En av många nya funktioner som introducerades i SQL Server 2008 var datakomprimering. Komprimering på antingen rad- eller sidnivå ger en möjlighet att spara diskutrymme, med avvägningen att kräva lite mer CPU för att komprimera och dekomprimera data. Det hävdas ofta att majoriteten av systemen är IO-bundna, inte CPU-bundna, så avvägningen är värt det. Fångsten? Du måste ha Enterprise Edition för att använda datakomprimering. Med lanseringen av SQL Server 2016 SP1 har det förändrats! Om du kör Standard Edition av SQL Server 2016 SP1 och högre kan du nu använda datakomprimering. Det finns också en ny inbyggd funktion för komprimering, COMPRESS (och dess motsvarighet DECOMPRESS). Datakomprimering fungerar inte på data utanför rad, så om du har en kolumn som NVARCHAR(MAX) i din tabell med värden som vanligtvis är större än 8 000 byte, kommer den informationen inte att komprimeras (tack Adam Machanic för den påminnelsen) . Funktionen COMPRESS löser detta problem och komprimerar data upp till 2 GB i storlek. Dessutom, även om jag skulle hävda att funktionen endast bör användas för stora data utanför rad, tyckte jag att det var ett värdefullt experiment att jämföra den direkt med rad- och sidkomprimering.
INSTÄLLNING
För testdata arbetar jag utifrån ett skript som Aaron Bertrand har använt tidigare, men jag har gjort några justeringar. Jag skapade en separat databas för testning men du kan använda tempdb eller en annan exempeldatabas, och sedan började jag med en Kundtabell som har tre NVARCHAR-kolumner. Jag övervägde att skapa större kolumner och fylla dem med strängar av upprepade bokstäver, men att använda läsbar text ger ett exempel som är mer realistiskt och därmed ger större noggrannhet.
Obs! Om du är intresserad av att implementera komprimering och vill veta hur det kommer att påverka lagring och prestanda i din miljö, REKOMMENDERAR JAG STARKT ATT DU TESTER DET. Jag ger dig metodiken med exempeldata; att implementera detta i din miljö bör inte innebära ytterligare arbete.
Du kommer att notera nedan att efter att ha skapat databasen aktiverar vi Query Store. Varför skapa en separat tabell för att försöka spåra våra prestandamått när vi bara kan använda funktionalitet inbyggd i SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Nu ska vi ställa in några saker i databasen:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Med tabellen skapad lägger vi till lite data, men vi lägger till 5 miljoner rader istället för 1 miljon. Det tar ungefär åtta minuter att köra på min bärbara dator.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Nu ska vi skapa ytterligare tre tabeller:en för radkomprimering, en för sidkomprimering och en för COMPRESS-funktionen. Observera att med COMPRESS-funktionen måste du skapa kolumnerna som VARBINARY-datatyper. Som ett resultat finns det inga icke-klustrade index i tabellen (eftersom du inte kan skapa en indexnyckel på en varbinär kolumn).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Därefter kopierar vi data från [dbo].[Kunder] till de andra tre tabellerna. Detta är en rak INSERT för våra sid- och radtabeller och tar ungefär två till tre minuter för varje INSERT, men det finns ett skalbarhetsproblem med KOMPRESSA-funktionen:att försöka infoga 5 miljoner rader i ett svep är helt enkelt inte rimligt. Skriptet nedan infogar rader i batcher om 50 000 och infogar bara 1 miljon rader istället för 5 miljoner. Jag vet, det betyder att vi inte är riktigt äpplen-till-äpplen här för jämförelse, men jag är ok med det. Att infoga 1 miljon rader tar 10 minuter på min maskin; finjustera skriptet och infoga 5 miljoner rader för dina egna tester.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Med alla våra tabeller fyllda kan vi göra en kontroll av storleken. För närvarande har vi inte implementerat ROW- eller PAGE-komprimering, men funktionen COMPRESS har använts:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
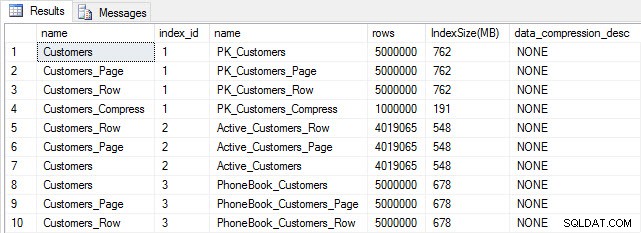 Tabell- och indexstorlek efter infogning
Tabell- och indexstorlek efter infogning
Som förväntat är alla tabeller utom Customers_Compress ungefär lika stora. Nu kommer vi att bygga om index på alla tabeller och implementera rad- och sidkomprimering på Customers_Row och Customers_Page, respektive.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Om vi kontrollerar tabellstorleken efter komprimering kan vi nu se hur vi sparar diskutrymme:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
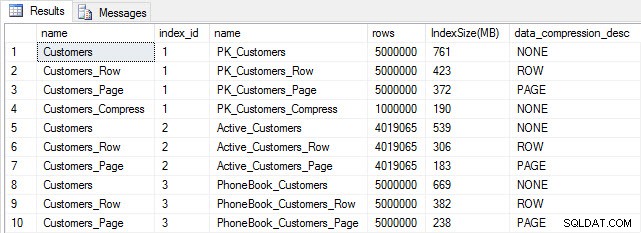
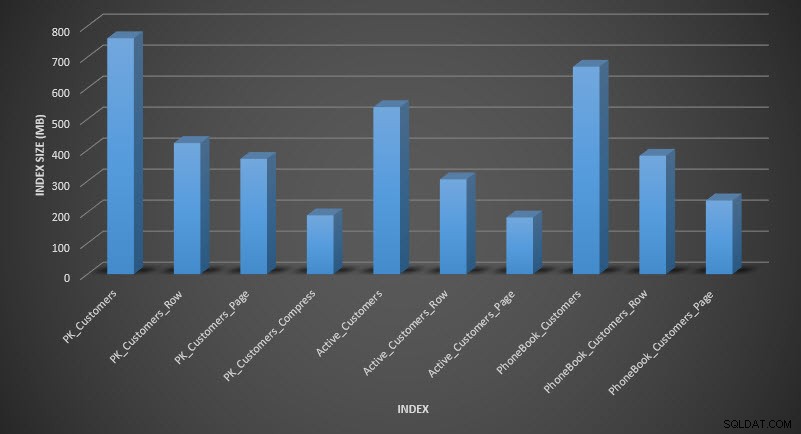 Indexstorlek efter komprimering
Indexstorlek efter komprimering
Som förväntat minskar rad- och sidkomprimeringen avsevärt storleken på tabellen och dess index. Funktionen COMPRESS sparade oss mest utrymme – det klustrade indexet är en fjärdedel av storleken på den ursprungliga tabellen.
UNDERSÖKNING AV FRÅGAS PRESTANDA
Innan vi testar frågeprestanda, notera att vi kan använda Query Store för att titta på INSERT och REBUILD prestanda:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
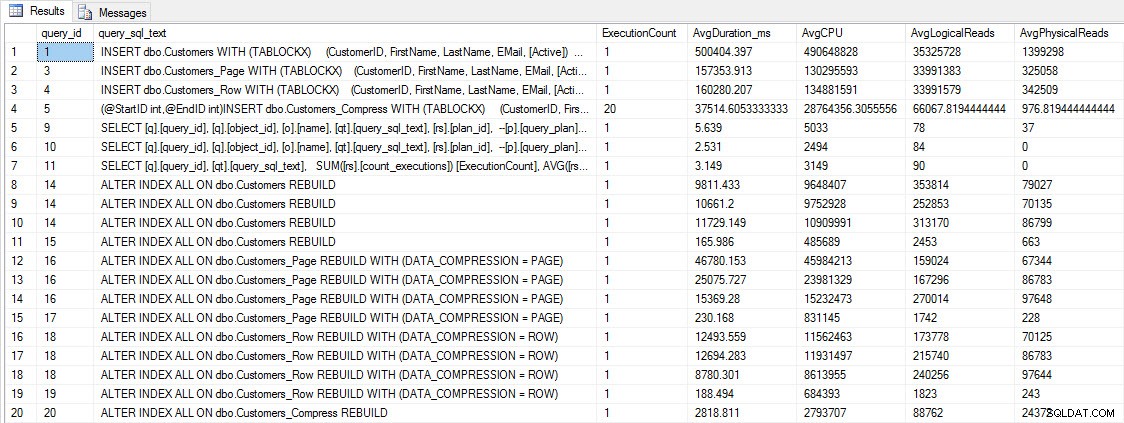 INFOGA och ÅTERBYGGA prestandamått
INFOGA och ÅTERBYGGA prestandamått
Även om denna information är intressant, är jag mer nyfiken på hur komprimering påverkar mina vardagliga SELECT-frågor. Jag har en uppsättning av tre lagrade procedurer som var och en har en SELECT-fråga, så att varje index används. Jag skapade dessa procedurer för varje tabell och skrev sedan ett skript för att hämta värden för för- och efternamn för att använda för testning. Här är skriptet för att skapa procedurerna.
När vi har skapat de lagrade procedurerna kan vi köra skriptet nedan för att anropa dem. Starta detta och vänta sedan ett par minuter...
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Efter några minuter kan du titta på vad som finns i Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Du kommer att se att de flesta lagrade procedurer endast har körts 20 gånger eftersom två procedurer mot [dbo].[Customers_Compress] är verkligen långsam. Detta är inte en överraskning; varken [FirstName] eller [LastName] är indexerade, så alla frågor måste skanna tabellen. Jag vill inte att de två frågorna ska sakta ner min testning, så jag kommer att ändra arbetsbelastningen och kommentera EXEC [dbo].[usp_FindActiveCustomer_CS] och EXEC [dbo].[usp_FindAnyCustomer_CS] och sedan starta det igen. Den här gången låter jag den köras i cirka 10 minuter, och när jag tittar på Query Store-utgången igen har jag lite bra data. Råa siffror finns nedan, med chefens favoritdiagram nedan.
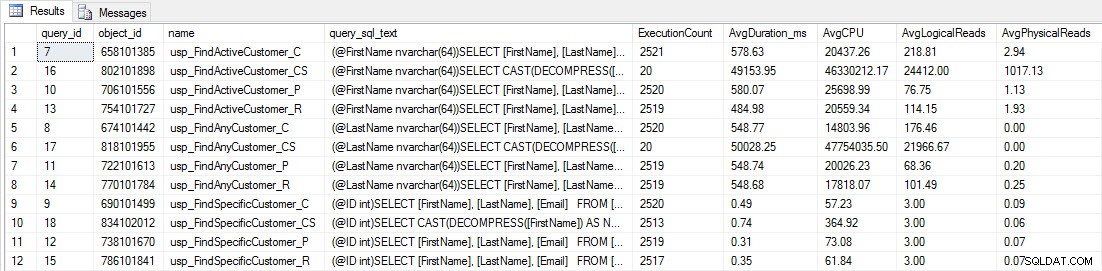 Prestandadata från Query Store
Prestandadata från Query Store
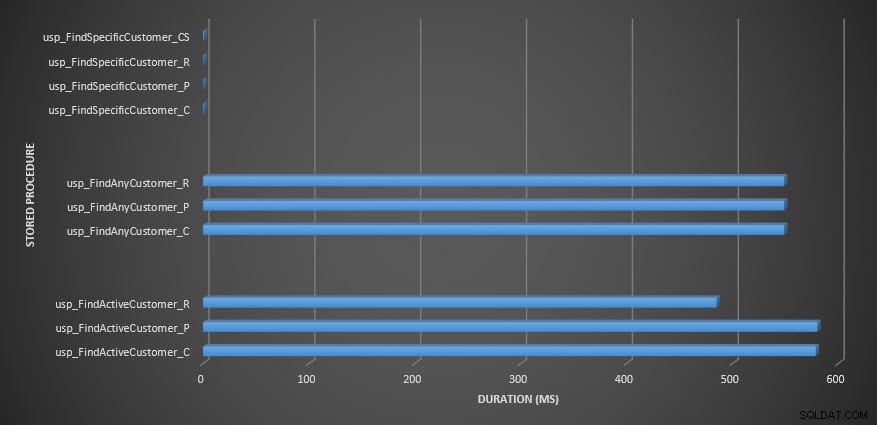 Lagrad procedurlängd
Lagrad procedurlängd
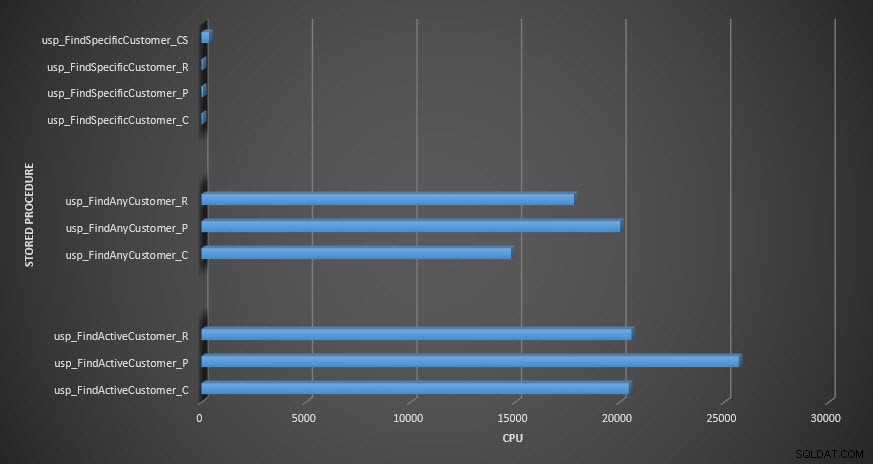 CPU för lagrad procedur
CPU för lagrad procedur
Påminnelse:Alla lagrade procedurer som slutar med _C är från den icke-komprimerade tabellen. Procedurerna som slutar med _R är den radkomprimerade tabellen, de som slutar med _P är sidkomprimerade, och den med _CS använder COMPRESS-funktionen (jag tog bort resultaten för nämnda tabell för usp_FindAnyCustomer_CS och usp_FindActiveCustomer_CS eftersom de skevde grafen så mycket att vi tappade skillnader i resten av data). Procedurerna usp_FindAnyCustomer_* och usp_FindActiveCustomer_* använde icke-klustrade index och returnerade tusentals rader för varje körning.
Jag förväntade mig att varaktigheten skulle vara längre för procedurerna usp_FindAnyCustomer_* och usp_FindActiveCustomer_* mot rad- och sidkomprimerade tabeller, jämfört med den icke-komprimerade tabellen, på grund av överkostnaderna för att dekomprimera data. Query Store-data stöder inte mina förväntningar – varaktigheten för dessa två lagrade procedurer är ungefär densamma (eller mindre i ett fall!) över de tre tabellerna. Den logiska IO för frågorna var nästan densamma i de icke-komprimerade och sid- och radkomprimerade tabellerna.
När det gäller CPU, i de lagrade procedurerna usp_FindActiveCustomer och usp_FindAnyCustomer var det alltid högre för de komprimerade tabellerna. CPU var jämförbar för proceduren usp_FindSpecificCustomer, som alltid var en singleton-uppslagning mot det klustrade indexet. Notera den höga CPU:n (men relativt låg varaktighet) för proceduren usp_FindSpecificCustomer mot tabellen [dbo].[Customer_Compress], som krävde DECOMPRESS-funktionen för att visa data i läsbart format.
SAMMANFATTNING
Den extra CPU som krävs för att hämta komprimerad data finns och kan mätas med Query Store eller traditionella baslinjemetoder. Baserat på denna första testning är CPU jämförbar för singleton-uppslagningar, men ökar med mer data. Jag ville tvinga SQL Server att dekomprimera mer än bara 10 sidor – jag ville ha minst 100. Jag körde varianter av det här skriptet, där tiotusentals rader returnerades, och fynden stämde överens med vad du ser här. Min förväntning är att för att se betydande skillnader i varaktighet på grund av tiden för att dekomprimera data, skulle frågor behöva returnera hundratusentals eller miljontals rader. Om du är i ett OLTP-system vill du inte returnera så många rader, så testerna här borde ge dig en uppfattning om hur komprimering kan påverka prestandan. Om du befinner dig i ett datalager kommer du förmodligen att se längre varaktighet tillsammans med högre CPU när du returnerar stora datamängder. Medan COMPRESS-funktionen ger avsevärda utrymmesbesparingar jämfört med sid- och radkomprimering, gör prestandaträffen i termer av CPU och oförmågan att indexera de komprimerade kolumnerna på grund av deras datatyp, att den bara är lönsam för stora datamängder som inte kommer att indexeras. letade.