Dina ansvarsområden som DBA (eller DBCC CHECKDB . Du kan komma en bit dit genom att skapa en enkel underhållsplan med en "Kontrollera databasintegritetsuppgift" – men i mina ögon är detta bara att markera en kryssruta.
Om du tittar närmare så finns det väldigt lite du kan göra för att kontrollera hur uppgiften fungerar. Till och med den ganska vidsträckta panelen Egenskaper avslöjar en hel del inställningar för underplanen för underhåll, men praktiskt taget ingenting om DBCC kommandon kommer den att köras. Personligen tycker jag att du borde ta ett mycket mer proaktivt och kontrollerat förhållningssätt till hur du utför din CHECKDB operationer i produktionsmiljöer, genom att skapa dina egna jobb och manuellt skapa din DBCC kommandon. Du kan skräddarsy ditt schema eller själva kommandona till olika databaser – till exempel är ASP.NET-medlemskapsdatabasen förmodligen inte lika avgörande som din försäljningsdatabas och kan tolerera mindre frekventa och/eller mindre noggranna kontroller.
Men för dina viktiga databaser tänkte jag att jag skulle sätta ihop ett inlägg för att detaljera några av de saker jag skulle undersöka för att minimera störningen DBCC kommandon kan orsaka – och vilka myter och marknadsföringshopp du bör vara försiktig med. Och jag vill tacka Paul "Mr. DBCC" Randal (@PaulRandal) för att han tillhandahållit värdefull input – inte bara till detta specifika inlägg, utan också de oändliga råd han ger på sin blogg, #sqlhelp och i SQLskills Immersion-träning.
Vänligen ta alla dessa idéer med en nypa salt och gör ditt bästa för att utföra adekvata tester i din miljö – alla dessa förslag kommer inte att ge bättre prestanda i alla miljöer. Men du är skyldig dig själv, dina användare och dina intressenter att åtminstone överväga effekten av din CHECKDB operationer kan ha och vidta åtgärder för att mildra dessa effekter där det är möjligt – utan att införa onödiga risker genom att inte kontrollera rätt saker.
Minska bruset och konsumera alla fel
Oavsett var du kör CHECKDB , använd alltid WITH NO_INFOMSGS alternativ. Detta undertrycker helt enkelt all irrelevant utdata som bara berättar hur många rader det finns i varje tabell; om du är intresserad av den informationen kan du få den från enkla frågor mot DMV och inte medan DBCC är igång. Att undertrycka utdata gör det mycket mindre sannolikt att du missar ett kritiskt meddelande begravt i all den glada produktionen.
På samma sätt bör du alltid använda WITH ALL_ERRORMSGS alternativet, men speciellt om du kör SQL Server 2008 RTM eller SQL Server 2005 (i dessa fall kan du se listan med fel per objekt trunkerad till 200). För alla CHECKDB andra operationer än snabba ad-hoc-kontroller, bör du överväga att styra utdata till en fil. Management Studio är begränsad till 1000 rader utdata från DBCC CHECKDB , så du kan gå miste om några fel om du överskrider denna siffra.
Även om det inte strikt är ett prestandaproblem, kommer användningen av dessa alternativ att förhindra att du behöver köra processen igen. Detta är särskilt viktigt om du är mitt uppe i en katastrofåterställning.
Ladda bort logiska kontroller där det är möjligt
I de flesta fall CHECKDB ägnar större delen av sin tid åt att utföra logiska kontroller av data. Om du har möjlighet att utföra dessa kontroller på en sann kopia av data kan du fokusera dina ansträngningar på den fysiska strukturen av dina produktionssystem och använda den sekundära servern för att hantera alla logiska kontroller och lindra den belastningen från den primära. Av sekundär server , jag menar bara följande:
- Platsen där du testar dina fullständiga återställningar – eftersom du testar dina återställningar, eller hur?
Andra personer (särskilt den gigantiska marknadsföringskraften som är Microsoft) kan ha övertygat dig om att andra former av sekundära servrar är lämpliga för DBCC kontroller. Till exempel:
- en AlwaysOn Availability Group läsbar sekundär;
- en ögonblicksbild av en speglad databas;
- en logg som skickas sekundär;
- SAN-spegling;
- eller andra varianter...
Tyvärr är detta inte fallet, och ingen av dessa sekundärer är giltiga, pålitliga platser för att utföra dina kontroller som ett alternativ till den primära. Endast en en-till-en-säkerhetskopia kan fungera som en sann kopia; allt annat som förlitar sig på saker som tillämpningen av loggsäkerhetskopior för att komma till ett konsekvent tillstånd kommer inte att på ett tillförlitligt sätt återspegla integritetsproblem på den primära.
Så i stället för att försöka ladda ner dina logiska kontroller till en sekundär och aldrig utföra dem på den primära, föreslår jag det här:
- Se till att du ofta testar återställningen av dina fullständiga säkerhetskopior. Och nej, detta inkluderar inte
COPY_ONLYsäkerhetskopior från en AG-sekundär, av samma skäl som ovan – det skulle bara vara giltigt i det fall du just har initierat sekundären med en fullständig återställning. - Kör
DBCC CHECKDBofta mot de fulla återställa, innan du gör något annat. Återigen, uppspelning av loggposter vid denna tidpunkt kommer att ogiltigförklara denna databas som en sann kopia av källan. - Kör
DBCC CHECKDBmot din primära, kanske uppdelad på sätt som Paul Randal föreslår, och/eller på ett mindre frekvent schema, och/eller medPHYSICAL_ONLYoftare än sällan. Detta kan bero på hur ofta och tillförlitligt du presterar (2). - Anta aldrig att det räcker med kontroller mot det sekundära. Även med en exakt kopia av din primära databas finns det fortfarande fysiska problem som kan uppstå på I/O-undersystemet i din primära databas som aldrig kommer att spridas till den sekundära.
- Analysera alltid
DBCCproduktion. Att bara köra det och ignorera det, för att bocka av det i någon lista, är lika användbart som att köra säkerhetskopior och göra anspråk på framgång utan att någonsin testa att du faktiskt kan återställa den säkerhetskopian när det behövs.
Experimentera med spårningsflaggor 2549, 2562 och 2566
Jag har gjort några grundliga tester av två spårningsflaggor (2549 och 2562) och har funnit att de kan ge betydande prestandaförbättringar, men Lonny rapporterar att de inte längre är nödvändiga eller användbara. Om du är på 2016 eller senare hoppar du över hela det här avsnittet . Om du använder en äldre version beskrivs dessa två spårningsflaggor mycket mer detaljerat i KB #2634571, men i princip:
- Spårningsflagga 2549
- Detta optimerar checkdb-processen genom att behandla varje enskild databasfil som att den finns på en unik underliggande disk. Detta är okej att använda om din databas har en enda datafil, eller om du vet att varje databasfil faktiskt finns på en separat enhet. Om din databas har flera filer och de delar en enda, direkt ansluten spindel bör du vara försiktig med denna spårningsflagga, eftersom den kan göra mer skada än nytta.
VIKTIGT :sql.sasquatch rapporterar en regression i detta spårningsflagga beteende i SQL Server 2014.
- Detta optimerar checkdb-processen genom att behandla varje enskild databasfil som att den finns på en unik underliggande disk. Detta är okej att använda om din databas har en enda datafil, eller om du vet att varje databasfil faktiskt finns på en separat enhet. Om din databas har flera filer och de delar en enda, direkt ansluten spindel bör du vara försiktig med denna spårningsflagga, eftersom den kan göra mer skada än nytta.
- Spårningsflagga 2562
- Denna flagga behandlar hela checkdb-processen som en enda batch, till priset av högre tempdb-användning (upp till 5 % av databasstorleken).
- Använder en bättre algoritm för att avgöra hur man läser sidor från databasen, vilket minskar spärrkonflikt (specifikt för
DBCC_MULTIOBJECT_SCANNER). Observera att denna specifika förbättring finns i SQL Server 2012-kodsökvägen, så du kommer att dra nytta av den även utan spårningsflaggan. Detta kan undvika fel som:
Timeout inträffade i väntan på låsning:klass 'DBCC_MULTIOBJECT_SCANNER'.
- Ovanstående två spårningsflaggor finns i följande versioner:
- SQL Server 2008 Service Pack 2 kumulativ uppdatering 9+
(10.00.4330 -> 10.00.5499)SQL Server 2008 Service Pack 3 kumulativ uppdatering 4+
(10.00.5775+)SQL Server 2008 R2 RTM kumulativ uppdatering 11+
(10.50.1809 -> 10.50.2424)SQL Server 2008 R2 Service Pack 1 kumulativ uppdatering 4+
(10.50.2796 -> 10.50.3999)SQL Server 2008 R2 Service Pack 2
(10.50.4000+)SQL Server 2012, alla versioner
(11.00.2100+) - Spårningsflagga 2566
- Om du fortfarande använder SQL Server 2005, försöker denna spårningsflagga, som introducerades 2005 SP2 CU#9 (9.00.3282) (men inte dokumenterad i den kumulativa uppdateringens Knowledge Base-artikel, KB #953752), att korrigera dålig prestanda av
DATA_PURITYkontrollerar x64-baserade system. Vid ett tillfälle kunde du se mer detaljer i KB #945770, men det verkar som att artikeln har rensats från både Microsofts supportsajt och WayBack-maskinen. Denna spårningsflagga borde inte vara nödvändig i modernare versioner av SQL Server, eftersom problemet i frågeprocessorn har åtgärdats.
- Om du fortfarande använder SQL Server 2005, försöker denna spårningsflagga, som introducerades 2005 SP2 CU#9 (9.00.3282) (men inte dokumenterad i den kumulativa uppdateringens Knowledge Base-artikel, KB #953752), att korrigera dålig prestanda av
Om du ska använda någon av dessa spårningsflaggor rekommenderar jag starkt att du ställer in dem på sessionsnivå med DBCC TRACEON snarare än som en startspårningsflagga. Det gör inte bara att du kan stänga av dem utan att behöva cykla SQL Server, utan det låter dig också implementera dem endast när du utför vissa CHECKDB kommandon, i motsats till operationer som använder någon typ av reparation.
Minska I/O-effekten:optimera tempdb
DBCC CHECKDB kan ha stor användning av tempdb, så se till att du planerar för resursutnyttjande där. Detta brukar vara en bra sak att göra i alla fall. För CHECKDB du kommer att vilja allokera utrymme till tempdb; det sista du vill ha är CHECKDB framsteg (och alla andra samtidiga operationer) för att behöva vänta på en autotillväxt. Du kan få en idé om krav genom att använda WITH ESTIMATEONLY , som Paul förklarar här. Tänk bara på att uppskattningen kan vara ganska låg på grund av en bugg i SQL Server 2008 R2. Om du använder spårningsflagga 2562 måste du också ta hänsyn till de ytterligare utrymmeskraven.
Och naturligtvis är alla typiska råd för att optimera tempdb på nästan alla system lämpliga här också:se till att tempdb har sin egen uppsättning snabb spindlar, se till att den är dimensionerad för att rymma all annan samtidig aktivitet utan att behöva växa, se till att du använder ett optimalt antal datafiler, etc. Några andra resurser du kan tänka på:
- Optimera tempdb-prestanda (MSDN)
- Kapacitetsplanering för tempdb (MSDN)
- En SQL Server DBA-myt om dagen:(12/30) tempdb bör alltid ha en datafil per processorkärna
Minska I/O-effekten:styr ögonblicksbilden
För att köra CHECKDB , kommer moderna versioner av SQL Server att försöka skapa en dold ögonblicksbild av din databas på samma enhet (eller på alla enheter om dina datafiler sträcker sig över flera enheter). Du kan inte kontrollera den här mekanismen, men om du vill kontrollera var CHECKDB fungerar, skapa din egen ögonblicksbild först (Enterprise Edition krävs) på vilken enhet du vill och kör DBCC kommando mot ögonblicksbilden. I båda fallen vill du köra den här operationen under en relativ driftstopp, för att minimera kopiera-på-skriv-aktiviteten som kommer att gå igenom ögonblicksbilden. Och du vill inte att det här schemat ska komma i konflikt med några tunga skrivoperationer, som indexunderhåll eller ETL.
Du kanske har sett förslag för att tvinga fram CHECKDB för att köra i offlineläge med WITH TABLOCK alternativ. Jag avråder starkt från detta tillvägagångssätt. Om din databas används aktivt kommer användarna bara att bli frustrerade om du väljer det här alternativet. Och om databasen inte används aktivt, sparar du inget diskutrymme genom att undvika en ögonblicksbild, eftersom det inte finns någon kopiera-på-skriv-aktivitet att lagra.
Minska I/O-påverkan:undvik 665/1450/1452-fel
I vissa fall kan du se något av följande fel:
Operativsystemet returnerade fel 1450 (Otillräckliga systemresurser finns för att slutföra den begärda tjänsten.) till SQL Server under en skrivning med offset 0x[...] i filen med handtag 0x[...]. Detta är vanligtvis ett tillfälligt tillstånd och SQL Server kommer att fortsätta att försöka igen. Om tillståndet kvarstår måste omedelbara åtgärder vidtas för att rätta till det.
Operativsystemet returnerade fel 665 (den begärda operationen kunde inte slutföras på grund av en filsystembegränsning) till SQL Server under en skrivning vid offset 0x[...] i filen '[fil]'
Det finns några tips här för att minska risken för dessa fel under CHECKDB operationer och minska deras påverkan i allmänhet – med flera tillgängliga korrigeringar, beroende på ditt operativsystem och SQL Server-version:
- Sparse File Errors:1450 eller 665 på grund av filfragmentering:Fixar och lösningar
- SQL Server rapporterar operativsystemfel 1450 eller 1452 eller 665 (försök igen)
Minska CPU-påverkan
DBCC CHECKDB är flertrådad som standard (men bara i Enterprise Edition). Om ditt system är CPU-bundet, eller om du bara vill ha CHECKDB för att använda mindre CPU till priset av att köras längre, kan du överväga att minska parallelliteten på ett par olika sätt:
- Använd Resource Governor på 2008 och senare, så länge du kör Enterprise Edition. För att rikta in bara DBCC-kommandon för en viss resurspool eller arbetsbelastningsgrupp måste du skriva en klassificeringsfunktion som kan identifiera de sessioner som kommer att utföra detta arbete (t.ex. en specifik inloggning eller ett jobb_id).
- Använd spårningsflagga 2528 för att stänga av parallellism för
DBCC CHECKDB(samtCHECKFILEGROUPochCHECKTABLE). Spårningsflaggan 2528 beskrivs här. Naturligtvis är detta endast giltigt i Enterprise Edition, för trots vad Books Online säger för närvarande, är sanningen attCHECKDBgår inte parallellt i Standard Edition. - Medan
DBCCkommandot i sig stöder inteMAXDOP(åtminstone före SQL Server 2014 SP2), den respekterar den globala inställningenmax degree of parallelism. Förmodligen inte något jag skulle göra i produktionen om jag inte hade några andra alternativ, men detta är ett övergripande sätt att kontrollera vissaDBCCkommandon om du inte kan rikta in dem mer explicit.
Vi hade bett om bättre kontroll över antalet processorer som DBCC CHECKDB använder, men de hade upprepade gånger nekats fram till SQL Server 2014 SP2. Så du kan nu lägga till WITH MAXDOP = n till kommandot.
Mina resultat
Jag ville demonstrera några av dessa tekniker i en miljö som jag kunde kontrollera. Jag installerade AdventureWorks2012 och utökade det sedan med AW-förstoringsskriptet skrivet av Jonathan Kehayias (blogg | @SQLPoolBoy), vilket utökade databasen till cirka 7 GB. Sedan körde jag en serie CHECKDB kommandon mot det och tidsbestämda dem. Jag använde en vanlig vanilj DBCC CHECKDB på egen hand, sedan används alla andra kommandon WITH NO_INFOMSGS, ALL_ERRORMSGS . Sedan fyra tester med (a) inga spårningsflaggor, (b) 2549, (c) 2562 och (d) både 2549 och 2562. Sedan upprepade jag de fyra testerna, men la till PHYSICAL_ONLY alternativet, som kringgår alla logiska kontroller. Resultaten (i genomsnitt över 10 testkörningar) är talande:
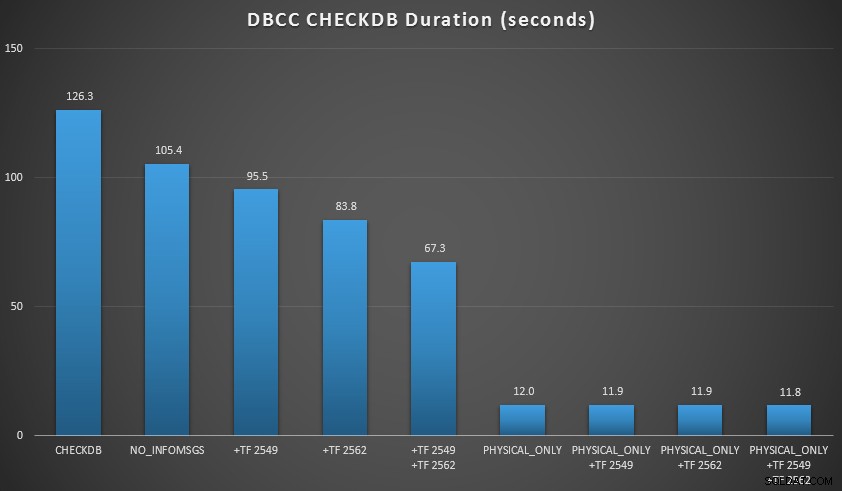
CHECKDB-resultat mot 7 GB databas
Sedan utökade jag databasen ytterligare, gjorde många kopior av de två förstorade tabellerna, vilket ledde till en databasstorlek strax norr om 70 GB, och körde testerna igen. Resultaten, återigen i genomsnitt över 10 testkörningar:
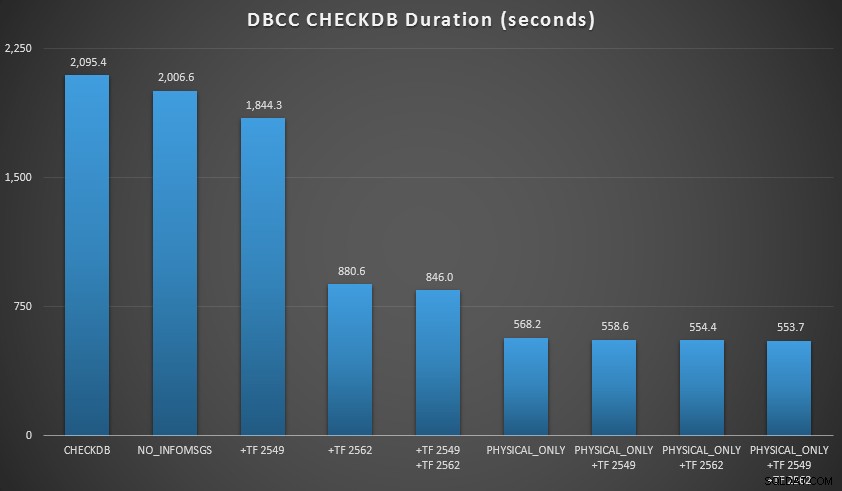
CHECKDB-resultat mot 70 GB databas
I dessa två scenarier har jag lärt mig följande (igen, med tanke på att din körsträcka kan variera och att du måste utföra dina egna tester för att dra några meningsfulla slutsatser):
- När jag måste utföra logiska kontroller:
- Vid små databasstorlekar används
NO_INFOMSGSoption kan minska bearbetningstiden avsevärt när kontrollerna körs i SSMS. På större databaser minskar dock denna fördel, eftersom tiden och arbetet som läggs ner på att vidarebefordra informationen blir en så obetydlig del av den totala varaktigheten. 21 sekunder av 2 minuter är betydande; 88 sekunder av 35 minuter, inte så mycket. - De två spårningsflaggor jag testade hade en betydande inverkan på prestandan – vilket motsvarar en körtidsminskning på 40-60 % när båda användes tillsammans.
- Vid små databasstorlekar används
- När jag kan skicka logiska kontroller till en sekundär server (igen, förutsatt att jag utför logiska kontroller någon annanstans mot en sann kopia ):
- Jag kan minska bearbetningstiden på min primära instans med 70-90 % jämfört med en standard
CHECKDBringa utan alternativ. - I mitt scenario hade spårningsflaggorna mycket liten inverkan på varaktigheten när
PHYSICAL_ONLYutfördes kontroller.
- Jag kan minska bearbetningstiden på min primära instans med 70-90 % jämfört med en standard
Naturligtvis, och jag kan inte nog understryka detta, är det här relativt små databaser och endast används för att jag ska kunna utföra upprepade, uppmätta tester inom rimlig tid. Den här servern hade 80 logiska processorer och 128 GB RAM, och jag var den enda användaren. Varaktighet och interaktion med andra arbetsbelastningar på systemet kan skeva dessa resultat en hel del. Här är en snabb glimt av typisk CPU-användning, med SQL Sentry, under en av CHECKDB operationer (och inget av alternativen ändrade verkligen den övergripande effekten på CPU, bara varaktigheten):
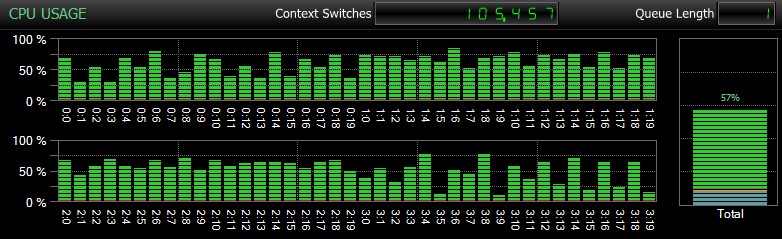
CPU-påverkan under CHECKDB – exempelläge
Och här är en annan vy som visar liknande CPU-profiler för tre olika exempel CHECKDB operationer i historiskt läge (jag har lagt över en beskrivning av de tre testerna som samplats i detta intervall):
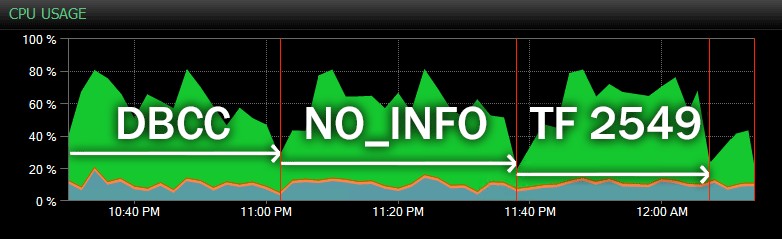
CPU-påverkan under CHECKDB – historiskt läge
På ännu större databaser, som finns på mer trafikerade servrar, kan du se olika effekter, och din körsträcka kommer troligen att variera. Så vänligen utför din due diligence och testa dessa alternativ och spårningsflaggor under en typisk samtidig arbetsbelastning innan du bestämmer dig för hur du vill närma dig CHECKDB .
Slutsats
DBCC CHECKDB är en mycket viktig men ofta undervärderad del av ditt ansvar som DBA eller arkitekt, och avgörande för skyddet av ditt företags data. Ta inte lätt på detta ansvar och gör ditt bästa för att säkerställa att du inte offra något i syfte att minska påverkan på dina produktionsinstanser. Viktigast av allt:se bortom marknadsföringsdatabladen för att vara säker på att du till fullo förstår hur giltiga dessa löften är och om du är villig att satsa ditt företags data på dem. Att snåla med vissa kontroller eller att lasta av dem till ogiltiga sekundära platser kan vara en katastrof som väntar på att hända.
Du bör också överväga att läsa dessa PSS-artiklar:
- En snabbare CHECKDB – Del I
- En snabbare CHECKDB – Del II
- En snabbare CHECKDB – Del III
- En snabbare CHECKDB – Del IV (SQL CLR UDT)
Och det här inlägget från Brent Ozar:
- Tre sätt att köra DBCC CHECKDB snabbare
Slutligen, om du har en olöst fråga om DBCC CHECKDB , lägg upp det till #sqlhelp hash-taggen på twitter. Paul kontrollerar den taggen ofta och eftersom hans bild borde visas i huvudartikeln i Books Online, är det troligt att om någon kan svara på det, så kan han det. Om det är för komplext för 140 tecken kan du fråga här (och jag ska se till att Paul ser det någon gång), eller skicka inlägg på en forumsajt som Database Administrators Stack Exchange.