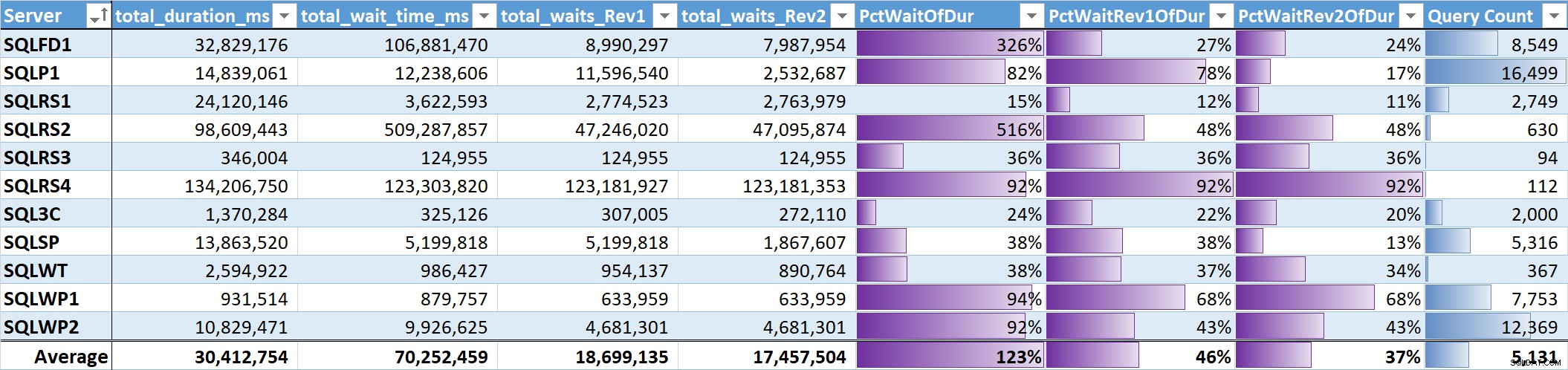 Tabell 3
Tabell 3
Det oviktade genomsnittet för de meningsfulla väntetiderna (Rev2) i alla system är 37 % av den totala sökfrågans varaktighet. På fem av systemen var den mindre än 25 %, och på endast två system var den över 50 %. På systemet med 92 % väntetid (SQLRS4), en med minst frågor, stod två frågor för 99 % av väntetiderna, 97 % av varaktigheten, 84 % av CPU:n och 86 % av läsningarna.
Även om väntetiden kan representera en betydande del av frågekörtiden på vissa system, och det verkar intuitivt att om du minskar väntetiden, så kommer också frågetiden att minska, vi har sett att väntetid och varaktighet är svagt korrelerade. Det är osannolikt att det är så enkelt, och min egen erfarenhet bekräftar detta. Mer forskning behövs här.
Omfattande justering med Plan Explorer och SQL Sentry
Som denna utmärkta SQLskills whitepaper ofta antyder, är roten till höga väntetider ofta ooptimerade frågor och index. Den kostnadsfria SentryOne Plan Explorer är specialbyggd för att minska resursförbrukningen via effektiv frågejustering med hjälp av dess Index Analysis-modul och många andra innovativa funktioner. SQL Sentry integrerar Plan Explorer direkt i modulerna Top SQL, Blocking och Deadlocks, så att du automatiskt kan fånga och ställa in problematiska frågor på ett ställe. Du kan enkelt välja ett intresseområde på SQL Sentry-instrumentpanelens historiska väntetider, CPU- eller IO-diagram och hoppa till Top SQL-vyn för att hitta de mest resurskrävande frågorna under den tiden. Sedan kan du med ett enda klick öppna en fråga i Plan Explorer och få detaljerade väntetider på frågenivå och resurser på begäran när det behövs. Jag tror inte att det finns en bättre utföringsform av den fullständiga inställningsmetoden för väntar och köer än denna.
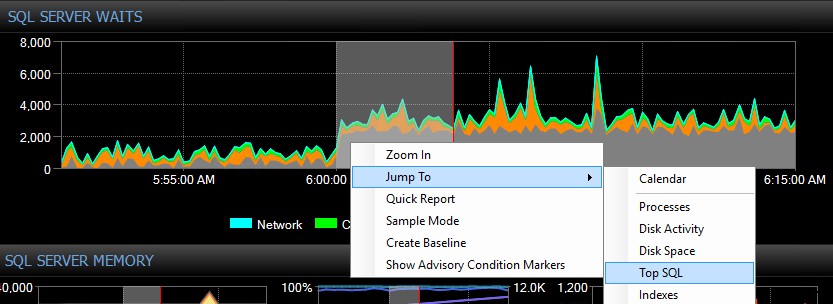 SQL Sentry Dashboard “Waits”-diagram
SQL Sentry Dashboard “Waits”-diagram
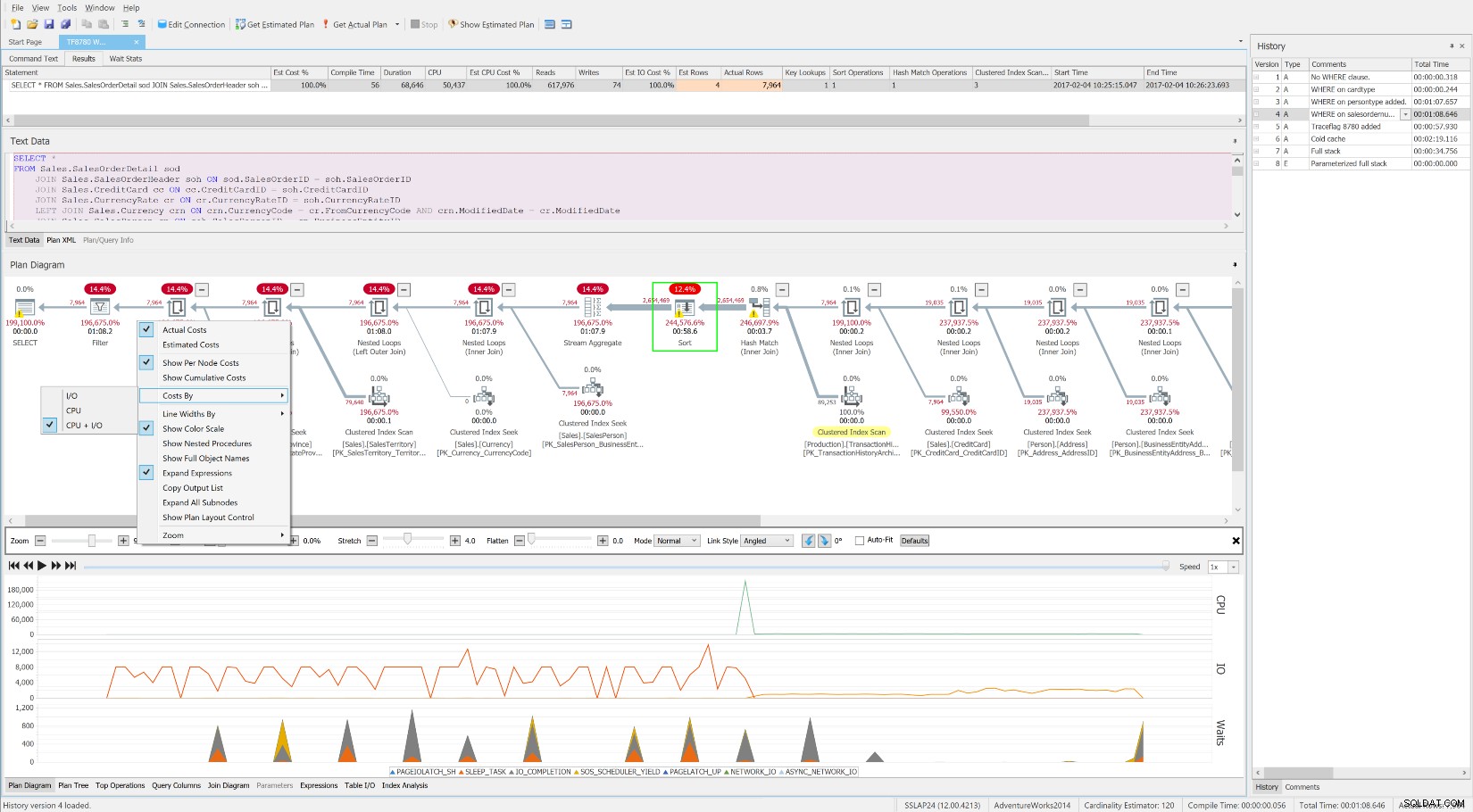 Den kostnadsfria SentryOne Plan Explorer som visar väntan över tid, tillsammans med driftnivå kostnader och resurser
Den kostnadsfria SentryOne Plan Explorer som visar väntan över tid, tillsammans med driftnivå kostnader och resurser
Slutsats
Att trimma med väntetider och köer är lika tillämpligt på SQL Server-prestanda idag som det var 2006. Att fokusera på väntan till uteslutande av resurser är dock en farlig affär, eftersom det är tydligt från data att det kommer att leda till allmänt ooptimerade och kostnadsineffektiva system. När det kommer till hårdvaruresurser och molnutgifter, betalar du i slutändan för beräknings- och IO-resurser, inte väntetid, så det är lämpligt att optimera direkt för konsumtion. Min erfarenhet är att när resursförbrukningen och relaterade påståenden minskar, kommer naturligtvis minskad väntetid att följa.
Bekräftelse
Jag ville tacka Fred Frost, Lead Data Scientist på SentryOne, för hans värdefulla input och kritiska granskning av denna analys.