Dataproffs får inte alltid använda databaser som har en optimal design. Ibland är de saker som får dig att gråta saker som vi har gjort mot oss själva, eftersom de verkade vara bra idéer vid den tiden. Ibland beror de på tredjepartsapplikationer. Ibland går de helt enkelt före dig.
Den jag tänker på i det här inlägget är när kolumnen datetime (eller datetime2, eller ännu bättre, datetimeoffset) faktiskt är två kolumner – en för datumet och en för tiden. (Om du har en separat kolumn igen för offset, så ska jag ge dig en kram nästa gång jag ser dig, för du har förmodligen fått ta itu med alla typer av skada.)
Jag gjorde en undersökning på Twitter, och fann att detta är ett mycket verkligt problem som ungefär hälften av er måste ta itu med datum och tid då och då.
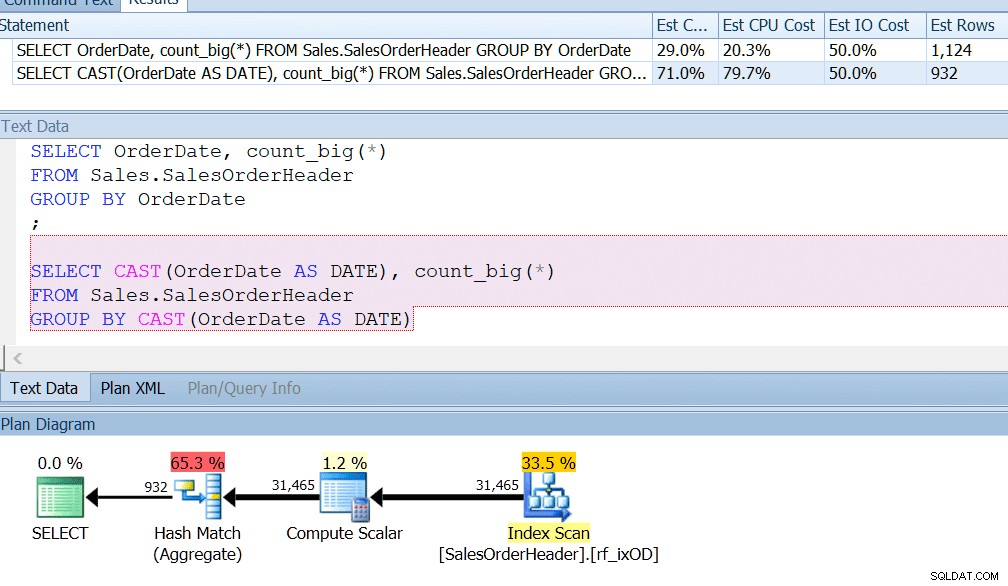
AdventureWorks gör nästan detta – om du tittar i tabellen Sales.SalesOrderHeader ser du en datetime-kolumn som heter OrderDate, som alltid har exakta datum i sig. Jag slår vad om att om du är en rapportutvecklare på AdventureWorks har du förmodligen skrivit frågor som letar efter antalet beställningar på en viss dag, med hjälp av GROUP BY OrderDate eller något liknande. Även om du visste att detta var en datetime-kolumn och det fanns potential för att den också skulle lagra en tid som inte är midnatt, skulle du fortfarande säga GROUP BY OrderDate bara för att använda ett index på rätt sätt. GROUP BY CAST(OrderDate AS DATE) klipper det bara inte.
Jag har ett index på OrderDate, som du skulle göra om du regelbundet frågade den kolumnen, och jag kan se att gruppering efter CAST(OrderDate AS DATE) är ungefär fyra gånger sämre ur ett CPU-perspektiv.
Så jag förstår varför du gärna skulle fråga din kolumn som om det vore ett datum, helt enkelt med vetskapen om att du kommer att ha en värld av smärta om användningen av den kolumnen ändras. Kanske löser du detta genom att ha en begränsning på bordet. Kanske stoppar du bara huvudet i sanden.
Och när någon kommer och säger "Du vet, vi borde lagra den tid som beställningar sker också", ja, du tänker på all kod som antar att OrderDate helt enkelt är ett datum, och räknar med att ha en separat kolumn som heter OrderTime (datatyp tid, snälla) kommer att vara det mest förnuftiga alternativet. Jag förstår. Det är inte idealiskt, men det fungerar utan att gå sönder för mycket saker.
Vid det här laget rekommenderar jag att du också gör OrderDateTime, vilket skulle vara en beräknad kolumn som förenar de två (vilket du bör göra genom att lägga till antalet dagar sedan dag 0 till CAST(OrderDate som datetime2), istället för att försöka lägga till tiden till datum, vilket i allmänhet är mycket rörigare). Och sedan indexera OrderDateTime, för det skulle vara vettigt.
Men ganska ofta kommer du att hitta dig själv med datum och tid som separata kolumner, med i princip ingenting du kan göra åt det. Du kan inte lägga till en beräknad kolumn eftersom det är ett tredjepartsprogram och du vet inte vad som kan gå sönder. Är du säker på att de aldrig gör SELECT *? En dag hoppas jag att de låter oss lägga till kolumner och gömma dem, men för närvarande riskerar du verkligen att gå sönder saker.
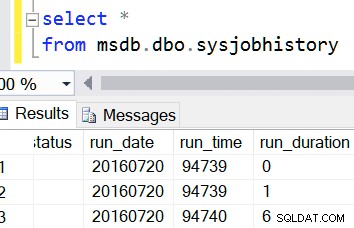
Och du vet, till och med msdb gör detta. De är båda heltal. Och det är på grund av bakåtkompatibilitet, antar jag. Men jag tvivlar på att du överväger att lägga till en beräknad kolumn till en tabell i msdb.
Så hur frågar vi detta? Låt oss anta att vi vill hitta de poster som låg inom ett visst datumintervall?
Låt oss experimentera lite.
Låt oss först skapa en tabell med 3 miljoner rader och indexera kolumnerna vi bryr oss om.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Jag kunde ha gjort det till ett klustrat index, men jag tror att ett icke-klustrat index är mer typiskt för din miljö.)
Våra data ser ut så här, och jag vill hitta rader mellan till exempel 2 augusti 2011 kl. 8:30 och 5 augusti 2011 kl. 21:30.
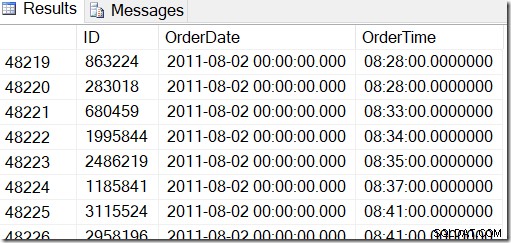
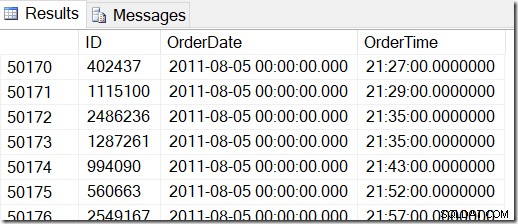
Genom att titta igenom data kan jag se att jag vill ha alla rader mellan 48221 och 50171. Det är 50171-48221+1=1951 rader (+1:an beror på att det är ett inkluderande intervall). Detta hjälper mig att vara säker på att mina resultat är korrekta. Du skulle förmodligen ha liknande på din maskin, men inte exakt, eftersom jag använde slumpmässiga värden när jag genererade min tabell.
Jag vet att jag inte bara kan göra något sånt här:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
…för detta skulle inte inkludera något som hände över natten den 4:e. Detta ger mig 1268 rader – helt klart inte rätt.
Ett alternativ är att kombinera kolumnerna:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Detta ger rätt resultat. Det gör det. Det är bara det att detta är helt icke-sargerbart och ger oss en skanning över alla rader i vår tabell. På våra 3 miljoner rader kan det ta sekunder att köra detta.
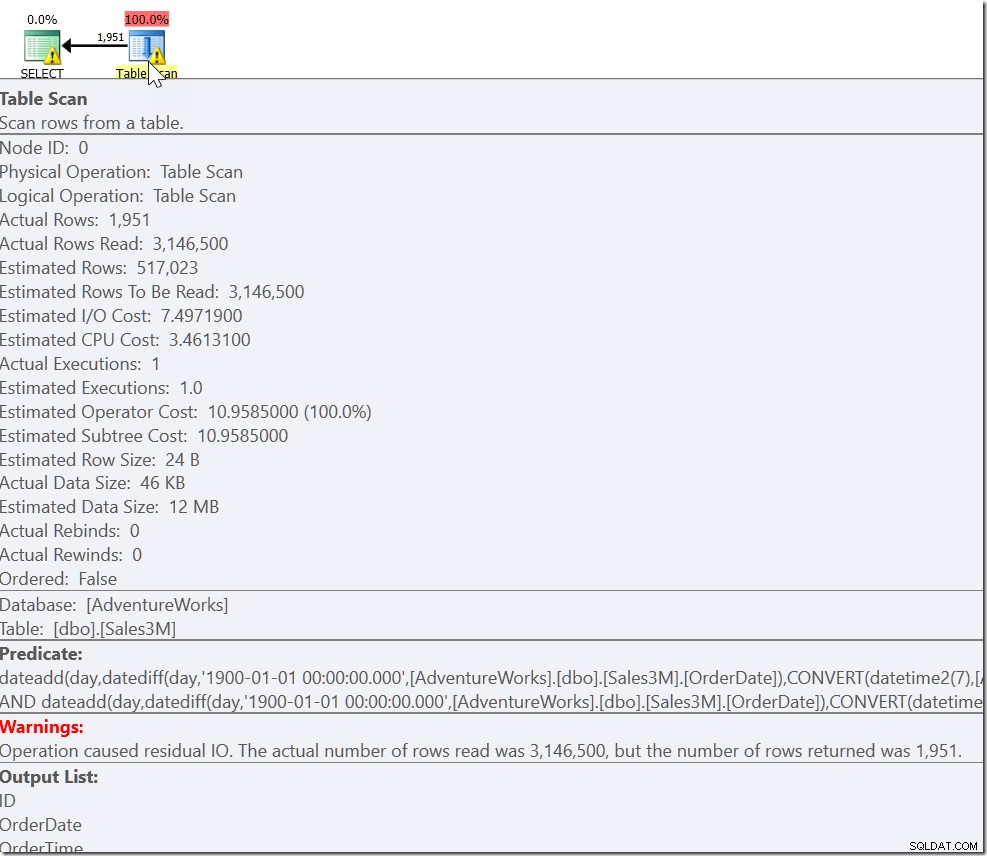
Vårt problem är att vi har ett vanligt fall, och två specialfall. Vi vet att varje rad som uppfyller OrderDate> '20110802' OCH OrderDate <'20110805' är en som vi vill ha. Men vi behöver också varje rad som är på-eller-efter 8:30 på 20110802, och på-eller-före 21:30 på 20110805. Och det leder oss till:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OR är hemskt, jag vet. Det kan också leda till skanningar, men inte nödvändigtvis. Här ser jag tre indexsök, som sammanfogas och sedan kontrolleras för unika. Frågeoptimeraren inser uppenbarligen att den inte bör returnera samma rad två gånger, men inser inte att de tre villkoren utesluter varandra. Och faktiskt, om du gjorde detta på ett intervall inom en enda dag, skulle du få fel resultat.
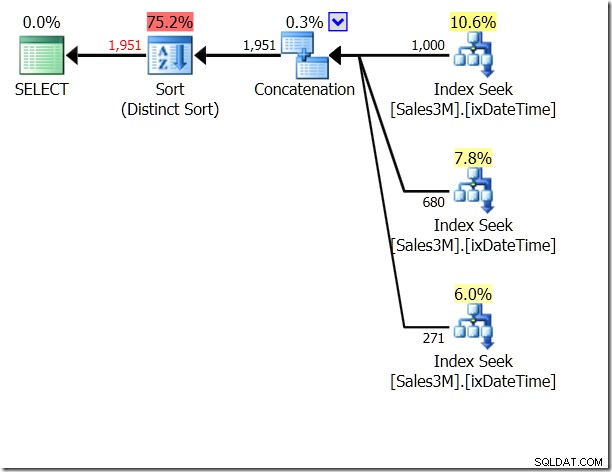
Vi skulle kunna använda UNION ALL på detta, vilket skulle innebära att QO inte skulle bry sig om huruvida villkoren utesluter varandra. Detta ger oss tre sökningar som är sammanlänkade – det är ganska bra.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Men det är fortfarande tre sökningar. Statistik IO säger att det är 20 läsningar på min maskin.

Nu, när jag tänker på sargbarhet, tänker jag inte bara på att undvika att placera indexkolumner i uttryck, jag tänker också på vad som kan hjälpa något att verka sargbar.
Ta WHERE LastName LIKE "Far%" till exempel. När jag tittar på planen för detta ser jag en Seek, med en Seek Predicate letar efter vilket namn som helst från långt upp till (men inte inklusive) FaS. Och så finns det ett restpredikat som kontrollerar LIKE-tillståndet. Detta beror inte på att QO anser att LIKE är sargable. Om det var det skulle det kunna använda LIKE i sökpredikatet. Det är för att det vet att allt som är uppfyllt av det LIKE-villkoret måste vara inom det intervallet.
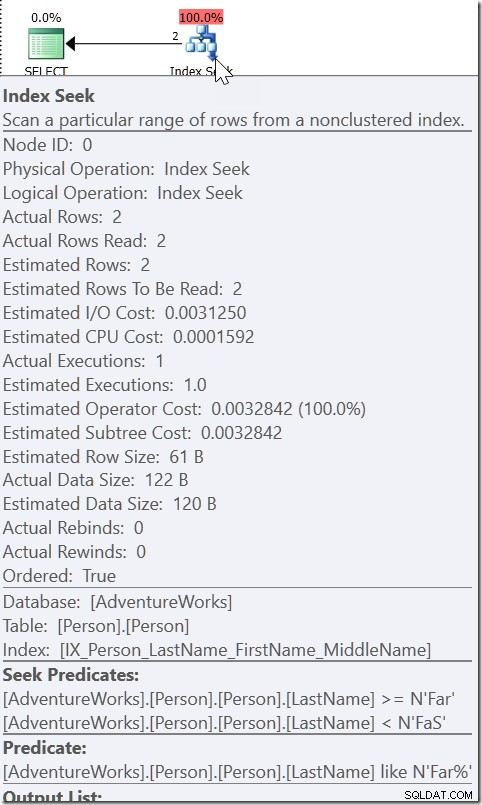
Ta WHERE CAST(OrderDate AS DATE) ='20110805'
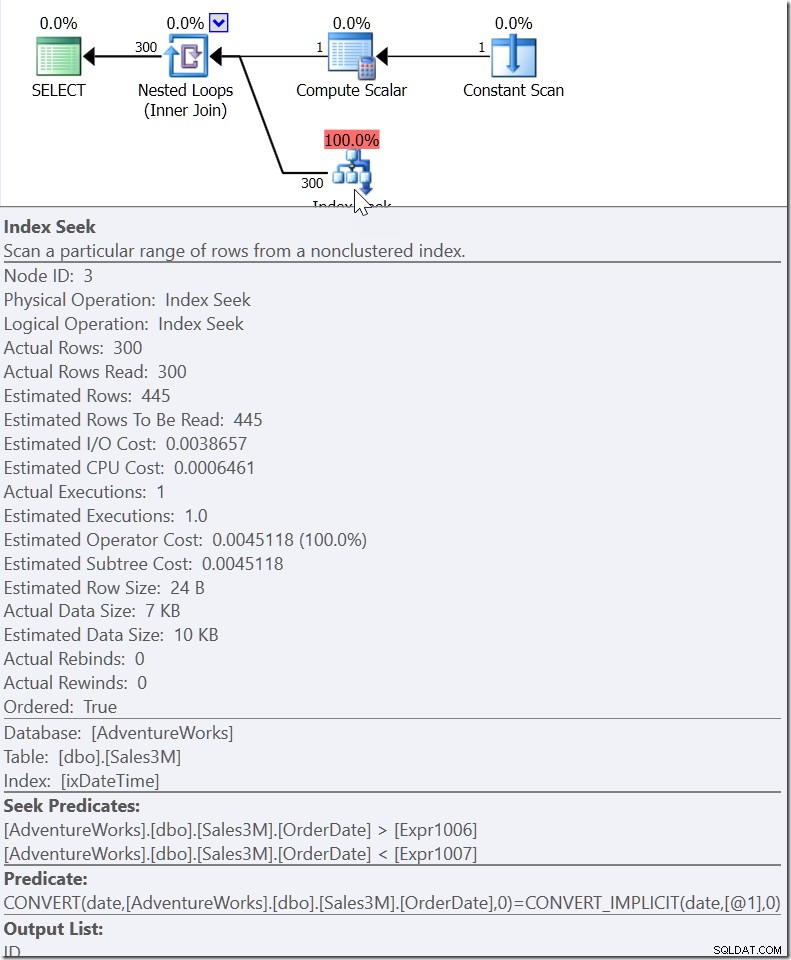
Här ser vi ett Seek Predicate som letar efter OrderDate-värden mellan två värden som har utarbetats någon annanstans i planen, men som skapar ett intervall där de rätta värdena måste finnas. Det här är inte>=20110805 00:00 och <20110806 00:00 (vilket är vad jag skulle ha gjort det), det är något annat. Värdet för början av detta intervall måste vara mindre än 20110805 00:00, eftersom det är>, inte>=. Allt vi egentligen kan säga är att när någon inom Microsoft implementerade hur QO skulle svara på den här typen av predikat, gav de det tillräckligt med information för att komma fram till vad jag kallar ett "hjälparpredikat."
Nu skulle jag älska att Microsoft skulle göra fler funktioner sargable, men just den begäran stängdes långt innan de pensionerade Connect.
Men det jag menar kanske är att de ska göra fler hjälppredikat.
Problemet med hjälppredikat är att de nästan säkert läser fler rader än du vill. Men det är fortfarande mycket bättre än att titta igenom hela indexet.
Jag vet att alla rader jag vill returnera kommer att ha OrderDate mellan 20110802 och 20110805. Det är bara det att det finns några som jag inte vill ha.
Jag kunde bara ta bort dem, och detta skulle vara giltigt:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
Men jag känner att det här är en lösning som kräver en viss tankeansträngning för att komma fram till. Mindre ansträngning från utvecklarens sida är att helt enkelt tillhandahålla ett hjälppredikat till vår korrekta men långsamma version.
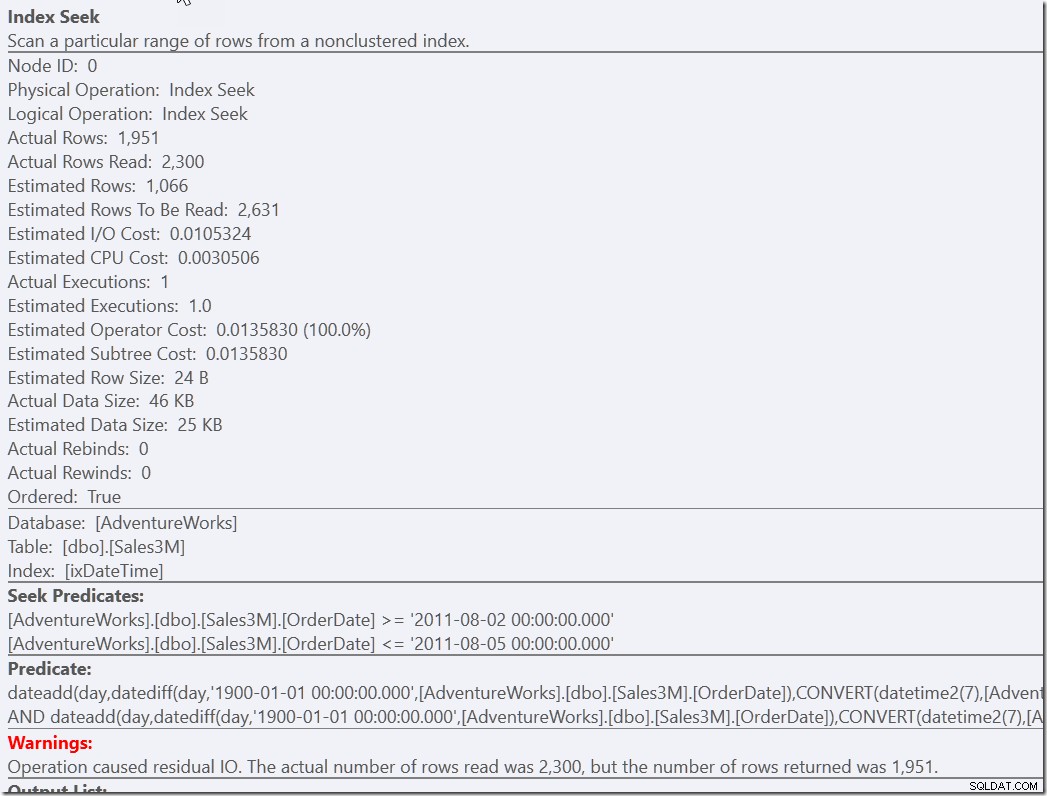
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Båda dessa frågor hittar de 2300 raderna som är på rätt dagar och måste sedan kontrollera alla dessa rader mot de andra predikaten. Den ena måste kontrollera de två NOT-villkoren, den andra måste göra någon typkonvertering och matematik. Men båda är mycket snabbare än vad vi hade tidigare, och gör en enda sökning (13 läsningar). Visst, jag får varningar om en ineffektiv RangeScan, men det här är min preferens framför att göra tre effektiva.
På vissa sätt är det största problemet med det här sista exemplet att någon välmenande person skulle se att hjälparpredikatet var överflödigt och kan ta bort det. Så är fallet med alla hjälppredikat. Så lägg en kommentar.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Om du har något som inte passar in i ett trevligt sargbart predikat, räkna ut ett det vill säga och ta reda på vad du behöver utesluta från det. Du kanske bara kommer på en bättre lösning.
@rob_farley