Att implementera en användarvänlig sökning kan vara knepigt, men det kan också göras mycket effektivt. Hur vet jag detta? För inte så länge sedan behövde jag implementera en sökmotor på en mobilapp. Appen byggdes på Ionic-ramverket och skulle ansluta till en CakePHP 2-backend. Tanken var att visa resultat medan användaren skrev. Det fanns flera alternativ för detta, men alla uppfyllde inte mitt projekts krav.
För att illustrera vad denna typ av uppgift innebär, låt oss föreställa oss att leta efter låtar och deras möjliga relationer (som artister, album, etc).
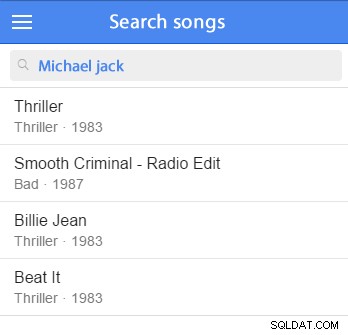
Posterna skulle behöva sorteras efter relevans, vilket skulle bero på om sökordet matchade fält från själva posten eller från andra kolumner i relaterade tabeller. Dessutom bör sökningen implementera åtminstone några grundläggande ordstammar. (Stammen används för att få rotformen för ett ord. "Stamlar", "stammar", "stammar" och "stammar" har alla samma rot:"stam".)
Metoden som presenteras här testades med flera hundra tusen poster och kunde hämta användbara resultat medan användaren skrev.
Fulltextsökprodukter att överväga
Det finns flera sätt vi kan implementera den här typen av sökning. Vårt projekt hade vissa begränsningar i förhållande till tid och serverresurser, så vi var tvungna att hålla lösningen så enkel som möjligt. Ett par utmanare dök så småningom upp:
Elasticsearch
Elasticsearch tillhandahåller fulltextsökningar i en dokumentorienterad tjänst. Den är utformad för att hantera enorma mängder belastning på ett distribuerat sätt:den kan rangordna resultat efter relevans, utföra aggregering och arbeta med ordstammar och synonymer. Detta verktyg är avsett för realtidssökningar. Från deras hemsida:
Elasticsearch bygger distribuerade funktioner ovanpå Apache Lucene för att tillhandahålla de mest kraftfulla fulltextsökningsfunktionerna som finns tillgängliga. Kraftfullt, utvecklarvänligt fråge-API stöder flerspråkig sökning, geolokalisering, kontextuella menade-du-förslag, autokomplettering och resultatutdrag.
Elasticsearch kan fungera som en REST-tjänst, svara på http-förfrågningar, och den kan ställas in mycket snabbt. Men att starta motorn som en tjänst kräver att du har vissa serveråtkomstprivilegier. Och om din värdleverantör inte stöder Elasticsearch direkt måste du installera några paket.
Summan av kardemumman är att den här produkten är ett utmärkt alternativ om du vill ha en stensäker söklösning. (Obs:Du kan behöva en VPS eller dedikerad server eftersom hårdvarukraven är ganska krävande.)
Sfinx
Precis som Elasticsearch tillhandahåller Sphinx också en mycket solid fulltextsökprodukt:Craigslist betjänar mer än 300 000 000 frågor per dag med den. Sphinx tillhandahåller inte ett inbyggt RESTful-gränssnitt. Det är implementerat i C, med ett mindre hårdvaruavtryck än Elasticsearch (som är implementerat i Java och kan köras på alla operativsystem med en jvm). Du behöver också root-åtkomst till servern med lite dedikerat RAM/CPU för att köra Sphinx korrekt.
MySQL fulltextsökning
Historiskt sett stöddes fulltextsökningar i MyISAM-motorer. Efter version 5.6 stödde MySQL även fulltextsökningar i InnoDB-lagringsmotorer. Detta har varit fantastiska nyheter, eftersom det gör det möjligt för utvecklare att dra nytta av InnoDB:s referensintegritet, förmåga att utföra transaktioner och radnivålås.
Det finns i princip två tillvägagångssätt för fulltextsökningar i MySQL:naturligt språk och booleskt läge. (Ett tredje alternativ utökar den naturliga språksökningen med en andra expansionsfråga.)
Huvudskillnaden mellan det naturliga och booleska läget är att det booleska läget tillåter vissa operatorer som en del av sökningen. Till exempel kan booleska operatorer användas om ett ord har större relevans än andra i frågan eller om ett specifikt ord ska finnas i resultaten etc. Det är värt att notera att i båda fallen kan resultaten sorteras efter den relevans som beräknas av MySQL under sökningen.
Ta besluten
Den bästa lösningen för vårt problem var att använda InnoDb fulltextsökningar i booleskt läge. Varför?
- Vi hade lite tid att implementera sökfunktionen.
- Vid denna tidpunkt hade vi ingen stor data att knäcka eller en massiv belastning för att kräva något som Elasticsearch eller Sphinx.
- Vi använde delad värd som inte stöder Elasticsearch eller Sphinx och hårdvaran var ganska begränsad i det här skedet.
- Medan vi ville ha ordstammar i vår sökfunktion, var det inte en deal breaker:vi kunde implementera det (inom begränsningar) med hjälp av enkel PHP-kodning och datadenormalisering
- Fulltextsökningar i booleskt läge kan söka efter ord med jokertecken (för ordet härrörande) och sortera resultaten baserat på relevans.
Fulltextsökningar i booleskt läge
Som nämnts tidigare är sökning på naturligt språk det enklaste tillvägagångssättet:sök bara efter en fras eller ett ord i kolumnerna där du har satt ett fulltextindex så får du resultat sorterade efter relevans.
I den normaliserade Vertabelo-modellen
Låt oss se hur en enkel sökning skulle fungera. Vi skapar en exempeltabell först:
-- Skapad av Vertabelo (https://vertabelo.com)-- Senaste ändringsdatum:2016-04-25 15:01:22.153-- tables-- Tabell:artistsCREATE TABLE artister ( id int(11) NOT NULL AUTO_INCREMENT, namn varchar(255) NOT NULL, biotext NOT NULL, CONSTRAINT artists_pk PRIMARY KEY (id)) ENGINE InnoDB;CREATE FULLTEXT INDEX artists_idx_1 ON artists (namn);-- Filens slut.
I naturligt språkläge
Du kan infoga några exempeldata och börja testa. (Det skulle vara bra att lägga till det i din exempeldatauppsättning.) Vi ska till exempel försöka söka efter Michael Jackson:
VÄLJ *FRÅN artister WHERE MATCH (artists.name) MOT ('Michael Jackson' I NATURAL LANGUAGE LÄGE) Den här frågan kommer att hitta poster som matchar söktermerna och sorterar matchande poster efter relevans; ju bättre matchning desto mer relevant är den och desto högre kommer resultatet att synas i listan.
I booleskt läge
Vi kan utföra samma sökning i booleskt läge. Om vi inte tillämpar några operatorer på vår fråga är den enda skillnaden att resultaten inte är sorterat efter relevans:
VÄLJ *FRÅN artister WHERE MATCH (artists.name) MOT ('Michael Jackson' I BOOLISKT LÄGE) Jokerteckenoperatorn i booleskt läge
Eftersom vi vill söka härstammade och partiella ord behöver vi jokerteckenoperatorn (*). Den här operatorn kan användas i sökningar i booleskt läge, vilket är anledningen till att vi valde det läget.
Så låt oss släppa lös kraften i boolesk sökning och försöka söka efter en del av artistens namn. Vi använder jokerteckenoperatorn för att matcha alla artister vars namn börjar med "Mich":
VÄLJ *FRÅN artister WHERE MATCH (namn) MOT ('Mich*' I BOOLENSK LÄGE) Sortering efter relevans i booleskt läge
Låt oss nu se den beräknade relevansen för sökningen. Detta kommer att hjälpa oss att förstå sorteringen vi kommer att göra senare med Cake:
VÄLJ *, MATCH (namn) MOT ('mich*' I BOOLENSK LÄGE) SOM rankFrån artister WHERE MATCH (namn) MOT ('mich*' I BOOLENSK LÄGE)ORDNING EFTER rank DESC Denna fråga hämtar sökträffar och det relevansvärde som MySQL beräknar för varje post. Motoroptimeraren kommer att upptäcka att vi väljer relevans, så den kommer inte att bry sig om att räkna om rangordningen.
Ordstammar i fulltextsökning
När vi tar med ordstammar i en sökning blir sökningen mer användarvänlig. Även om resultatet inte är ett ord i sig, försöker algoritmer generera samma rot för härledda ord. Till exempel är stammen "argu" inte ett engelskt ord, men det kan användas som stam för "argue", "argued", "argues", "arguing", "Argus" och andra ord.
Stemming förbättrar resultaten, eftersom användaren kan skriva in ett ord som inte har någon exakt matchning men dess "stam" gör det. Även om PHP-avstämmare eller Snowballs Python-avstämmare kan vara ett alternativ (om du har root-SSH-åtkomst till din server), kommer vi att använda klassen PorterStemmer.php.
Den här klassen implementerar algoritmen som föreslagits av Martin Porter för att stamma ord på engelska. Som författaren säger på sin webbplats är den gratis att använda för alla ändamål. Släpp bara filen i din leverantörskatalog i CakePHP, inkludera biblioteket i din modell och anrop den statiska metoden för att stamma ett ord:
//inkludera biblioteket (bör heta PorterStemmer.php) i CakePHP:s leverantörsmappApp::import('Vendor', 'PorterStemmer'); //stamma ett ord (ord måste härstamma ett efter ett)echo PorterStemmer::Stem(‘stemming’); //utgång kommer att vara 'stam' Vårt mål är att göra sökningen snabb och effektiv och att kunna sortera resultat efter deras fulltextrelevans. För att göra detta måste vi använda ordstamming på två sätt:
- Orden som angetts av användaren
- Låtrelaterad data (som vi lagrar i kolumner och sorterar efter resultat baserat på relevans)
Den första typen av ordstamming kan åstadkommas så här:
App::import('Vendor', 'PorterStemmer');$search =trim(preg_replace('/[^A-Za-z0-9_\s]/', '', $search));/ /ta bort oönskade tecken$words =explode(" ", trim($search));$stemmedSearch ="";$unstemmedSearch ="";foreach ($words as $word) { $stemmedSearch .=PorterStemmer::Stem($ ord). "* ";//vi lägger till jokertecken efter varje ord $unstemmedSearch =$word . "* ";//för att söka i artistkolumnen som inte är stammad}$stemmedSearch =trim($stemmedSearch);$unstemmedSearch =trim($unstemmedSearch);if ($stemmedSearch =="*" || $unstemmedSearch==" *") { //annars kommer mySql att klaga, eftersom du inte kan använda enbart jokertecknet $stemmedSearch =""; $unstemmedSearch ="";} Vi har skapat två strängar:en för att söka efter artistnamnet (utan stam), och en för att söka i de andra stamkolumnerna. Detta kommer att hjälpa oss senare att bygga vårt 'mot' del av fulltextfrågan. Låt oss nu se hur vi kan styra och sortera låtens data.
Avnormalisera sångdata
Våra sorteringskriterier kommer att baseras på att först matcha låtens artist (utan stam). Därefter kommer låtens namn, album och relaterade kategorier. Stemming kommer att användas på alla sekundära sökkriterier.
För att illustrera detta, anta att jag söker efter "nirvana" och det finns en låt som heter "Nirvana Games" av "XYZ", och en annan låt som heter "Polly" av artisten "Nirvana". Resultaten bör lista "Polly" först, eftersom matchningen på artistnamnet är viktigare än en matchning på låtnamnet (baserat på mina kriterier).
För att göra detta lade jag till fyra fält i songs tabell, en för vart och ett av sök-/sorteringskriterierna vi vill ha:
ALTER TABLE `låtar` ADD `denorm_artist` VARCHAR(255) NOT NULL EFTER`trackname`, ADD `denorm_trackname` VARCHAR(500) NOT NULL EFTER`denorm_artist`, ADD `denorm_album` VARCHAR(255)` NOT NULL EFTER denorm_trackname`,ADD `denorm_categories` VARCHAR(500) NOT NULL EFTER`denorm_album`, ADD FULLTEXT (`denorm_artist`), ADD FULLTEXT(`denorm_trackname`), ADD FULLTEXT (`denorm_album`), ADD FULLTEXT(`denorm_categories`);
Vår kompletta databasmodell skulle se ut så här:
När du sparar en låt med add/edit i CakePHP behöver du bara lagra artistnamnet i kolumnen denorm_artist utan att stävja det. Lägg sedan till det stammade spårnamnet i denorm_trackname fältet (liknande vad vi gjorde i den sökta texten) och spara det stammade albumets namn i denorm_album kolumn. Slutligen, lagra den skaftade kategoriuppsättningen för låten i denorm_categories fältet, sammanfoga orden och lägga till ett mellanslag mellan varje stamkategorinamn.
Fulltextsökning och relevanssortering i CakePHP
Om vi fortsätter med exemplet med att söka efter "Nirvana", låt oss se vad en fråga som liknar denna kan åstadkomma:
VÄLJ spårnamn, MATCH(denorm_artist) AGAINST ('Nirvana*' I BOOLEAN MODE) som rank1, MATCH(denorm_trackname) AGAINST ('Nirvana*' I BOOLEAN MODE) som rank2, MATCH(denorm_album) AGAINST ('Nirvana*' I BOOLEAN MODE) som rank3, MATCH(denorm_categories) AGAINST ('Nirvana*' I BOOLEAN MODE) som rank4 FRÅN låtar WHERE MATCH(denorm_artist) AGAINST ('Nirvana*' I BOOLEAN MODE) OR MATCH(denorm_trackname) MOT ('N) ' I BOOLENSK LÄGE) ELLER MATCH(denorm_album) MOT ('Nirvana*' I BOOLENSK LÄGE) ELLER MATCH(denorm_categories) MOT ('Nirvana*' I BOOLENSK LÄGE) ORDNING EFTER rank1 DESC, rank2 DESC, rank3 DESC, rank4 DESC Vi skulle få följande utdata:
| spårnamn | rank1 | rank2 | rank3 | rank4 |
| Polly | 0,0906190574169159 | 0 | 0 | 0 |
| nirvana-spel | 0 | 0,0906190574169159 | 0 | 0 |
För att göra detta i CakePHP, hit Metoden måste anropas med en kombination av parametrar "fält", "villkor" och "ordning". Fortsätter med den tidigare PHP-exempelkoden:
//inom Song.php modellfil $fields =array( "Sång.spårnamn", "MATCH(Song.denorm_artist) MOT ({$unstemmedSearch} I BOOLISKT LÄGE) som `rank1`", "MATCH(Sång. denorm_trackname) MOT ({$stemmedSearch} I BOOLENSK LÄGE) som `rank2`", "MATCH(Song.denorm_album) AGAINST ({$stemmedSearch} I BOOLEAN MODE) som `rank3`", "MATCH(Song.denorm_categories) AGAINST ( {$stemmedSearch} I BOOLENSK LÄGE) som `rank4`" );$order ="`rank1` DESC,`rank2` DESC,`rank3` DESC,`rank4` DESC,Song.trackname ASC";$conditions =array( "ELLER" => array( "MATCH(Song.denorm_artist) MOT ({$unstemmedSearch} I BOOLENSK LÄGE)", "MATCH(Song.denorm_trackname) MOT ({$stemmedSearch} I BOOLENSK LÄGE)", "MATCH(Sång. denorm_album) MOT ({$stemmedSearch} I BOOLENSK LÄGE)", "MATCH(Song.denorm_categories) MOT ({$stemmedSearch} I BOOLENSK LÄGE)" );$results =$this->hit (‘all’,array(‘conditions’=>$conditions,’fields’=>$fields,’order’=>$order); $results kommer att vara samlingen av låtar sorterade med de kriterier vi definierade tidigare.
Denna lösning kan användas för att generera sökningar som är meningsfulla för användaren – utan att kräva för mycket tid från utvecklarna eller lägga till större komplexitet i koden.
Gör CakePHP-sökningar ännu bättre
Det är värt att nämna att att "krydda" de denormaliserade kolumnerna med mer data kan leda till bättre resultat.
Med "krydda" menar jag att du kan inkludera, i de denormaliserade kolumnerna, mer data från ytterligare kolumner som du anser vara användbar med målet att göra resultaten mer relevanta, till exempel om du visste att en artists land kunde ingå i söktermerna, kan lägga till landet tillsammans med artistnamnet i denorm_artist kolumn. Detta skulle förbättra kvaliteten på sökresultaten.
Av min erfarenhet (beroende på de faktiska data som du använder och kolumnerna du avnormaliserar) tenderar de översta resultaten att vara riktigt korrekta. Det här är bra för mobilappar, eftersom det kan vara frustrerande för användaren att rulla ner en lång lista.
Slutligen, om du behöver få mer data från tabellerna som låten relaterar till, kan du alltid göra en join och få artisten, kategorier, album, låtkommentarer etc. Om du använder CakePHP:s innehållsbara beteendefilter, skulle jag vilja föreslå att du lägger till plugin-programmet EagerLoader för att göra anslutningarna effektivt.
Om du har din egen metod för att implementera fulltextsökning, vänligen dela det i kommentarerna nedan. Vi kan alla lära av varandras erfarenheter.