När du är djupt involverad i att felsöka ett problem i SQL Server, kommer du ibland på att du vill veta exakt i vilken ordning frågorna kördes. Jag ser detta med mer komplicerade lagrade procedurer som innehåller lager av logik, eller i scenarier där det finns mycket redundant kod. Extended Events är ett naturligt val här, eftersom det vanligtvis används för att fånga information om exekvering av frågor. Du kan ofta använda session_id och tidsstämpeln för att förstå händelseordningen, men det finns ett sessionsalternativ för XE som är ännu mer tillförlitligt:Spåra orsakssamband.
När du aktiverar Spåra orsakssamband för en session lägger den till ett GUID och ett sekvensnummer till varje händelse, som du sedan kan använda för att gå igenom ordningen i vilken händelserna inträffade. Omkostnaderna är minimala och det kan vara en betydande tidsbesparing i många felsökningsscenarier.
Konfigurera
Med hjälp av WideWorldImporters-databasen skapar vi en lagrad procedur att använda:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Sedan skapar vi en eventsession:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); Vi kommer också att köra ad-hoc-frågor, så vi fångar både sp_statement_completed (påståenden slutförda inom en lagrad procedur) och sql_statement_completed (påståenden slutförda som inte är inom en lagrad procedur). Observera att alternativet TRACK_CAUSALITY för sessionen är inställt på PÅ. Återigen, den här inställningen är specifik för händelsesessionen och måste aktiveras innan den startas. Du kan inte aktivera inställningen direkt, som att du kan lägga till eller ta bort händelser och mål medan sessionen pågår.
För att starta händelsesessionen genom gränssnittet, högerklicka bara på den och välj Starta session.
Test
Inom Management Studio kör vi följande kod:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Här är vår XE-utgång:

Observera att den första frågan som körs, som är markerad, är SELECT @@SPID och har en GUID av FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. Vi körde inte den här frågan, den inträffade i bakgrunden, och även om XE-sessionen är inställd för att filtrera bort systemfrågor, fångas den här – av vilken anledning som helst – fortfarande.
De nästa fyra raderna representerar koden vi faktiskt körde. Det finns de två frågorna från den lagrade proceduren, själva den lagrade proceduren och sedan vår ad-hoc-fråga. Alla har samma GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Bredvid GUID finns sekvens-id (seq), och frågorna är numrerade ett till fyra.
I vårt exempel använde vi inte GO för att dela upp satserna i olika partier. Lägg märke till hur utdata ändras när vi gör det:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

Vi har fortfarande samma antal totala rader, men nu har vi tre GUID. En för SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), en för de tre frågorna som representerar den lagrade proceduren (F962B9A4-0665-4802-9E6C-B217634D8787), och en för ad-hoc 5 -9702-4DE5-8467-8D7CF55B5D80).
Detta är vad du troligen kommer att se när du tittar på data från din applikation, men det beror på hur applikationen fungerar. Om den använder anslutningspooling och anslutningarna återställs regelbundet (vilket förväntas), kommer varje anslutning att ha sin egen GUID.
Du kan återskapa detta med hjälp av exempel PowerShell-koden nedan:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Här är ett exempel på utökade händelser efter att ha låtit koden köras en stund:

Det finns fyra olika GUID för våra fem påståenden, och om du tittar på koden ovan ser du att det finns fyra olika anslutningar. Om du ändrar händelsesessionen för att inkludera händelsen rpc_completed, kan du se poster med exec sp_reset_connection.
Din XE-utgång kommer att bero på din kod och din applikation; Jag nämnde först att detta var användbart vid felsökning av mer komplexa lagrade procedurer. Tänk på följande exempel:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Här har vi två lagrade procedurer, usp_TransctionInfo och usp_GetFullCustomerInfo, som anropas av en annan lagrad procedur, usp_GetCustomerData. Det är inte ovanligt att se detta, eller till och med se ytterligare nivåer av kapsling med lagrade procedurer. Om vi kör usp_GetCustomerData från Management Studio ser vi följande:
EXEC [Sales].[usp_GetCustomerData] 981;

Här inträffade alla körningar på samma GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, och vi kan se ordningsföljden för exekvering av fråge från ett till åtta med hjälp av seq-kolumnen. I fall där flera lagrade procedurer anropas är det inte ovanligt att sekvens-id-värdet hamnar i hundratals eller tusentals.
Slutligen, i fallet där du tittar på körning av en fråga och du har inkluderat spåra orsakssamband, och du hittar en fråga som ger dåligt resultat – eftersom du sorterade utdata baserat på varaktighet eller något annat mått, notera att du kan hitta den andra frågor genom att gruppera på GUID:
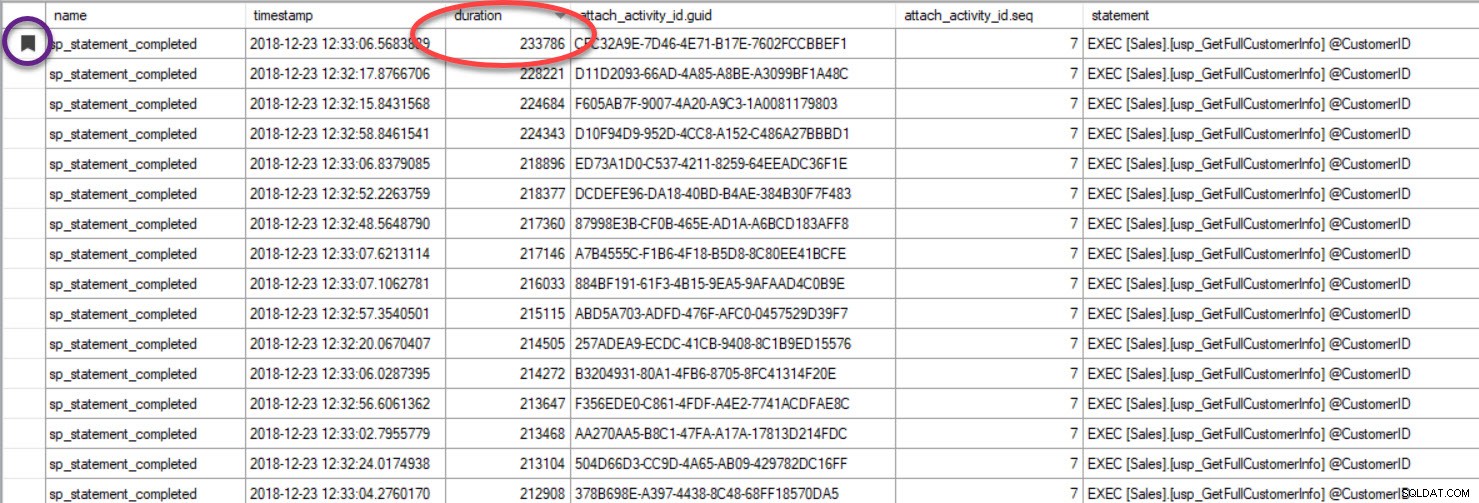
Utdata har sorterats efter varaktighet (högsta värdet inringat i rött), och jag har bokmärkt det (i lila) med knappen Växla bokmärke. Om vi vill se de andra frågorna för GUID, gruppera efter GUID (Högerklicka på kolumnnamnet högst upp, välj sedan Gruppera efter denna kolumn), och använd sedan knappen Nästa bokmärke för att komma tillbaka till vår fråga:
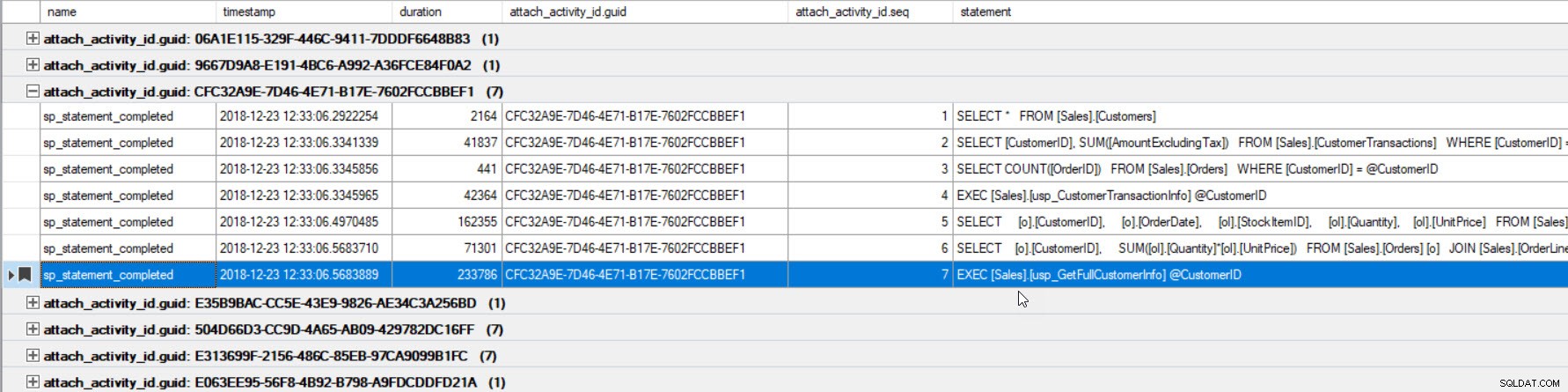
Nu kan vi se alla frågor som kördes inom samma anslutning och i den körda ordningen.
Slutsats
Alternativet Spåra orsakssamband kan vara oerhört användbart när du felsöker frågeprestanda och försöker förstå händelseordningen i SQL Server. Det är också användbart när du ställer in en händelsesession som använder målet pair_matching, för att säkerställa att du matchar på rätt fält/åtgärd och hittar rätt omatchad händelse. Återigen, detta är en inställning på sessionsnivå, så den måste tillämpas innan du startar händelsesessionen. För en session som är igång, stoppa händelsesessionen, aktivera alternativet och starta den sedan igen.