Introduktion
Nyligen stötte vi på ett intressant prestandaproblem på en av våra SQL Server-databaser som behandlar transaktioner i en allvarlig takt. Transaktionstabellen som användes för att fånga dessa transaktioner blev ett hett bord. Som ett resultat dök problemet upp i applikationslagret. Det var en intermittent timeout för sessionen som försökte lägga upp transaktioner.
Detta hände eftersom en session vanligtvis skulle "hålla fast" vid bordet och orsaka en serie falska låsningar i databasen.
Den första reaktionen från en typisk databasadministratör skulle vara att identifiera den primära blockeringssessionen och avsluta den på ett säkert sätt. Detta var säkert eftersom det vanligtvis var en SELECT-sats eller en inaktiv session.
Det gjordes även andra försök att lösa problemet:
- Renar bordet. Detta förväntades ge bra prestanda även om frågan var tvungen att skanna en hel tabell.
- Aktivera isoleringsnivån READ COMMITTED SNAPSHOT för att minska effekten av blockerande sessioner.
I den här artikeln ska vi försöka återskapa en förenklad version av scenariot och använda den för att visa hur enkel indexering kan hantera situationer som denna när den görs rätt.
Två relaterade tabeller
Ta en titt på Lista 1 och Lista 2. De visar de förenklade versionerna av tabeller som är involverade i det aktuella scenariot.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Lista 3 visar en utlösare som infogar fyra rader i TranDetails tabell för varje rad som infogas i TranLog bord.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Gå med i fråga
Det är typiskt att hitta transaktionstabeller som stöds av stora tabeller. Syftet är att behålla mycket äldre transaktioner eller att lagra detaljerna i poster som sammanfattas i den första tabellen. Se det här som beställningar och beställningsinformation tabeller som är typiska i SQL Server-exempeldatabaser. I vårt fall överväger vi TranLog och TranDetails tabeller.
Under normala omständigheter fyller transaktioner dessa två tabeller över tid. När det gäller rapportering eller enkla frågor, kommer frågan att utföra en koppling på dessa två tabeller. Denna koppling kommer att dra nytta av en gemensam kolumn mellan tabellerna.
Först fyller vi i tabellen med hjälp av frågan i Listing 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
I vårt exempel är den vanliga kolumnen som används av kopplingen TranID kolumn:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Du kan se de två enkla exempelfrågorna som använder en join för att hämta poster från TranLog och TranDetails .
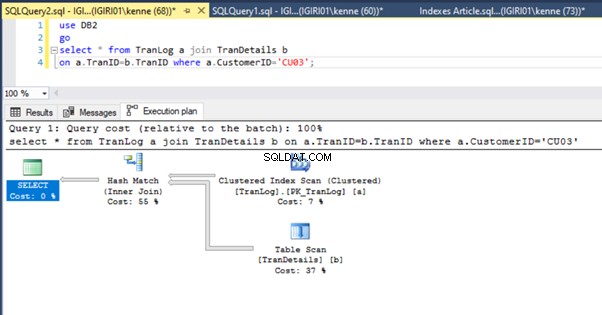
När vi kör frågorna i Lista 5 måste vi i båda fallen göra en fullständig tabellskanning på båda tabellerna (se figurerna 1 och 2). Den dominerande delen av varje fråga är de fysiska operationerna. Båda är inre sammanfogningar. Lista 5a använder dock en Hash Match gå med, medan listning 5b använder en Inkapslad loop Ansluta sig. Obs! Lista 5a returnerar 4000 rader medan lista 4b returnerar 4 rader.
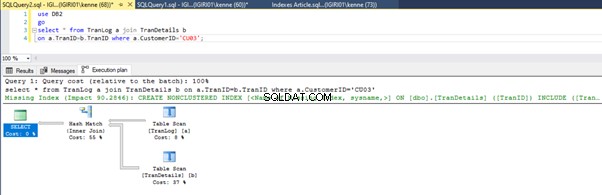
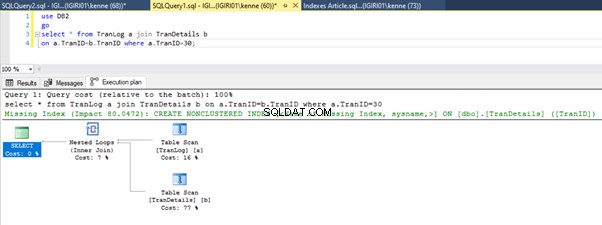
Tre steg för prestandajustering
Den första optimeringen vi gör är att introducera ett index (en primärnyckel, för att vara exakt) på TranID kolumnen i TranLog tabell:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
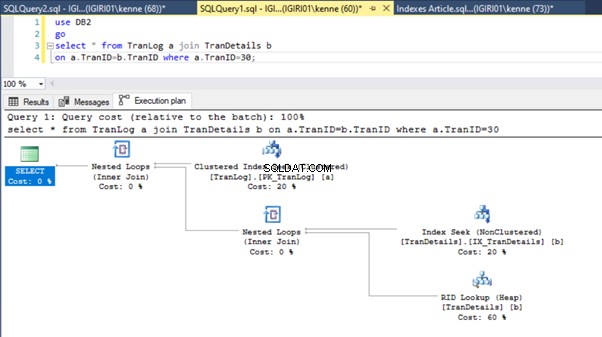
Figurerna 3 och 4 visar att SQL Server använder detta index i båda frågorna och gör en skanning i Lista 5a och en sökning i Lista 5b.
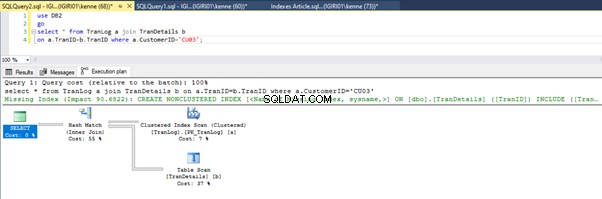
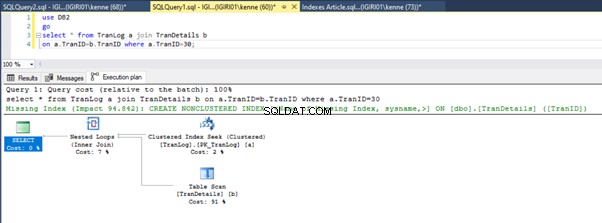
Vi har ett indexsök i notering 5b. Det händer på grund av kolumnen som är involverad i WHERE-satspredikatet – TranID. Det är den kolumnen vi har använt ett index på.
Därefter introducerar vi en främmande nyckel på TranID kolumnen i TranDetails tabell (lista 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Detta förändrar inte mycket i utförandeplanen. Situationen är praktiskt taget densamma som visats tidigare i figurerna 3 och 4.
Sedan introducerar vi ett index på kolumnen för främmande nyckel:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
Denna åtgärd förändrar genomförandeplanen för notering 5b dramatiskt (se figur 6). Vi ser att fler index försöker hända. Lägg också märke till RID-uppslagningen i figur 6.
RID-sökningar på högar sker vanligtvis i frånvaro av en primärnyckel. En heap är en tabell utan primärnyckel.
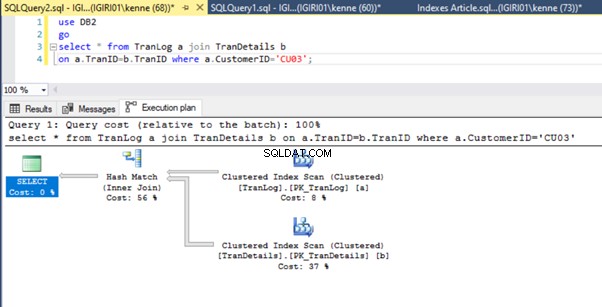
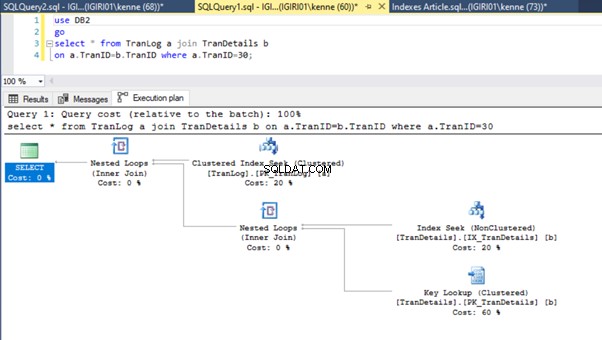
Slutligen lägger vi till en primärnyckel till TranDetails tabell. Detta tar bort tabellskanningen och RID-högsökningen i listorna 5a respektive 5b (se figurerna 7 och 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Slutsats
Den prestandaförbättring som introduceras av index är välkänd för även nybörjare på DBA. Vi vill dock påpeka att du måste titta noga på hur frågor använder index.
Dessutom är tanken att etablera lösningen i det speciella fallet där vi har kopplingsfrågor mellan Transaktionslogg tabeller och Transaktionsdetaljer tabeller.
Det är i allmänhet vettigt att upprätthålla förhållandet mellan sådana tabeller med hjälp av en nyckel och introducera index till primär- och främmande nyckelkolumnerna.
Vid utveckling av applikationer som använder en sådan design, bör utvecklare ha i åtanke de nödvändiga indexen och relationerna på designstadiet. Moderna verktyg för SQL Server-specialister gör dessa krav mycket lättare att uppfylla. Du kan profilera dina frågor med hjälp av det specialiserade verktyget Query Profiler. Det är en del av den professionella lösningen med flera funktioner dbForge Studio for SQL Server utvecklad av Devart för att göra livet för DBA enklare.