Ett prestandaproblem som jag ofta ser är när användare behöver matcha en del av en sträng med en fråga som följande:
... WHERE SomeColumn LIKE N'%SomePortion%';
Med ett ledande jokertecken är detta predikat "icke-SARGable" – bara ett fint sätt att säga att vi inte kan hitta de relevanta raderna genom att använda en sökning mot ett index på SomeColumn .
En lösning som vi blir lite oroliga för är fulltextsökning; detta är dock en komplex lösning och det kräver att sökmönstret består av hela ord, inte använder stoppord och så vidare. Detta kan hjälpa om vi letar efter rader där en beskrivning innehåller ordet "mjuk" (eller andra derivator som "mjukare" eller "mjuka"), men det hjälper inte när vi letar efter strängar som kan innehålla i ord (eller som inte alls är ord, som alla produkt-SKU:er som innehåller "X45-B" eller alla registreringsskyltar som innehåller sekvensen "7RA").
Tänk om SQL Server på något sätt visste om alla möjliga delar av en sträng? Min tankeprocess är i linje med trigram / trigraph i PostgreSQL. Grundkonceptet är att motorn har förmågan att göra punktuppslagningar på delsträngar, vilket innebär att du inte behöver skanna hela tabellen och analysera varje fullständigt värde.
Det specifika exemplet de använder där är ordet cat . Förutom hela ordet kan det delas upp i delar:c , ca och at (de utelämnar a och t per definition – ingen efterföljande delsträng kan vara kortare än två tecken). I SQL Server behöver vi inte vara så komplexa; vi behöver egentligen bara halva trigrammet – om vi tänker på att bygga en datastruktur som innehåller alla understrängar av cat , vi behöver bara dessa värden:
- katt
- vid
- t
Vi behöver inte c eller ca , eftersom alla som söker efter LIKE '%ca%' kunde enkelt hitta värde 1 genom att använda LIKE 'ca%' istället. På samma sätt kan alla som söker efter LIKE '%at%' eller LIKE '%a%' skulle kunna använda ett efterföljande jokertecken endast mot dessa tre värden och hitta det som matchar (t.ex. LIKE 'at%' hittar värde 2 och LIKE 'a%' kommer också att hitta värde 2, utan att behöva hitta de understrängarna inom värde 1, vilket är där den verkliga smärtan skulle komma ifrån).
Så, givet att SQL Server inte har något liknande inbyggt, hur skapar vi ett sådant trigram?
En separat fragmenttabell
Jag ska sluta hänvisa till "trigram" här eftersom detta inte är riktigt analogt med den funktionen i PostgreSQL. Vad vi ska göra är att bygga en separat tabell med alla "fragment" av den ursprungliga strängen. (Så i cat Till exempel skulle det finnas en ny tabell med dessa tre rader och LIKE '%pattern%' sökningar skulle riktas mot den nya tabellen som LIKE 'pattern%' predikat.)
Innan jag börjar visa hur min föreslagna lösning skulle fungera, låt mig vara helt tydlig att den här lösningen inte bör användas i varje enskilt fall där LIKE '%wildcard%' sökningar går långsamt. På grund av hur vi kommer att "explodera" källdata till fragment, är det sannolikt begränsat i praktiken till mindre strängar, som adresser eller namn, i motsats till större strängar, som produktbeskrivningar eller sessionssammandrag.
Ett mer praktiskt exempel än cat är att titta på Sales.Customer tabellen i WideWorldImporters exempeldatabas. Den har adressrader (båda nvarchar(60) ), med den värdefulla adressinformationen i kolumnen DeliveryAddressLine2 (av okända skäl). Någon kanske letar efter någon som bor på en gata som heter Hudecova , så de kommer att köra en sökning så här:
SELECT CustomerID, DeliveryAddressLine2
FROM Sales.Customers
WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
/* This returns two rows:
CustomerID DeliveryAddressLine2
---------- ----------------------
61 1695 Hudecova Avenue
181 1846 Hudecova Crescent
*/ Som du kan förvänta dig måste SQL Server utföra en skanning för att hitta dessa två rader. Vilket borde vara enkelt; Men på grund av tabellens komplexitet ger denna triviala fråga en mycket rörig exekveringsplan (skanningen är markerad och har en varning för kvarvarande I/O):
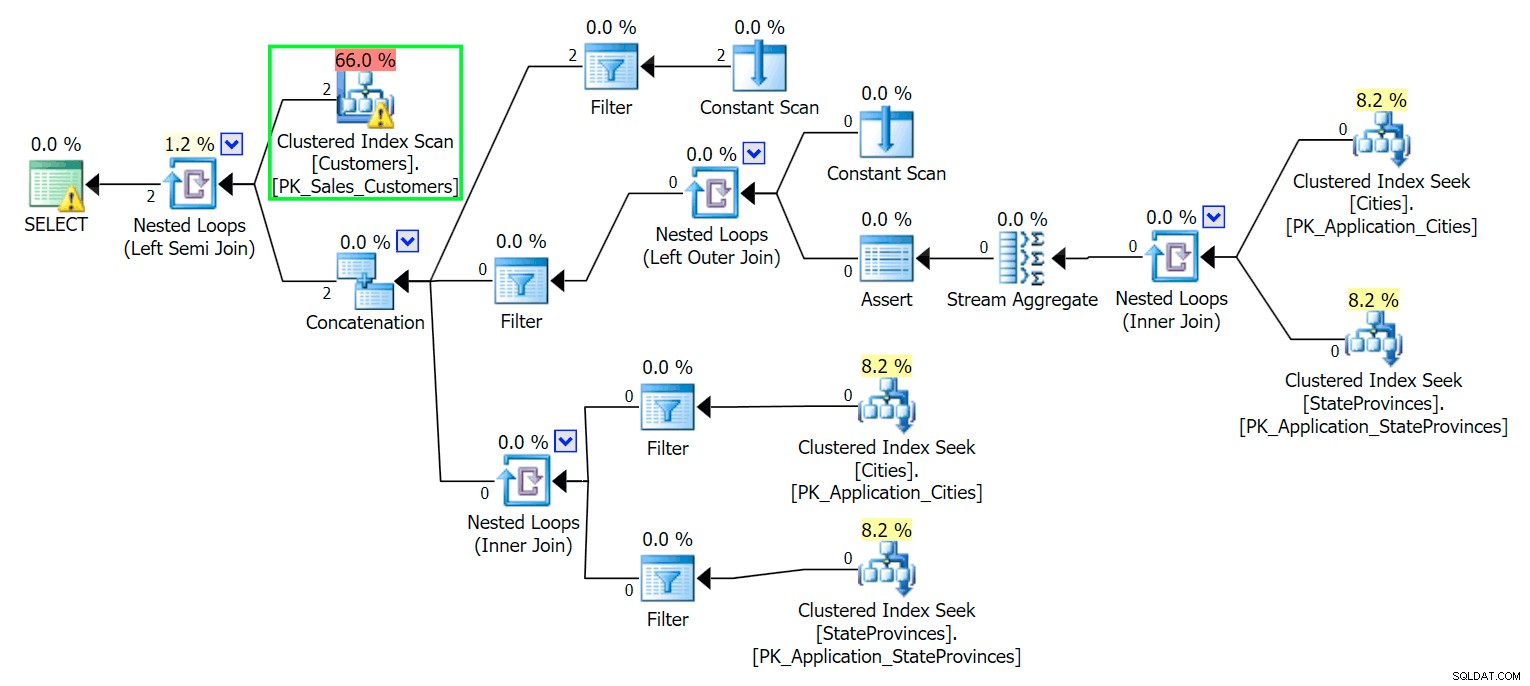
Blecch. För att hålla våra liv enkla, och för att se till att vi inte jagar ett gäng röda sillar, låt oss skapa en ny tabell med en delmängd av kolumnerna, och till att börja med lägger vi bara in samma två rader ovanifrån:
CREATE TABLE Sales.CustomersCopy ( CustomerID int IDENTITY(1,1) CONSTRAINT PK_CustomersCopy PRIMARY KEY, CustomerName nvarchar(100) NOT NULL, DeliveryAddressLine1 nvarchar(60) NOT NULL, DeliveryAddressLine2 nvarchar(60) ); GO INSERT Sales.CustomersCopy ( CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 ) SELECT CustomerName, DeliveryAddressLine1, DeliveryAddressLine2 FROM Sales.Customers WHERE DeliveryAddressLine2 LIKE N'%Hudecova%';
Nu, om vi kör samma fråga som vi körde mot huvudtabellen, får vi något mycket mer rimligt att titta på som utgångspunkt. Detta kommer fortfarande att bli en skanning oavsett vad vi gör – om vi lägger till ett index med DeliveryAddressLine2 som den ledande nyckelkolumnen kommer vi med största sannolikhet att få en indexskanning, med en nyckeluppslagning beroende på om indexet täcker kolumnerna i frågan. Som den är får vi en klustrad indexskanning:
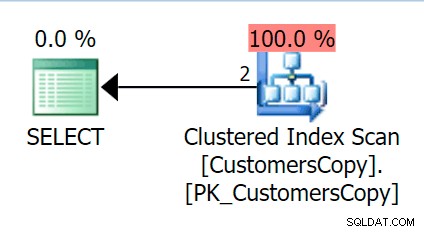
Låt oss sedan skapa en funktion som kommer att "explodera" dessa adressvärden i fragment. Vi förväntar oss 1846 Hudecova Crescent , till exempel för att ha följande uppsättning fragment:
- 1846 Hudecova Crescent
- 846 Hudecova Crescent
- 46 Hudecova Crescent
- 6 Hudecova Crescent
- Hudecova Crescent
- Hudecova Crescent
- udecova Crescent
- decova Crescent
- ecova Crescent
- cova Crescent
- ova Crescent
- va Crescent
- en halvmåne
- Halvmåne
- Halvmåne
- nya
- escent
- doft
- cent
- ent
- nt
- t
Det är ganska trivialt att skriva en funktion som kommer att producera denna utdata – vi behöver bara en rekursiv CTE som kan användas för att gå igenom varje tecken genom hela inmatningen:
CREATE FUNCTION dbo.CreateStringFragments( @input nvarchar(60) )
RETURNS TABLE WITH SCHEMABINDING
AS
RETURN
(
WITH x(x) AS
(
SELECT 1 UNION ALL SELECT x+1 FROM x WHERE x < (LEN(@input))
)
SELECT Fragment = SUBSTRING(@input, x, LEN(@input)) FROM x
);
GO
SELECT Fragment FROM dbo.CreateStringFragments(N'1846 Hudecova Crescent');
-- same output as above bulleted list Låt oss nu skapa en tabell som lagrar alla adressfragment och vilken kund de tillhör:
CREATE TABLE Sales.CustomerAddressFragments ( CustomerID int NOT NULL, Fragment nvarchar(60) NOT NULL, CONSTRAINT FK_Customers FOREIGN KEY(CustomerID) REFERENCES Sales.CustomersCopy(CustomerID) ); CREATE CLUSTERED INDEX s_cat ON Sales.CustomerAddressFragments(Fragment, CustomerID);
Då kan vi fylla i det så här:
INSERT Sales.CustomerAddressFragments(CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f;
För våra två värden infogar detta 42 rader (en adress har 20 tecken och den andra har 22). Nu blir vår fråga:
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
INNER JOIN Sales.CustomerAddressFragments AS f
ON f.CustomerID = c.CustomerID
AND f.Fragment LIKE N'Hudecova%'; Här är en mycket trevligare plan – två klustrade index *söker* och en kapslad loop går samman:
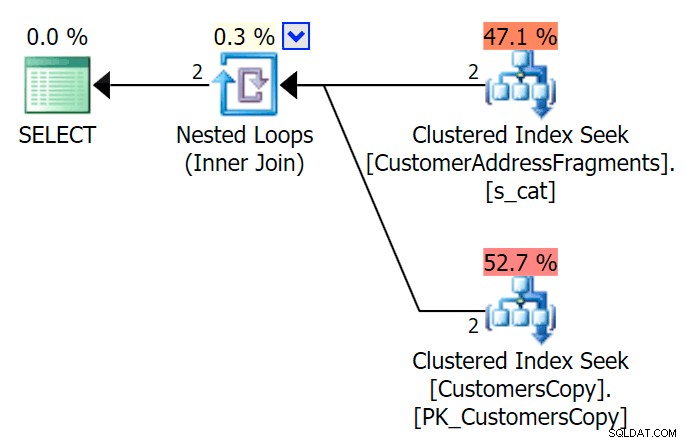
Vi kan också göra detta på ett annat sätt genom att använda EXISTS :
SELECT c.CustomerID, c.DeliveryAddressLine2
FROM Sales.CustomersCopy AS c
WHERE EXISTS
(
SELECT 1 FROM Sales.CustomerAddressFragments
WHERE CustomerID = c.CustomerID
AND Fragment LIKE N'Hudecova%'
); Här är den planen, som på ytan ser ut att vara dyrare – den väljer att skanna tabellen CustomersCopy. Vi kommer snart att se varför detta är den bättre frågemetoden:
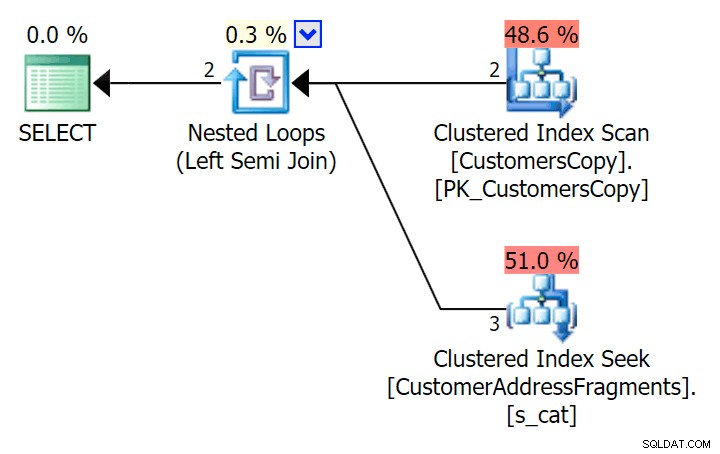
Nu, på denna massiva datamängd med 42 rader, är skillnaderna i varaktighet och I/O så små att de är irrelevanta (och i själva verket, i denna lilla storlek, ser skanningen mot bastabellen billigare ut när det gäller I/O O än de andra två planerna som använder fragmenttabellen):

Tänk om vi skulle fylla dessa tabeller med mycket mer data? Mitt exemplar av Sales.Customers har 663 rader, så om vi korsar sammanfogar det mot sig själv, skulle vi få någonstans nära 440 000 rader. Så låt oss bara blanda ihop 400K och skapa en mycket större tabell:
TRUNCATE TABLE Sales.CustomerAddressFragments; DELETE Sales.CustomersCopy; DBCC FREEPROCCACHE WITH NO_INFOMSGS; INSERT Sales.CustomersCopy WITH (TABLOCKX) (CustomerName, DeliveryAddressLine1, DeliveryAddressLine2) SELECT TOP (400000) c1.CustomerName, c1.DeliveryAddressLine1, c2.DeliveryAddressLine2 FROM Sales.Customers c1 CROSS JOIN Sales.Customers c2 ORDER BY NEWID(); -- fun for distribution -- this will take a bit longer - on my system, ~4 minutes -- probably because I didn't bother to pre-expand files INSERT Sales.CustomerAddressFragments WITH (TABLOCKX) (CustomerID, Fragment) SELECT c.CustomerID, f.Fragment FROM Sales.CustomersCopy AS c CROSS APPLY dbo.CreateStringFragments(c.DeliveryAddressLine2) AS f; -- repeated for compressed version of the table -- 7.25 million rows, 278MB (79MB compressed; saving those tests for another day)
För att nu jämföra prestanda och genomförandeplaner givet en mängd möjliga sökparametrar, testade jag ovanstående tre frågor med dessa predikat:
| Fråga | Predikat | ||||
|---|---|---|---|---|---|
| WHERE DeliveryLineAddress2 GILLAR … | N'%Hudecova%' | N'%cova%' | N'%ova%' | N'%va%' | |
| GÅ MED … VAR Fragment LIKE … | N'Hudecova%' | N'cova%' | N'ova%' | N'va%' | |
| VAR FINNS (… VAR Fragment LIKE …) | |||||
När vi tar bort bokstäver från sökmönstret skulle jag förvänta mig att se fler rader och kanske olika strategier som optimeraren väljer. Låt oss se hur det gick för varje mönster:
Hudecova%
För detta mönster var skanningen fortfarande densamma för LIKE-tillståndet; men med mer data är kostnaden mycket högre. Sökningarna i fragmenttabellen lönar sig verkligen vid detta radantal (1 206), även med riktigt låga uppskattningar. EXISTS-planen lägger till en distinkt sort, som du kan förvänta dig att lägga till kostnaden, men i det här fallet slutar den med att göra färre läsningar:

 Planera för JOIN till fragmenttabellen
Planera för JOIN till fragmenttabellen 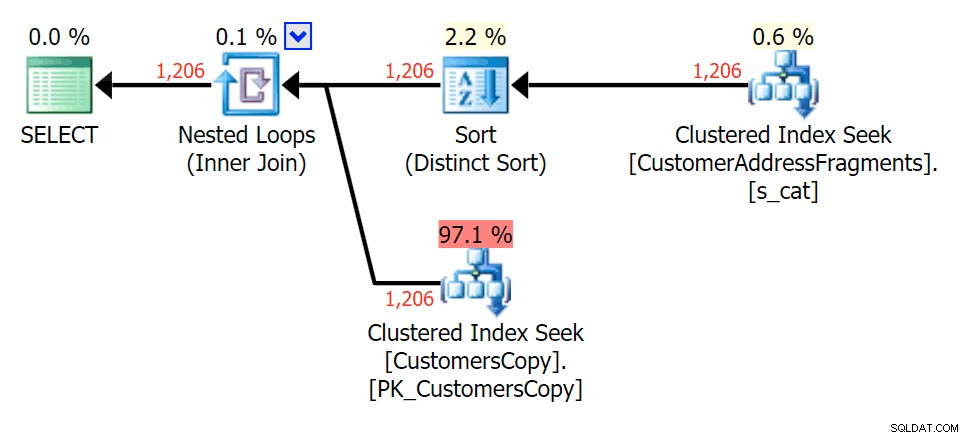 Planera för EXISTS mot fragmenttabellen
Planera för EXISTS mot fragmenttabellen cova%
När vi tar bort några bokstäver från vårt predikat ser vi att läsningarna faktiskt är lite högre än med den ursprungliga klustrade indexskanningen, och nu över -uppskatta raderna. Ändå förblir vår varaktighet betydligt lägre med båda fragmentfrågorna; skillnaden den här gången är mer subtil – båda har sorter (endast FINNS är distinkt):

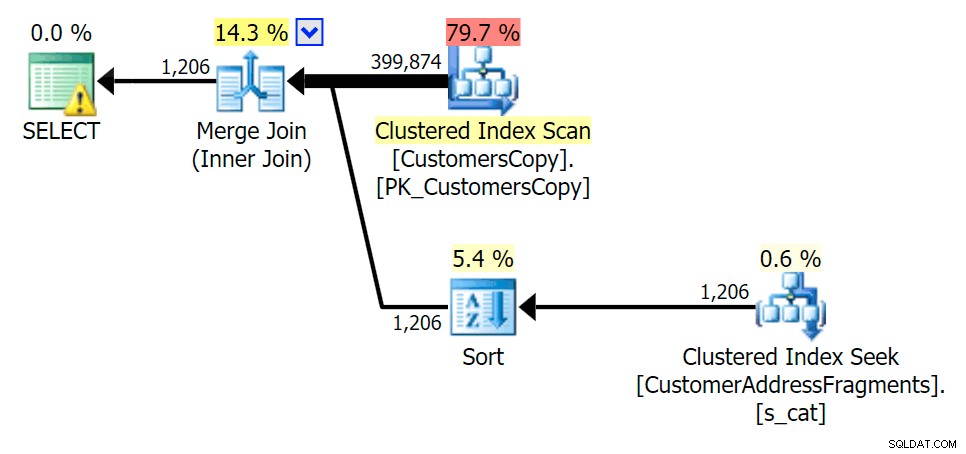 Planera för JOIN till fragmenttabellen
Planera för JOIN till fragmenttabellen 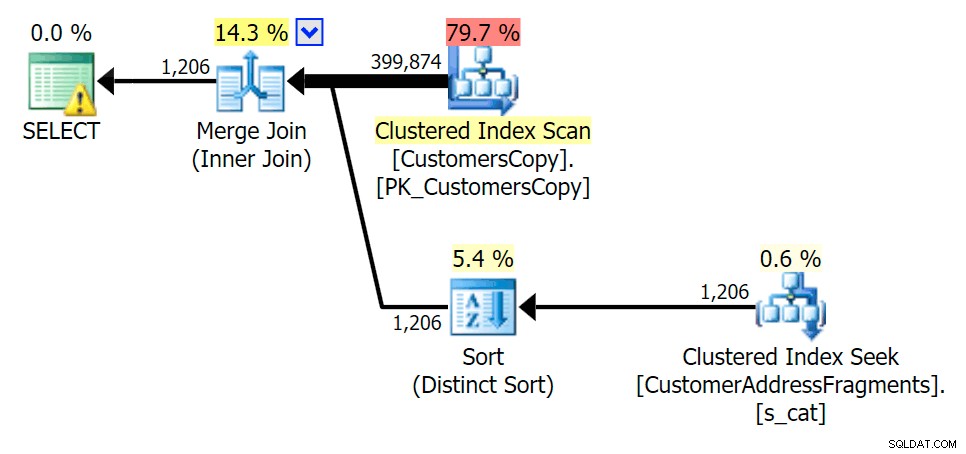 Planera för EXISTS mot fragmenttabellen
Planera för EXISTS mot fragmenttabellen ova%
Att ta bort en extra bokstav ändrade inte mycket; även om det är värt att notera hur mycket de beräknade och faktiska raderna hoppar här – vilket betyder att detta kan vara ett vanligt delsträngmönster. Den ursprungliga LIKE-frågan är fortfarande ganska långsammare än fragmentfrågorna.

 Planera för JOIN till fragmenttabellen
Planera för JOIN till fragmenttabellen 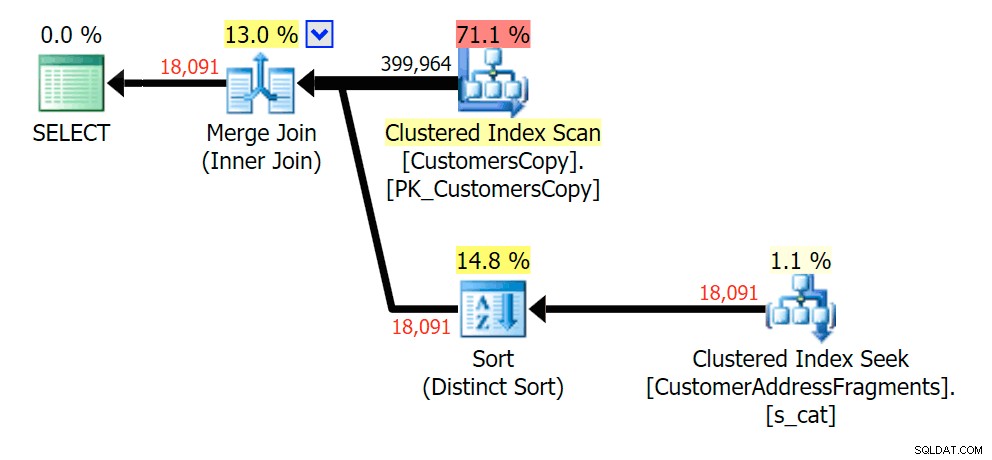 Planera för EXISTS mot fragmenttabellen
Planera för EXISTS mot fragmenttabellen va%
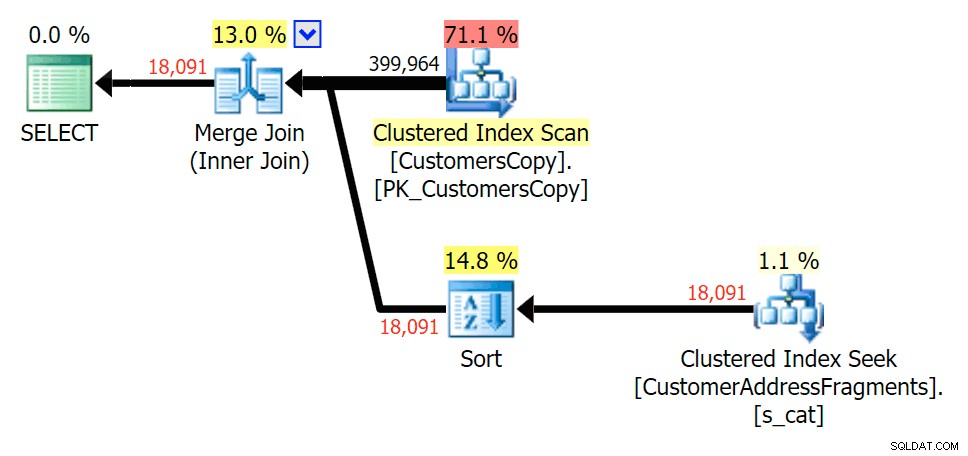
Ned till två bokstäver introducerar detta vår första diskrepans. Lägg märke till att JOIN producerar mer rader än den ursprungliga frågan eller EXISTS. Varför skulle det vara det?

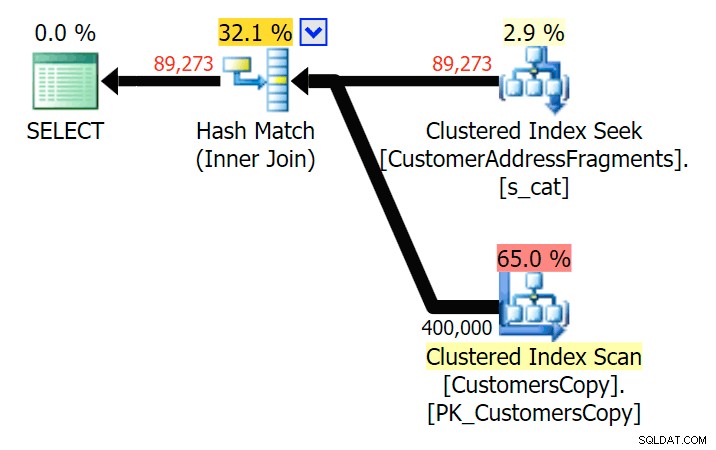 Planera för JOIN till fragmenttabellen
Planera för JOIN till fragmenttabellen 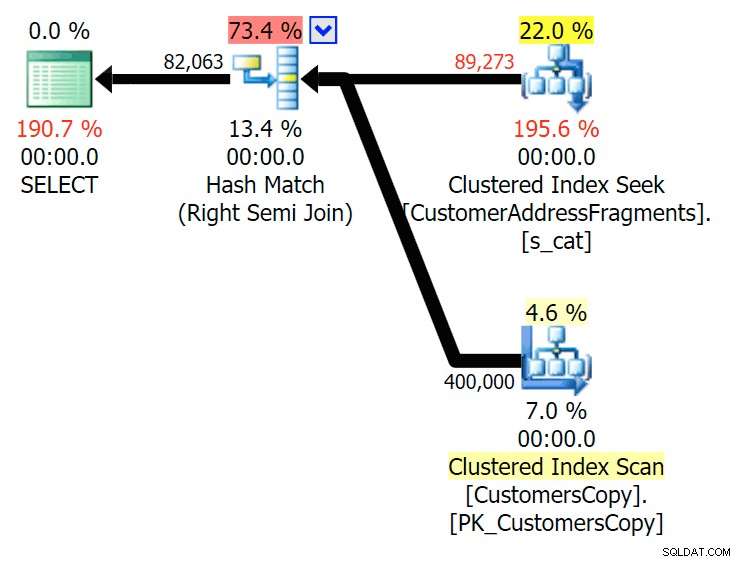 Planera för EXISTS mot fragmenttabellen Vi behöver inte leta långt. Kom ihåg att det finns ett fragment som börjar från varje efterföljande tecken i den ursprungliga adressen, vilket betyder ungefär
Planera för EXISTS mot fragmenttabellen Vi behöver inte leta långt. Kom ihåg att det finns ett fragment som börjar från varje efterföljande tecken i den ursprungliga adressen, vilket betyder ungefär 899 Valentova Road kommer att ha två rader i fragmenttabellen som börjar med va (skiftlägeskänslighet åsido). Så du kommer att matcha på båda Fragment = N'Valentova Road' och Fragment = N'va Road' . Jag ska spara dig sökningen och ge ett enda exempel av många: SELECT TOP (2) c.CustomerID, c.DeliveryAddressLine2, f.Fragment FROM Sales.CustomersCopy AS c INNER JOIN Sales.CustomerAddressFragments AS f ON c.CustomerID = f.CustomerID WHERE f.Fragment LIKE N'va%' AND c.DeliveryAddressLine2 = N'899 Valentova Road' AND f.CustomerID = 351; /* CustomerID DeliveryAddressLine2 Fragment ---------- -------------------- -------------- 351 899 Valentova Road va Road 351 899 Valentova Road Valentova Road */
Detta förklarar lätt varför JOIN producerar fler rader; om du vill matcha utdata från den ursprungliga LIKE-frågan bör du använda EXISTS. Att rätt resultat oftast också går att få på ett mindre resurskrävande sätt är bara en bonus. (Jag skulle vara nervös över att se folk välja JOIN om det var det flera gånger effektivare alternativet – du bör alltid föredra korrekta resultat framför att oroa dig för prestanda.)
Sammanfattning
Det är tydligt att i det här specifika fallet – med en adresskolumn nvarchar(60) och en maxlängd på 26 tecken – att dela upp varje adress i fragment kan ge en viss lättnad för annars dyra "ledande jokertecken"-sökningar. Desto bättre utdelning verkar ske när sökmönstret är större och som ett resultat mer unikt. Jag har också visat varför EXISTS är bättre i scenarier där flera matchningar är möjliga – med en JOIN får du redundant utdata om du inte lägger till någon "största n per grupp"-logik.
Varningar
Jag kommer att vara den första att erkänna att den här lösningen är ofullständig, ofullständig och inte genomarbetad:
- Du måste hålla fragmenttabellen synkroniserad med bastabellen med hjälp av triggers – enklast skulle vara för infogningar och uppdateringar, ta bort alla rader för dessa kunder och infoga dem igen, och för borttagningar tar du självklart bort raderna från fragmenten tabell.
- Som nämnts fungerade den här lösningen bättre för denna specifika datastorlek och kanske inte fungerar så bra för andra stränglängder. Det skulle motivera ytterligare testning för att säkerställa att den är lämplig för din kolumnstorlek, genomsnittliga värdelängd och typiska sökparameterlängd.
- Eftersom vi kommer att ha många kopior av fragment som "Crescent" och "Street" (strålar inte med alla samma eller liknande gatunamn och husnummer), skulle vi kunna normalisera det ytterligare genom att lagra varje unikt fragment i en fragmenttabell, och sedan ännu en tabell som fungerar som en många-till-många-övergångstabell. Det skulle vara mycket mer besvärligt att ställa in, och jag är inte helt säker på att det skulle finnas mycket att vinna.
- Jag har inte helt undersökt sidkomprimering ännu, det verkar som – åtminstone i teorin – detta skulle kunna ge en viss fördel. Jag har också en känsla av att en kolumnbutiksimplementering kan vara fördelaktig i vissa fall också.
Hur som helst, allt som sagt, jag ville bara dela det som en utvecklande idé och be om feedback om dess praktiska funktion för specifika användningsfall. Jag kan gräva i mer detaljer för ett framtida inlägg om du kan berätta för mig vilka aspekter av denna lösning som intresserar dig.