Att ha referenstabeller i din databas är väl ingen stor sak? Du behöver bara knyta en kod eller ID med en beskrivning för varje referenstyp. Men vad händer om du bokstavligen har dussintals och dussintals referenstabeller? Finns det ett alternativ till ett-bord-per-typ-metoden? Läs vidare för att upptäcka en generisk och utbyggbar databasdesign för att hantera alla dina referensdata.
Detta ovanligt utseende diagram är ett fågelperspektiv av en logisk datamodell (LDM) som innehåller alla referenstyper för ett företagssystem. Det är från en utbildningsinstitution, men det kan gälla datamodellen för vilken typ av organisation som helst. Ju större modell, desto fler referenstyper kommer du sannolikt att upptäcka.
Med referenstyper menar jag referensdata, eller uppslagsvärden, eller – om du vill vara flash – taxonomier . Vanligtvis används värdena som definieras här i rullgardinslistor i din applikations användargränssnitt. De kan också visas som rubriker på en rapport.
Denna specifika datamodell hade cirka 100 referenstyper. Låt oss zooma in och titta på bara två av dem.
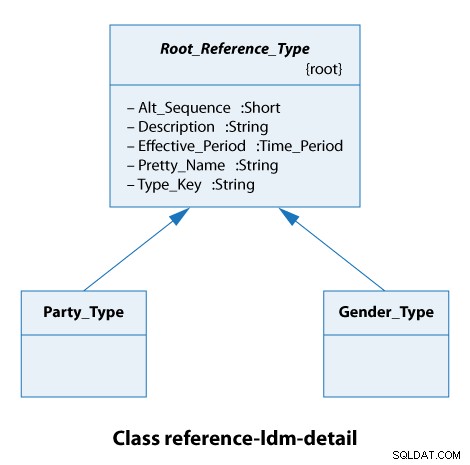
Från detta klassdiagram ser vi att alla referenstyper utökar Root_Reference_Type . I praktiken betyder detta bara att alla våra referenstyper har samma attribut från Alt_Sequence genom till Type_Key inklusive, som visas nedan.
| Attribut | Beskrivning |
|---|---|
Alt_Sequence | Används för att definiera en alternativ sekvens när en icke-alfabetisk ordning krävs. |
Description | Beskrivningen av typen. |
Effective_Period | Definierar effektivt om referensposten är aktiverad eller inte. När en referens väl har använts kan den inte tas bort på grund av referensrestriktioner; det kan bara inaktiveras. |
| Det vackra namnet på typen. Det här är vad användaren ser på skärmen. |
Type_Key | Den unika interna KEY för typen. Detta är dolt för användaren men applikationsutvecklare kan använda detta i stor utsträckning i sin SQL. |
Typen av parti här är antingen en organisation eller en person. Typerna av kön är manliga och kvinnliga. Så det här är verkligen enkla fall.
Den traditionella referenstabelllösningen
Så hur ska vi implementera den logiska modellen i den fysiska världen av en faktisk databas?
Vi skulle kunna anta att varje referenstyp kommer att mappas till sin egen tabell. Du kan hänvisa till detta som det mer traditionella ett-bord-per-klass lösning. Det är enkelt nog och skulle se ut ungefär så här:
Nackdelen med detta är att det kan finnas dussintals och dussintals av dessa tabeller, alla har samma kolumner, alla gör i stort sett samma sak.
Dessutom kan vi skapa mycket mer utvecklingsarbete . Om ett användargränssnitt för varje typ krävs för att administratörer ska kunna behålla värdena, multipliceras mängden arbete snabbt. Det finns inga hårda och snabba regler för detta – det beror verkligen på din utvecklingsmiljö – så du måste prata med dina utvecklare för att förstå vilken effekt detta har.
Men med tanke på att alla våra referenstyper har samma attribut, eller kolumner, finns det ett mer generiskt sätt att implementera vår logiska datamodell? Ja, det finns! Och det kräver bara två tabeller .
Tvåbordslösningen
Den första diskussionen jag någonsin haft om detta ämne var i mitten av 90-talet, när jag arbetade för ett försäkringsbolag på London Market. Då gick vi direkt till fysisk design och använde mest naturliga/affärsnycklar, inte ID. Där referensdata fanns beslutade vi att behålla en tabell per typ som var sammansatt av en unik kod (VARCHAR PK) och en beskrivning. Faktum är att det fanns mycket färre referenstabeller då. Oftare än inte skulle en begränsad uppsättning affärskoder användas i en kolumn, möjligen med en definierad databaskontrollbegränsning; det skulle inte finnas någon referenstabell alls.
Men spelet har gått vidare sedan dess. Det här är en tvåbordslösning kan se ut så här:
Som du kan se är denna fysiska datamodell väldigt enkel. Men det är helt annorlunda än den logiska modellen, och inte för att något har blivit päronformat. Det beror på att ett antal saker gjordes som en del av fysisk design .
reference_type Tabellen representerar varje enskild referensklass från LDM. Så om du har 20 referenstyper i din LDM har du 20 rader med metadata i tabellen. reference_value Tabellen innehåller de tillåtna värdena för alla referenstyperna.
Vid tidpunkten för detta projekt var det några ganska livliga diskussioner mellan utvecklare. Vissa föredrog tvåbordslösningen och andra föredrog ett-bord-per-typ metod.
Det finns för- och nackdelar för varje lösning. Som du kanske gissar var utvecklarna mestadels oroade över hur mycket arbete användargränssnittet skulle ta. Vissa trodde att det skulle gå ganska snabbt att sätta ihop ett administratörsgränssnitt för varje tabell. Andra trodde att det skulle vara mer komplicerat att bygga ett enda administratörsgränssnitt men att det i slutändan skulle löna sig.
I just detta projekt gynnades tvåbordslösningen. Låt oss titta på det mer i detalj.
Det utvidgbara och flexibla referensdatamönstret
Eftersom din datamodell utvecklas över tiden och nya referenstyper krävs, behöver du inte fortsätta att göra ändringar i din databas för varje ny referenstyp. Du behöver bara definiera nya konfigurationsdata. För att göra detta lägger du till en ny rad i reference_type tabellen och lägg till dess kontrollerade lista över tillåtna värden till reference_value bord.
Ett viktigt koncept i denna lösning är att definiera effektiva tidsperioder för vissa värden. Till exempel kan din organisation behöva fånga ett nytt reference_value av "Proof of ID" som kommer att accepteras vid något framtida datum. Det är en enkel fråga att lägga till det nya reference_value med effective_period_from korrekt inställt datum. Detta kan göras i förväg. Fram till det datumet kommer den nya posten inte att visas i rullgardinsmenyn med värden som användarna av din applikation ser. Detta beror på att din applikation endast visar värden som är aktuella eller aktiverade.
Å andra sidan kan du behöva stoppa användare från att använda ett visst reference_value . I så fall uppdaterar du bara den med effective_period_to korrekt inställt datum. När den dagen har passerat kommer värdet inte längre att visas i rullgardinsmenyn. Den blir inaktiverad från den tidpunkten. Men eftersom den fortfarande fysiskt existerar som en rad i tabellen, upprätthålls referensintegriteten för de tabeller där det redan har refererats.
Nu när vi arbetade med tvåtabellslösningen blev det uppenbart att några ytterligare kolumner skulle vara användbara på reference_type tabell. Dessa fokuserade mest på gränssnittsproblem.
Till exempel, pretty_name på reference_type tabellen lades till för användning i användargränssnittet. Det är användbart för stora taxonomier att använda ett fönster med en sökfunktion. Sedan pretty_name kan användas för fönstrets titel.
Å andra sidan, om en rullgardinslista med värden räcker, pretty_name kan användas för LOV-prompten. På liknande sätt kan beskrivning användas i användargränssnittet för att fylla i roll-over-hjälp.
Att ta en titt på vilken typ av konfiguration eller metadata som ingår i dessa tabeller hjälper till att förtydliga saker och ting lite.
Hur man hanterar allt det där
Även om exemplet som används här är väldigt enkelt, kan referensvärdena för ett stort projekt snabbt bli ganska komplexa. Så det kan vara tillrådligt att behålla allt detta i ett kalkylblad. Om så är fallet kan du använda själva kalkylarket för att generera SQL med hjälp av strängsammansättning. Detta klistras in i skript, som exekveras mot måldatabaserna som stödjer utvecklingens livscykel och produktionsdatabasen (live). Detta såddar databasen med alla nödvändiga referensdata.
Här är konfigurationsdata för de två LDM-typerna, Gender_Type och Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
Det finns en rad i reference_type för varje LDM-undertyp av Root_Reference_Type . Beskrivningen i reference_type är hämtat från LDM-klassbeskrivningen. För Gender_Type , skulle detta lyda "Identifierar en persons kön". DML-kodavsnitten visar skillnaderna i beskrivningar mellan typ och värde, som kan användas i användargränssnittet eller i rapporter.
Du kommer att se den där reference_type kallas Gender_Type har tilldelats ett intervall på 13000000 till 13999999 för dess associerade reference_value.ids . I den här modellen är varje reference_type tilldelas ett unikt, icke-överlappande antal ID:n. Detta är inte strikt nödvändigt, men det tillåter oss att gruppera relaterade värde-ID:n. Det härmar ungefär vad du skulle få om du hade separata bord. Det är trevligt att ha, men om du inte tror att det finns någon fördel med detta kan du avstå från det.
En annan kolumn som lades till i PDM är admin_role . Här är varför.
Vilka är administratörer
Vissa taxonomier kan lägga till eller ta bort värden med liten eller ingen effekt. Detta inträffar när inga program använder sig av värdena i sin logik, eller när typen inte är ansluten till andra system. I sådana fall är det säkert för användaradministratörer att hålla dessa uppdaterade.
Men i andra fall måste mycket mer försiktighet utövas. Ett nytt referensvärde kan orsaka oavsiktliga konsekvenser för programlogik eller för nedströms system.
Anta till exempel att vi lägger till följande i taxonomin för könstyp:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Detta blir snabbt ett problem om vi har följande logik inbyggd någonstans:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Det är klart att "om du inte är man måste du vara kvinna"-logiken inte längre gäller i den utökade taxonomin.
Det är här admin_role kolumn spelar in. Det föddes från diskussioner med utvecklarna om den fysiska designen, och det fungerade tillsammans med deras UI-lösning. Men om en-tabell-per-klass-lösningen hade valts, då reference_type inte skulle ha funnits. Metadata som den innehöll skulle ha hårdkodats i applikationen Gender_Type table – , som varken är flexibel eller utdragbar.
Endast användare med rätt behörighet kan administrera taxonomin. Detta kommer sannolikt att baseras på sakkunskap (SME ). Å andra sidan kan vissa taxonomier behöva administreras av IT för att möjliggöra konsekvensanalys, grundlig testning och för att eventuella kodändringar ska släppas harmoniskt i tid för den nya konfigurationen. (Om detta görs genom ändringsförfrågningar eller på annat sätt är upp till din organisation.)
Du kanske har noterat att granskningskolumnerna created_by , created_date , updated_by och updated_date refereras inte alls i skriptet ovan. Återigen, om du inte är intresserad av dessa behöver du inte använda dem. Denna speciella organisation hade en standard som föreskrev att ha granskningskolumner på varje tabell.
Triggers:Att hålla saker konsekventa
Utlösare säkerställer att dessa granskningskolumner uppdateras konsekvent, oavsett källan till SQL (skript, din applikation, schemalagda batchuppdateringar, ad-hoc-uppdateringar, etc.).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Min bakgrund är mestadels Oracle och tyvärr begränsar Oracle identifierare till 30 byte. För att undvika att överskrida detta får varje tabell ett kort alias på tre till fem tecken och andra tabellrelaterade artefakter använder det aliaset i sina namn. Så, reference_value alias är reva – de två första tecknen från varje ord. Före radinfogning och före raduppdatering förkortas till bri och bru respektive. Sekvensnamnet reva_seq , och så vidare.
Handkodning av triggers som denna, tabell efter tabell, kräver mycket demoraliserande pannplåtsarbete för utvecklare. Lyckligtvis kan dessa utlösare skapas via kodgenerering , men det är ämnet för en annan artikel!
Vikten av nycklar
ref_type_key och type_key kolumner är båda begränsade till 30 byte. Detta gör att de kan användas i SQL-frågor av PIVOT-typ (i Oracle. Andra databaser kanske inte har samma längdbegränsning för identifierare).
Eftersom nyckelunikitet säkerställs av databasen och utlösaren säkerställer att dess värde förblir detsamma hela tiden, kan – och bör – dessa nycklar användas i frågor och kod för att göra dem mer läsbara . Vad menar jag med detta? Tja, istället för:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Du skriver:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
I grund och botten anger nyckeln tydligt vad frågan gör .
Från LDM till PDM, med utrymme att växa
Resan från LDM till PDM är inte nödvändigtvis en rak väg. Det är inte heller en direkt förvandling från det ena till det andra. Det är en separat process som introducerar sina egna överväganden och sina egna bekymmer.
Hur modellerar du referensdata i din databas?