Introduktion
I den här artikeln kommer vi att prata om att använda nvarchar data typ. Vi kommer att utforska hur SQL Server lagrar denna datatyp på disken och hur den bearbetas i RAM-minnet. Vi kommer också att undersöka hur storleken på nvarchar kan påverka prestandan.
Faktisk datastorlek:nchar vs nvarchar
Vi använder nvarchar när storleken på kolumndataposter förmodligen kommer att variera avsevärt. Lagringsstorleken (i byte) är dubbelt så stor som den faktiska längden på inmatad data + 2 byte. Detta gör att vi kan spara disklagring i jämförelse med att använda nchar data typ. Låt oss överväga följande exempel. Vi skapar två tabeller. En tabell innehåller nvarchar-kolumn, en annan tabell innehåller nchar-kolumner. Storleken på kolumnen är 2000 tecken (4000 byte).
CREATE TABLE dbo.testnvarchar (
col1 NVARCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnvarchar (col1)
SELECT
REPLICATE('&', 10)
GO
CREATE TABLE dbo.testnchar (
col1 NCHAR(2000) NULL
);
GO
INSERT INTO dbo.testnchar (col1)
SELECT
REPLICATE('&', 10)
GO
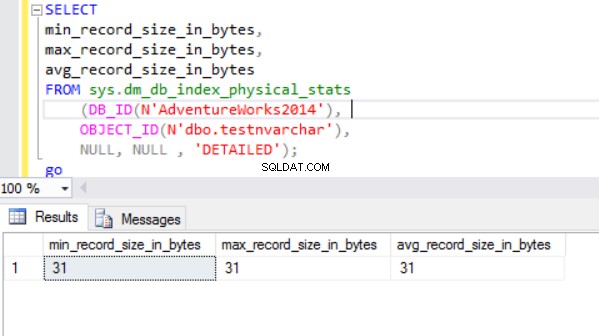
Den faktiska radstorleken är:
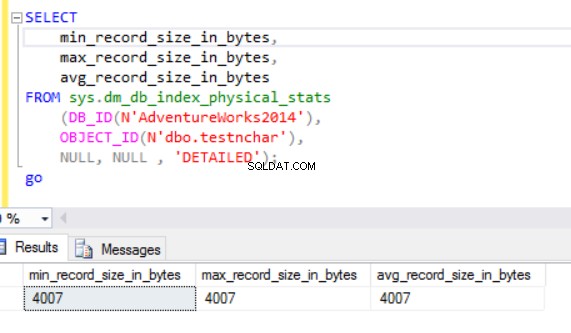
Som vi kan se är den faktiska radstorleken för nvarchar-datatypen mycket mindre än nchar-datatypen. I fallet med nchar-datatypen använder vi ~4000 byte för att lagra 10 symboler teckensträng. Vi använder ~20 byte för att lagra samma teckensträng i fallet med nvarchar-datatypen.
SQL Server-motorn bearbetar data till RAM (buffertpool). Hur är det med radstorleken i minnet?
Faktisk datastorlek:HDD vs RAM
Låt oss köra följande fråga:
SELECT col1 FROM dbo.testnchar;

Det finns ingen skillnad mellan disk- och RAM-användning när det gäller teckensträngen med fast längd.
SELECT col1 FROM dbo.testnvarchar;

Vi kan se att SQL Server Engine begärde minnet för bara hälften av den deklarerade radstorleken (2000 byte istället för faktiska 20 byte) och flera byte för ytterligare information. Från en sida minskar vi diskutrymmesanvändningen men från en annan kan vi blåsa upp det begärda RAM-minnet. Detta är en bieffekt av användningen av de olika teckendatatyperna. Denna bieffekt kan i vissa fall påverka resurserna kraftigt.
FORMAT():RAM begärt kontra använt RAM
Vi använder FORMAT-funktionen, som returnerar ett formaterat värde med angivet format och valfri kultur. Returvärdet är nvarchar eller null. Längden på returvärdet bestäms av formatet . FORMAT(getdate(), 'ååååMMdd','en-US') kommer att resultera i '20170412'. Vi behöver 16 byte för att lagra detta resultat i kolumnen på skivan (resultatet blir nvarchar(8)). Vad är datastorleken i RAM-minnet för den specifika datan?
Låt oss köra följande fråga. Vi använder följande miljö:
- AdventureWorks2014
- MS SQL 2016 utvecklingsutgåva
- dbo.Customer (19'820'000 poster) innehåller data från Sales.Customer (19'820 poster har laddats upp 1000 gånger)):
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,FORMAT([modifieddate], 'yyyyMMdd', 'en-US') AS md
,' ' AS code INTO #tmp
FROM rs
Frågeexekveringsplanen är ganska enkel:

Den första operationen är "Clustered index scan" på dbo.Customer-tabellen. ~19 000 000 poster har lästs. Uppskattad datastorlek är 435 Mb.
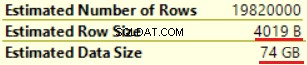
Nästa operation är "Compute Scalar" (beräkning av FORMAT()-funktionen). Resultatet är ganska oväntat eftersom vi formaterar 16 bytes teckensträng. Radstorleken ökade dramatiskt från 23 byte till 4019 byte. Samma sak med den uppskattade datastorleken — från 435 MB till 74 GB. Vi kan se att FORMAT() returnerar NVARCHAR(4000).
MS SQL Server 2016 har den fantastiska förmågan att visa överdrivet minnestillstånd. Vi kan se varningen i den senaste operationen (T-SQL SELECT INTO):
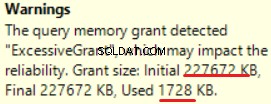
Detta är "överbeviljat" av minnet:mer än 90 % av det beviljade minnet används inte.
Frågetidsstatistiken är:
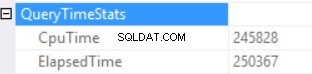
Den långa exekveringstiden beror på en icke-effektiv exekvering av skalärfunktioner och bakre bieffekt av en Excessive Memory Grant – Hash Match (Right Outer Join). Vi har en kumulativ effekt av två olika orsaker:exekvering av flera skalära funktioner och överdriven minnestilldelning.
SQL Server-motorn kan inte ge mer än 25 % av det tillåtna minnet per fråga. Vi kan ändra detta belopp i företagsutgåvan av MS SQL Server med hjälp av resursregulatorn. Det beviljade minnet består av två delar:obligatoriskt och extra. Ett erforderligt minne används för de interna behoven – för sortering och hash join-operationer. Ytterligare minne är baserat på den uppskattade datastorleken. Om både erforderligt och extra minne överskrider gränsen på 25 %, ger SQL Server-motorn ytterligare 25 % av det tillgängliga minnet. Läs inlägget om SQL Server-minnesbeviljande för detaljer.
Låt oss köra samma fråga utan FORMAT()-funktionen.
;WITH rs
AS
(SELECT
c.customerid
,c.modifieddate
,p.LastName
FROM [dbo].[Customer] c
LEFT OUTER JOIN [person].[person] p
ON p.BusinessEntityID = c.PersonID)
SELECT
customerid
,LastName
,' ' AS code INTO #tmp
FROM rs
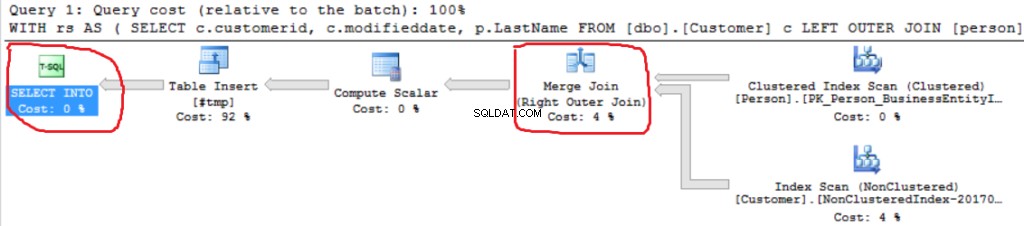
Vi kan se en annan Right Outer Join-implementering (Merge Join istället för Hash Join).
Memory Grant info är (om ingen sortering och Hash Join SQL Server kan ge inget minne):
Frågetiden Statistiken är (tiden minskar förutsägbart:ingen skalär funktion körs, den uppskattade datastorleken är mindre än i föregående exempel):

Så vi blåser upp det "beviljade minnet" till 222 MB (och använder mindre än 2 MB av det) genom att använda FORMAT()-funktionen. Datavolymen i exemplet är liten.
Lång tids körningsfråga
Betrakta den verkliga SQL-frågan från en produktionsmiljö. Den här frågan har körts under en batchladdningsprocess (inte ett klassiskt transaktionsscenario). Vi använder MS SQL Server som startas på Amazon Web Services (AWS, Amazon Relational Database Service). DB-instansens egenskaper är 160 GB RAM (inte mer än ~30 GB RAM-minne kan beviljas per fråga) och 40 vCPU. SQL-frågan var nästan densamma som exemplet ovan (skillnaden är i antal tabeller och datastorlek):CTE inkluderade koppling mellan 6 tabeller. "Mastertabellen" (en tabell i FROM-satsen) innehåller ~175'000'000 poster och datastorleken är 20GB. Uppslagstabellerna (höger tabell i JOIN-satsen) är små (i jämförelse med huvudtabellen). SQL-frågan innehåller två anrop av FORMAT()-funktionen (två kolumner från "master table"-tabellen är parametern för denna funktion).
Produktionsfrågan ser ut så här:
;WITH rs AS ( SELECT <in column list>, c.modifieddate, c.createddate FROM [Master table] c LEFT OUTER JOIN [table1 ] p1 ON … LEFT OUTER JOIN [table2 ] p2 ON … LEFT OUTER JOIN [table3 ] p3 ON … LEFT OUTER JOIN [table4 ] p4 ON … LEFT OUTER JOIN [table5 ] p5 ON … ) SELECT DISTINT <out column list>, FORMAT([modifieddate], 'yyyyMMdd','en-US') AS md, FORMAT([createddate], 'yyyyMMdd','en-US') AS cd INTO #tmp FROM rs
"Bilden" av utförandeplanen är nedan (utförandeplanen är enkel:sekventiell sammanfogning och sortering (SÄRSKILDA nyckelord) överst):

Låt oss utforska informationen i detalj.
Den första operationen är "Table scan" (allt är korrekt, inga överraskningar):

Operationen "Scalar compute" ökar dramatiskt den uppskattade radstorleken såväl som den uppskattade radstorleken (från 19 GB upp till 1,3 TB). Två anrop av FORMAT()-funktionen lade till cirka 8000 byte till den uppskattade radstorleken (men den faktiska datastorleken är mindre).

En av JOIN-operationerna (Hash Match, Right Outer Join) använder icke-unika kolumner från den högra tabellen. Det spelar ingen roll när det gäller några få skivor. Detta är inte vårt fall. Som ett resultat ökar den uppskattade datastorleken upp till ~2,4TB.

Det finns också en varning (inte tillräckligt med RAM för att bearbeta denna operation):
SQL-frågan innehåller en "Distinct Sorter"-operation på toppen, som ser ut som körsbäret på toppen av en kaka. Vi kan se samma varning där.
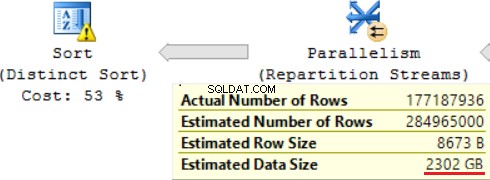
Ett resultat av att använda en skalär funktion är en lång tid för utförande av en fråga:24 timmar. En av orsakerna till detta problem är en felaktig uppskattning av den begärda datastorleken baserat på "Uppskattad datastorlek". Utan att använda FORMAT()-funktionen, kör MS SQL Server denna fråga på 2 timmar.
Slutsats
Utvecklare bör vara försiktiga när de använder datatyperna nvarchar och varchar. Att välja redundanta datatyper för kolumner kan leda till att det erforderliga minnet blåser upp. Som ett resultat kommer RAM att gå till spillo, databasprestanda försämras.