I del 1 och del 2 av den här serien täckte jag de logiska, eller konceptuella, aspekterna av namngivna tabelluttryck i allmänhet, och härledda tabeller specifikt. Den här månaden och nästa kommer jag att täcka de fysiska bearbetningsaspekterna av härledda tabeller. Kom ihåg från del 1 fysisk dataoberoende principen för relationsteorin. Relationsmodellen och standardfrågespråket som är baserat på det är tänkt att endast behandla de konceptuella aspekterna av data och lämna de fysiska implementeringsdetaljerna som lagring, optimering, åtkomst och bearbetning av data till databasplattformen (implementering ). Till skillnad från den konceptuella behandlingen av data som är baserad på en matematisk modell och ett standardspråk, och därför är väldigt lika i de olika relationsdatabashanteringssystemen där ute, är den fysiska behandlingen av data inte baserad på någon standard, och tenderar därför att att vara väldigt plattformsspecifik. I min bevakning av den fysiska behandlingen av namngivna tabelluttryck i serien fokuserar jag på behandlingen i Microsoft SQL Server och Azure SQL Database. Den fysiska behandlingen i andra databasplattformar kan vara ganska annorlunda.
Kom ihåg att det som utlöste den här serien är viss förvirring som finns i SQL Server-gemenskapen kring namngivna tabelluttryck. Både vad gäller terminologi och vad gäller optimering. Jag tog upp några terminologiska överväganden i de två första delarna av serien och kommer att ta upp mer i framtida artiklar när jag diskuterar CTEs, åsikter och inline TVFs. När det gäller optimering av namngivna tabelluttryck finns det förvirring kring följande objekt (jag nämner härledda tabeller här eftersom det är fokus i den här artikeln):
- Ihärdighet: Finns en härledd tabell kvar någonstans? Blir det kvar på disken, och hur hanterar SQL Server minnet för det?
- Kolumnprojektion: Hur fungerar indexmatchning med härledda tabeller? Till exempel, om en härledd tabell projicerar en viss delmängd av kolumner från någon underliggande tabell, och den yttersta frågan projicerar en delmängd av kolumnerna från den härledda tabellen, är SQL Server smart nog att räkna ut optimal indexering baserat på den slutliga delmängden av kolumner behövs det egentligen? Och hur är det med behörigheter; behöver användaren behörighet till alla kolumner som refereras till i de inre frågorna, eller bara till de sista som faktiskt behövs?
- Flera referenser till kolumnalias: Om den härledda tabellen har en resultatkolumn som är baserad på en icke-deterministisk beräkning, t.ex. ett anrop till funktionen SYSDATETIME, och den yttre frågan har flera referenser till den kolumnen, kommer beräkningen att göras endast en gång eller separat för varje yttre referens ?
- Unnesting/substitution/inlining: Avlägsnar eller infogas SQL Server den härledda tabellfrågan? Det vill säga, utför SQL Server en substitutionsprocess där den konverterar den ursprungliga kapslade koden till en fråga som går direkt mot bastabellerna? Och om så är fallet, finns det något sätt att instruera SQL Server att undvika den här odlande processen?
Dessa är alla viktiga frågor och svaren på dessa frågor har betydande prestandaimplikationer, så det är en bra idé att ha en tydlig förståelse för hur dessa objekt hanteras i SQL Server. Den här månaden ska jag ta upp de tre första punkterna. Det finns ganska mycket att säga om det fjärde objektet så jag kommer att ägna en separat artikel till det nästa månad (del 4).
I mina exempel kommer jag att använda en exempeldatabas som heter TSQLV5. Du kan hitta skriptet som skapar och fyller i TSQLV5 här, och dess ER-diagram här.
Ihärdighet
Vissa människor antar intuitivt att SQL Server kvarstår resultatet av tabelluttrycksdelen av den härledda tabellen (den inre frågans resultat) i en arbetstabell. När detta skrivs är det inte fallet; Men eftersom uthållighetsöverväganden är en leverantörs val kan Microsoft besluta att ändra detta i framtiden. Faktum är att SQL Server kan bevara mellanliggande frågeresultat i arbetstabeller (vanligtvis i tempdb) som en del av frågebehandlingen. Om den väljer att göra det ser du någon form av en spool-operatör i planen (Spool, Eager Spool, Lazy Spool, Table Spool, Index Spool, Window Spool, Row Count Spool). Men SQL Servers val om att spoola något i en arbetstabell eller inte har för närvarande inget att göra med din användning av namngivna tabelluttryck i frågan. SQL Server spolar ibland mellanresultat av prestandaskäl, som att undvika upprepat arbete (även om det för närvarande inte är relaterat till användningen av namngivna tabelluttryck), och ibland av andra skäl, som Halloween-skydd.
Som nämnts, nästa månad kommer jag att gå in på detaljerna om odling av härledda tabeller. Tills vidare räcker det med att säga att SQL Server normalt tillämpar en avvecklings-/inlinningsprocess på härledda tabeller, där den ersätter de kapslade frågorna med en fråga mot de underliggande bastabellerna. Tja, jag förenklar lite. Det är inte som att SQL Server bokstavligen konverterar den ursprungliga T-SQL-frågesträngen med de härledda tabellerna till en ny frågesträng utan dessa; SQL Server tillämpar snarare transformationer på ett internt logiskt träd av operatörer, och resultatet är att de härledda tabellerna vanligtvis blir okapslade. När du tittar på en exekveringsplan för en fråga som involverar härledda tabeller, ser du inget omnämnande av dessa eftersom de för de flesta optimeringsändamål inte existerar. Du ser tillgång till de fysiska strukturerna som innehåller data för de underliggande bastabellerna (heap, B-tree rowstore index och columnstore index för diskbaserade tabeller och träd och hash index för minnesoptimerade tabeller).
Det finns fall som hindrar SQL Server från att hämma en härledd tabell, men även i de fallen kvarstår inte SQL Server tabelluttryckets resultat i en arbetstabell. Jag kommer att ge detaljerna tillsammans med exempel nästa månad.
Eftersom SQL Server inte består av härledda tabeller, snarare interagerar direkt med de fysiska strukturerna som innehåller data för de underliggande bastabellerna, är frågan om hur minnet hanteras för härledda tabeller oklart. Om de underliggande bastabellerna är diskbaserade, måste deras relevanta sidor bearbetas i buffertpoolen. Om de underliggande tabellerna är minnesoptimerade måste deras relevanta rader i minnet bearbetas. Men det är inte annorlunda än när du frågar de underliggande tabellerna direkt själv utan att använda härledda tabeller. Så det är inget speciellt här. När du använder härledda tabeller behöver SQL Server inte tillämpa några speciella minnesöverväganden för dessa. För de flesta frågeoptimeringsändamål finns de inte.
Om du har ett fall där du behöver bevara något mellanstegs resultat i en arbetstabell, måste du använda temporära tabeller eller tabellvariabler – inte namngivna tabelluttryck.
Kolumnprojektion och ett ord på SELECT *
Projektion är en av de ursprungliga operatorerna för relationalgebra. Anta att du har en relation R1 med attributen x, y och z. Projektionen av R1 på någon delmängd av dess attribut, t.ex. x och z, är en ny relation R2, vars rubrik är delmängden av projicerade attribut från R1 (x och z i vårt fall), och vars kropp är uppsättningen av tupler bildad från den ursprungliga kombinationen av projicerade attributvärden från R1:s tupler.
Kom ihåg att en relations kropp - som är en uppsättning tuplar - per definition inte har några dubbletter. Så det säger sig självt att resultatrelationens tuplar är den distinkta kombinationen av attributvärden som projiceras från den ursprungliga relationen. Kom dock ihåg att brödtexten i en tabell i SQL är en multiuppsättning av rader och inte en uppsättning, och normalt kommer SQL inte att eliminera dubbletter av rader om du inte instruerar det. Givet en tabell R1 med kolumnerna x, y och z kan följande fråga potentiellt returnera dubbla rader och följer därför inte relationalgebras projektionsoperators semantik för att returnera en uppsättning:
SELECT x, z FROM R1;
Genom att lägga till en DISTINCT-sats eliminerar du dubbletter av rader och följer noggrannare semantiken för relationsprojektion:
SELECT DISTINCT x, z FROM R1;
Naturligtvis finns det vissa fall där du vet att resultatet av din fråga har distinkta rader utan behov av en DISTINCT-sats, t.ex. när en delmängd av kolumnerna som du returnerar inkluderar en nyckel från den efterfrågade tabellen. Till exempel, om x är en nyckel i R1, är ovanstående två frågor logiskt ekvivalenta.
Minns i alla fall de frågor jag nämnde tidigare kring optimering av frågor som involverar härledda tabeller och kolumnprojektion. Hur fungerar indexmatchning? Om en härledd tabell projicerar en viss delmängd av kolumner från någon underliggande tabell, och den yttersta frågan projicerar en delmängd av kolumnerna från den härledda tabellen, är SQL Server smart nog att räkna ut optimal indexering baserat på den slutliga delmängden av kolumner som faktiskt är behövs? Och hur är det med behörigheter; behöver användaren behörighet till alla kolumner som refereras till i de inre frågorna, eller bara till de sista som faktiskt behövs? Anta också att tabelluttrycksfrågan definierar en resultatkolumn som är baserad på en beräkning, men den yttre frågan projicerar inte den kolumnen. Utvärderas beräkningen överhuvudtaget?
Börja med den sista frågan, låt oss prova den. Tänk på följande fråga:
USE TSQLV5; GO SELECT custid, city, 1/0 AS div0error FROM Sales.Customers;
Som du kan förvänta dig misslyckas denna fråga med ett divideringsfel med noll:
Msg 8134, Level 16, State 1Dela med noll fel påträffat.
Definiera sedan en härledd tabell som heter D baserat på ovanstående fråga, och i den yttre frågan projektera D på endast custid och stad, som så:
SELECT custid, city
FROM ( SELECT custid, city, 1/0 AS div0error
FROM Sales.Customers ) AS D; Som nämnts tillämpar SQL Server normalt avkapsling/ersättning, och eftersom det inte finns något i den här frågan som förhindrar upplösning (mer om detta nästa månad), är ovanstående fråga likvärdig med följande fråga:
SELECT custid, city FROM Sales.Customers;
Återigen, jag förenklar lite här. Verkligheten är lite mer komplex än att dessa två frågor anses vara riktigt identiska, men jag kommer till de komplexiteten nästa månad. Poängen är att uttrycket 1/0 inte ens dyker upp i frågans exekveringsplan och utvärderas inte alls, så ovanstående fråga körs utan fel.
Tabelluttrycket måste ändå vara giltigt. Tänk till exempel på följande fråga:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Även om den yttre frågan endast projicerar en kolumn från den inre frågans grupperingsuppsättning, är den inre frågan inte giltig eftersom den försöker returnera kolumner som varken ingår i grupperingsuppsättningen eller ingår i en aggregerad funktion. Den här frågan misslyckas med följande fel:
Msg 8120, Level 16, State 1Kolumnen 'Sales.Customers.custid' är ogiltig i urvalslistan eftersom den inte finns i vare sig en aggregatfunktion eller GROUP BY-satsen.
Låt oss sedan ta itu med indexmatchningsfrågan. Om den yttre frågan projicerar endast en delmängd av kolumnerna från den härledda tabellen, kommer SQL Server att vara smart nog att göra indexmatchning baserat på endast de returnerade kolumnerna (och naturligtvis alla andra kolumner som annars spelar en meningsfull roll, såsom filtrering, gruppering och så vidare)? Men innan vi tar itu med den här frågan kanske du undrar varför vi ens stör oss på den. Varför skulle du ha de inre frågans returkolumner som den yttre frågan inte behöver?
Svaret är enkelt, att förkorta koden genom att låta den inre frågan använda den ökända SELECT *. Vi vet alla att det är en dålig praxis att använda SELECT *, men det är fallet främst när det används i den yttersta frågan. Vad händer om du frågar efter en tabell med en viss rubrik, och senare ändras den rubriken? Applikationen kan sluta med buggar. Även om du inte får buggar, kan det sluta med att du genererar onödig nätverkstrafik genom att returnera kolumner som programmet egentligen inte behöver. Dessutom använder du indexering mindre optimalt i ett sådant fall eftersom du minskar chansen att matcha täckande index som är baserade på de verkligen nödvändiga kolumnerna.
Som sagt, jag känner mig faktiskt ganska bekväm med att använda SELECT * i ett tabelluttryck, med vetskapen om att jag ändå bara kommer att projicera de verkligt nödvändiga kolumnerna i den yttersta frågan. Ur en logisk synvinkel är det ganska säkert med några mindre varningar som jag kommer till inom kort. Det är så länge som indexmatchning görs optimalt i ett sådant fall, och de goda nyheterna är det.
För att visa detta, anta att du behöver fråga i tabellen Sales.Orders och returnera de tre senaste beställningarna för varje kund. Du planerar att definiera en härledd tabell som heter D baserat på en fråga som beräknar radnummer (resultatkolumn rownum) som är uppdelade av custid och ordnade efter orderdate DESC, orderid DESC. Den yttre frågan kommer att filtrera från D (relationell restriktion ) endast de rader där rownum är mindre än eller lika med 3, och projicera D på custid, orderdate, orderid och rownum. Nu har Sales.Orders fler kolumner än de som du behöver projicera, men för korthetens skull vill du att den inre frågan ska använda SELECT * plus radnummerberäkningen. Det är säkert och kommer att hanteras optimalt när det gäller indexmatchning.
Använd till följande kod för att skapa det optimala täckande indexet för att stödja din fråga:
CREATE INDEX idx_custid_odD_oidD ON Sales.Orders(custid, orderdate DESC, orderid DESC);
Här är frågan som arkiverar uppgiften (vi kallar den fråga 1):
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Lägg märke till den inre frågans SELECT * och den yttre frågans explicita kolumnlista.
Planen för den här frågan, som återges av SentryOne Plan Explorer, visas i figur 1.
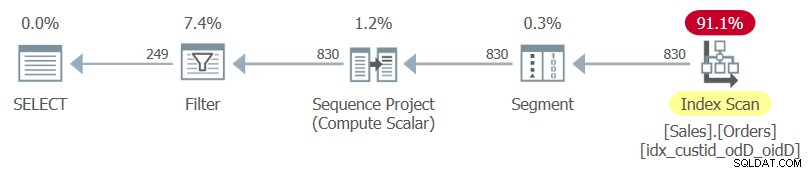 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Observera att det enda index som används i denna plan är det optimala täckande index som du just skapat.
Om du bara markerar den inre frågan och undersöker dess exekveringsplan, kommer du att se tabellens klustrade index som används följt av en sorteringsoperation.
Så det är goda nyheter.
När det gäller behörigheter är det en annan historia. Till skillnad från med indexmatchning, där du inte behöver indexet för att inkludera kolumner som refereras av de inre frågorna så länge som de till slut inte behövs, måste du ha behörighet till alla refererade kolumner.
För att demonstrera detta, använd följande kod för att skapa en användare som heter user1 och tilldela några behörigheter (VÄLJ behörigheter för alla kolumner från Sales.Customers och endast på de tre kolumnerna från Sales.Orders som i slutändan är relevanta i frågan ovan):
CREATE USER user1 WITHOUT LOGIN; GRANT SHOWPLAN TO user1; GRANT SELECT ON Sales.Customers TO user1; GRANT SELECT ON Sales.Orders(custid, orderdate, orderid) TO user1;
Kör följande kod för att imitera användare1:
EXECUTE AS USER = 'user1';
Försök att välja alla kolumner från Sales.Orders:
SELECT * FROM Sales.Orders;
Som förväntat får du följande fel på grund av bristen på behörigheter för några av kolumnerna:
Msg 230, Level 14, State 1SELECT-behörigheten nekades i kolumnen 'empid' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230 , Nivå 14, Tillstånd 1
SELECT-behörigheten nekades i kolumnen 'requireddate' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Medd. 230, Nivå 14, tillstånd 1
SELECT-behörigheten nekades i kolumnen 'shippeddate' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Tillstånd 1
SELECT-behörigheten nekades i kolumnen 'shipperid' för objektet 'Order', databasen 'TSQLV5', schema 'Försäljning'.
Medd. 230, nivå 14, tillstånd 1
SELECT-behörigheten nekades i kolumnen 'frakt' för objektet 'Order', databasen 'TSQLV5', schemat 'Försäljning'.
Msg 230, Level 14, State 1
SELECT-behörigheten nekades i kolumnen 'shipname' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT-behörigheten nekades i kolumnen 'shipaddress' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT-behörigheten nekades i kolumnen 'shipcity' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT behörighet nekades i kolumnen 'shipregion' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT-behörigheten var nekad i kolumnen 'shippostalcode' för objektet 'Order', databasen 'TSQLV5', schema 'Försäljning'.
Medd. 230, nivå 14, tillstånd 1
VÄLJ-behörigheten nekades den kolumnen 'shipcountry' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Prova följande fråga, projicera och interagera endast med kolumner som användare1 har behörighet för:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Ändå får du kolumnbehörighetsfel på grund av bristen på behörigheter för några av kolumnerna som refereras till av den inre frågan via dess SELECT *:
Msg 230, Level 14, State 1SELECT-behörigheten nekades i kolumnen 'empid' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230 , Nivå 14, Tillstånd 1
SELECT-behörigheten nekades i kolumnen 'requireddate' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Medd. 230, Nivå 14, tillstånd 1
SELECT-behörigheten nekades i kolumnen 'shippeddate' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, Tillstånd 1
SELECT-behörigheten nekades i kolumnen 'shipperid' för objektet 'Order', databasen 'TSQLV5', schema 'Försäljning'.
Medd. 230, nivå 14, tillstånd 1
SELECT-behörigheten nekades i kolumnen 'frakt' för objektet 'Order', databasen 'TSQLV5', schemat 'Försäljning'.
Msg 230, Level 14, State 1
SELECT-behörigheten nekades i kolumnen 'shipname' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT-behörigheten nekades i kolumnen 'shipaddress' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT-behörigheten nekades i kolumnen 'shipcity' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT behörighet nekades i kolumnen 'shipregion' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Msg 230, Level 14, State 1
SELECT-behörigheten var nekad i kolumnen 'shippostalcode' för objektet 'Order', databasen 'TSQLV5', schema 'Försäljning'.
Medd. 230, nivå 14, tillstånd 1
VÄLJ-behörigheten nekades den kolumnen 'shipcountry' för objektet 'Order', databasen 'TSQLV5', schema 'Sales'.
Om det verkligen är praxis i ditt företag att tilldela användarna behörigheter till endast relevanta kolumner som de behöver interagera med, vore det vettigt att använda lite längre kod och vara tydlig om kolumnlistan i både de inre och yttre frågorna, som så:
SELECT custid, orderdate, orderid, rownum
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Den här gången körs frågan utan fel.
En annan variant som kräver att användaren endast har behörighet för de relevanta kolumnerna är att vara tydlig med kolumnnamnen i den inre frågans SELECT-lista och använda SELECT * i den yttre frågan, som så:
SELECT *
FROM ( SELECT custid, orderdate, orderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC, orderid DESC) AS rownum
FROM Sales.Orders ) AS D
WHERE rownum <= 3; Denna fråga körs också utan fel. Jag ser dock den här versionen som en som är benägen att få buggar ifall det senare görs några ändringar i någon inre nivå av häckning. Som nämnts tidigare är den bästa praxis för mig att vara tydlig om kolumnlistan i den yttersta frågan. Så så länge du inte har några farhågor om bristande behörighet på några av kolumnerna, känner jag mig bekväm med SELECT * i inre frågor, men en explicit kolumnlista i den yttersta frågan. Om tillämpning av specifika kolumnbehörigheter är en vanlig praxis i företaget, är det bäst att helt enkelt vara tydlig om kolumnnamn på alla nivåer av kapsling. Tänk på, att vara tydlig med kolumnnamn på alla nivåer av kapsling är faktiskt obligatoriskt om din fråga används i ett schemabundet objekt, eftersom schemabindning inte tillåter användningen av SELECT * någonstans i frågan.
Kör nu följande kod för att ta bort indexet du skapade tidigare på Sales.Orders:
DROP INDEX IF EXISTS idx_custid_odD_oidD ON Sales.Orders;
Det finns ett annat fall med ett liknande dilemma angående legitimiteten av att använda SELECT *; i den inre frågan i EXISTS-predikatet.
Tänk på följande fråga (vi kallar den fråga 2):
SELECT custid
FROM Sales.Customers AS C
WHERE EXISTS (SELECT * FROM Sales.Orders AS O
WHERE O.custid = C.custid); Planen för denna fråga visas i figur 2.
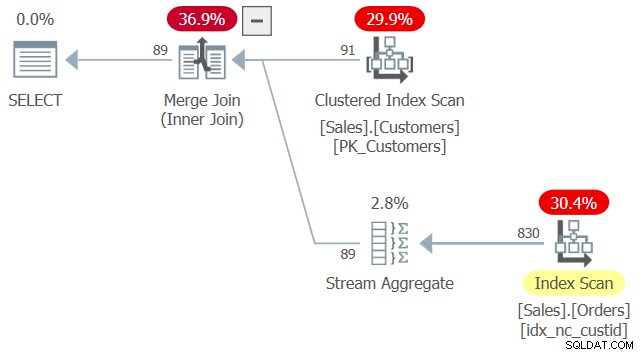 Figur 2:Plan för fråga 2
Figur 2:Plan för fråga 2
När indexmatchning användes ansåg optimeraren att indexet idx_nc_custid är ett täckande index på Sales.Orders eftersom det innehåller custid-kolumnen – den enda riktiga relevanta kolumnen i den här frågan. Det är trots att detta index inte innehåller någon annan kolumn förutom custid, och att den inre frågan i EXISTS-predikatet säger SELECT *. Än så länge verkar beteendet likna användningen av SELECT * i härledda tabeller.
Vad som är annorlunda med den här frågan är att den körs utan fel, trots att user1 inte har behörighet på några av kolumnerna från Sales.Orders. Det finns ett argument för att motivera att inte kräva behörigheter för alla kolumner här. När allt kommer omkring behöver EXISTS-predikatet bara kontrollera om det finns matchande rader, så den inre frågans SELECT-lista är verkligen meningslös. Det hade förmodligen varit bäst om SQL inte krävde en SELECT-lista alls i ett sådant fall, men det skeppet har redan seglat. Den goda nyheten är att SELECT-listan faktiskt ignoreras – både när det gäller indexmatchning och när det gäller nödvändiga behörigheter.
Det verkar också som att det finns en annan skillnad mellan härledda tabeller och EXISTS när du använder SELECT * i den inre frågan. Kom ihåg den här frågan från tidigare i artikeln:
SELECT country
FROM ( SELECT *
FROM Sales.Customers
GROUP BY country ) AS D; Om du kommer ihåg genererade den här koden ett fel eftersom den inre frågan är ogiltig.
Prova samma inre fråga, bara den här gången i EXISTS-predikatet (vi kallar detta påstående 3):
IF EXISTS ( SELECT *
FROM Sales.Customers
GROUP BY country )
PRINT 'This works! Thanks Dmitri Korotkevitch for the tip!'; Konstigt nog anser SQL Server den här koden som giltig och den körs framgångsrikt. Planen för denna kod visas i figur 3.
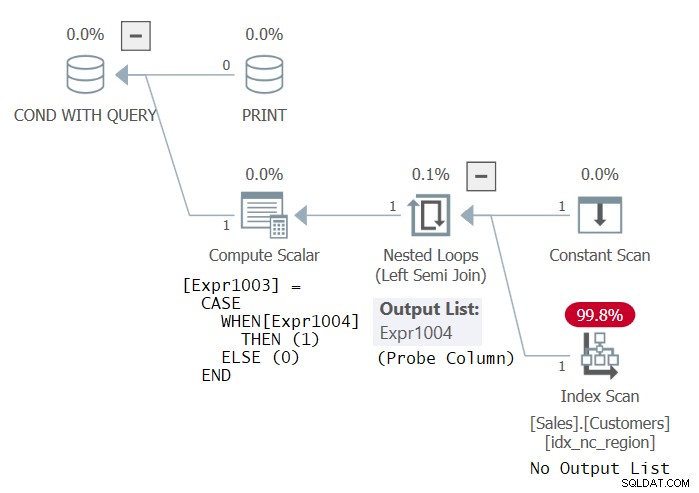 Figur 3:Plan för uttalande 3
Figur 3:Plan för uttalande 3
Denna plan är identisk med planen du skulle få om den inre frågan bara var SELECT * FROM Sales.Customers (utan GROUP BY). När allt kommer omkring, du kontrollerar om det finns grupper, och om det finns rader finns det naturligtvis grupper. Hur som helst, jag tror att det faktum att SQL Server anser denna fråga som giltig är en bugg. Visst borde SQL-koden vara giltig! Men jag kan se varför vissa skulle kunna hävda att SELECT-listan i EXISTS-frågan är tänkt att ignoreras. Hur som helst använder planen en undersökt vänster semi-join, som inte behöver returnera några kolumner, utan bara undersöka en tabell för att kontrollera om det finns några rader. Indexet på kunder kan vara vilket index som helst.
Vid det här laget kan du köra följande kod för att sluta imitera användare1 och släppa den:
REVERT; DROP USER IF EXISTS user1;
Tillbaka till det faktum att jag tycker att det är en praktisk övning att använda SELECT * i inre nivåer av kapsling, ju fler nivåer du har, desto mer förkortar och förenklar denna övning din kod. Här är ett exempel med två kapslingsnivåer:
SELECT orderid, orderyear, custid, empid, shipperid
FROM ( SELECT *, DATEFROMPARTS(orderyear, 12, 31) AS endofyear
FROM ( SELECT *, YEAR(orderdate) AS orderyear
FROM Sales.Orders ) AS D1 ) AS D2
WHERE orderdate = endofyear; Det finns fall där denna praxis inte kan användas. Till exempel, när den inre frågan sammanfogar tabeller med vanliga kolumnnamn, som i följande exempel:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT *,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Både Sales.Customers och Sales.Orders har en kolumn som kallas custid. Du använder ett tabelluttryck som är baserat på en koppling mellan de två tabellerna för att definiera den härledda tabellen D. Kom ihåg att en tabells rubrik är en uppsättning kolumner, och som en uppsättning kan du inte ha dubbletter av kolumnnamn. Därför misslyckas den här frågan med följande fel:
Msg 8156, Level 16, State 1Kolumnen 'custid' specificerades flera gånger för 'D'.
Här måste du vara tydlig om kolumnnamn i den inre frågan, och se till att du antingen returnerar custid från endast en av tabellerna, eller tilldelar unika kolumnnamn till resultatkolumnerna om du vill returnera båda. Oftare skulle du använda den tidigare metoden, som så:
SELECT custid, companyname, orderdate, orderid, rownum
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Återigen, du kan vara tydlig med kolumnnamnen i den inre frågan och använda SELECT * i den yttre frågan, som så:
SELECT *
FROM ( SELECT C.custid, C.companyname, O.orderdate, O.orderid,
ROW_NUMBER() OVER(PARTITION BY C.custid
ORDER BY O.orderdate DESC, O.orderid DESC) AS rownum
FROM Sales.Customers AS C
LEFT OUTER JOIN Sales.Orders AS O
ON C.custid = O.custid ) AS D
WHERE rownum <= 3; Men som jag nämnde tidigare anser jag att det är en dålig praxis att inte vara explicit om kolumnnamn i den yttersta frågan.
Flera referenser till kolumnalias
Låt oss gå vidare till nästa punkt - flera referenser till härledda tabellkolumner. Om den härledda tabellen har en resultatkolumn som är baserad på en icke-deterministisk beräkning, och den yttre frågan har flera referenser till den kolumnen, kommer då beräkningen att utvärderas endast en gång eller separat för varje referens?
Låt oss börja med det faktum att flera referenser till samma icke-deterministiska funktion i en fråga ska utvärderas oberoende. Betrakta följande fråga som ett exempel:
SELECT NEWID() AS mynewid1, NEWID() AS mynewid2;
Denna kod genererar följande utdata som visar två olika GUID:er:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 7BF389EC-082F-44DA-B98A-DB85CD095506 EA1EFF65-B2E4-4060-9592-7116F674D406
Omvänt, om du har en härledd tabell med en kolumn som är baserad på en icke-deterministisk beräkning, och den yttre frågan har flera referenser till den kolumnen, ska beräkningen endast utvärderas en gång. Tänk på följande fråga (vi kallar denna fråga 4):
SELECT mynewid AS mynewid1, mynewid AS mynewid2 FROM ( SELECT NEWID() AS mynewid ) AS D;
Planen för denna fråga visas i figur 4.
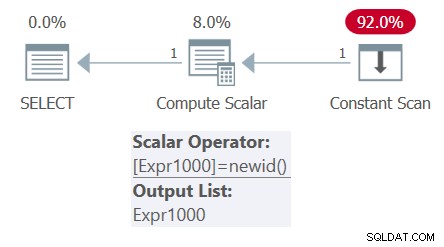 Figur 4:Plan för fråga 4
Figur 4:Plan för fråga 4
Observera att det bara finns en anrop av NEWID-funktionen i planen. Följaktligen visar utgången samma GUID två gånger:
mynewid1 mynewid2 ------------------------------------ ------------------------------------ 296A80C9-260A-47F9-9EB1-C2D0C401E74A 296A80C9-260A-47F9-9EB1-C2D0C401E74A
Så ovanstående två frågor är inte logiskt likvärdiga, och det finns fall där inlining/ersättning inte äger rum.
Med vissa icke-deterministiska funktioner är det lite svårare att visa att flera anrop i en fråga hanteras separat. Ta funktionen SYSDATETIME som ett exempel. Den har 100 nanosekunders precision. Vilka är chanserna att en fråga som den följande faktiskt visar två olika värden?
SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2;
Om du är uttråkad kan du trycka på F5 upprepade gånger tills det händer. Om du har viktigare saker att göra med din tid kanske du föredrar att köra en loop, som så:
DECLARE @i AS INT = 1;
WHILE EXISTS( SELECT *
FROM ( SELECT SYSDATETIME() AS mydt1, SYSDATETIME() AS mydt2 ) AS D
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; Till exempel, när jag körde den här koden fick jag 1971.
Om du vill försäkra dig om att den icke-deterministiska funktionen endast anropas en gång och lita på samma värde i flera frågereferenser, se till att du definierar ett tabelluttryck med en kolumn baserad på funktionsanropet och har flera referenser till den kolumnen från den yttre frågan, som så (vi kallar denna fråga 5):
SELECT mydt AS mydt1, mydt AS mydt1 FROM ( SELECT SYSDATETIME() AS mydt ) AS D;
Planen för denna fråga visas i figur 5.
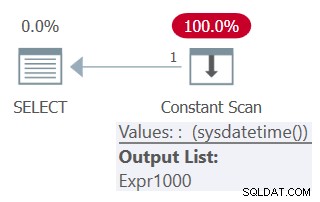 Figur 5:Plan för fråga 5
Figur 5:Plan för fråga 5
Lägg märke till i planen att funktionen endast anropas en gång.
Nu kan detta vara en riktigt intressant övning för patienter att slå F5 upprepade gånger tills du får två olika värden. The good news is that a vaccine for COVID-19 will be found sooner.
You could of course try running a test with a loop:
DECLARE @i AS INT = 1;
WHILE EXISTS ( SELECT *
FROM (SELECT mydt AS mydt1, mydt AS mydt2
FROM ( SELECT SYSDATETIME() AS mydt ) AS D1) AS D2
WHERE mydt1 = mydt2 )
SET @i += 1;
PRINT @i; You can let it run as long as you feel that it’s reasonable to wait, but of course it won’t stop on its own.
Understanding this, you will know to avoid writing code such as the following:
SELECT
CASE
WHEN RAND() < 0.5
THEN STR(RAND(), 5, 3) + ' is less than half.'
ELSE STR(RAND(), 5, 3) + ' is at least half.'
END; Because occasionally, the output will not seem to make sense, e.g.,
0.550 is less than half.For more on evaluation within a CASE expression, see the section "Expressions can be evaluated more than once" in Aaron Bertrand's post, "Dirty Secrets of the CASE Expression."
Instead, you should either store the function’s result in a variable and then work with the variable or, if it needs to be part of a query, you can always work with a derived table, like so:
SELECT
CASE
WHEN rnd < 0.5
THEN STR(rnd, 5, 3) + ' is less than half.'
ELSE STR(rnd, 5, 3) + ' is at least half.'
END
FROM ( SELECT RAND() AS rnd ) AS D; Sammanfattning
In this article I covered some aspects of the physical processing of derived tables.
When the outer query projects only a subset of the columns of a derived table, SQL Server is able to apply efficient index matching based on the columns in the outermost SELECT list, or that play some other meaningful role in the query, such as filtering, grouping, ordering, and so on. From this perspective, if for brevity you prefer to use SELECT * in inner levels of nesting, this will not negatively affect index matching. However, the executing user (or the user whose effective permissions are evaluated), needs permissions to all columns that are referenced in inner levels of nesting, even those that eventually are not really relevant. An exception to this rule is the SELECT list of the inner query in an EXISTS predicate, which is effectively ignored.
When you have multiple references to a nondeterministic function in a query, the different references are evaluated independently. Conversely, if you encapsulate a nondeterministic function call in a result column of a derived table, and refer to that column multiple times from the outer query, all references will rely on the same function invocation and get the same values.