Förra veckan presenterade jag min T-SQL :Bad Habits and Best Practices-session under GroupBy-konferensen. En videorepris och annat material finns här:
- T-SQL:dåliga vanor och bästa praxis
En av de saker jag alltid nämner i den sessionen är att jag i allmänhet föredrar GROUP BY framför DISTINCT när jag eliminerar dubbletter. Även om DISTINCT bättre förklarar avsikten och GROUP BY endast krävs när aggregering finns, är de utbytbara i många fall.
Låt oss börja med något enkelt med Wide World Importers. Dessa två frågor ger samma resultat:
SELECT DISTINCT Description FROM Sales.OrderLines; SELECT Description FROM Sales.OrderLines GROUP BY Description;
Och faktiskt härleda sina resultat med exakt samma utförandeplan:

Samma operatörer, samma antal läsningar, försumbara skillnader i CPU och total varaktighet (de turas om att "vinna").
Så varför skulle jag rekommendera att använda den ordligare och mindre intuitiva GROUP BY-syntaxen över DISTINCT? Tja, i det här enkla fallet är det en myntflip. Men i mer komplexa fall kan DISTINCT sluta göra mer arbete. I huvudsak samlar DISTINCT in alla rader, inklusive alla uttryck som behöver utvärderas, och slänger sedan ut dubbletter. GROUP BY kan (igen, i vissa fall) filtrera bort dubblettraderna före utför något av det arbetet.
Låt oss prata om strängaggregation, till exempel. Medan du i SQL Server v.Next kommer att kunna använda STRING_AGG (se inlägg här och här), måste vi andra fortsätta med FOR XML PATH (och innan du berättar för mig om hur fantastiska rekursiva CTE är för detta, snälla läs detta inlägg också). Vi kan ha en fråga som denna, som försöker returnera alla beställningar från tabellen Sales.OrderLines, tillsammans med artikelbeskrivningar som en pipavgränsad lista:
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
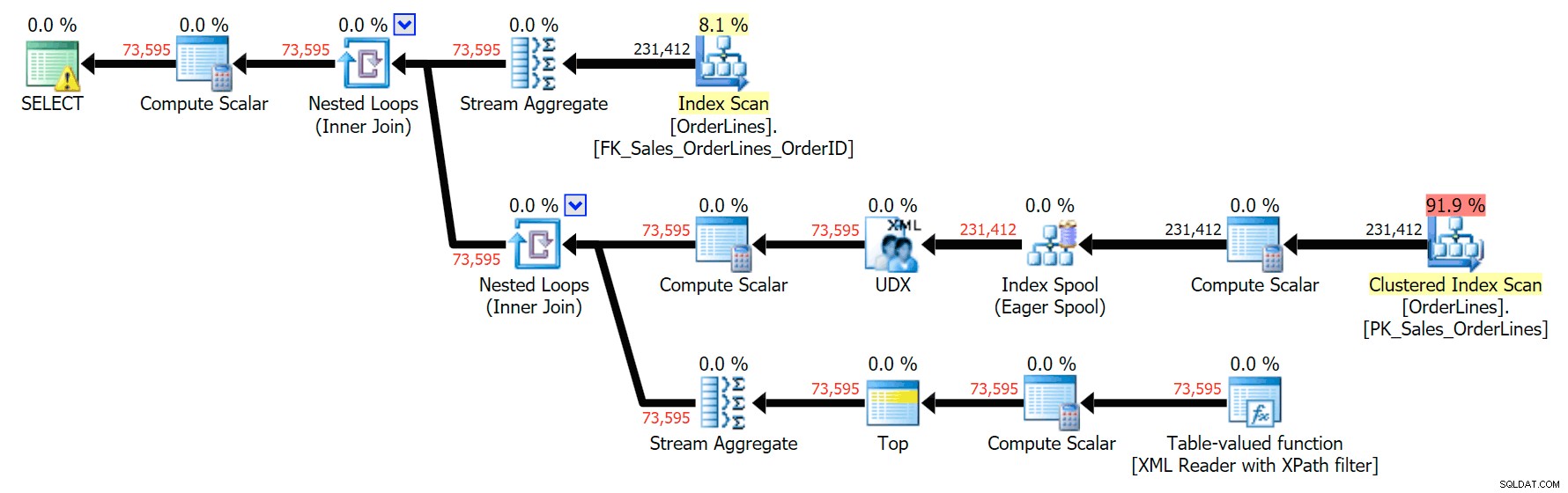
Det här är en typisk fråga för att lösa den här typen av problem, med följande exekveringsplan (varningen i alla planerna är bara för den implicita konverteringen som kommer ut från XPath-filtret):
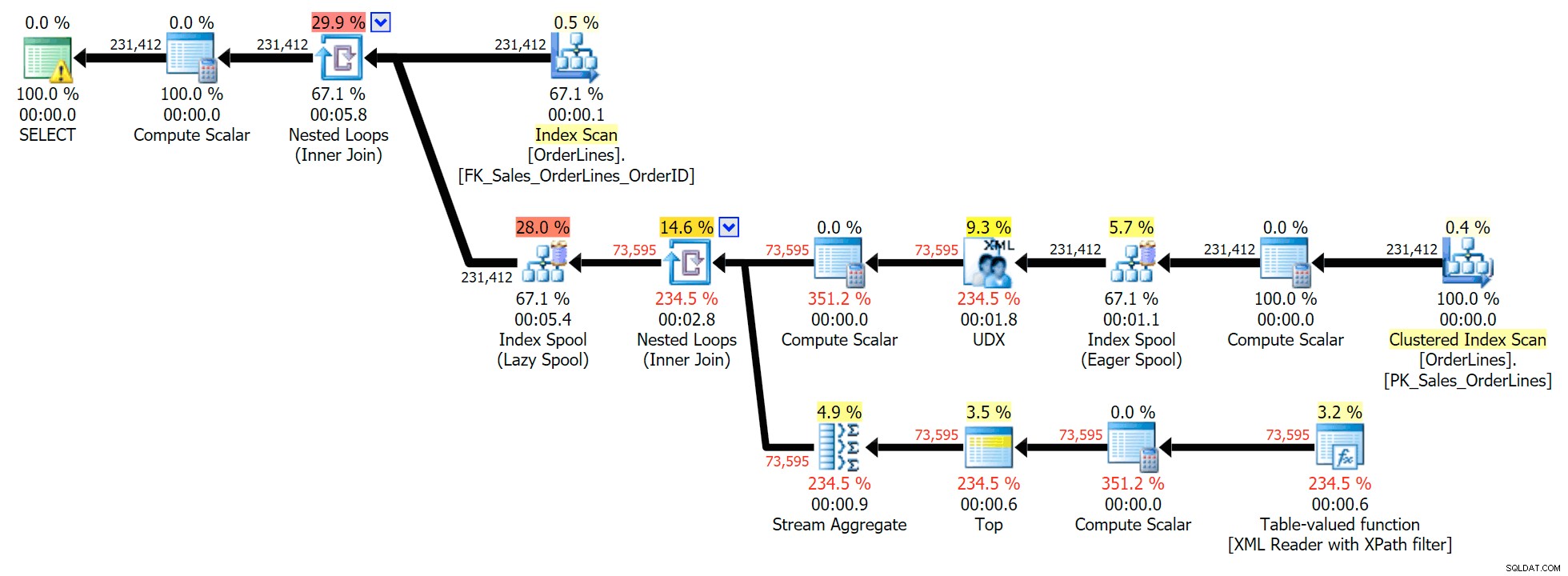
Det har dock ett problem som du kanske märker i antalet rader. Du kan säkert upptäcka det när du avslappnat skannar utdata:

För varje beställning ser vi den röravgränsade listan, men vi ser en rad för varje artikel i varje ordning. Knäsakten är att kasta en DISTINKT på kolumnlistan:
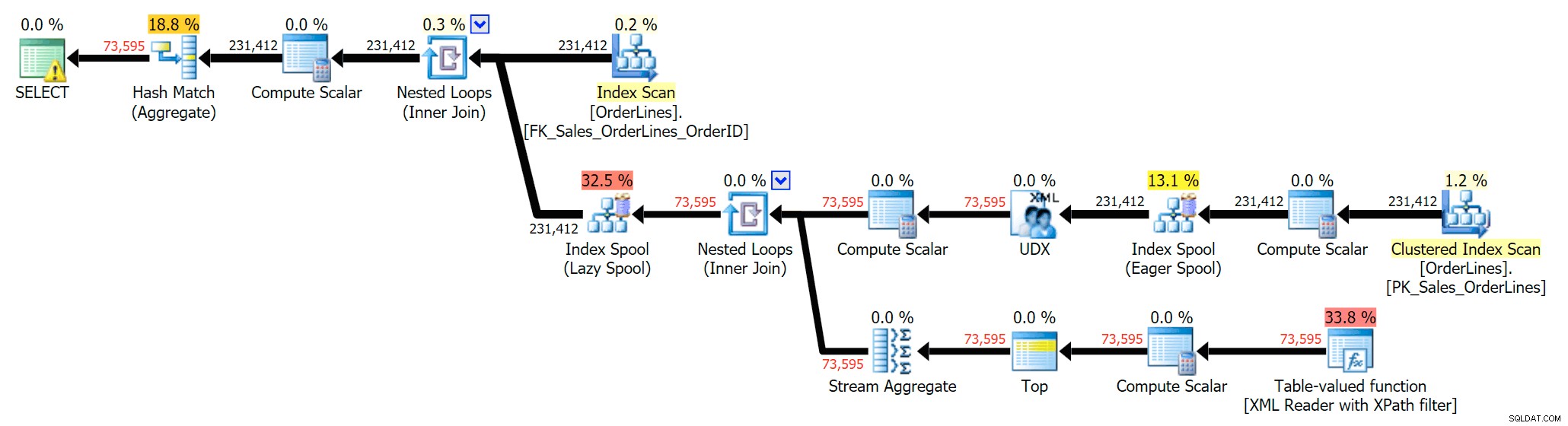
SELECT DISTINCT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o;
Det eliminerar dubbletterna (och ändrar beställningsegenskaperna på skanningarna, så att resultaten inte nödvändigtvis visas i en förutsägbar ordning), och producerar följande exekveringsplan:
Ett annat sätt att göra detta är att lägga till en GROUP BY för OrderID (eftersom underfrågan inte uttryckligen behöver ska refereras igen i GROUP BY):
SELECT o.OrderID, OrderItems = STUFF((SELECT N'|' + Description FROM Sales.OrderLines WHERE OrderID = o.OrderID FOR XML PATH(N''), TYPE).value(N'text()[1]', N'nvarchar(max)'),1,1,N'') FROM Sales.OrderLines AS o GROUP BY o.OrderID;
Detta ger samma resultat (även om beställningen har kommit tillbaka) och en något annorlunda plan:
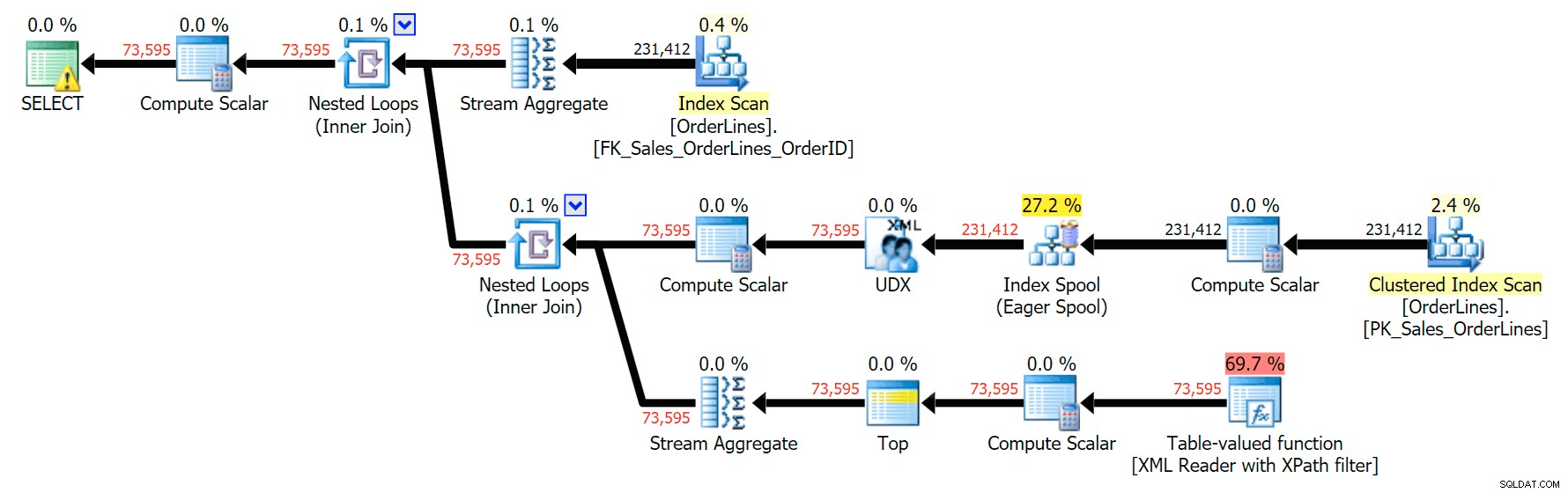
Prestandamåtten är dock intressanta att jämföra.

Variationen DISTINCT tog 4X så lång tid, använde 4X CPU och nästan 6X läsningarna jämfört med GROUP BY-variationen. (Kom ihåg att dessa frågor ger exakt samma resultat.)
Vi kan också jämföra exekveringsplanerna när vi ändrar kostnaderna från CPU + I/O kombinerat till endast I/O, en funktion som är exklusiv för Plan Explorer. Vi visar också de omkostnadsbelagda värdena (som är baserade på de faktiska). kostnader som observerats under utförande av en fråga, en funktion som också bara finns i Plan Explorer). Här är DISTINCT-planen:
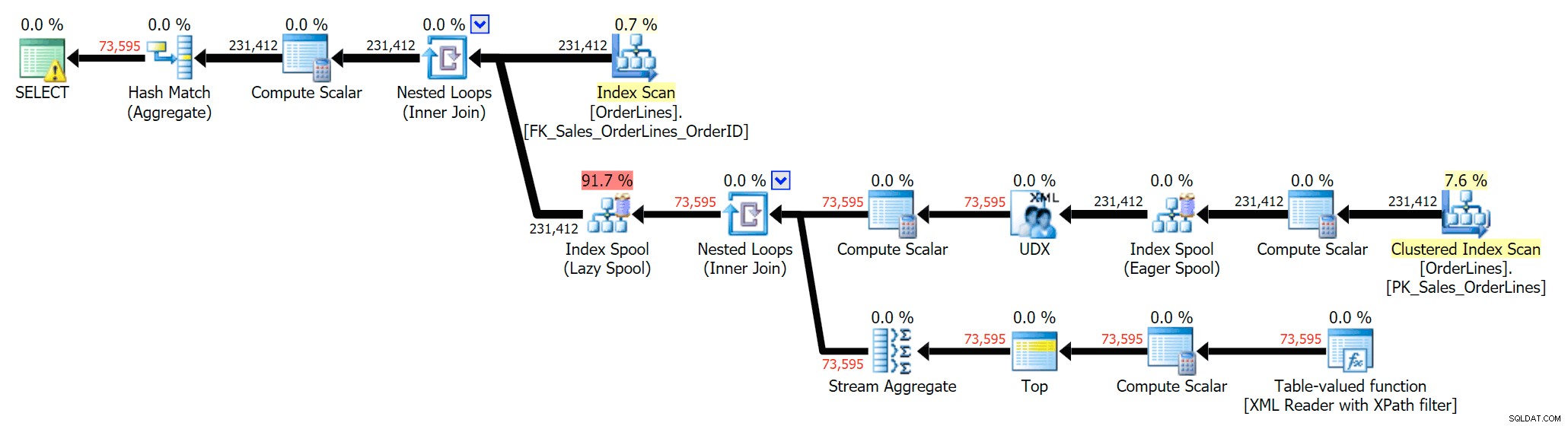
Och här är GROUP BY-planen:
Du kan se att i GROUP BY-planen finns nästan all I/O-kostnad i skanningarna (här är verktygstipset för CI-skanningen, som visar en I/O-kostnad på ~3,4 "frågedollar"). Ändå i DISTINCT-planen finns det mesta av I/O-kostnaden i indexspolen (och här är verktygstipset; I/O-kostnaden här är ~41,4 "frågedollar"). Observera att CPU:n är mycket högre med indexspolen också. Vi kommer att prata om "query bucks" en annan gång, men poängen är att indexspolen är mer än 10 gånger så dyr som skanningen - men skanningen är fortfarande samma 3,4 i båda planerna. Detta är en anledning till att det alltid stör mig när folk säger att de behöver "fixa" operatören i planen med den högsta kostnaden. Någon operatör i planen kommer alltid vara den dyraste; det betyder inte att det behöver fixas.
@AaronBertrand dessa frågor är inte riktigt logiskt likvärdiga — DISTINCT är på båda kolumnerna, medan din GROUP BY bara finns på en
— Adam Machanic (@AdamMachanic) 20 januari 2017
Även om Adam Machanic har rätt när han säger att dessa frågor skiljer sig semantiskt, är resultatet detsamma – vi får samma antal rader, som innehåller exakt samma resultat, och vi gjorde det med mycket färre läsningar och CPU.
Så även om DISTINCT och GROUP BY är identiska i många scenarier, är här ett fall där GROUP BY-metoden definitivt leder till bättre prestanda (till bekostnad av mindre tydlig deklarativ avsikt i själva frågan). Jag skulle vara intresserad av att veta om du tror att det finns några scenarier där DISTINCT är bättre än GROUP BY, åtminstone när det gäller prestanda, vilket är mycket mindre subjektivt än stil eller om ett uttalande måste vara självdokumenterande.
Det här inlägget passar in i min "överraskningar och antaganden"-serier eftersom många saker vi håller som sanningar baserade på begränsade observationer eller särskilda användningsfall kan testas när de används i andra scenarier. Vi måste bara komma ihåg att ta oss tid att göra det som en del av SQL-frågeoptimering...
Referenser
- Grupperad sammanlänkning i SQL Server
- Grupperad sammanfogning :Beställa och ta bort dubbletter
- Fyra praktiska användningsfall för grupperad sammanlänkning
- SQL Server v.Next:STRING_AGG() prestanda
- SQL Server v.Next:STRING_AGG Performance, del 2