Det här inlägget är en del av en serie om radmål. Du hittar de andra delarna här:
- Del 1:Ställa in och identifiera radmål
- Del 2:Semi-anslutningar
- Del 3:Anti Joins
Använd Anti Join med en toppoperatör
Du kommer ofta att se en innersida Top (1) operator i apply anti join genomförandeplaner. Till exempel genom att använda databasen AdventureWorks:
SELECT P.ProductID
FROM Production.Product AS P
WHERE
NOT EXISTS
(
SELECT 1
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = P.ProductID
); Planen visar en topp (1) operatör på insidan av appliceringen (yttre referenser) anti join:
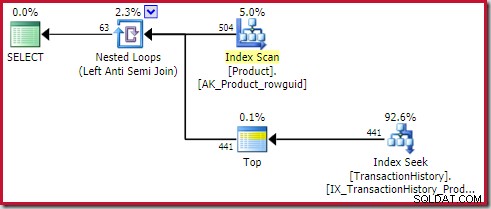
Denna Top-operatör är helt redundant . Det krävs inte för korrekthet, effektivitet eller för att säkerställa att ett radmål är satt.
Operatören för applicering mot sammanfogning slutar leta efter rader på insidan (för aktuell iteration) så snart en rad ses vid sammanfogningen. Det är fullt möjligt att skapa en appliceringsskyddsplan utan toppen. Så varför finns det en toppoperatör i den här planen?
Källa till toppoperatören
För att förstå var denna meningslösa Top-operatör kommer ifrån måste vi följa de viktigaste stegen som togs under sammanställningen och optimeringen av vår exempelfråga.
Som vanligt tolkas frågan först i ett träd. Detta har en logisk "existerar inte"-operator med en underfråga, som i det här fallet stämmer överens med den skrivna formen av frågan:

Underfrågan inte existerar rullas upp i en applicera anti-join:

Detta omvandlas sedan ytterligare till en logisk vänster-anti-semi-join. Det resulterande trädet som skickas till kostnadsbaserad optimering ser ut så här:

Den första utforskningen som den kostnadsbaserade optimeraren utför är att introducera en logisk distinkt operation på den nedre anti-joiningången för att producera unika värden för anti-join-nyckeln. Den allmänna tanken är att istället för att testa dubblerade värden vid sammanfogningen, kan planen dra nytta av att gruppera dessa värden i förväg.
Regeln för ansvarsfull utforskning kallas LASJNtoLASJNonDist (vänster anti semi join till vänster anti semi join på distinkt). Ingen fysisk implementering eller kostnadsberäkning har utförts ännu, så detta är bara optimeraren som utforskar en logisk motsvarighet, baserad på närvaron av dubblett av ProduktID värden. Det nya trädet med grupperingsoperationen tillagd visas nedan:

Nästa logiska transformation som övervägs är att skriva om joinen som en apply . Detta utforskas med hjälp av regeln LASJNtoApply (vänster anti semi join för att ansöka med relationellt urval). Som nämnts tidigare i serien var den tidigare transformationen från applicera till join att möjliggöra transformationer som fungerar specifikt på joins. Det är alltid möjligt att skriva om en anslutning som en ansökan, så detta utökar utbudet av tillgängliga optimeringar.
Nu gör optimeraren inte alltid överväga en tillämpa omskrivning som en del av kostnadsbaserad optimering. Det måste finnas något i det logiska trädet för att göra det värt att trycka samman predikatet nedåt på insidan. Vanligtvis kommer detta att vara förekomsten av ett matchande index, men det finns andra lovande mål. I det här fallet är det den logiska nyckeln på Produkt-ID skapas av den aggregerade operationen.
Resultatet av denna regel är en korrelerad anti-join med markering på insidan:

Därefter överväger optimeraren att flytta det relationella urvalet (det korrelerade sammanfogningspredikatet) längre ner på insidan, förbi det distinkta (grupp för aggregat) som introducerades av optimeraren tidigare. Detta görs enligt regel SelOnGbAgg , som flyttar så mycket av ett urval (predikat) förbi en lämplig grupp efter aggregat som det kan (en del av urvalet kan lämnas kvar). Den här aktiviteten hjälper till att driva val så nära dataåtkomstoperatörerna på bladnivå som möjligt, för att eliminera rader tidigare och göra senare indexmatchning enklare.
I det här fallet finns filtret i samma kolumn som grupperingsoperationen, så omvandlingen är giltig. Det resulterar i att hela urvalet skjuts in under aggregatet:

Den sista operationen av intresse utförs av regeln GbAggToConstScanOrTop . Denna omvandling ser ut att ersätta en grupp efter aggregat med en konstant skanning eller Topp logisk operation. Den här regeln matchar vårt träd eftersom grupperingskolumnen är konstant för varje rad som passerar genom det nedtryckta urvalet. Alla rader har garanterat samma ProduktID . Gruppering på det enda värdet ger alltid en rad. Därför är det giltigt att omvandla aggregatet till en Top (1). Så det är här toppen kommer ifrån.
Implementering och kostnadsberäkning
Optimizern kör nu en serie implementeringsregler för att hitta fysiska operatörer för vart och ett av de lovande logiska alternativen som den hittills har övervägt (lagrade effektivt i en memostruktur). Hash och merge anti-anslutning fysiska alternativ kommer från det ursprungliga trädet med infört aggregat (med tillstånd av regel LASJNtoLASJNonDist kom ihåg). Ansökan behöver lite mer arbete för att bygga en fysisk topp och matcha urvalet med en indexsökning.
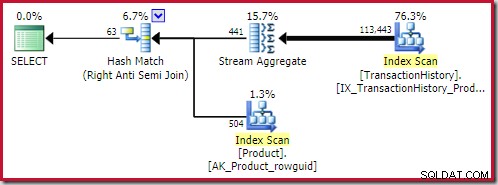
Den bästa hash-anti-join den hittade lösningen kostar 0,362143 enheter:
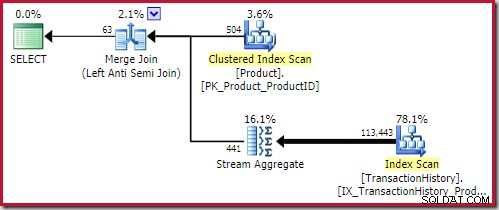
Den bästa sammanslagningsmottagningen lösning kommer in på 0,353479 enheter (något billigare):
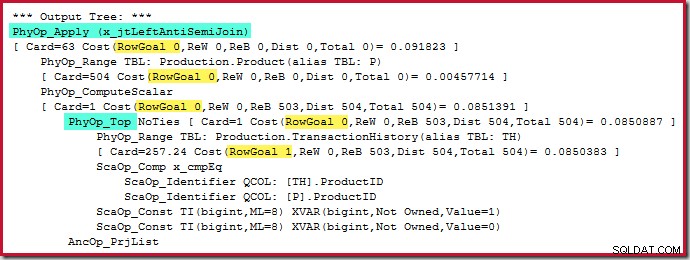
Ansök mot anslutning kostar 0,091823 enheter (billigast med stor marginal):
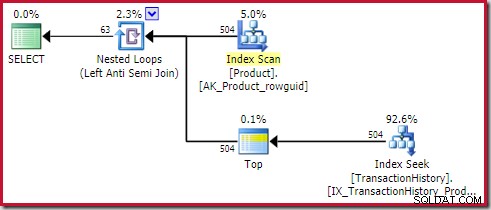
Den skarpsinniga läsaren kan märka att antalet rader på insidan av appliceringsskyddet (504) skiljer sig från föregående skärmdump av samma plan. Detta eftersom detta är en beräknad plan, medan den tidigare planen var efterutförande. När denna plan exekveras, finns endast totalt 441 rader på insidan över alla iterationer. Detta belyser en av visningssvårigheterna med att tillämpa semi/anti-join-planer:Minsta optimeringsuppskattning är en rad, men en semi- eller anti-join kommer alltid att hitta en rad eller inga rader på varje iteration. De 504 raderna som visas ovan representerar 1 rad på var och en av 504 iterationer. För att få siffrorna att stämma överens måste uppskattningen vara 441/504 =0,875 rader varje gång, vilket förmodligen skulle förvirra människor lika mycket.
Hur som helst, planen ovan har "turen" nog att kvalificera sig för ett radmål på insidan av appliceringsskyddet av två skäl:
- Anti-kopplingen omvandlas från en koppling till en applicering i den kostnadsbaserade optimeraren. Detta sätter ett radmål (som fastställts i del tre).
- Top(1)-operatorn anger också ett radmål på sitt underträd.
Själva topoperatorn har inget radmål (från applicera) eftersom radmålet 1 inte skulle vara mindre än den vanliga uppskattningen, som också är 1 rad (Card=1 för PhyOp_Top nedan):
Anti Join Anti Pattern
Följande allmänna planform är en som jag ser som ett antimönster:
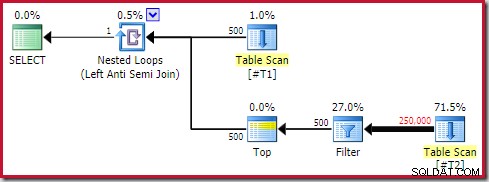
Inte varje utförandeplan som innehåller en appliceringsskyddad sammanfogning med en topp (1) operatör på dess insida kommer att vara problematisk. Ändå är det ett mönster att känna igen och ett som nästan alltid kräver ytterligare utredning.
De fyra huvudelementen att hålla utkik efter är:
- A korrelerade kapslade loopar (tillämpa ) anti join
- En Topp (1) operatören omedelbart på insidan
- Ett betydande antal rader på den yttre ingången (så att den inre sidan kommer att köras många gånger)
- En potentiellt dyr underträd under toppen
"$$$"-underträdet är ett som är potentiellt dyrt vid körning . Detta kan vara svårt att känna igen. Om vi har tur kommer det att finnas något självklart som en hel tabell eller indexskanning. I mer utmanande fall kommer underträdet att se helt oskyldigt ut vid första anblicken, men innehålla något dyrt när man tittar närmare på det. För att ge ett ganska vanligt exempel kan du se en Indexsökning som förväntas returnera ett litet antal rader, men som innehåller ett dyrt restpredikat som testar ett mycket stort antal rader för att hitta de få som kvalificerar sig.
Det föregående AdventureWorks-kodexemplet hade inte ett "potentiellt dyrt" underträd. Indexsökningen (utan kvarvarande predikat) skulle vara en optimal åtkomstmetod oavsett radmålsöverväganden. Detta är en viktig punkt:att ge optimeraren en alltid effektiv dataåtkomstväg på insidan av en korrelerad koppling är alltid en bra idé. Detta är ännu mer sant när appliceringen körs i anti-sammanfogningsläge med en övre (1) operatör på insidan.
Låt oss nu titta på ett exempel som har ganska dyster körtidsprestanda på grund av detta antimönster.
Exempel
Följande skript skapar två temporära tabeller. Den första har 500 rader som innehåller heltal från 1 till 500 inklusive. Den andra tabellen har 500 kopior av varje rad i den första tabellen, för totalt 250 000 rader. Båda tabellerna använder sql_variant datatyp.
DROP TABLE IF EXISTS #T1, #T2;
CREATE TABLE #T1 (c1 sql_variant NOT NULL);
CREATE TABLE #T2 (c1 sql_variant NOT NULL);
-- Numbers 1 to 500 inclusive
-- Stored as sql_variant
INSERT #T1
(c1)
SELECT
CONVERT(sql_variant, SV.number)
FROM master.dbo.spt_values AS SV
WHERE
SV.[type] = N'P'
AND SV.number >= 1
AND SV.number <= 500;
-- 500 copies of each row in table #T1
INSERT #T2
(c1)
SELECT
T1.c1
FROM #T1 AS T1
CROSS JOIN #T1 AS T2;
-- Ensure we have the best statistical information possible
CREATE STATISTICS sc1 ON #T1 (c1) WITH FULLSCAN, MAXDOP = 1;
CREATE STATISTICS sc1 ON #T2 (c1) WITH FULLSCAN, MAXDOP = 1; Prestanda
Vi kör nu en fråga som letar efter rader i den mindre tabellen som inte finns i den större tabellen (naturligtvis finns det inga):
SELECT
T1.c1
FROM #T1 AS T1
WHERE
NOT EXISTS
(
SELECT 1
FROM #T2 AS T2
WHERE T2.c1 = T1.c1
); Den här frågan körs i ungefär 20 sekunder , vilket är fruktansvärt lång tid att jämföra 500 rader med 250 000. Den uppskattade SSMS-planen gör det svårt att se varför prestandan kan vara så dålig:
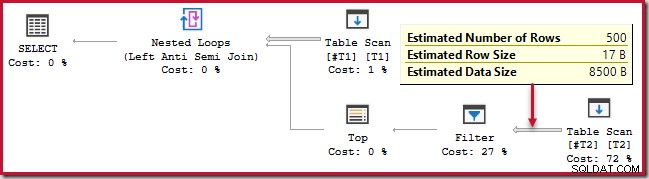
Observatören måste vara medveten om att SSMS uppskattade planer visar inre sidouppskattningar per iteration av den kapslade slinganslutningen. Förvirrande nog visar faktiska SSMS-planer antalet rader över alla iterationer . Plan Explorer utför automatiskt de enkla beräkningarna som krävs för att uppskattade planer också ska visa det totala antalet förväntade rader:
Trots det är körtidsprestandan mycket sämre än beräknat. Utförandeplanen efter genomförandet (faktisk) är:
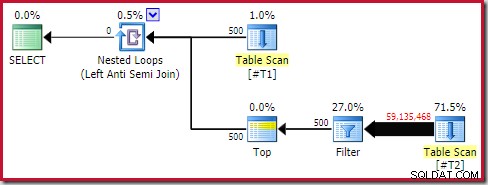
Notera det separata filtret, som normalt skulle tryckas ner i skanningen som ett restpredikat. Detta är anledningen till att använda sql_variant data typ; det förhindrar att predikatet trycks in, vilket gör det stora antalet rader från skanningen lättare att se.
Analys
Orsaken till avvikelsen beror på hur optimeraren uppskattar antalet rader som den kommer att behöva läsa från tabellskanningen för att möta det enradiga målet som ställts in i filtret. Det enkla antagandet är att värden är likformigt fördelade i tabellen, så för att möta 1 av de 500 unika värdena som finns måste SQL Server läsa 250 000 / 500 =500 rader. Över 500 iterationer, det kommer till 250 000 rader.
Optimerarens likformighetsantagande är generellt, men det fungerar inte bra här. Du kan läsa mer om detta i A Row Goal Request av Joe Obbish och rösta på hans förslag på Connect-ersättningsforumet på Use More Than Density to Cost a Scan on the Inner Side of a Nested Loop med TOP.
Min syn på denna specifika aspekt är att optimeraren snabbt bör backa från ett enkelt antagande om enhetlighet när operatören är på insidan av en kapslad slinganslutning (dvs. uppskattade återspolningar plus återbindningar är större än en). Det är en sak att anta att vi behöver läsa 500 rader för att hitta en matchning vid den första iterationen av slingan. Att anta detta vid varje iteration verkar väldigt osannolikt vara korrekt; det betyder att de första 500 raderna som påträffas bör innehålla ett av varje distinkt värde. Det är högst osannolikt att det blir fallet i praktiken.
En serie olyckliga händelser
Oavsett hur återkommande toppoperatörer beräknas, förefaller det mig att hela situationen bör undvikas i första hand . Kom ihåg hur toppen i denna plan skapades:
- Optimeraren introducerade ett distinkt aggregat på insidan som en prestandaoptimering .
- Detta aggregat tillhandahåller per definition en nyckel i sammanfogningskolumnen (det ger unikhet).
- Denna konstruerade nyckel ger ett mål för konverteringen från en koppling till en applikation.
- Predikatet (valet) som är kopplat till appliceringen trycks ned förbi aggregatet.
- Aggregationen fungerar nu garanterat på ett enda distinkt värde per iteration (eftersom det är ett korrelationsvärde).
- Aggregationen ersätts av en Top (1).
Alla dessa transformationer är giltiga individuellt. De är en del av normala optimeringsoperationer eftersom den söker efter en rimlig utförandeplan. Tyvärr är resultatet här att det spekulativa aggregatet som introduceras av optimeraren slutar förvandlas till en Topp (1) med ett tillhörande radmål . Radmålet leder till den felaktiga kostnadsberäkningen baserat på enhetlighetsantagandet och sedan till valet av en plan som är högst osannolikt att prestera bra.
Nu kan man invända att applicera anti-join ändå skulle ha ett radmål – utan transformationssekvensen ovan. Motargumentet är att optimeraren inte skulle överväga omvandling från anti join till apply anti join (ställer in radmålet) utan den optimeringsintroducerade aggregatet som ger LASJNtoApply bestämma något att binda sig till. Dessutom har vi sett (i del tre) att om anti-join hade gått in i kostnadsbaserad optimering som en applicering (istället för en join) skulle det återigen finnas inget radmål .
Kort sagt, radmålet i den slutliga planen är helt artificiellt och har ingen grund i den ursprungliga frågespecifikationen. Problemet med topp- och radmålet är en bieffekt av denna mer grundläggande aspekt.
Lösningar
Det finns många möjliga lösningar på detta problem. Om du tar bort något av stegen i optimeringssekvensen ovan säkerställer du att optimeraren inte producerar en appliceringsförhindrande implementering med dramatiskt (och artificiellt) reducerade kostnader. Förhoppningsvis kommer det här problemet att lösas i SQL Server förr snarare än senare.
Under tiden är mitt råd att se upp för anti join anti-mönstret. Se till att insidan av en appliceringsskyddad koppling alltid har en effektiv åtkomstväg för alla körtidsförhållanden. Om detta inte är möjligt kan du behöva använda tips, inaktivera radmål, använda en planguide eller tvinga fram en frågebutiksplan för att få stabil prestanda från frågor mot anslutning.
Seriesammanfattning
Vi har täckt mycket mark under de fyra omgångarna, så här är en sammanfattning på hög nivå:
- Del 1 – Ställa in och identifiera radmål
- Frågesyntax avgör inte närvaron eller frånvaron av ett radmål.
- Ett radmål ställs bara in när målet är mindre än den vanliga uppskattningen.
- Physical Top-operatorer (inklusive de som introduceras av optimeraren) lägger till ett radmål i sitt underträd.
- En
FASTellerSET ROWCOUNTuttalande sätter ett radmål i grunden för planen. - Semi join och anti join får lägg till ett radmål.
- SQL Server 2017 CU3 lägger till showplan-attributet EstimateRowsWithoutRowGoal för operatörer som påverkas av ett radmål
- Radmålinformation kan avslöjas av odokumenterade spårningsflaggor 8607 och 8612.
- Del 2 – Semi-anslutningar
- Det är inte möjligt att uttrycka en semi-join direkt i T-SQL, så vi använder indirekt syntax t.ex.
IN,EXISTS, ellerINTERSECT. - Dessa syntaxer tolkas i ett träd som innehåller en applicering (korrelerad koppling).
- Optimeraren försöker omvandla applikationen till en vanlig koppling (inte alltid möjligt).
- Hash, sammanfogning och vanliga kapslade slingor, semi-join, anger inte ett radmål.
- Använd halvanslutning sätter alltid ett radmål.
- Apply semi join kan kännas igen genom att ha yttre referenser på den kapslade loops join-operatorn.
- Apply semi join använder inte en Top (1) operator på insidan.
- Del 3 – Anti Joins
- Också tolkad i en ansökan, med ett försök att skriva om det som en koppling (inte alltid möjligt).
- Hash, sammanfogning och vanliga kapslade loopar mot sammanfogning anger inte ett radmål.
- Använd anti-anslutning sätter inte alltid ett radmål.
- Endast kostnadsbaserade optimeringsregler (CBO) som omvandlar anti join till att tillämpas sätter ett radmål.
- Anti-anslutning måste ange CBO som en anslutning (gäller inte). Annars kan inte kopplingen för att tillämpa transformering ske.
- För att ange CBO som en anslutning måste omskrivningen före CBO från ansök till gå med ha lyckats.
- CBO utforskar bara att skriva om en anti-join till en ansökan i lovande fall.
- Pre-CBO-förenklingar kan ses med odokumenterad spårningsflagga 8621.
- Del 4 – Anti Join Anti Pattern
- Optimeraren ställer bara in ett radmål för att tillämpa anti-anslutning där det finns en lovande anledning att göra det.
- Tyvärr lägger flera interagerande optimeringstransformationer till en Top (1)-operator på insidan av en applicerings-anti-join.
- Översta operatorn är redundant; det krävs inte för korrekthet eller effektivitet.
- Toppen sätter alltid ett radmål (till skillnad från applicera, som behöver en bra anledning).
- Det obefogade radmålet kan leda till extremt dåliga resultat.
- Se upp för ett potentiellt dyrt underträd under den konstgjorda toppen (1).