
Denna månads T-SQL-tisdag är värd för Mike Donnelly (@SQLMD), och han sammanfattar ämnet på följande sätt:
Ämnet den här månaden är okomplicerad, men väldigt öppen. Du måste lära dig något nytt och sedan skriva ett blogginlägg som förklarar det.Tja, från det ögonblick som Mike tillkännagav ämnet, ville jag inte riktigt lära mig något nytt, och när helgen närmade sig och jag visste att måndagen skulle angripa mig med jurytjänst, trodde jag att jag skulle behöva sitta här månad ut.
Sedan lärde Martin Smith mig något som jag antingen aldrig visste eller visste för länge sedan men har glömt (ibland vet du inte vad du inte vet, och ibland kan du inte komma ihåg vad du aldrig visste och vad du inte kan kom ihåg). Jag minns att jag ändrade en kolumn från NOT NULL till NULL bör vara en operation med endast metadata, där skrivningar till vilken sida som helst skjuts upp tills den sidan uppdateras av andra skäl, eftersom NULL bitmapp skulle egentligen inte behöva existera förrän minst en rad kunde bli NULL .
I samma inlägg påminde @ypercube mig också om detta relevanta citat från Books Online (stavfel och allt):
Att ändra en kolumn från NOT NULL till NULL stöds inte som en onlineoperation när den ändrade kolumnen är referenser av icke-klustrade index."Inte en onlineoperation" kan tolkas som "inte enbart en metadataoperation" – vilket betyder att det faktiskt kommer att vara en datastorleksoperation (ju större index, desto längre tid tar det).
Jag försökte bevisa detta med ett ganska enkelt (men långdraget) experiment mot en specifik målkolumn för att konvertera från NOT NULL till NULL . Jag skulle skapa 3 tabeller, alla med en klustrad primärnyckel, men var och en med olika icke-klustrade index. En skulle ha målkolumnen som en nyckelkolumn, den andra som en INCLUDE kolumnen, och den tredje skulle inte referera till målkolumnen alls.
Här är mina tabeller och hur jag fyllde dem:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Varje tabell hade 100 000 rader, de klustrade indexen hade 310 sidor och de icke-klustrade indexen hade antingen 272 sidor (test1 och test2 ) eller 174 sidor (test3 ). (Dessa värden är lätta att få från sys.dm_db_index_physical_stats .)
Därefter behövde jag ett enkelt sätt att fånga operationer som loggades på sidnivå – jag valde sys.fn_dblog() , även om jag kunde ha grävt djupare och tittat på sidor direkt. Jag brydde mig inte om att bråka med LSN-värden för att skicka till funktionen, eftersom jag inte körde detta i produktion och inte brydde mig så mycket om prestanda, så efter testerna dumpade jag bara resultaten av funktionen, exklusive all data som loggades före ALTER TABLE operationer.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Nu kunde jag köra mina tester, som var mycket enklare än installationen.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Nu kunde jag undersöka operationerna som loggades i varje fall:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Resultaten tycks antyda att varje bladsida i det icke-klustrade indexet berörs för de fall där målkolumnen nämns i indexet på något sätt, men inga sådana operationer förekommer för det fall där målkolumnen inte nämns i någon icke-klustrade index:
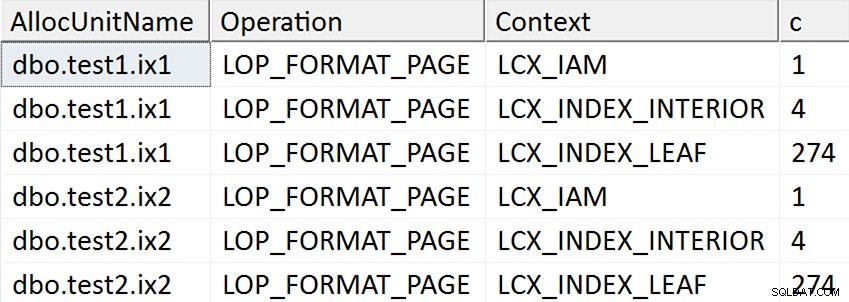
Faktum är att i de två första fallen tilldelas nya sidor (du kan validera det med DBCC IND , som Spörri gjorde i sitt svar), så operationen kan ske online, men det betyder inte att den är snabb (eftersom den fortfarande måste skriva ut en kopia av all denna data och göra NULL bitmappsändring som en del av att skriva ut varje ny sida och logga all aktivitet).
Jag tror att de flesta skulle misstänka att en kolumn ändras från NOT NULL till NULL skulle endast vara metadata i alla scenarier, men jag har visat här att detta inte är sant om kolumnen refereras av ett icke-klustrat index (och liknande saker händer oavsett om det är en nyckel eller INCLUDE kolumn). Kanske kan denna operation också tvingas vara ONLINE i Azure SQL Database idag, eller kommer det att vara möjligt i nästa större version? Detta gör inte nödvändigtvis att de faktiska fysiska operationerna sker snabbare, men det kommer att förhindra blockering som ett resultat.
Jag testade inte det scenariot (och analys av om det verkligen är online är tuffare i Azure i alla fall), och jag testade det inte heller på en hög. Något jag kan återkomma till i ett framtida inlägg. Under tiden bör du vara försiktig med alla antaganden du kan göra om operationer som endast avser metadata.