När du behöver arbeta med en databas som du inte är 100% bekant med, kan du bli överväldigad av de hundratals mätvärden som finns tillgängliga. Vilka är de viktigaste? Vad ska jag övervaka och varför? Vilka mönster i mått bör ringa några varningsklockor? I det här blogginlägget kommer vi att försöka introducera dig till några av de viktigaste mätvärdena att hålla ett öga på när du kör MySQL eller MariaDB i produktion.
Com_* Statusräknare
Vi börjar med Com_*-räknare - de definierar antalet och typerna av frågor som MySQL kör. Vi pratar här om frågetyper som SELECT, INSERT, UPDATE och många fler. Det är ganska viktigt att hålla ett öga på dem eftersom plötsliga toppar eller oväntade droppar kan tyda på att något gick fel i systemet.
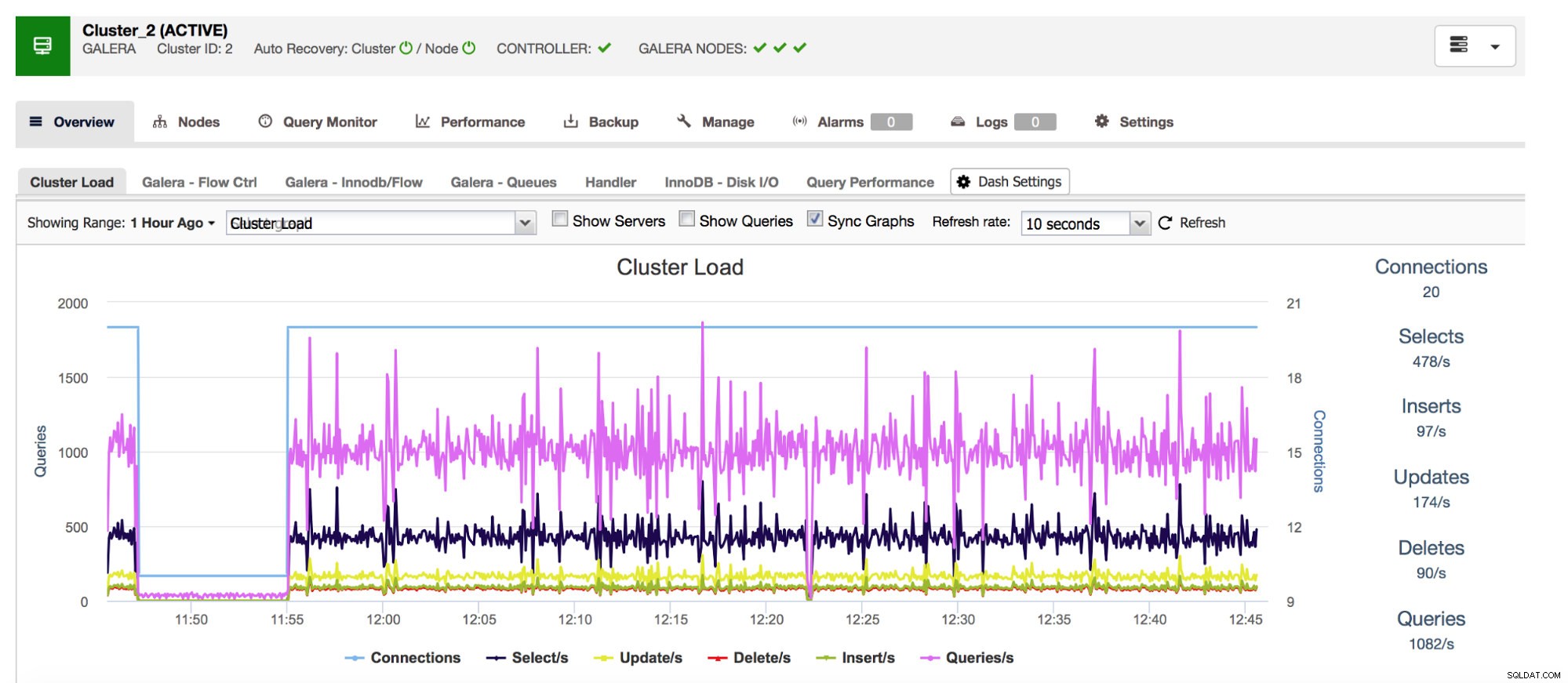
Vårt allomfattande databashanteringssystem ClusterControl visar dig denna data relaterad till de vanligaste frågetyperna i avsnittet "Översikt".
Hanterare_* Statusräknare
En kategori av mätvärden du bör hålla ett öga på är Handler_*-räknare i MySQL. Com_*-räknare talar om för dig vilken typ av frågor din MySQL-instans kör men en SELECT kan vara helt annorlunda från en annan - SELECT kan vara en primärnyckelsökning, det kan också vara en tabellsökning om ett index inte kan användas. Hanterare berättar hur MySQL kommer åt lagrad data - detta är mycket användbart för att undersöka prestandaproblemen och bedöma om det finns en möjlig vinst i fråga om granskning och ytterligare indexering.
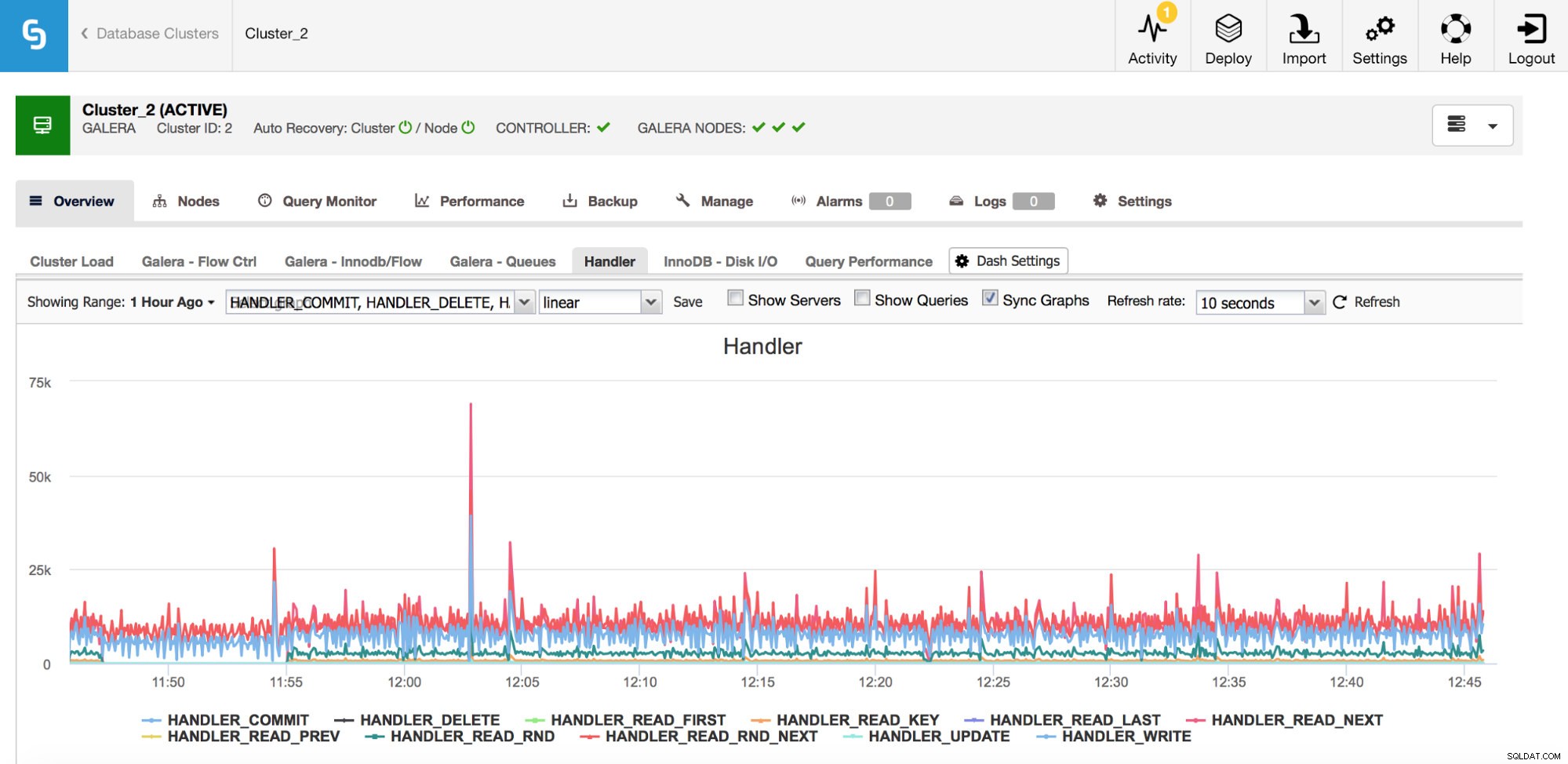
Som du kan se från grafen ovan finns det många mätvärden att spåra (och ClusterControl-graferna är de viktigaste) - vi kommer inte att täcka dem alla här (du kan hitta beskrivningar i MySQL-dokumentationen) men vi vill lyfta fram de viktigaste.
Handler_read_rnd_next - när MySQL kommer åt en rad utan en indexuppslagning, i sekventiell ordning, kommer denna räknare att ökas. Om i din arbetsbelastning handler_read_rnd_next är ansvarig för en hög andel av hela trafiken, betyder det att dina tabeller troligen kan använda några ytterligare index eftersom MySQL gör många tabellsökningar.
Handler_read_next och handler_read_prev - dessa två räknare uppdateras när MySQL gör en indexskanning - framåt eller bakåt. Handler_read_first och handler_read_last kan kasta lite mer ljus över vilken typ av indexsökning det är - om vi pratar om fullständig indexsökning (framåt eller bakåt), kommer dessa två räknare att uppdateras.
Handler_read_key - den här räknaren, å andra sidan, om dess värde är högt, talar om för dig att dina tabeller är väl indexerade eftersom många av raderna nåddes genom en indexsökning.
Replikeringsfördröjning
Om du arbetar med MySQL-replikering är replikeringsfördröjning ett mått du definitivt vill övervaka. Replikeringsfördröjning är oundviklig och du kommer att behöva hantera det, men för att hantera det måste du förstå varför det händer. För det är det första steget att veta _när_ den dök upp.
När du ser en ökning av replikeringsfördröjningen, skulle du vilja kolla andra grafer för att få fler ledtrådar - varför har det hänt? Vad kan ha orsakat det? Orsakerna kan vara olika - långa, tunga DML:er, betydande ökning av antalet DML:er som körs under en kort tidsperiod, CPU- eller I/O-begränsningar.
InnoDB I/O
Det finns ett antal viktiga mätvärden för att övervaka som är relaterade till I/O.
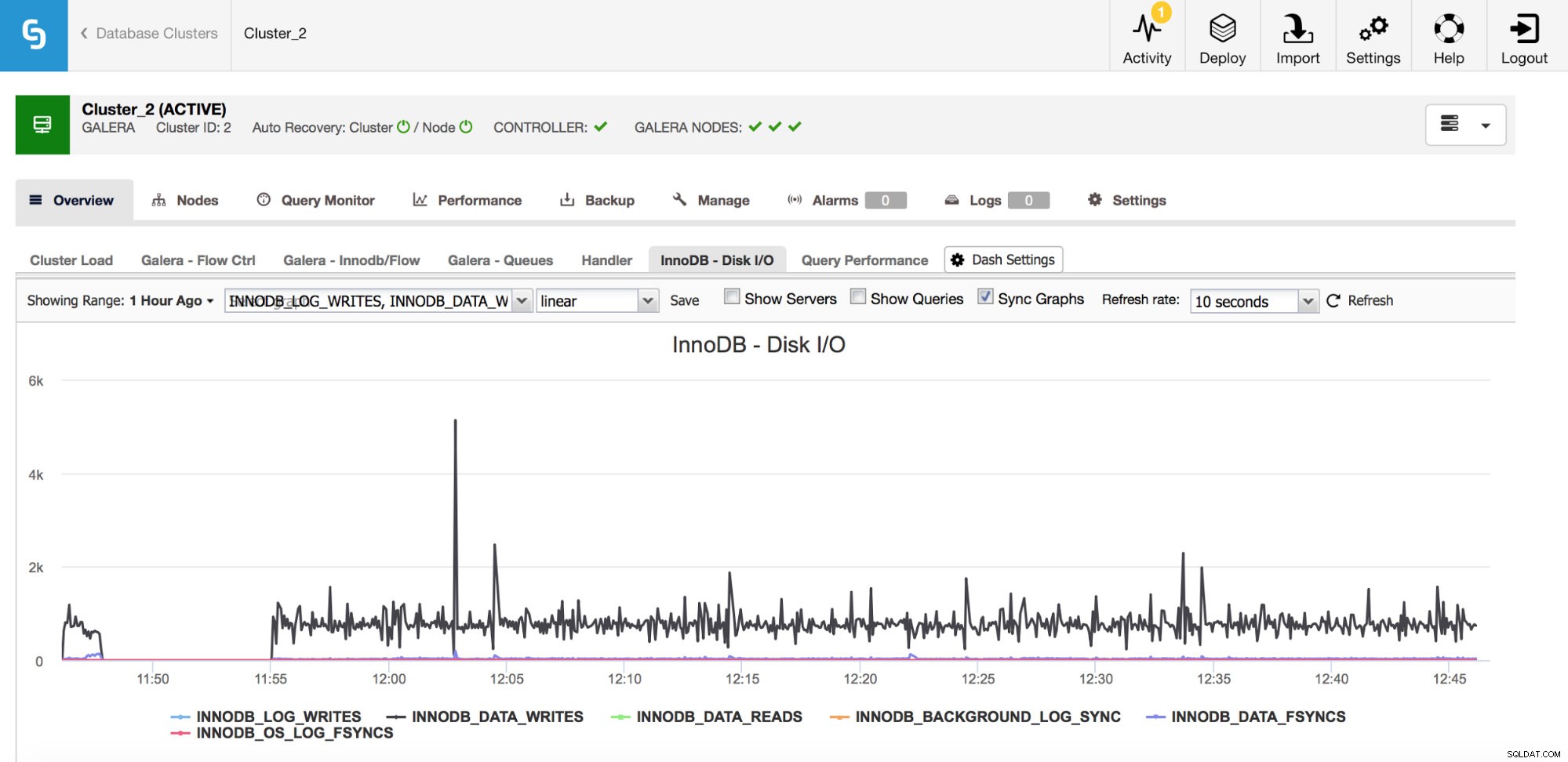
I grafen ovan kan du se ett par mätvärden som berättar vilken typ av I/O InnoDB gör - data skriver och läser, gör om loggskrivningar, fsyncs. Dessa mätvärden hjälper dig att till exempel avgöra om replikeringsfördröjningen orsakades av en topp i I/O eller kanske av någon annan anledning. Det är också viktigt att hålla reda på dessa mätvärden och jämföra dem med dina hårdvarubegränsningar - om du närmar dig hårdvarugränserna för dina diskar, kanske det är dags att undersöka detta innan det får mer allvarliga effekter på din databasprestanda.
Severalnines DevOps Guide to Database ManagementLär dig om vad du behöver veta för att automatisera och hantera dina databaser med öppen källkod Ladda ner gratisGalerastatistik - Flödeskontroll och köer
Om du råkar använda Galera Cluster (oavsett vilken smak du använder), finns det ytterligare ett par mätvärden du skulle vilja övervaka noga, dessa är något sammankopplade. Först av dem är mätvärden relaterade till flödeskontroll.
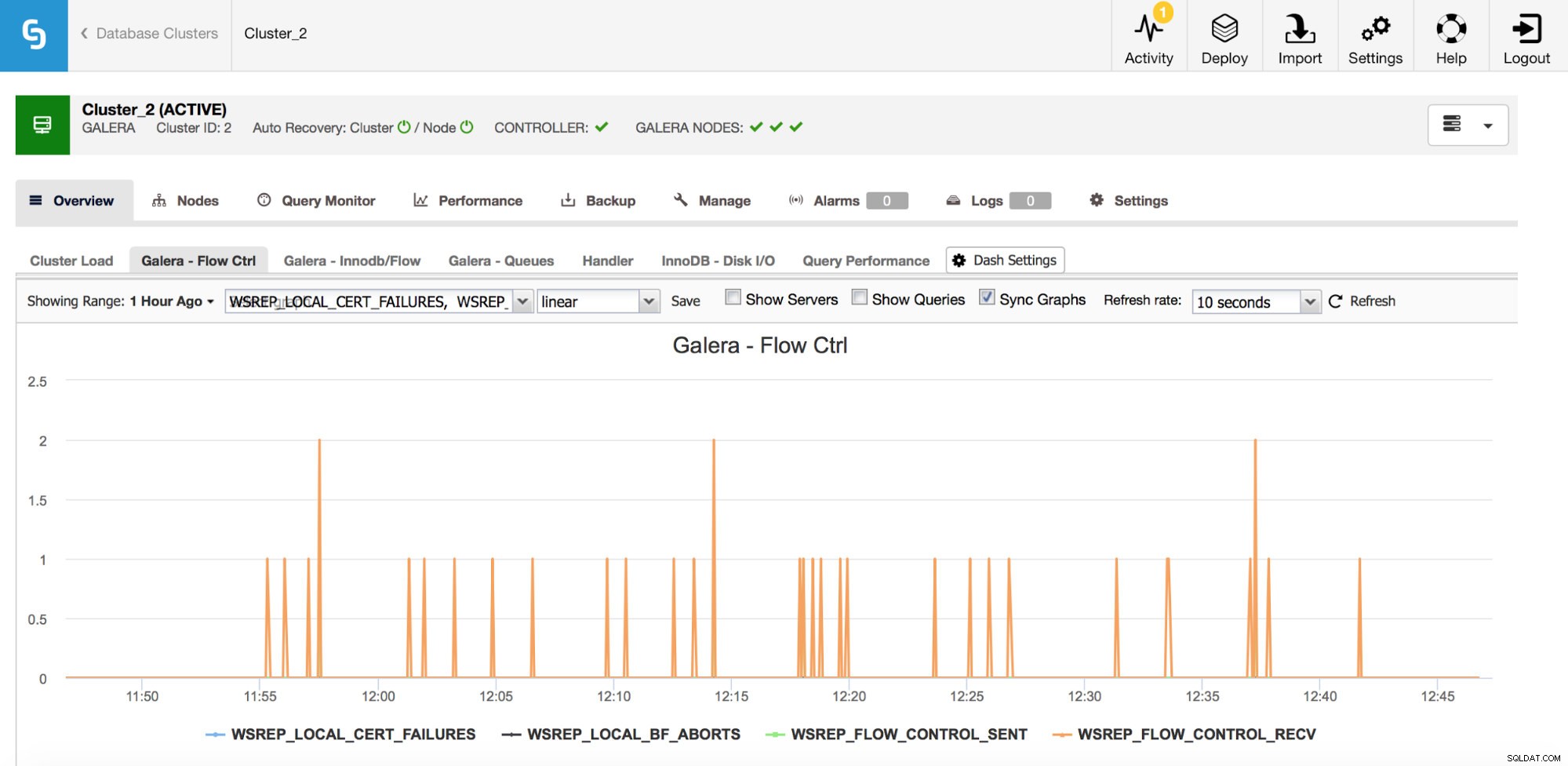
Flödeskontroll, i Galera, är ett sätt att hålla klustret synkroniserat. Närhelst en nod stannar och inte kan hänga med resten av klustret, börjar den skicka flödeskontrollmeddelanden som ber de återstående klusternoderna att sakta ner. Detta gör att den kan komma ikapp. Detta minskar klustrets prestanda, så det är viktigt att kunna avgöra vilken nod och när den började skicka flödeskontrollmeddelanden. Detta kan förklara några av de nedgångar som användarna upplevt eller begränsa tidsfönstret och värddatorn att använda för vidare undersökning.
Den andra uppsättningen mätvärden att övervaka är de som är relaterade till sändnings- och mottagningsköer i Galera.
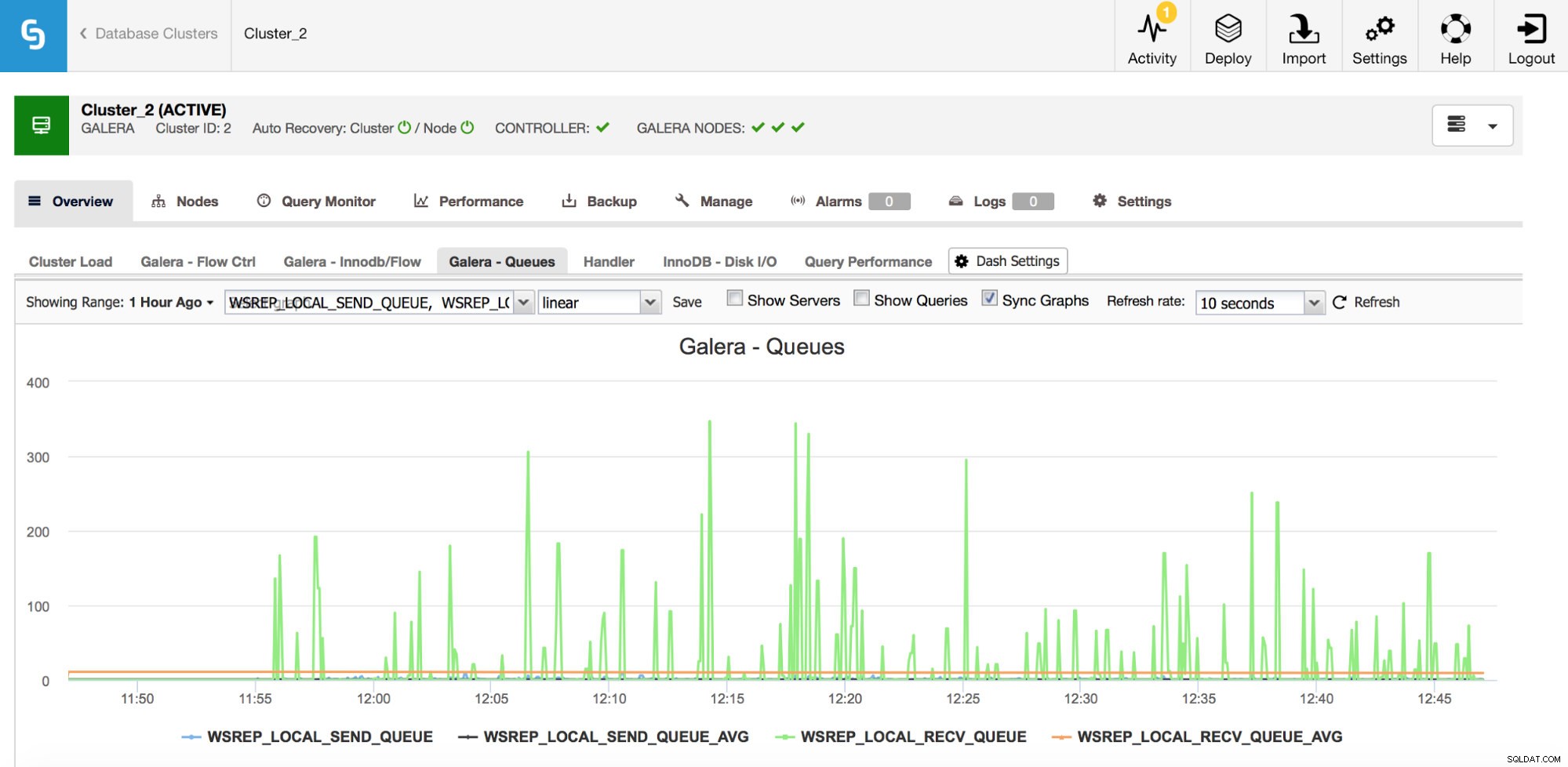
Galera-noder kan cache-skrivuppsättningar (transaktioner) om de inte kan tillämpa alla omedelbart. Vid behov kan de även cache-skrivuppsättningar som är på väg att skickas till andra noder (om en given nod tar emot skrivningar från applikationen). Båda fallen är symtom på en avmattning som med största sannolikhet kommer att leda till att flödeskontrollmeddelanden skickas och kräver en viss utredning - varför det hände, på vilken nod, vid vilken tidpunkt?
Detta är naturligtvis bara toppen av isberget när vi tar hänsyn till alla mätvärden som MySQL gör tillgänglig - ändå kan du inte gå fel om du börjar titta på dem vi täckte här, förutom vanliga OS/hårdvarumått som CPU , minne, diskanvändning och tillstånd för tjänsterna.