Lastbalanserare är en viktig komponent i alla högt tillgängliga databasinställningar. De används för att öka kapaciteten och tillförlitligheten hos dina kritiska system och applikationer genom att förhindra att någon server blir överbelastad. Vi pratar mycket om dem på Severalnines-bloggen, som varför du behöver dem och hur de fungerar. En av de mest populära lastbalanserarna som finns tillgängliga för MySQL och MariaDB är HAProxy.
Funktionsmässigt är HAProxy inte jämförbar med ProxySQL eller MaxScale. HAProxy är dock en snabb, robust lastbalanserare som kommer att fungera perfekt i alla miljöer så länge som applikationen kan utföra läs/skrivdelning och skicka SELECT-frågor till en backend och alla skrivningar och SELECT...FOR UPDATE till en separat backend.
Att hålla reda på alla mätvärden som görs tillgängliga av HAProxy är mycket viktigt; du måste kunna känna till statusen för din proxy, särskilt för att veta om du har stött på några problem.
ClusterControl har alltid gjort en HAProxy-statussida tillgänglig som visar proxyns tillstånd i realtid. Nu, med de nya Prometheus-baserade instrumentpanelerna SCUMM (Severalnines ClusterControl Unified Monitoring &Management) är det möjligt att enkelt spåra hur dessa mätvärden förändras över tiden.
Det här blogginlägget kommer att utforska de olika mätvärdena som presenteras i HAProxy SCUMM-instrumentpanelen.
Utforska HAProxy Dashboard i ClusterControl
Alla Prometheus- och SCUMM-instrumentpaneler är inaktiverade som standard i ClusterControl. Men att distribuera dem för ett givet kluster är bara en fråga om ett klick. Om du övervakar flera kluster med ClusterControl kan du återanvända samma Prometheus-instans för varje kluster.
När den har implementerats kan du komma åt HAProxy-instrumentpanelen. Låt oss ta en titt på den information som finns tillgänglig i instrumentpanelen:
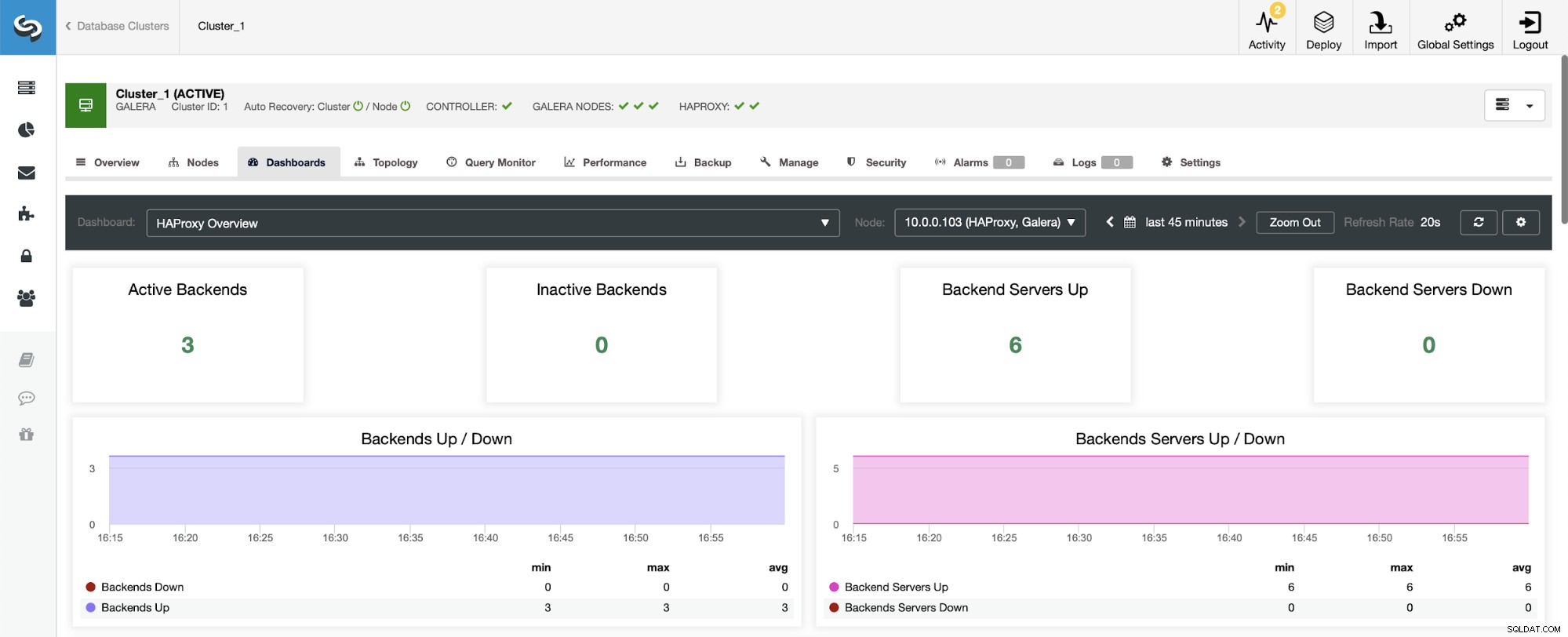
Det första du ser när du navigerar till HAProxy-instrumentpanelen är information om tillståndet för dina backends. Observera här att vad du ser kan bero på klustertypen och hur du har distribuerat HAProxy. I det här fallet distribuerade vi ett Galera-kluster och HAProxy distribuerades på ett round-robin-sätt. Därför ser du tre backends för läsning och tre för skrivning - sex totalt. Det är också därför du ser alla backends markerade som "Upp."
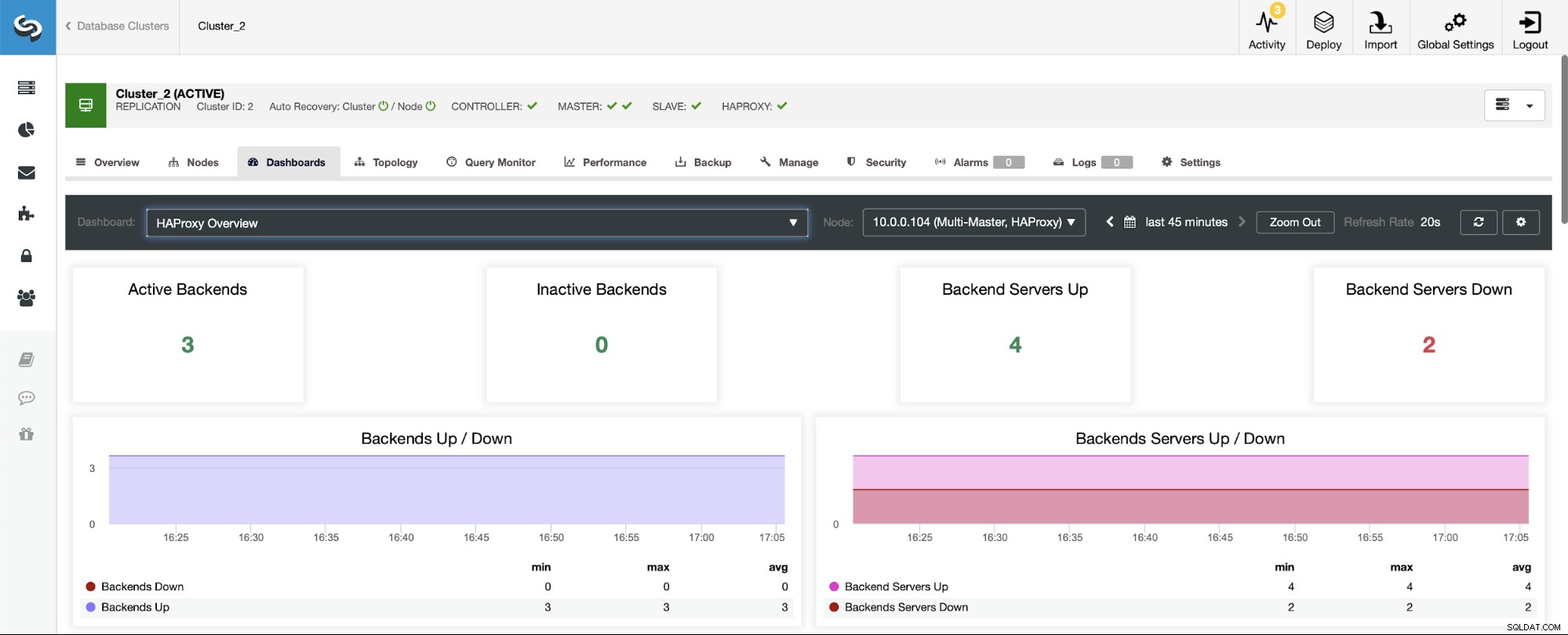
I ett scenario med ett replikeringskluster kommer saker och ting att se annorlunda ut eftersom HAProxy kommer att distribueras i en läs/skrivdelning, och skripten kommer att hålla bara en värd (master) igång i skribentens backend.
Obs, det är därför du nedan ser två backend-servrar markerade som "Ner":
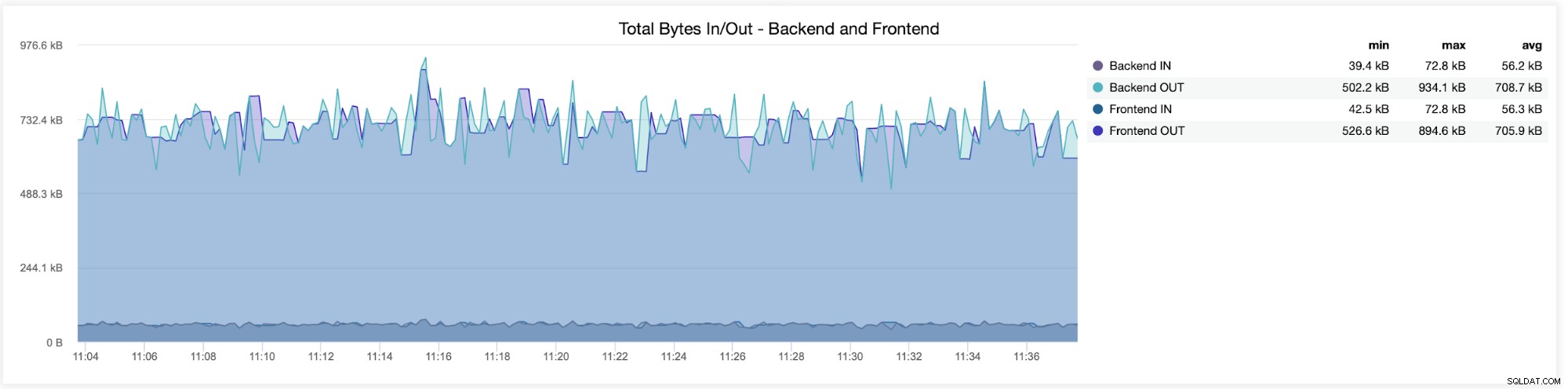
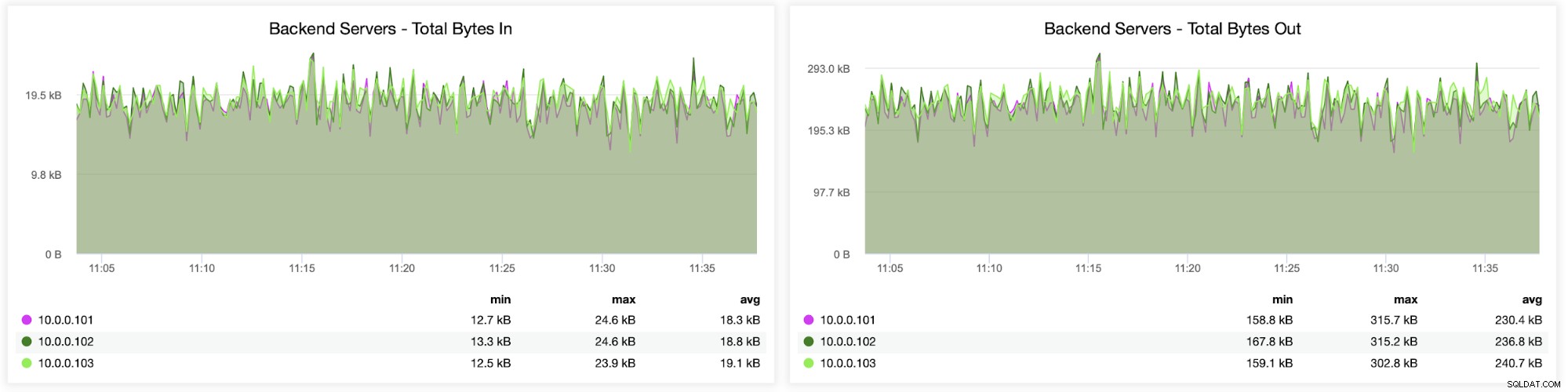
I följande diagram kommer du att se data som skickas och tas emot av båda backend (från HAProxy till databasservrarna) och frontend (mellan HAProxy och klientvärdar):
Du kan också kontrollera trafikfördelningen mellan backends i din HAProxy-konfiguration. I det här fallet har vi två backends, och frågorna skickas via port 3308, som fungerar som round-robin accesspunkt till vårt Galera-kluster:
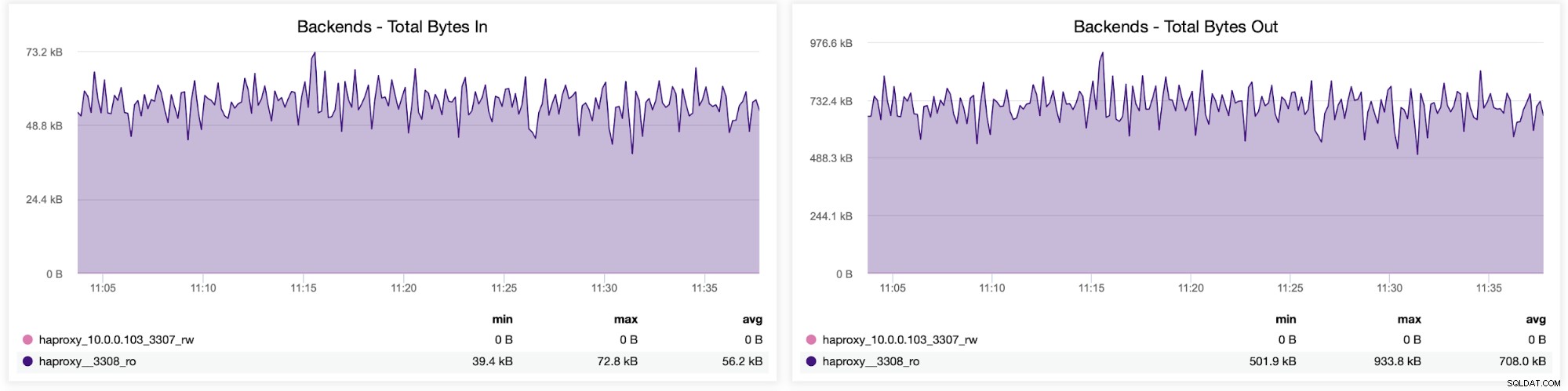
Närnäst kan du se hur trafiken fördelades över alla backend-servrar. I det här scenariot – på grund av round-robin åtkomstmönstret – fördelades data mer eller mindre jämnt över alla tre backend Galera-servrarna:
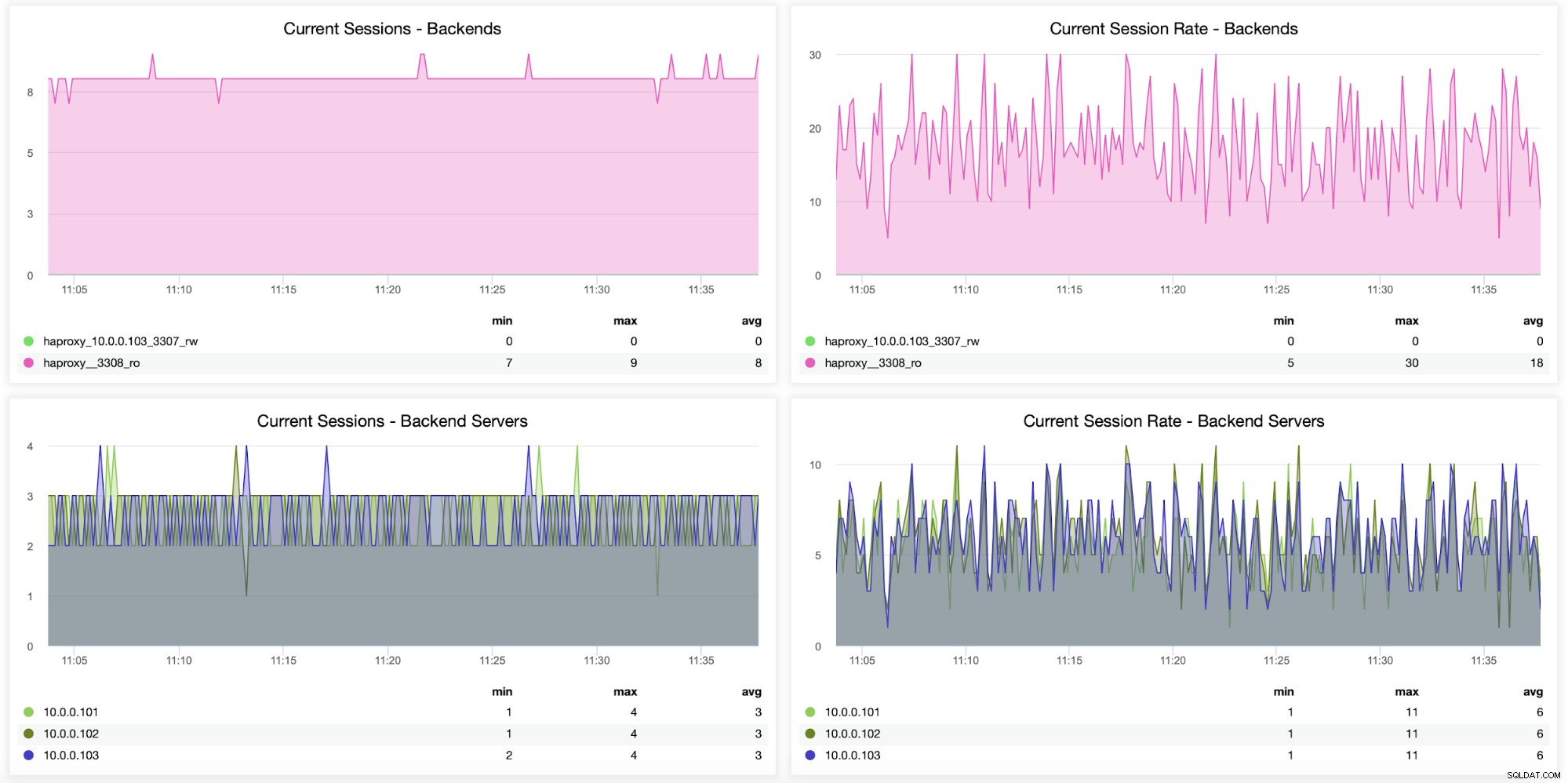
Information om sessioner, inklusive hur många sessioner som öppnades från HAProxy till backend servrar, kan också övervakas, som visas i följande graf. Du kan också spåra hur många gånger per sekund en ny session öppnades för backend och hur dessa mätvärden ser ut per backend-server.
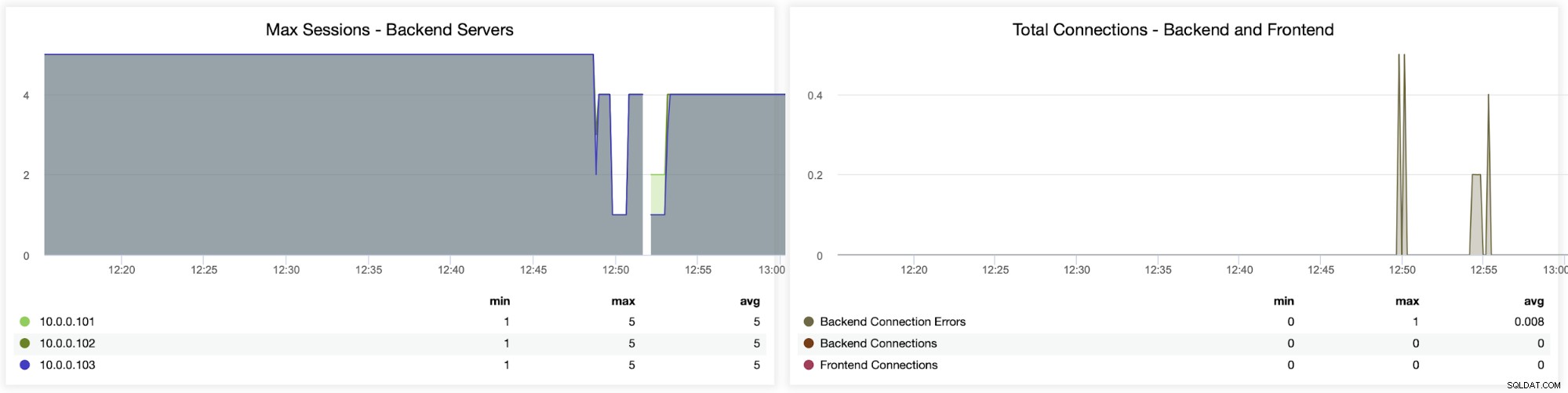
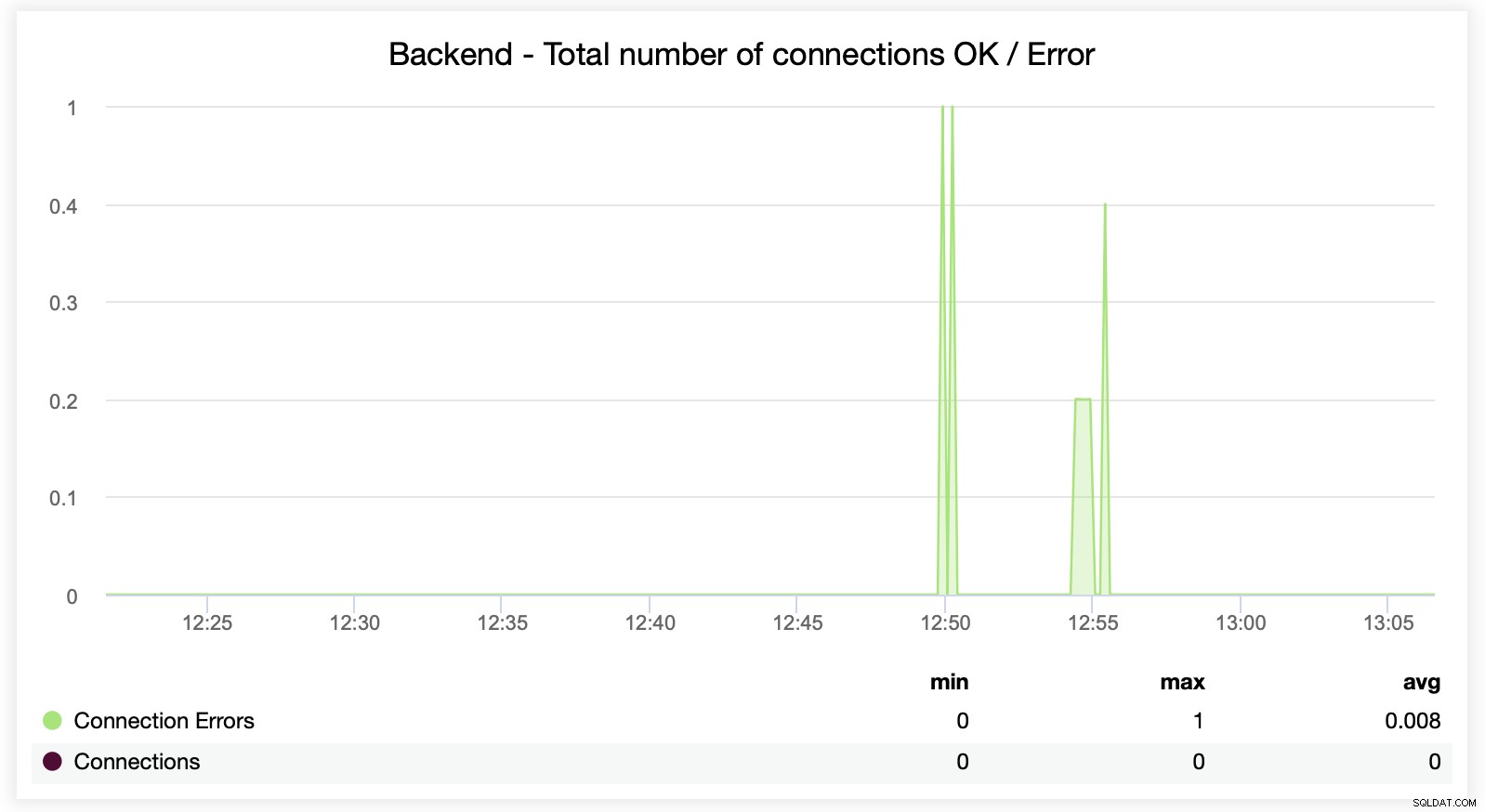
Följande två diagram visar det maximala antalet sessioner per backend-server och när anslutningsproblem uppstod. Detta kan vara ganska användbart för felsökningsändamål där du träffar ett konfigurationsfel på din HAProxy-instans och anslutningarna börjar tappa.
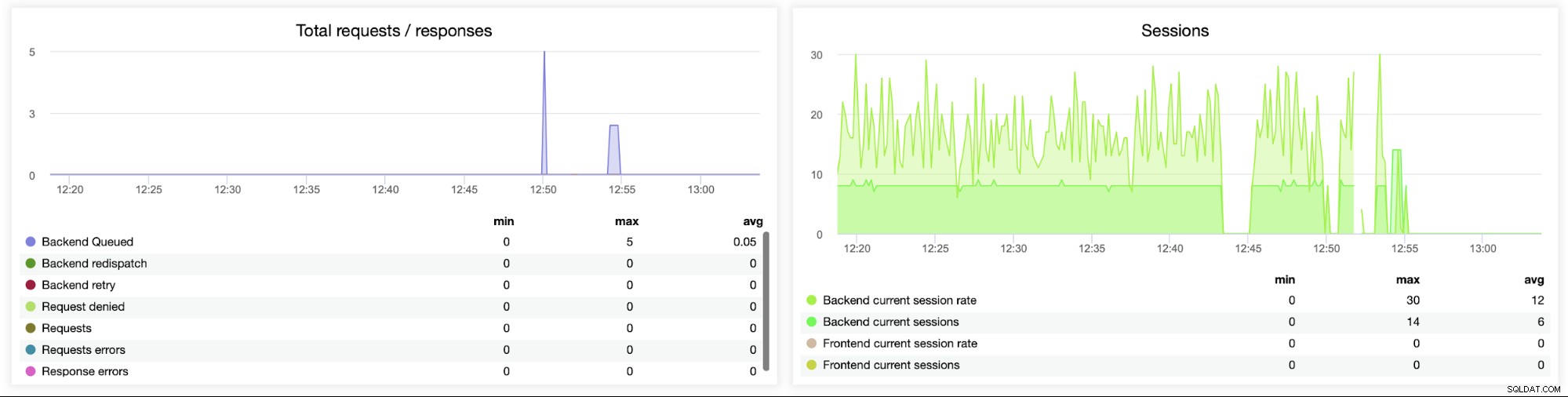
Denna nästa graf är potentiellt mer värdefull eftersom den visar olika mätvärden relaterade till fel hantering, såsom fel, begärandefel, återförsök på backend-sidan, etc. Det finns också en "Sessions"-graf som visar en översikt över sessionsstatistiken.
Här kan du se att ClusterControl spårar anslutningsfelen i realtid, vilket kan hjälpa till att fastställa den exakta tidpunkten när problemen började utvecklas.
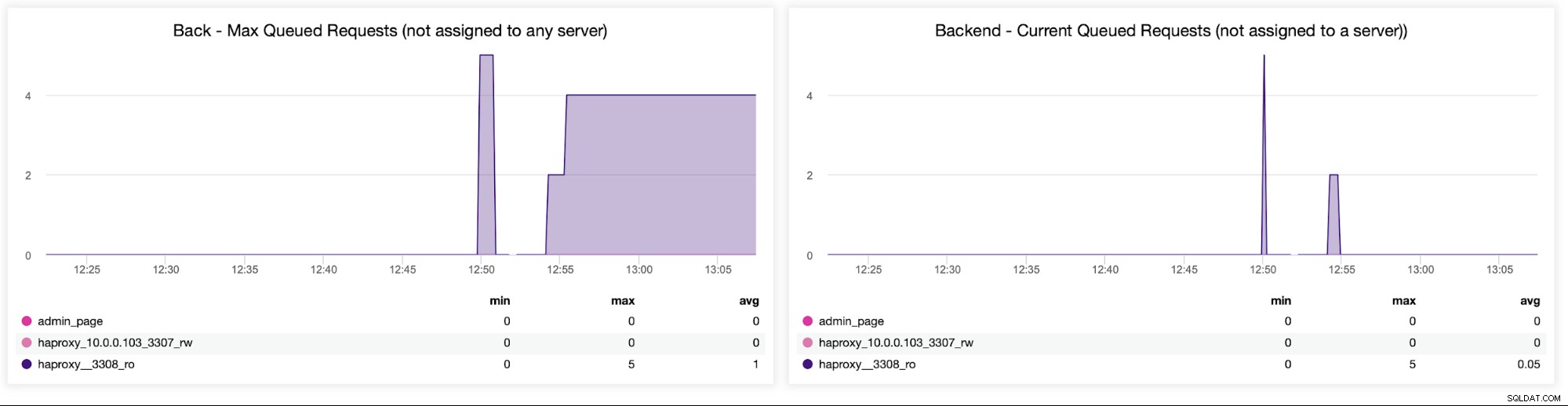
Sistligen ska vi titta på följande två diagram relaterade till förfrågningar i kö . HAProxy köar förfrågningar till backend om backend-servrarna är övermättade. Detta kan till exempel peka på de överbelastade databasservrarna, som inte kan hantera mer trafik.
Avsluta
Att distribuera och övervaka din HAProxy-lastbalanserare i ClusterControl kan hjälpa till att göra det enkelt att hantera och övervaka dina anslutningar. Att ha tydlig insyn i prestanda för dina backends, trafikdistribution, sessionsstatistik, anslutningsfel och antalet förfrågningar i kö kan hjälpa till att säkerställa tillgängligheten och skalbarheten för alla databasinställningar.
ClusterControl gör det enkelt att installera och övervaka lastbalanserare för alla databaskonfigurationer. Använder du inte ClusterControl ännu? Om du själv vill se hur enkelt det är att distribuera och övervaka din HAProxy-lastbalanserare med ClusterControl, bjuder vi in dig till en gratis 30-dagars testversion av plattformen, utan begränsningar. För en mer detaljerad genomgång av varför och hur man använder HAProxy för lastbalansering, kolla in vår handledning om MySQL Load Balancing med HAProxy.