Den här artikeln är den tredje delen i en serie om NULL-komplexitet. I del 1 täckte jag innebörden av NULL-markören och hur den beter sig i jämförelser. I del 2 beskrev jag NULL-behandlingens inkonsekvenser i olika språkelement. Den här månaden beskriver jag kraftfulla standardfunktioner för NULL-hantering som ännu inte har kommit till T-SQL, och de lösningar som människor använder för närvarande.
Jag kommer att fortsätta använda exempeldatabasen TSQLV5 som förra månaden i några av mina exempel. Du kan hitta skriptet som skapar och fyller denna databas här, och dess ER-diagram här.
DISTINKT predikat
I del 1 i serien förklarade jag hur NULLs beter sig i jämförelser och komplexiteten kring den trevärdiga predikatlogiken som SQL och T-SQL använder. Tänk på följande predikat:
X =YOm någon predikand är NULL – inklusive när båda är NULL – är resultatet av detta predikat det logiska värdet OKÄNT. Med undantag för operatorerna IS NULL och IS NOT NULL, gäller detsamma för alla andra operatorer, inklusive annorlunda än (<>):
X <> YOfta i praktiken vill du att NULLs ska bete sig precis som icke-NULL-värden för jämförelseändamål. Det är särskilt fallet när du använder dem för att representera saknade men otillämpliga värden. Standarden har en lösning för detta behov i form av en funktion som kallas DISTINCT-predikatet, som använder följande form:
Istället för att använda likhets- eller ojämlikhetssemantik använder detta predikat distinkthetsbaserad semantik när man jämför predikander. Som ett alternativ till en likhetsoperator (=), skulle du använda följande formulär för att få en TRUE när de två predikanderna är samma, inklusive när båda är NULLs, och en FALSE när de inte är det, inklusive när den ena är NULL och annat är inte:
X SKÄR INTE FRÅN YSom ett alternativ till en annan än operator (<>), skulle du använda följande form för att få ett TRUE när de två predikanderna är olika, inklusive när den ena är NULL och den andra inte är det, och en FALSE när de är samma, inklusive när båda är NULL:
X SKILT FRÅN YLåt oss tillämpa predikatet DISTINCT på exemplen vi använde i del 1 i serien. Kom ihåg att du behövde skriva en fråga som givet en indataparameter @dt returnerar beställningar som skickades på inmatningsdatumet om det inte är NULL, eller som inte skickades alls om indatat är NULL. Enligt standarden skulle du använda följande kod med predikatet DISTINCT för att hantera detta behov:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT DISTINCT FROM @dt;
För nu, kom ihåg från del 1 att du kan använda en kombination av EXISTS-predikatet och INTERSECT-operatorn som en SARG-bar lösning i T-SQL, så här:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate INTERSECT SELECT @dt);
För att returnera beställningar som skickades på ett annat datum än (till skillnad från) inmatningsdatumet @dt, använder du följande fråga:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS DISTINCT FROM @dt;
Lösningen som fungerar i T-SQL använder en kombination av EXISTS-predikatet och operatorn EXCEPT, som så:
SELECT orderid, shippeddate FROM Sales.Orders WHERE EXISTS(SELECT shippeddate EXCEPT SELECT @dt);
I del 1 diskuterade jag också scenarier där du behöver ansluta tabeller och tillämpa distinkthetsbaserad semantik i join-predikatet. I mina exempel använde jag tabeller som heter T1 och T2, med NULLable join-kolumner som heter k1, k2 och k3 på båda sidor. Enligt standarden skulle du använda följande kod för att hantera en sådan join:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 IS NOT DISTINCT FROM T2.k1 AND T1.k2 IS NOT DISTINCT FROM T2.k2 AND T1.k3 IS NOT DISTINCT FROM T2.k3;
För nu, i likhet med de tidigare filtreringsuppgifterna, kan du använda en kombination av EXISTS-predikatet och INTERSECT-operatorn i joins ON-sats för att emulera det distinkta predikatet i T-SQL, så här:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2 FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2.k1, T2.k2, T2.k3);
När det används i ett filter är det här formuläret SARGable, och när det används i joins kan det här formuläret förlita sig på indexordning.
Om du vill se predikatet DISTINCT läggas till i T-SQL kan du rösta på det här.
Om du efter att ha läst det här avsnittet fortfarande känner dig lite orolig över predikatet DISTINCT är du inte ensam. Kanske är detta predikat mycket bättre än någon befintlig lösning vi för närvarande har i T-SQL, men det är lite mångsidigt och lite förvirrande. Den använder en negativ form för att tillämpa det som i våra sinnen är en positiv jämförelse, och vice versa. Nåväl, ingen sa att alla standardförslag är perfekta. Som Charlie noterade i en av sina kommentarer till del 1, skulle följande förenklade formulär fungera bättre:
Det är kortfattat och mycket mer intuitivt. Istället för X SKILJER INTE FRÅN Y, skulle du använda:
X ÄR YOch istället för X ÄR DISTINKT FRÅN Y, skulle du använda:
X ÄR INTE YDenna föreslagna operator är faktiskt anpassad till de redan befintliga operatorerna IS NULL och IS NOT NULL.
Tillämpad på vår frågeuppgift, för att returnera beställningar som skickades på inmatningsdatumet (eller som inte skickades om inmatningen är NULL) skulle du använda följande kod:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS @dt;
För att returnera beställningar som har skickats på ett annat datum än inmatningsdatumet använder du följande kod:
SELECT orderid, shippeddate FROM Sales.Orders WHERE shippeddate IS NOT @dt;
Om Microsoft någonsin bestämmer sig för att lägga till det distinkta predikatet, skulle det vara bra om de stödde både den vanliga verbose formen och denna icke-standardiserade ännu mer koncisa och mer intuitiva form. Märkligt nog stöder SQL Servers frågeprocessor redan en intern jämförelseoperatör IS, som använder samma semantik som den önskade IS-operatören som jag beskrev här. Du kan hitta detaljer om denna operatör i Paul Whites artikel Undocumented Query Plans:Equality Comparisons (uppslag "IS istället för EQ"). Vad som saknas är att exponera det externt som en del av T-SQL.
NULL-behandlingsklausul (IGNERA NULLAR | RESPECT NULLS)
När du använder offsetfönsterfunktionerna LAG, LEAD, FIRST_VALUE och LAST_VALUE, behöver du ibland kontrollera NULL-behandlingsbeteendet. Som standard returnerar dessa funktioner resultatet av det begärda uttrycket i den begärda positionen, oavsett om resultatet av uttrycket är ett verkligt värde eller ett NULL. Men ibland vill du fortsätta röra dig i den relevanta riktningen (bakåt för LAG och LAST_VALUE, framåt för LEAD och FIRST_VALUE), och returnera det första icke-NULL-värdet om det finns, och NULL annars. Standarden ger dig kontroll över detta beteende med hjälp av en NULL-behandlingsklausul med följande syntax:
offset_function(Standardinställningen om NULL-behandlingsklausulen inte är specificerad är alternativet RESPECT NULLS, vilket betyder att returnera allt som finns i den begärda positionen även om NULL. Tyvärr är denna klausul ännu inte tillgänglig i T-SQL. Jag kommer att ge exempel för standardsyntaxen med funktionerna LAG och FIRST_VALUE, samt lösningar som fungerar i T-SQL. Du kan använda liknande tekniker om du behöver sådan funktionalitet med LEAD och LAST_VALUE.
Som exempeldata använder jag en tabell som heter T4 som du skapar och fyller i med följande kod:
DROP TABLE IF EXISTS dbo.T4; GO CREATE TABLE dbo.T4 ( id INT NOT NULL CONSTRAINT PK_T4 PRIMARY KEY, col1 INT NULL ); INSERT INTO dbo.T4(id, col1) VALUES ( 2, NULL), ( 3, 10), ( 5, -1), ( 7, NULL), (11, NULL), (13, -12), (17, NULL), (19, NULL), (23, 1759);
Det finns en vanlig uppgift som innebär att returnera det sista relevanta värde. En NULL i col1 indikerar ingen förändring i värdet, medan ett icke-NULL-värde indikerar ett nytt relevant värde. Du måste returnera det sista icke-NULL col1-värdet baserat på id-beställning. Med standardbehandlingsklausulen NULL skulle du hantera uppgiften så här:
SELECT id, col1, COALESCE(col1, LAG(col1) IGNORE NULLS OVER(ORDER BY id)) AS lastval FROM dbo.T4;
Här är det förväntade resultatet från den här frågan:
id col1 lastval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 -1 7 NULL -1 11 NULL -1 13 -12 -12 17 NULL -12 19 NULL -12 23 1759 1759
Det finns en lösning i T-SQL, men den involverar två lager av fönsterfunktioner och ett tabelluttryck.
I det första steget använder du MAX-fönsterfunktionen för att beräkna en kolumn som kallas grp som innehåller det maximala id-värdet hittills när col1 inte är NULL, som så:
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Denna kod genererar följande utdata:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 5 7 NULL 5 11 NULL 5 13 -12 13 17 NULL 13 19 NULL 13 23 1759 23
Som du kan se skapas ett unikt grp-värde när det sker en förändring i col1-värdet.
I det andra steget definierar du en CTE baserat på frågan från det första steget. Sedan, i den yttre frågan, returnerar du det maximala col1-värdet hittills, inom varje partition som definieras av grp. Det är det sista icke-NULL col1-värdet. Här är den fullständiga lösningskoden:
WITH C AS
(
SELECT id, col1,
MAX(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
MAX(col1) OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS lastval
FROM C; Det är helt klart mycket mer kod och arbete jämfört med att bara säga IGNORE_NULLS.
Ett annat vanligt behov är att returnera det första relevanta värdet. I vårt fall, anta att du måste returnera det första icke-NULL col1-värdet hittills baserat på id-beställning. Med standardbehandlingssatsen NULL skulle du hantera uppgiften med funktionen FIRST_VALUE och alternativet IGNORE NULLS, så här:
SELECT id, col1,
FIRST_VALUE(col1) IGNORE NULLS
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM dbo.T4; Här är det förväntade resultatet från den här frågan:
id col1 firstval ----------- ----------- ----------- 2 NULL NULL 3 10 10 5 -1 10 7 NULL 10 11 NULL 10 13 -12 10 17 NULL 10 19 NULL 10 23 1759 10
Lösningen i T-SQL använder en liknande teknik som den som användes för det senaste icke-NULL-värdet, men istället för en dubbel-MAX-metod använder du funktionen FIRST_VALUE ovanpå en MIN-funktion.
I det första steget använder du MIN-fönsterfunktionen för att beräkna en kolumn som kallas grp som har det lägsta id-värdet hittills när col1 inte är NULL, som så:
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4; Denna kod genererar följande utdata:
id col1 grp ----------- ----------- ----------- 2 NULL NULL 3 10 3 5 -1 3 7 NULL 3 11 NULL 3 13 -12 3 17 NULL 3 19 NULL 3 23 1759 3
Om det finns några NULL-värden före det första relevanta värdet slutar du med två grupper – den första med NULL som grp-värde och den andra med det första icke-NULL-id som grp-värde.
I det andra steget placerar du det första stegets kod i ett tabelluttryck. Sedan använder du i den yttre frågan funktionen FIRST_VALUE, partitionerad av grp, för att samla in det första relevanta (icke-NULL) värdet om det finns, och NULL annars, som så:
WITH C AS
(
SELECT id, col1,
MIN(CASE WHEN col1 IS NOT NULL THEN id END)
OVER(ORDER BY id
ROWS UNBOUNDED PRECEDING) AS grp
FROM dbo.T4
)
SELECT id, col1,
FIRST_VALUE(col1)
OVER(PARTITION BY grp
ORDER BY id
ROWS UNBOUNDED PRECEDING) AS firstval
FROM C; Återigen, det är mycket kod och arbete jämfört med att helt enkelt använda alternativet IGNORE_NULLS.
Om du känner att den här funktionen kan vara användbar för dig kan du rösta för att den inkluderas i T-SQL här.
ORDNING EFTER NULLER FÖRST | NULLER SIST
När du beställer data, oavsett om det är för presentationsändamål, fönster, TOP/OFFSET-FETCH-filtrering eller något annat syfte, är det frågan om hur NULLs ska bete sig i detta sammanhang? SQL-standarden säger att NULLs ska sorteras tillsammans antingen före eller efter icke-NULLs, och de överlåter till implementeringen att avgöra på ett eller annat sätt. Men vad leverantören än väljer måste det vara konsekvent. I T-SQL ordnas NULL först (före icke-NULL) när man använder stigande ordning. Betrakta följande fråga som ett exempel:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate, orderid;
Den här frågan genererar följande utdata:
orderid shippeddate ----------- ----------- 11008 NULL 11019 NULL 11039 NULL ... 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06
Utdata visar att ej levererade beställningar, som har ett NULL-leveransdatum, beställer före skickade beställningar, som har ett befintligt tillämpligt leveransdatum.
Men vad händer om du behöver NULL för att beställa sist när du använder stigande ordning? ISO/IEC SQL-standarden stöder en klausul som du tillämpar på ett ordningsuttryck som styr om NULLs ordning först eller sist. Syntaxen för denna sats är:
För att hantera vårt behov, returnera beställningarna sorterade efter deras leveransdatum, stigande, men med ej levererade beställningar som returneras sist, och sedan efter deras beställnings-ID som en tiebreaker, skulle du använda följande kod:
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY shippeddate NULLS LAST, orderid;
Tyvärr är denna NULLS-beställningsklausul inte tillgänglig i T-SQL.
En vanlig lösning som människor använder i T-SQL är att föregå ordningsuttrycket med ett CASE-uttryck som returnerar en konstant med ett lägre ordningsvärde för icke-NULL-värden än för NULL, som så (vi kallar den här lösningen för fråga 1):
SELECT orderid, shippeddate FROM Sales.Orders ORDER BY CASE WHEN shippeddate IS NOT NULL THEN 0 ELSE 1 END, shippeddate, orderid;
Denna fråga genererar önskad utdata med NULLs som visas sist:
orderid shippeddate ----------- ----------- 10249 2017-07-10 10252 2017-07-11 10250 2017-07-12 ... 11063 2019-05-06 11067 2019-05-06 11069 2019-05-06 11008 NULL 11019 NULL 11039 NULL ...
Det finns ett täckande index definierat i tabellen Sales.Orders, med kolumnen shippeddate som nyckel. Men på samma sätt som en manipulerad filtreringskolumn förhindrar SARG-möjligheten för filtret och möjligheten att tillämpa ett sök- ett index, förhindrar en manipulerad ordningskolumn möjligheten att förlita sig på indexordning för att stödja frågans ORDER BY-sats. Därför genererar SQL Server en plan för fråga 1 med en explicit sorteringsoperator, som visas i figur 1.
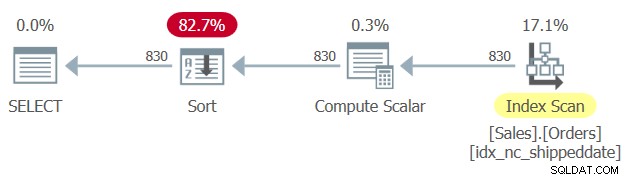 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Ibland är storleken på data inte så stor för att den explicita sorteringen ska vara ett problem. Men ibland är det så. Med explicit sortering blir frågans skalbarhet extralinjär (du betalar mer per rad ju fler rader du har), och svarstiden (tiden det tar att returnera den första raden) försenas.
Det finns ett knep som du kan använda för att undvika explicit sortering i ett sådant fall med en lösning som optimeras med en orderbevarande operatör för sammanfogning av sammanfogning. Du kan hitta en detaljerad täckning av denna teknik som används i olika scenarier i SQL Server:Undvika en sortering med sammanfogning av sammanfogning. Det första steget i lösningen förenar resultaten av två frågor:en fråga som returnerar raderna där beställningskolumnen inte är NULL med en resultatkolumn (vi kallar det sortcol) baserat på en konstant med något ordningsvärde, säg 0, och en annan fråga som returnerar raderna med NULL, med sortcol satt till en konstant med ett högre ordningsvärde än i den första frågan, säg 1. I det andra steget definierar du sedan ett tabelluttryck baserat på koden från det första steget, och sedan i den yttre frågan ordnar du raderna från tabelluttrycket först efter sortcol och sedan efter de återstående ordningselementen. Här är den kompletta lösningens kod som implementerar denna teknik (vi kallar den här lösningen Query 2):
WITH C AS ( SELECT orderid, shippeddate, 0 AS sortcol FROM Sales.Orders WHERE shippeddate IS NOT NULL UNION ALL SELECT orderid, shippeddate, 1 AS sortcol FROM Sales.Orders WHERE shippeddate IS NULL ) SELECT orderid, shippeddate FROM C ORDER BY sortcol, shippeddate, orderid;
Planen för denna fråga visas i figur 2.
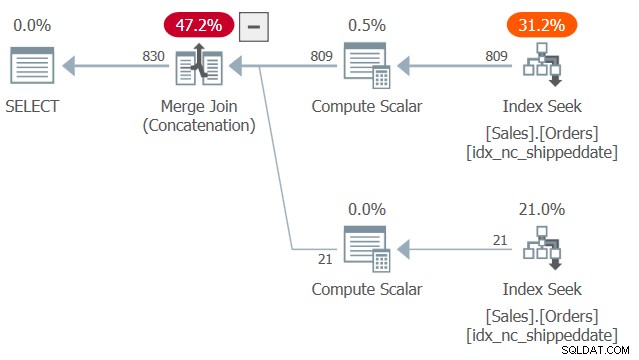 Figur 2:Plan för fråga 2
Figur 2:Plan för fråga 2
Lägg märke till två sökningar och beställda intervallsökningar i det täckande indexet idx_nc_shippeddate - en drar raderna där shippeddate inte är NULL och en annan drar rader där shippeddate är NULL. Sedan, på samma sätt som Merge Join-algoritmen fungerar i en sammanfogning, förenar Merge Join (Concatenation)-algoritmen raderna från de två ordnade sidorna på ett blixtlåsliknande sätt och bevarar den intagna ordningen för att stödja frågans presentationsordningsbehov. Jag säger inte att den här tekniken alltid är snabbare än den mer typiska lösningen med CASE-uttrycket, som använder explicit sortering. Den förra har dock linjär skalning och den senare har n log n skalning. Så den förra tenderar att klara sig bättre med stort antal rader och den senare med små antal.
Uppenbarligen är det bra att ha en lösning för detta vanliga behov, men det kommer att bli mycket bättre om T-SQL lade till stöd för standard NULL-beställningsklausulen i framtiden.
Slutsats
ISO/IEC SQL-standarden har en hel del NULL-hanteringsfunktioner som ännu inte har gjort det till T-SQL. I den här artikeln täckte jag några av dem:DISTINCT-predikatet, NULL-behandlingsklausulen och kontrollen av om NULLs ordning först eller sist. Jag gav också lösningar för dessa funktioner som stöds i T-SQL, men de är uppenbarligen besvärliga. Nästa månad fortsätter jag diskussionen genom att täcka den unika standardbegränsningen, hur den skiljer sig från T-SQL-implementeringen och de lösningar som kan implementeras i T-SQL.