Folk undrar om de ska göra sitt bästa för att förhindra undantag, eller bara låta systemet hantera dem. Jag har sett flera diskussioner där folk diskuterar om de ska göra vad de kan för att förhindra ett undantag, eftersom felhantering är "dyrt". Det råder ingen tvekan om att felhantering inte är gratis, men jag skulle förutsäga att en begränsningsöverträdelse är minst lika effektiv som att först kontrollera efter en potentiell överträdelse. Detta kan vara annorlunda för en nyckelöverträdelse än en statisk begränsningsöverträdelse, till exempel, men i det här inlägget ska jag fokusera på det förstnämnda.
De primära metoder som människor använder för att hantera undantag är:
- Låt bara motorn hantera det och skicka eventuella undantag tillbaka till den som ringer.
- Använd
BEGIN TRANSACTIONochROLLBACKom@@ERROR <> 0. - Använd
TRY/CATCHmedROLLBACKiCATCHblockera (SQL Server 2005+).
Och många tar tillvägagångssättet att de bör kontrollera om de kommer att drabbas av överträdelsen först, eftersom det verkar renare att hantera dubbletten själv än att tvinga motorn att göra det. Min teori är att man ska lita på men verifiera; överväg till exempel detta tillvägagångssätt (oftast pseudokod):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Vi vet att IF NOT EXISTS check garanterar inte att någon annan inte har infogat raden när vi kommer till INSERT (såvida vi inte placerar aggressiva lås på bordet och/eller använder SERIALIZABLE ), men den yttre kontrollen hindrar oss från att försöka begå ett misslyckande och sedan behöva rulla tillbaka. Vi håller oss utanför hela TRY/CATCH struktur om vi redan vet att INSERT kommer att misslyckas, och det skulle vara logiskt att anta att – åtminstone i vissa fall – detta kommer att vara mer effektivt än att ange TRY/CATCH strukturera villkorslöst. Detta är lite meningsfullt i en enda INSERT scenario, men föreställ dig ett fall där det händer mer i den TRY blockera (och fler potentiella överträdelser som du kan kontrollera i förväg, vilket innebär ännu mer arbete som du annars skulle behöva utföra och sedan återställa om en senare överträdelse skulle inträffa).
Nu skulle det vara intressant att se vad som skulle hända om du använde en icke-standardisoleringsnivå (något jag kommer att behandla i ett framtida inlägg), särskilt med samtidighet. För det här inlägget ville jag dock börja långsamt och testa dessa aspekter med en enda användare. Jag skapade en tabell som heter dbo.[Objects] , en mycket förenklad tabell:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Jag ville fylla den här tabellen med 100 000 rader med exempeldata. För att göra värdena i namnkolumnen unika (eftersom PK är den begränsning jag ville bryta mot) skapade jag en hjälpfunktion som tar ett antal rader och en minimisträng. Minsta strängen skulle användas för att säkerställa att antingen (a) uppsättningen startade förbi det maximala värdet i objekttabellen, eller (b) uppsättningen startade vid minimivärdet i objekttabellen. (Jag kommer att specificera dessa manuellt under testerna, verifierade helt enkelt genom att inspektera data, även om jag förmodligen kunde ha byggt in den checken i funktionen.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Detta gäller en CROSS JOIN av sys.all_objects på sig själv genom att lägga till ett unikt radnummer till varje namn, så de första 10 resultaten skulle se ut så här:
Att fylla tabellen med 100 000 rader var enkelt:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Nu, eftersom vi kommer att infoga nya unika värden i tabellen, skapade jag en procedur för att utföra en del rensning i början och slutet av varje test – förutom att ta bort alla nya rader vi har lagt till, kommer det också att städas upp cachen och buffertarna. Inget du vill koda in i en procedur på ditt produktionssystem, naturligtvis, men ganska bra för lokal prestandatestning.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Jag skapade också en loggtabell för att hålla reda på start- och sluttider för varje test:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Slutligen hanterar den lagrade testproceduren en mängd olika saker. Vi har tre olika felhanteringsmetoder, som beskrivs i punkterna ovan:"JustInsert", "Rollback" och "TryCatch"; vi har också tre olika infogningstyper:(1) alla inserts lyckas (alla rader är unika), (2) alla inserts misslyckas (alla rader är dubbletter) och (3) halva inserts lyckas (hälften av raderna är unika och hälften raderna är dubbletter). I kombination med detta finns två olika tillvägagångssätt:kontrollera för överträdelsen innan du försöker infoga, eller bara gå vidare och låt motorn avgöra om den är giltig. Jag trodde att detta skulle ge en bra jämförelse av de olika felhanteringsteknikerna i kombination med olika sannolikheter för kollisioner för att se om en hög eller låg kollisionsprocent skulle påverka resultaten avsevärt.
För dessa tester valde jag 40 000 rader som mitt totala antal insättningsförsök, och i proceduren utför jag en sammanslutning av 20 000 unika eller icke-unika rader med 20 000 andra unika eller icke-unika rader. Du kan se att jag hårdkodade cutoff-strängarna i proceduren; observera att på ditt system kommer dessa avbrott nästan säkert att inträffa på en annan plats.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Nu kan vi kalla denna procedur med olika argument för att få det olika beteendet vi är ute efter, att försöka infoga 40 000 värden (och förstås veta hur många som ska lyckas eller misslyckas i varje fall). För varje 'felhanteringsmetod' (försök bara infogningen, använd start tran/rollback eller försök/fånga) och varje infogningstyp (alla lyckas, hälften lyckas och ingen lyckas), kombinerat med om du ska kontrollera överträdelsen eller inte För det första ger detta oss 18 kombinationer:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;000;
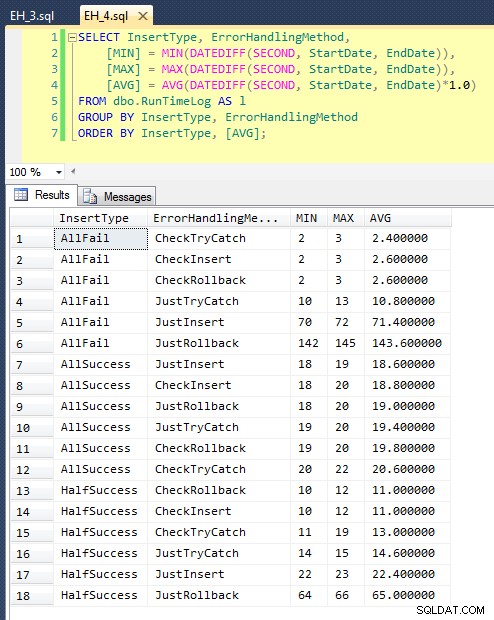
Efter att vi har kört detta (det tar cirka 8 minuter på mitt system), har vi några resultat i vår logg. Jag körde hela partiet fem gånger för att se till att vi fick anständiga medelvärden och för att jämna ut eventuella anomalier. Här är resultaten:
Grafen som plottar alla varaktigheter på en gång visar ett par allvarliga extremvärden:
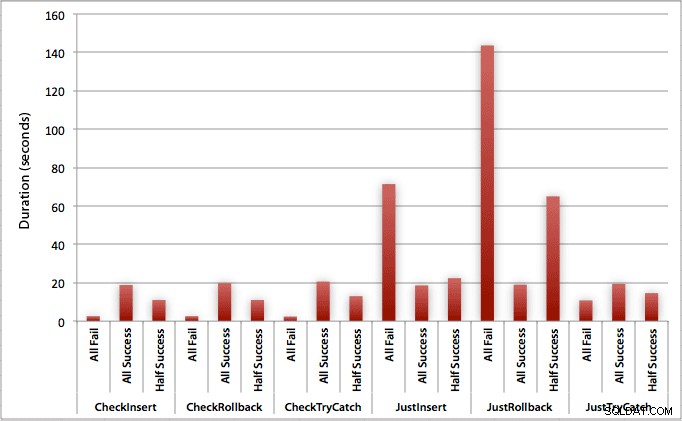
Du kan se att i de fall där vi förväntar oss en hög frekvens av misslyckanden (i det här testet 100 %), är att börja en transaktion och återställa det överlägset minst attraktiva tillvägagångssättet (3,59 millisekunder per försök), samtidigt som man bara låter motorn lyfta ett fel är ungefär hälften så illa (1,785 millisekunder per försök). Det näst sämsta resultatet var fallet där vi påbörjar en transaktion och sedan återställer den, i ett scenario där vi förväntar oss att ungefär hälften av försöken misslyckas (i genomsnitt 1,625 millisekunder per försök). De 9 fallen på vänster sida av diagrammet, där vi kontrollerar överträdelsen först, vågade sig inte över 0,515 millisekunder per försök.
Med det sagt, de individuella graferna för varje scenario (hög % av framgång, hög % av misslyckanden och 50-50) ger verkligen intrycket av varje metod.
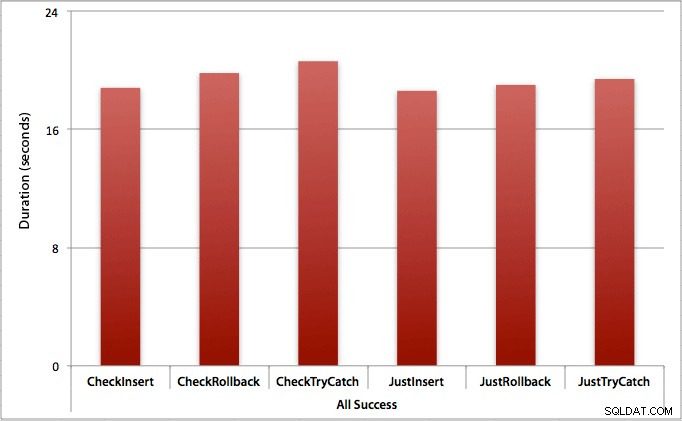
Där alla insättningar lyckas
I det här fallet ser vi att kostnaden för att kontrollera överträdelsen först är försumbar, med en genomsnittlig skillnad på 0,7 sekunder över batchen (eller 125 mikrosekunder per insättningsförsök):
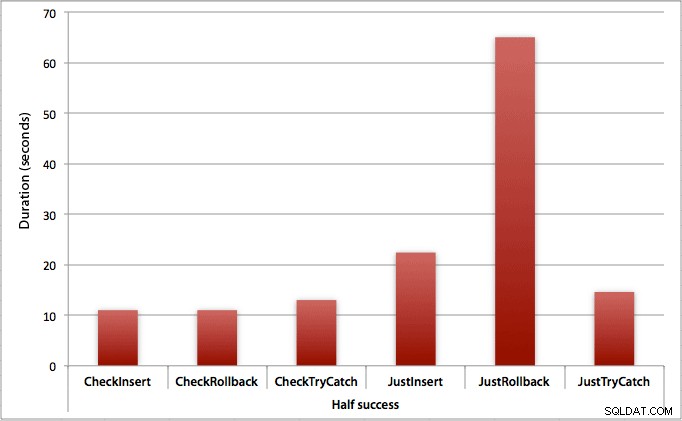
Där bara halva inläggen lyckas
När hälften av skären misslyckas ser vi ett stort hopp i varaktigheten för insättnings-/återställningsmetoderna. Scenariot där vi startar en transaktion och återställer den är ungefär 6 gånger långsammare över batchen jämfört med att kontrollera först (1,625 millisekunder per försök mot 0,275 millisekunder per försök). Även TRY/CATCH-metoden är 11 % snabbare när vi först kollar:
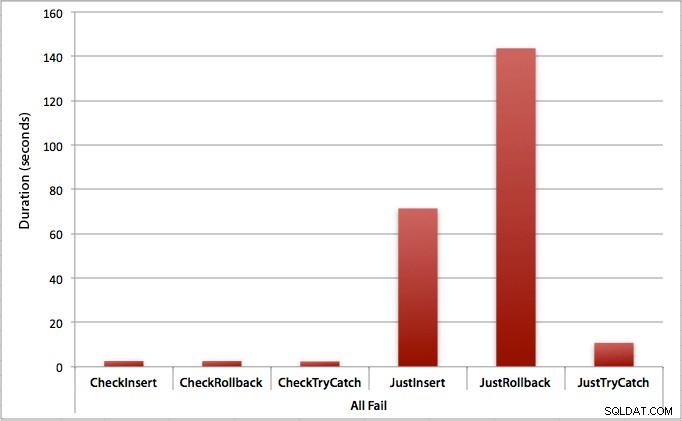
Där alla inlägg misslyckas
Som du kan förvänta dig visar detta den mest uttalade effekten av felhantering och de mest uppenbara fördelarna med att kontrollera först. Återställningsmetoden är nästan 70 gånger långsammare i det här fallet när vi inte kontrollerar jämfört med när vi gör det (3,59 millisekunder per försök kontra 0,065 millisekunder per försök):
Vad säger detta oss? Om vi tror att vi kommer att få en hög felfrekvens, eller inte har någon aning om vad vår potentiella felfrekvens kommer att vara, kommer det att vara oerhört värt mödan att kontrollera först för att undvika överträdelser i motorn. Även i de fall där vi har ett framgångsrikt insert varje gång, är kostnaden för att kontrollera först marginell och lätt motiverad av den potentiella kostnaden för att hantera fel senare (om inte din förväntade felfrekvens är exakt 0%).
Så för nu tror jag att jag kommer att hålla fast vid min teori om att det i enkla fall är vettigt att kontrollera om det finns en potentiell överträdelse innan du säger åt SQL Server att gå vidare och infoga ändå. I ett framtida inlägg kommer jag att titta på prestandapåverkan av olika isoleringsnivåer, samtidighet och kanske till och med några andra felhanteringstekniker.
[Som en sida skrev jag en komprimerad version av det här inlägget som ett tips för mssqltips.com redan i februari.]