 När jag växte upp älskade jag spel som testade förmågan att matcha minne och mönster. Flera av mina vänner hade Simon, medan jag hade en knock-off som hette Einstein. Andra hade en Atari Touch Me, som jag redan då visste var ett tveksamt namnbeslut. Nuförtiden betyder mönstermatchning något mycket annat för mig och kan vara en dyr del av vardagliga databasfrågor.
När jag växte upp älskade jag spel som testade förmågan att matcha minne och mönster. Flera av mina vänner hade Simon, medan jag hade en knock-off som hette Einstein. Andra hade en Atari Touch Me, som jag redan då visste var ett tveksamt namnbeslut. Nuförtiden betyder mönstermatchning något mycket annat för mig och kan vara en dyr del av vardagliga databasfrågor.
Jag stötte nyligen på ett par kommentarer om Stack Overflow där en användare uppgav, som ett faktum, att CHARINDEX presterar bättre än LEFT eller LIKE . I ett fall citerade personen en artikel av David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT/RIGHT vs CHARINDEX." Ja, artikeln visar att, i det konstruerade exemplet, CHARINDEX presterade bäst. Men eftersom jag alltid är skeptisk till sådana allmänna uttalanden och inte kunde komma på en logisk anledning till varför en strängfunktion skulle alltid prestera bättre än någon annan, med allt annat lika , jag körde hans tester. Visst, jag hade upprepade gånger olika resultat på min maskin (klicka för att förstora):
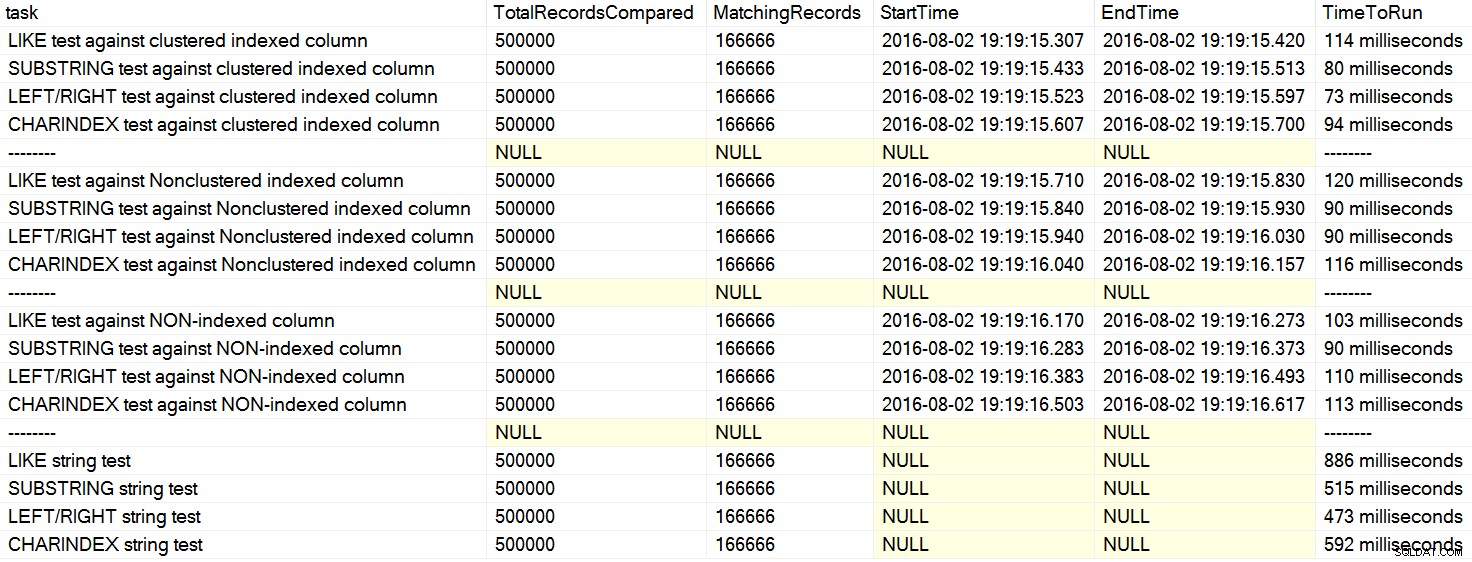 På min dator var CHARINDEX långsammare än VÄNSTER/HÖGER/SUBSTRING.
På min dator var CHARINDEX långsammare än VÄNSTER/HÖGER/SUBSTRING.
Davids tester jämförde i princip dessa frågestrukturer – letade efter ett strängmönster antingen i början eller slutet av ett kolumnvärde – i termer av obearbetad varaktighet:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Bara genom att titta på dessa klausuler kan du se varför CHARINDEX kan vara mindre effektivt – det gör flera ytterligare funktionella anrop som de andra metoderna inte behöver utföra. Varför detta tillvägagångssätt fungerade bäst på Davids maskin är jag inte säker på; kanske körde han koden exakt som postad och tappade inte riktigt buffertar mellan testerna, så att de senare testerna gynnades av cachad data.
I teorin, CHARINDEX kunde ha uttryckts enklare, t.ex.:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Men detta fungerade faktiskt ännu sämre i mina tillfälliga tester.)
Och varför dessa ens är OR förhållanden, jag är inte säker. Realistiskt sett gör du oftast en av två typer av mönstersökningar:börjar med eller innehåller (det är mycket mindre vanligt att leta efter slutar med ). Och i de flesta av dessa fall tenderar användaren att ange i förväg om de vill börjar med eller innehåller , åtminstone i varje applikation jag har varit involverad i i min karriär.
Det är vettigt att separera dessa som separata typer av frågor, istället för att använda ett ELLER villkorlig, eftersom börjar med kan använda ett index (om det finns ett som är tillräckligt lämpligt för en sökning, eller är smalare än det klustrade indexet), medan slutar med kan inte (och ELLER förhållanden tenderar att kasta skiftnycklar mot optimeraren i allmänhet). Om jag kan lita på GILLA att använda ett index när det kan, och att prestera lika bra som eller bättre än de andra lösningarna ovan i de flesta eller alla fall, då kan jag göra denna logik väldigt enkel. En lagrad procedur kan ta två parametrar – mönstret som söks efter och typen av sökning som ska utföras (vanligtvis finns det fyra typer av strängmatchning – börjar med, slutar med, innehåller eller exakt matchning).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Detta hanterar varje potentiellt fall utan att använda dynamisk SQL; OPTION (RECOMPILE) är där för att du inte vill att en plan som är optimerad för "slutar med" (som nästan säkert kommer att behöva skannas) ska återanvändas för en "börjar med"-fråga, eller vice versa; det kommer också att säkerställa att uppskattningarna är korrekta ("börjar med S" har förmodligen mycket annan kardinalitet än "börjar med QX"). Även om du har ett scenario där användare väljer en typ av sökning 99% av gångerna, kan du använda dynamisk SQL här istället för att kompilera om, men i så fall skulle du fortfarande vara sårbar för parametersniffning. I många villkorslogiska frågor är omkompilering och/eller fullständig dynamisk SQL ofta det mest förnuftiga tillvägagångssättet (se mitt inlägg om "The Kitchen Sink").
Testen
Eftersom jag nyligen har börjat titta på den nya WideWorldImporters exempeldatabasen, bestämde jag mig för att köra mina egna tester där. Det var svårt att hitta en anständig tabell utan ett ColumnStore-index eller en tidshistoriktabell, men Sales.Invoices , som har 70 510 rader, har en enkel nvarchar(20) kolumn som heter CustomerPurchaseOrderNumber som jag bestämde mig för att använda för testerna. (Varför det är nvarchar(20) när varje enskilt värde är ett 5-siffrigt tal har jag ingen aning om, men mönstermatchning bryr sig egentligen inte om byten under representerar siffror eller strängar.)
| Försäljningsfakturor CustomerPurchaseOrderNumber | ||
|---|---|---|
| Mönster | # rader | % av tabellen |
| Börjar med "1" | 70 505 | 99,993 % |
| Börjar med "2" | 5 | 0,007 % |
| Slutar med "5" | 6 897 | 9,782 % |
| Slutar med "30" | 749 | 1,062 % |
Jag letade runt på värdena i tabellen för att komma fram till flera sökkriterier som skulle producera väldigt olika antal rader, förhoppningsvis för att avslöja eventuellt tipppunktbeteende med ett givet tillvägagångssätt. Till höger är sökfrågorna jag landade på.
Jag ville bevisa för mig själv att proceduren ovan onekligen var bättre överlag för alla möjliga sökningar än någon av de frågor som använder OR villkor, oavsett om de använder LIKE , LEFT/RIGHT , SUBSTRING , eller CHARINDEX . Jag tog Davids grundläggande frågestrukturer och placerade dem i lagrade procedurer (med reservationen att jag inte riktigt kan testa "innehåller" utan hans input, och att jag var tvungen att göra hans OR logik lite mer flexibel för att få samma antal rader), tillsammans med en version av min logik. Jag planerade också att testa procedurerna med och utan ett index som jag skulle skapa i sökkolumnen, och under både en varm och en kall cache.
Procedurerna:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Jag gjorde också versioner av Davids procedurer som är sanna mot hans ursprungliga avsikt, förutsatt att kravet verkligen är att hitta alla rader där sökmönstret är i början *eller* slutet av strängen. Jag gjorde detta helt enkelt så att jag kunde jämföra prestanda för de olika metoderna, precis som han skrev dem, för att se om mina resultat på denna datamängd skulle matcha mina tester av hans ursprungliga skript på mitt system. I det här fallet fanns det ingen anledning att introducera en egen version, eftersom den helt enkelt skulle matcha hans LIKE % + @pattern OR LIKE @pattern + % variation.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Med procedurerna på plats kunde jag generera testkoden – vilket ofta är lika roligt som det ursprungliga problemet. Först en loggningstabell:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Sedan väljer koden som skulle utföra operationer med hjälp av de olika procedurerna och argumenten:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Resultat
Jag körde dessa tester på en virtuell maskin som körde Windows 10 (1511/10586.545), SQL Server 2016 (13.0.2149), med 4 processorer och 32 GB RAM. Jag körde varje uppsättning tester 11 gånger; för de varma cache-testerna slängde jag ut den första uppsättningen resultat eftersom några av dessa var verkligt kalla cache-tester.
Jag kämpade med hur jag skulle rita resultaten för att visa mönster, mest för att det helt enkelt inte fanns några mönster. Nästan varje metod var den bästa i ett scenario och den sämsta i ett annat. I följande tabeller lyfte jag fram de bästa och sämsta förfarandena för varje kolumn, och du kan se att resultaten är långt ifrån avgörande:
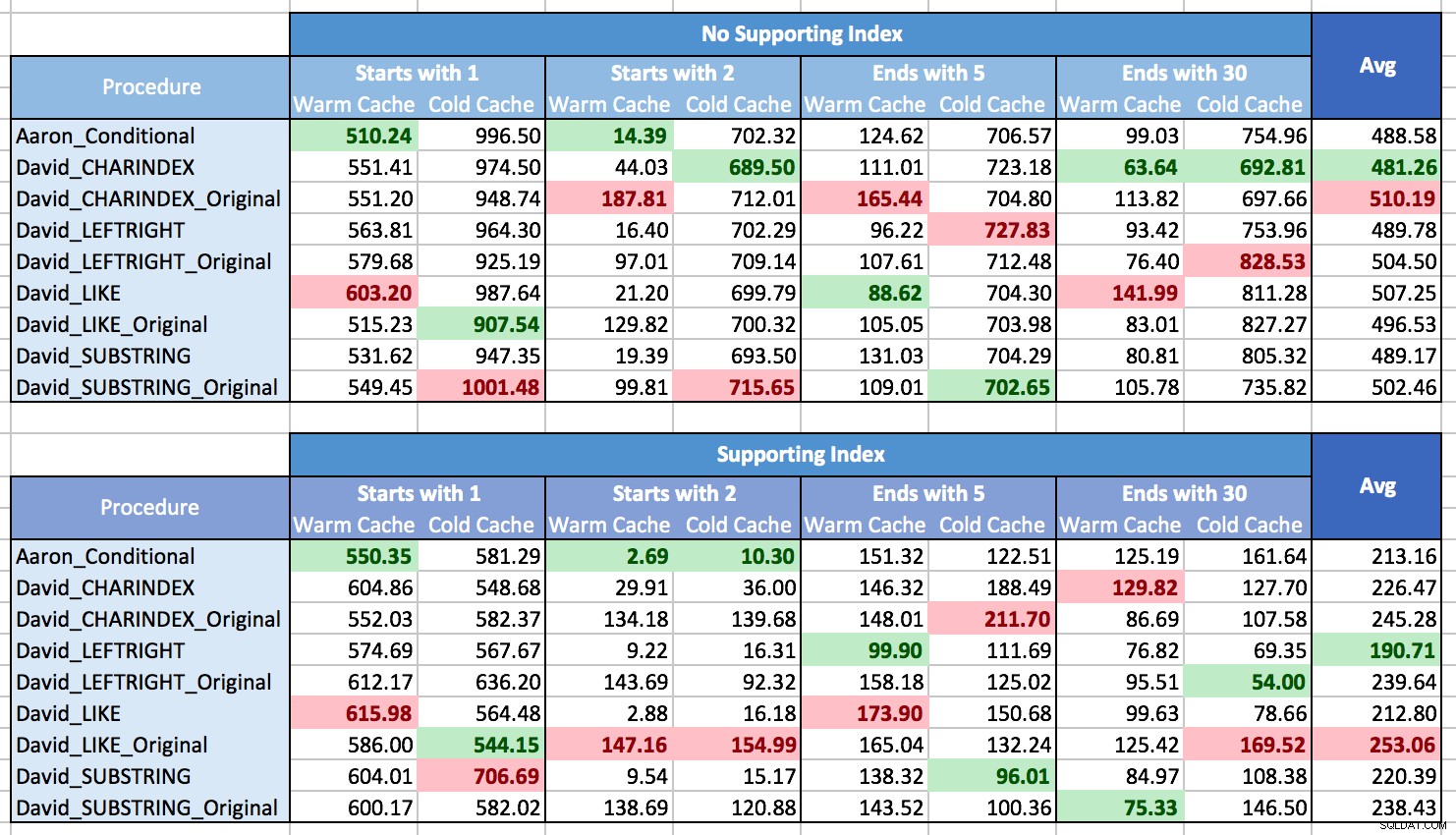 I dessa tester vann CHARINDEX ibland, och ibland inte.
I dessa tester vann CHARINDEX ibland, och ibland inte.
Vad jag har lärt mig är att på det hela taget, om du kommer att ställas inför många olika situationer (olika typer av mönstermatchning, med ett stödjande index eller inte, data kan inte alltid finnas i minnet), det finns verkligen ingen klar vinnare, och prestandaomfånget i genomsnitt är ganska litet (i själva verket, eftersom en varm cache inte alltid hjälpte, skulle jag misstänka att resultaten påverkades mer av kostnaden för att rendera resultaten än att hämta dem). För individuella scenarier, lita inte på mina tester; kör några benchmarks själv med tanke på din hårdvara, konfiguration, data och användningsmönster.
Varningar
Några saker jag inte övervägde för dessa tester:
- Klustrade kontra icke-klustrade . Eftersom det är osannolikt att ditt klustrade index kommer att finnas i en kolumn där du utför mönstermatchningssökningar mot början eller slutet av strängen, och eftersom en sökning kommer att vara i stort sett densamma i båda fallen (och skillnaderna mellan skanningar kommer till stor del att vara funktion av indexbredd kontra tabellbredd), testade jag bara prestanda med ett icke-klustrat index. Om du har några specifika scenarier där denna skillnad ensam gör stor skillnad för mönstermatchning, vänligen meddela mig.
- MAX typer . Om du söker efter strängar inom
varchar(max)/nvarchar(max), de kan inte indexeras, så om du inte använder beräknade kolumner för att representera delar av värdet, kommer en skanning att krävas – oavsett om du letar efter börjar med, slutar med eller innehåller. Jag testade inte om prestandaoverheaden korrelerar med storleken på strängen, eller om ytterligare overhead introduceras helt enkelt på grund av typen.
- Fulltextsökning . Jag har lekt med den här funktionen här och nu, och jag kan stava det, men om jag förstår det kan det bara vara till hjälp om du söker efter hela ord utan slut, och inte bryr dig om var i strängen de var hittades. Det skulle inte vara användbart om du lagrade textstycken och ville hitta alla de som börjar med "Y", innehåller ordet "den" eller slutar med ett frågetecken.
Sammanfattning
Det enda allmänna uttalandet jag kan göra när jag går ifrån detta test är att det inte finns några allmänna uttalanden om vad som är det mest effektiva sättet att utföra matchning av strängmönster. Även om jag är partisk mot mitt villkorliga tillvägagångssätt för flexibilitet och underhållbarhet, var det inte prestandavinnaren i alla scenarier. För mig, såvida jag inte hamnar i en flaskhals i prestanda och jag följer alla vägar, kommer jag att fortsätta använda mitt tillvägagångssätt för konsekvens. Som jag föreslog ovan, om du har ett mycket snävt scenario och är mycket känslig för små skillnader i varaktighet, kommer du att vilja köra dina egna tester för att avgöra vilken metod som genomgående fungerar bäst för dig.