Förra månaden täckte jag en Special Islands-utmaning. Uppgiften var att identifiera aktivitetsperioder för varje tjänst-ID och tolerera ett gap på upp till ett antal inmatade sekunder (@allowedgap ). Förbehållet var att lösningen måste vara kompatibel före 2012, så du kunde inte använda funktioner som LAG och LEAD, eller samla fönsterfunktioner med en ram. Jag fick ett antal mycket intressanta lösningar publicerade i kommentarerna av Toby Ovod-Everett, Peter Larsson och Kamil Kosno. Se till att gå igenom deras lösningar eftersom de alla är ganska kreativa.
Märkligt nog gick ett antal av lösningarna långsammare med det rekommenderade indexet än utan det. I den här artikeln föreslår jag en förklaring till detta.
Även om alla lösningar var intressanta, ville jag här fokusera på lösningen av Kamil Kosno, som är en ETL-utvecklare hos Zopa. I sin lösning använde Kamil en mycket kreativ teknik för att efterlikna LAG och LEAD utan LAG och LEAD. Du kommer förmodligen att hitta tekniken praktisk om du behöver utföra LAG/LEAD-liknande beräkningar med kod som är kompatibel före 2012.
Varför är vissa lösningar snabbare utan det rekommenderade indexet?
Som en påminnelse föreslog jag att du använder följande index för att stödja lösningarna på utmaningen:
SKAPA INDEX idx_sid_ltm_lid PÅ dbo.EventLog(serviceid, logtime, logid);
Min före 2012-kompatibla lösning var följande:
DECLARE @allowedgap AS INT =66; -- i sekunder MED C1 AS( SELECT logid, serviceid, logtime AS s, -- important, 's'> 'e', för senare beställning DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog),C2 AS( SELECT logid, serviceid, logtime, eventtype, counteach, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth FROM C1 UNPIVOT(loggtid FÖR händelsetyp IN (s, e)) AS U),C3 AS( SELECT serviceid, eventtype, logtime, (ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 SOM grp FRÅN C2 CROSS APPLY (VÄRDEN(CASE WHEN eventtype ='s' THEN counteach - (countboth - counteach) WHEN eventtype ='e' THEN (countboth - counteach) - counteach END ) ) AS A(countactive) WHERE ( eventtype ='s' OCH countactive =1) ELLER (händelsetyp ='e' OCH countactive =0))SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtimeFROM C3 PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) SOM P;
Figur 1 har planen för min lösning med det rekommenderade indexet på plats.
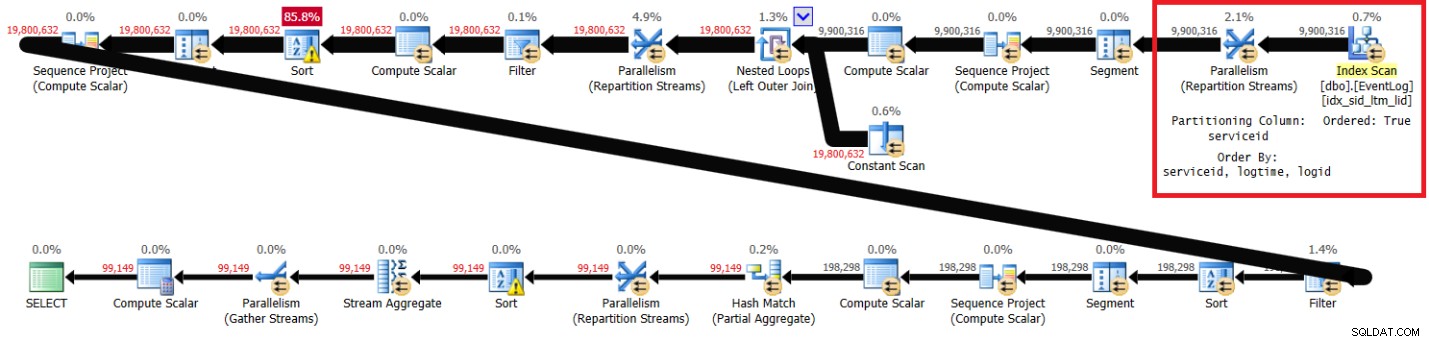 Figur 1:Planera för Itziks lösning med rekommenderat index
Figur 1:Planera för Itziks lösning med rekommenderat index
Lägg märke till att planen skannar det rekommenderade indexet i nyckelordning (Ordered property is True), partitionerar strömmarna efter serviceid med hjälp av ett orderbevarande utbyte och tillämpar sedan den initiala beräkningen av radnummer baserat på indexordning utan behov av sortering. Följande är prestandastatistiken som jag fick för den här frågans körning på min bärbara dator (förfluten tid, CPU-tid och högsta väntetid uttryckt i sekunder):
förfluten:43, CPU:60, logiska läsvärden:144 120 , väntan högst:CXPACKET:166
Jag tappade sedan det rekommenderade indexet och körde om lösningen:
SLÄPP INDEX idx_sid_ltm_lid PÅ dbo.EventLog;
Jag fick planen som visas i figur 2.
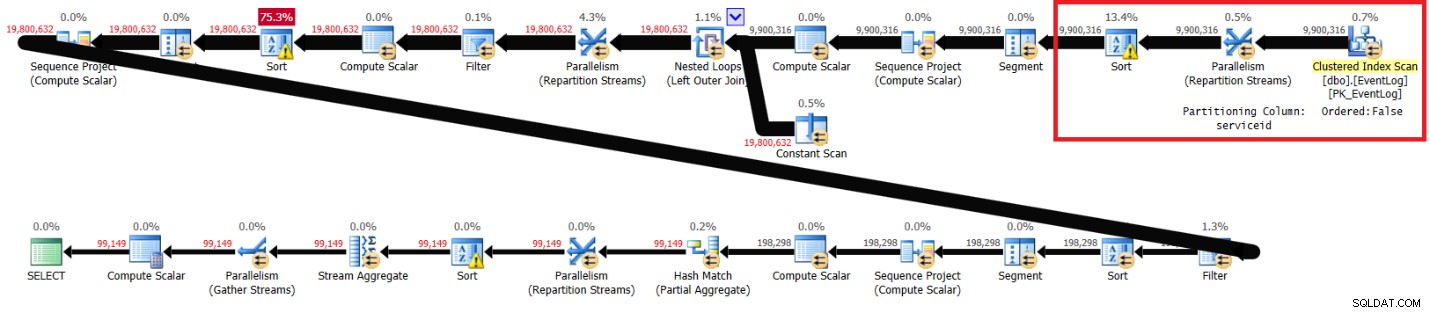 Figur 2:Planera för Itziks lösning utan rekommenderat index
Figur 2:Planera för Itziks lösning utan rekommenderat index
De markerade avsnitten i de två planerna visar skillnaden. Planen utan det rekommenderade indexet utför en oordnad skanning av det klustrade indexet, partitionerar strömmarna efter serviceid med hjälp av ett icke-orderbevarande utbyte och sorterar sedan raderna som fönsterfunktionen behöver (efter serviceid, logtime, logid). Resten av arbetet verkar vara detsamma i båda planerna. Du skulle kunna tro att planen utan det rekommenderade indexet borde vara långsammare eftersom den har en extra sort som den andra planen inte har. Men här är prestandastatistiken som jag fick för den här planen på min bärbara dator:
förfluten:31, CPU:89, logiska läsningar:172 598 , CXPACKET-väntningar:84
Det är mer CPU-tid involverad, vilket delvis beror på den extra sorten; det finns mer I/O inblandade, förmodligen på grund av ytterligare sorteringsspill; den förflutna tiden är dock cirka 30 procent snabbare. Vad skulle kunna förklara detta? Ett sätt att försöka ta reda på detta är att köra frågan i SSMS med alternativet Live Query Statistics aktiverat. När jag gjorde detta slutade operatören längst till höger parallellism (Repartition Streams) på 6 sekunder utan det rekommenderade indexet och på 35 sekunder med det rekommenderade indexet. Den viktigaste skillnaden är att den förra får data förbeställda från ett index och är en orderbevarande börs. Den senare får informationen oordnad och är inte en orderbevarande utbyte. Orderbevarande börser tenderar att vara dyrare än icke-orderbevarande börser. Dessutom, åtminstone i den högra delen av planen fram till den första sorteringen, levererar den förra raderna i samma ordning som utbytespartitioneringskolumnen, så att du inte får alla trådar att verkligen bearbeta raderna parallellt. Den senare levererar raderna oordnade, så du får alla trådar att bearbeta rader verkligen parallellt. Du kan se att den översta väntan i båda planerna är CXPACKET, men i det förra fallet är väntetiden dubbelt så lång som i det senare, vilket säger dig att parallellismhantering i det senare fallet är mer optimal. Det kan vara några andra faktorer som spelar in som jag inte tänker på. Om du har ytterligare idéer som kan förklara den överraskande prestandaskillnaden, vänligen dela.
På min bärbara dator resulterade detta i att exekveringen utan att det rekommenderade indexet var snabbare än det med det rekommenderade indexet. Ändå, på en annan testmaskin var det tvärtom. När allt kommer omkring har du en extra sort, med spillpotential.
Av nyfikenhet testade jag en seriell exekvering (med alternativet MAXDOP 1) med det rekommenderade indexet på plats och fick följande prestandastatistik på min bärbara dator:
förfluten:42, CPU:40, logiska läsningar:143 519
Som du kan se liknar körtiden körtiden för parallellkörningen med det rekommenderade indexet på plats. Jag har bara 4 logiska processorer i min bärbara dator. Självklart kan din körsträcka variera med olika hårdvara. Poängen är att det är värt att testa olika alternativ, inklusive med och utan indexering som du skulle tro att det borde hjälpa. Resultaten är ibland överraskande och kontraintuitiva.
Kamils lösning
Jag var verkligen fascinerad av Kamils lösning och gillade särskilt hur han emulerade LAG och LEAD med en teknik som var kompatibel före 2012.
Här är koden som implementerar det första steget i lösningen:
SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_timeFROM dbo.EventLog;
Denna kod genererar följande utdata (visar endast data för serviceid 1):
serviceid loggtid sluttid starttid---------- -------------------- ---------- ---- -------1 2018-09-12 08:00:00 1 01 2018-09-12 08:01:01 2 11 2018-09-12 08:01:59 3 21 2018-09-12 08 :03:00 4 31 2018-09-12 08:05:00 5 41 2018-09-12 08:06:02 6 5...
Det här steget beräknar två radnummer som är ett från varandra för varje rad, uppdelade av serviceid och ordnade efter logtid. Det aktuella radnumret representerar sluttiden (kalla det sluttid), och det aktuella radnumret minus ett representerar starttiden (kalla det starttid).
Följande kod implementerar det andra steget i lösningen:
MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FROM RNS UNPIVOT(radnummer FÖR time_type IN (start_time, end_time)) AS U;
Detta steg genererar följande utdata:
serviceid logtime rownum time_type---------- -------------------- ------- ------ -----1 2018-09-12 08:00:00 0 start_time1 2018-09-12 08:00:00 1 sluttid1 2018-09-12 08:01:01 1 start_time1 2018-09-12 08:0 :01 2 sluttid1 2018-09-12 08:01:59 2 starttid1 2018-09-12 08:01:59 3 sluttid1 2018-09-12 08:03:00 3 starttid1 2018-08-09:00 4 sluttid1 2018-09-12 08:05:00 4 starttid1 2018-09-12 08:05:00 5 sluttid1 2018-09-12 08:06:02 5 starttid1 2018-09-6_12:00 slut ...
Det här steget avpivoterar varje rad i två rader, och duplicerar varje loggpost – en gång för tidstyp start_time och en annan för end_time. Som du kan se, förutom de lägsta och högsta radnumren, visas varje radnummer två gånger – en gång med loggtiden för den aktuella händelsen (start_tid) och en annan med loggtiden för föregående händelse (sluttid).
Följande kod implementerar det tredje steget i lösningen:
MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT * FRÅN RNS UNPIVOT(radnummer FÖR tid_typ IN (starttid, sluttid)) AS U PIVOT(MAX(loggtid) FÖR tid_typ IN(starttid, sluttid)) SOM P;
Denna kod genererar följande utdata:
serviceid rownum start_time end_time -------------------- ------------ --------------- ----------------------------------1 0 2018-09-12 08 :00:00 NULL1 1 2018-09-12 08:01:01 2018-09-12 08:00:001 2 2018-09-12 08:01:59 2018-09-12 08:01:2018 - 09-12 08:03:00 2018-09-12 08:01:591 4 2018-09-12 08:05:00 2018-09-12 08:03:001 5 2018-09-12 08:0 2018-09-12 08:05:001 6 NULL 2018-09-12 08:06:02...
Det här steget pivoterar data, grupperar par av rader med samma radnummer och returnerar en kolumn för den aktuella händelseloggtiden (start_tid) och en annan för föregående händelseloggtid (sluttid). Denna del emulerar effektivt en LAG-funktion.
Följande kod implementerar det fjärde steget i lösningen:
DECLARE @allowedgap AS INT =66; MED RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog)SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grpFROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time)) AS U PIVOT( MAX(loggtid) FÖR time_type IN(start_tid, sluttid)) SOM PWHERE ISNULL(DATEDIFF(andra, sluttid, starttid), @allowedgap + 1)> @allowedgap;
Denna kod genererar följande utdata:
serviceid rownum start_time end_time start_time_grp end_time_grp--------- ------- -------------------- ---- ---------------- -------------------- --------------------1 0 2018-09- 12 08:00:00 NULL 1 01 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 11 6 NULL 2018-09-12 08:06:02 3 2... /pre>Detta steg filtrerar par där skillnaden mellan föregående sluttid och aktuell starttid är större än det tillåtna gapet och rader med endast en händelse. Nu måste du koppla varje aktuell rads starttid med nästa rads sluttid. Detta kräver en LEAD-liknande beräkning. För att uppnå detta skapar koden, återigen, radnummer som är ett ifrån varandra, bara den här gången representerar det aktuella radnumret starttiden (start_time_grp ) och det aktuella radnumret minus ett representerar sluttiden (end_time_grp).
Precis som tidigare är nästa steg (nummer 5) att öppna raderna. Här är koden som implementerar detta steg:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY service-ID ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Ranges as ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(loggtid) FÖR time_type IN(start_time, end_time)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT *FROM Ranges UNPIVOT(grp FOR grp_type IN(start_tid_grp, slut_tid_grp)) AS U;Utdata:
serviceid rownum start_time end_time grp grp_type---------------- ------- -------------------- ---- ---------------- ---- ---------------1 0 2018-09-12 08:00:00 NULL 0 end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 1 end_time_grp1 0 2018-09-12 08:00:00 NULL 1 start_time_grp1 6 NULL 9-2018-08:end_time_grp1 4 2018-09-12 08:05:00 2018-09-12 08:03:00 2 start_time_grp1 6 NULL 2018-09-12 08:06:02 3 start_time_grp...Som du kan se är grp-kolumnen unik för varje ö inom ett tjänst-ID.
Steg 6 är det sista steget i lösningen. Här är koden som implementerar detta steg, som också är den kompletta lösningskoden:
DECLARE @allowedgap AS INT =66; WITH RNS AS( SELECT serviceid, logtime, ROW_NUMBER() OVER(PARTITION BY service-ID ORDER BY logtime) AS end_time, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime) - 1 AS start_time FROM dbo.EventLog),Ranges as ( SELECT serviceid, rownum, start_time, end_time, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) AS start_time_grp, ROW_NUMBER() OVER (ORDER BY serviceid,rownum) -1 AS end_time_grp FROM RNS UNPIVOT(rownum FOR time_type IN (start_time, end_time) ) AS U PIVOT(MAX(loggtid) FÖR time_type IN(start_tid, sluttid)) AS P WHERE ISNULL(DATEDIFF(second, end_time, start_time), @allowedgap + 1)> @allowedgap)SELECT serviceid, MIN(start_time) AS start_time , MAX(end_time) AS end_timeFROM Ranges UNPIVOT(grp FOR grp_type IN(start_time_grp, end_time_grp)) AS UGROUP BY serviceid, grpHAVING (MIN(start_time) IS NOT NULL AND MAX(end_time) IS NOT NULL);Detta steg genererar följande utdata:
serviceid start_time end_time ------------ -------------------------- ------ --------------------1 2018-09-12 08:00:00 2018-09-12 08:03:001 2018-09-12 08:05 :00 2018-09-12 08:06:02...Det här steget grupperar raderna efter serviceid och grp, filtrerar endast relevanta grupper och returnerar den lägsta starttiden som början av ön och den maximala sluttiden som slutet av ön.
Figur 3 har planen som jag fick för den här lösningen med det rekommenderade indexet på plats:
SKAPA INDEX idx_sid_ltm_lid PÅ dbo.EventLog(serviceid, logtime, logid);Planera med rekommenderat index i figur 3.
Figur 3:Planera för Kamils lösning med rekommenderat index
Här är prestandastatistiken som jag fick för den här körningen på min bärbara dator:
förfluten:44, CPU:66, logiska läsningar:72979, topp väntan:CXPACKET:148Jag tappade sedan det rekommenderade indexet och körde om lösningen:
SLÄPP INDEX idx_sid_ltm_lid PÅ dbo.EventLog;Jag fick planen som visas i figur 4 för utförandet utan det rekommenderade indexet.
Figur 4:Planera för Kamils lösning utan rekommenderat index
Här är prestandastatistiken som jag fick för den här körningen:
förfluten:30, CPU:85, logiska läsningar:94813, väntan överst:CXPACKET:70Körtiderna, CPU-tiderna och CXPACKET-väntetiderna är mycket lika min lösning, även om de logiska läsningarna är lägre. Kamils lösning går också snabbare på min bärbara dator utan det rekommenderade indexet, och det verkar som om det beror på liknande skäl.
Slutsats
Anomalier är bra. De gör dig nyfiken och får dig att gå och undersöka grundorsaken till problemet och som ett resultat lära dig nya saker. Det är intressant att se att vissa frågor, på vissa maskiner, körs snabbare utan den rekommenderade indexeringen.
Tack igen till Toby, Peter och Kamil för era lösningar. I den här artikeln täckte jag upp Kamils lösning, med hans kreativa teknik för att efterlikna LAG och LEAD med radnummer, unpivoting och pivotering. Du kommer att finna den här tekniken användbar när du behöver LAG- och LEAD-liknande beräkningar som måste stödjas i miljöer före 2012.