På PASS Summit för några veckor sedan släppte Microsoft CTP2.1 av SQL Server 2019, och en av de stora funktionsförbättringarna som ingår i CTP är Scalar UDF Inlining. Före den här utgåvan ville jag leka med prestandaskillnaden mellan inlining av skalära UDF:er och RBAR (rad-för-plågsamma-rad) exekvering av skalära UDF:er i tidigare versioner av SQL Server och jag råkade ut för ett syntaxalternativ för SKAPA FUNKTION uttalande i SQL Server Books Online som jag aldrig hade sett förut.
DDL för SKAPA FUNKTION stöder en WITH-sats för funktionsalternativ och när jag läste Books Online märkte jag att syntaxen inkluderade följande:
-- Transact-SQL funktionsklausuler::= { [ KRYPTERING ] | [ SCHEMABINDING ] | [ GÅR NULL PÅ NULL INPUT | KALLAD PÅ NULL INPUT ] | [ EXECUTE_AS_Clause ] }
Jag var verkligen nyfiken på RETURNS NULL ON NULL INPUT funktionsalternativ så jag bestämde mig för att göra några tester. Jag blev mycket förvånad över att få reda på att det faktiskt är en form av skalär UDF-optimering som har funnits i produkten sedan åtminstone SQL Server 2008 R2.
Det visar sig att om du vet att en skalär UDF alltid kommer att returnera ett NULL-resultat när en NULL-ingång tillhandahålls, bör UDF ALLTID skapas med RETURNS NULL ON NULL INPUT alternativet, för då kör SQL Server inte ens funktionsdefinitionen alls för några rader där indata är NULL – kortsluter den i praktiken och undviker bortkastad exekvering av funktionskroppen.
För att visa dig detta beteende kommer jag att använda en SQL Server 2017-instans med den senaste kumulativa uppdateringen applicerad på den och AdventureWorks2017 databas från GitHub (du kan ladda ner den härifrån) som levereras med en dbo.ufnLeadingZeros funktion som helt enkelt lägger till inledande nollor till inmatningsvärdet och returnerar en sträng på åtta tecken som inkluderar de inledande nollorna. Jag ska skapa en ny version av den funktionen som inkluderar RETURNS NULL ON NULL INPUT alternativet så att jag kan jämföra det med den ursprungliga funktionen för exekveringsprestanda.
ANVÄND [AdventureWorks2017]; GÅ SKAPA FUNKTION [dbo].[ufnLeadingZeros_new]( @Value int ) RETURER varchar(8) MED SCHEMABINDING, RETURERAR NULL PÅ NULL INPUT AS BEGIN Retur DECLARE); SET @ReturnValue =CONVERT(varchar(8), @Value); SET @ReturnValue =REPLICATE('0', 8 - DATALENGTH(@ReturnValue)) + @ReturnValue; RETURN (@ReturnValue); SLUTET; GÅ I syfte att testa skillnaderna i exekveringsprestanda inom databasmotorn för de två funktionerna, bestämde jag mig för att skapa en Extended Event-session på servern för att spåra sqlserver.module_end händelse, som utlöses i slutet av varje exekvering av den skalära UDF:en för varje rad. Detta låter mig demonstrera rad-för-rad-bearbetningssemantiken, och låter mig också spåra hur många gånger funktionen faktiskt anropades under testet. Jag bestämde mig för att också samla in sql_batch_completed och sql_statement_completed händelser och filtrera allt efter session_id för att vara säker på att jag bara fångar information relaterad till sessionen jag faktiskt körde testerna på (om du vill replikera dessa resultat måste du ändra 74:an på alla ställen i koden nedan till vilket sessions-ID som helst ditt test kod kommer att köras in). Eventsessionen använder TRACK_CAUSALITY så att det är lätt att räkna hur många körningar av funktionen som skedde genom activity_id.seq_no värde för händelserna (vilket ökar med ett för varje händelse som uppfyller session_id filter).
SKAPA EVENT SESSION [Session72] PÅ SERVER ADD EVENT sqlserver.module_end( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver_comple ( [paket0].[equal_uint64]([sqlserver].[session_id],(74)))), LÄGG TILL HÄNDELSE sqlserver.sql_batch_starting( VAR ([paket0].[equal_uint64]([sqlserver].[session_id],(74) ))), ADD EVENT sqlserver.sql_statement_completed( WHERE ([package0].[equal_uint64]([sqlserver].[session_id],(74)))), ADD EVENT sqlserver.sql_statement_starting( WHERE ([equal_uint64]) ([sqlserver].[session_id],(74)))) MED (TRACK_CAUSALITY=ON) GO
När jag startade evenemangssessionen och öppnade Live Data Viewer i Management Studio, körde jag två frågor; en som använder den ursprungliga versionen av funktionen för att fylla nollor till CurrencyRateID kolumnen i Sales.SalesOrderHeader tabell och den nya funktionen för att producera identisk utdata men med RETURNER NULL ON NULL INPUT alternativet, och jag samlade in informationen om den faktiska utförandeplanen för jämförelse.
SELECT SalesOrderID, dbo.ufnLeadingZeros(CurrencyRateID) FROM Sales.SalesOrderHeader; GO SELECT SalesOrderID, dbo.ufnLeadingZeros_new(CurrencyRateID) FROM Sales.SalesOrderHeader; GÅ
Granskning av data för utökade evenemang visade ett par intressanta saker. Först kördes den ursprungliga funktionen 31 465 gånger (från antalet module_end händelser) och den totala CPU-tiden för sql_statement_completed händelsen var 204 ms med en längd på 482 ms.
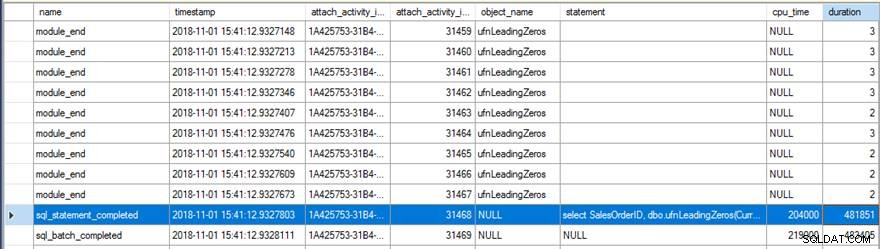
Den nya versionen med RETURNS NULL ON NULL INPUT det angivna alternativet kördes endast 13 976 gånger (igen, från antalet module_end händelser) och CPU-tiden för sql_statement_completed händelsen var 78 ms med en längd på 359 ms.

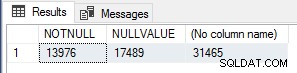
Jag tyckte detta var intressant så för att verifiera antalet körningar körde jag följande fråga för att räkna NOT NULL värderader, rader med NULL-värden och totala rader i Sales.SalesOrderHeader bord.
SELECT SUM(CASE WHEN CurrencyRateID IS NOT NULL THEN 1 ELSE 0 END) AS NOTNULL, SUM(CASE WHEN CurrencyRateID IS NULL THEN 1 ELSE 0 END) AS NULLVALUE, COUNT , COUNT.
Dessa siffror motsvarar exakt antalet module_end händelser för vart och ett av testerna, så detta är definitivt en mycket enkel prestandaoptimering för skalära UDF:er som bör användas om du vet att resultatet av funktionen blir NULL om ingångsvärdena är NULL, för att kortsluta/förbikoppla funktionsexekvering helt för dessa rader.
QueryTimeStats-informationen i de faktiska exekveringsplanerna återspeglade också prestandavinsterna:
Detta är en ganska betydande minskning av enbart CPU-tid, vilket kan vara en betydande smärtpunkt för vissa system.
Användningen av skalära UDF:er är ett välkänt designantimönster för prestanda och det finns en mängd olika metoder för att skriva om koden för att undvika deras användning och prestandaträff. Men om de redan är på plats och inte enkelt kan ändras eller tas bort, återskapa UDF helt enkelt med RETURNS NULL ON NULL INPUT alternativet kan vara ett mycket enkelt sätt att förbättra prestandan om det finns många NULL-indata i datamängden där UDF används.