Service Pack 2 för SQL Server 2014 släpptes förra månaden (läs releasekommentarerna här) och innehåller en ny DBCC-sats:DBCC CLONEDATABASE . Jag var ganska glad över att se detta kommando introducerat, eftersom det ger en mycket enkel sätt att kopiera ett databasschema, inklusive statistik , som kan användas för att testa frågeprestanda utan att kräva allt utrymme som behövs för data i databasen. Jag fick äntligen lite tid att testa DBCC CLONEDATABASE och förstår begränsningarna, och jag måste säga att det var ganska roligt.
Grunderna
Jag började med att skapa en klon av AdventureWorks2014-databasen och köra en fråga mot källdatabasen och sedan klondatabasen:
DBCC CLONEDATABASE (N'AdventureWorks2014', N'AdventureWorks2014_CLONE'); GO SET STATISTICS IO ON; GO SET STATISTICS TIME ON; GO SET STATISTICS XML ON; GO USE [AdventureWorks2014]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO USE [AdventureWorks2014_CLONE]; GO SELECT * FROM [Sales].[SalesOrderHeader] [h] JOIN [Sales].[SalesOrderDetail] [d] ON [h].[SalesOrderID] = [d].[SalesOrderID] ORDER BY [SalesOrderDetailID]; GO SET STATISTICS IO OFF; GO SET STATISTICS TIME OFF; GO SET STATISTICS XML OFF; GO
Om jag tittar på I/O- och TIME-utgången kan jag se att frågan mot källdatabasen tog längre tid och genererade mycket mer I/O, som båda förväntas eftersom klondatabasen inte har några data i sig:
/* SOURCE-databas */
SQL Server Execution Times:
CPU-tid =0 ms, förfluten tid =0 ms.
SQL Server-analys och kompileringstid:
CPU-tid =0 ms, förfluten tid =4 ms.
(121317 rad(er) påverkas)
Tabell 'SalesOrderHeader'. Skanningsantal 0, logiskt läser 371567, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'Arbetsbord'. Skanningsantal 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'SalesOrder Detail'. Skanningsantal 5, logiskt läser 1361, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'Arbetsbord'. Skanningsantal 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
(1 rad(er) påverkas)
SQL Server Execution Times:
CPU-tid =686 ms, förfluten tid =2548 ms.
/* CLONE-databas */
SQL Server Execution Times:
CPU-tid =0 ms, förfluten tid =0 ms.
SQL Server-analys och kompileringstid:
CPU-tid =12 ms, förfluten tid =12 ms.
(0 rad(er) påverkas)
Tabell 'Arbetsbord'. Skanningsantal 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'SalesOrderHeader'. Skanningsantal 0, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
Tabell 'SalesOrder Detail'. Skanningsantal 5, logiskt läser 0, fysiskt läser 0, read-ahead läser 0, lob logiskt läser 0, lob fysisk läser 0, lob läser framåt läser 0.
(1 rad(er) påverkas)
SQL Server Execution Times:
CPU-tid =0 ms, förfluten tid =83 ms.
Om jag tittar på exekveringsplanerna är de samma för båda databaserna förutom de faktiska värdena (mängden data som faktiskt flyttade genom planen):
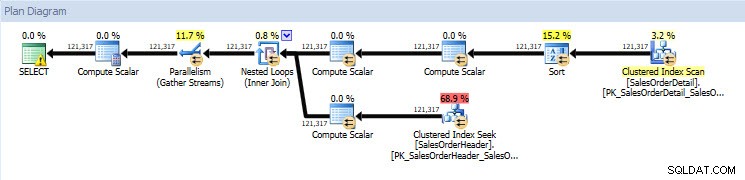 Frågeplan för databasen AdventureWorks2014
Frågeplan för databasen AdventureWorks2014
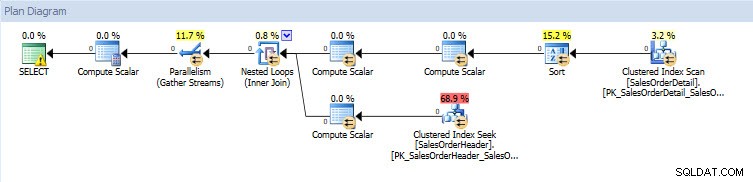 Frågeplan för databasen AdventureWorks2014_CLONE
Frågeplan för databasen AdventureWorks2014_CLONE
Det är här värdet för DBCC CLONEDATABASE är uppenbart – jag kan få en tom kopia av en databas till vem som helst (Microsoft produktsupport, min kollega DBA, etc.) och få dem att återskapa och undersöka ett problem, och de behöver inte potentiellt hundratals GB diskutrymme för att göra Det. Melissas juli T-SQL Tuesday-inlägg har detaljerad information om vad som händer under klonprocessen, så jag rekommenderar att du läser det för mer information.
Är det det?
Men... kan jag göra mer med DBCC CLONEDATABASE ? Jag menar, det här är bra, men jag tror att det finns många andra saker jag kan göra med en tom kopia av databasen. Om du läser dokumentationen för DBCC CLONEDATABASE , ser du den här raden:
Min första tanke var, "frågeoptimerare – hmm... kan jag använda detta som ett alternativ för att testa uppgraderingar ?”
Tja, den klonade databasen är skrivskyddad, men jag tänkte att jag skulle försöka ändra några alternativ ändå. Om jag till exempel kunde ändra kompatibilitetsläget skulle det vara riktigt coolt, eftersom jag då skulle kunna testa CE-ändringar i både SQL Server 2014 och SQL Server 2016.
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 110;
Jag får ett felmeddelande:
Msg 3906, Level 16, State 1Det gick inte att uppdatera databasen "AdventureWorks2014_CLONE" eftersom databasen är skrivskyddad.
Msg 5069, Level 16, State 1
ALTER DATABASE-satsen misslyckades.
Hm. Kan jag ändra återställningsmodellen?
ALTER DATABASE [AdventureWorks2014_CLONE] SET RECOVERY SIMPLE WITH NO_WAIT;
Jag kan. Det verkar inte rättvist. Tja, det är skrivskyddat, kan jag ändra det?
ALTER DATABASE [AdventureWorks2014_CLONE] SET READ_WRITE WITH NO_WAIT;
JA! Innan du blir för upphetsad, låt mig lämna denna anteckning från dokumentationen här:
Obs Den nygenererade databasen som genereras från DBCC CLONEDATABASE stöds inte för att användas som en produktionsdatabas och är främst avsedd för felsökning och diagnostiska syften. Vi rekommenderar att du tar bort den klonade databasen efter att databasen har skapats.Jag kommer att upprepa den här raden från dokumentationen och feta den och sätta den röd som en vänlig men extremt viktig påminnelse:
Den nygenererade databasen som genereras från DBCC CLONEDATABASE stöds inte för att användas som en produktionsdatabas och är främst avsedd för felsökning och diagnostiska syften.Det är bra för mig, jag skulle definitivt inte använda den här för produktion, men nu kan jag använda den för att testa! NU kan jag ändra kompatibilitetsläget, och NU kan jag säkerhetskopiera det och återställa det på en annan instans för testning!
USE [master]; GO BACKUP DATABASE [AdventureWorks2014_CLONE] TO DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH INIT, NOFORMAT, STATS = 10, NAME = N'AW2014_CLONE_full'; GO /* restore on SQL Server 2016 */ RESTORE DATABASE [AdventureWorks2014_CLONE] FROM DISK = N'C:\Backups\AdventureWorks2014_CLONE.bak' WITH MOVE N'AdventureWorks2014_Data' TO N'C:\Databases\AdventureWorks2014_Data_2684624044.mdf', MOVE N'AdventureWorks2014_Log' TO N'C:\Databases\AdventureWorks2014_Log_3195542593.ldf', NOUNLOAD, REPLACE, STATS = 5; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET COMPATIBILITY_LEVEL = 130; GO
DET HÄR ÄR STORT.
I mitt förra inlägg pratade jag om spårningsflagga 2389 och testning med den nya Cardinality Estimator eftersom, vänner, ni behöver att testa med den nya CE:n innan du uppgraderar. Om du inte testar, och om du ändrar kompatibilitetsläget till 120 (SQL Server 2014) eller 130 (SQL Server 2016) som en del av din uppgradering, riskerar du att arbeta i ett brandsläckningsläge om du stöter på regressioner med det nya CE. Nu kan du ha det bra och prestandan kan bli ännu bättre efter att du har uppgraderat. Men... skulle du inte vilja vara säker?
Mycket ofta när jag nämner testning före en uppgradering får jag höra att det inte finns någon miljö där man kan testa. Jag vet att några av er har en testmiljö. Några av er har Test, Dev, QA, UAT och vem vet vad mer. Du har tur.
För er som säger att ni inte har någon testmiljö alls att testa i, ger jag er DBCC CLONEDATABASE . Med det här kommandot har du ingen ursäkt för att inte köra de vanligast körda frågorna och tunga mot en klon av din databas. Även om du inte har en testmiljö har du din egen maskin. Säkerhetskopiera klondatabasen från produktionen, släpp klonen, återställ säkerhetskopian till din lokala instans och testa sedan. Klondatabasen tar väldigt lite utrymme på disken och du kommer inte att drabbas av minnes- eller I/O-konflikter eftersom det inte finns några data. Du kommer kunna validera frågeplaner från klonen mot de från din produktionsdatabas. Vidare, om du återställer på SQL Server 2016 kan du inkludera Query Store i din testning! Aktivera Query Store, kör igenom dina tester i det ursprungliga kompatibilitetsläget, uppgradera sedan kompatibilitetsläget och testa igen. Du kan använda Query Store för att jämföra frågor sida vid sida! (Kan du säga att jag dansar i min stol just nu?)
Överväganden
Återigen, det här borde inte vara något du skulle använda i produktionen, och jag vet att du inte skulle göra det, men det tål att upprepas eftersom i sitt nuvarande tillstånd, DBCC CLONEDATABASE är inte helt komplett . Detta noteras i KB-artikeln under objekt som stöds; objekt som minnesoptimerade tabeller och filtabeller kopieras inte, fulltext stöds inte, etc.
Nu är klondatabasen inte utan nackdelar. Om du av misstag kör en indexombyggnad eller en uppdatering av statistik i den databasen har du precis raderat dina testdata. Du kommer att förlora den ursprungliga statistiken, vilket är vad du antagligen ville ha i första hand. Om jag till exempel kontrollerar statistik för det klustrade indexet på SalesOrderHeader just nu, får jag detta:
USE [AdventureWorks2014_CLONE]; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Originalstatistik för SalesOrderHeader
Originalstatistik för SalesOrderHeader
Nu, om jag uppdaterar statistik mot den tabellen, får jag detta:
UPDATE STATISTICS [Sales].[SalesOrderHeader] WITH FULLSCAN; GO DBCC SHOW_STATISTICS (N'Sales.SalesOrderHeader',PK_SalesOrderHeader_SalesOrderID);
 Uppdaterad (tom) statistik för SalesOrderHeader
Uppdaterad (tom) statistik för SalesOrderHeader
Som en extra säkerhet är det förmodligen en bra idé att inaktivera automatiska uppdateringar av statistik:
USE [master]; GO ALTER DATABASE [AdventureWorks2014_CLONE] SET AUTO_UPDATE_STATISTICS OFF WITH NO_WAIT;
Om du råkar uppdatera statistik oavsiktligt, kör DBCC CLONEDATABASE och att gå igenom processen för säkerhetskopiering och återställning är inte så svårt, och du kommer att få det automatiserat på nolltid.
Du kan lägga till data till databasen. Detta kan vara användbart om du vill experimentera med statistik (t.ex. olika samplingsfrekvenser, filtrerad statistik) och du har tillräckligt med lagringsutrymme för att hålla en kopia av tabellens data.
Utan data i databasen kommer du uppenbarligen inte att få tillförlitligt representativ varaktighet och I/O-data. Det är ok. Om du behöver data om verklig resursanvändning behöver du en kopia av din databas med all data i den. DBCC CLONEDATABASE handlar egentligen om att testa frågeprestanda; det är allt. Det är inte på något sätt en ersättning för traditionell uppgraderingstestning – men det är ett nytt alternativ för att validera hur SQL Server optimerar en fråga med olika versioner och kompatibilitetslägen. Lycka till med testet!