Virtualisering är mycket populärt för organisationer:det tillåter dem att bättre använda hårdvara genom att kombinera flera servrar på en enda värd, ger HA-kapacitet och ger en minskning av olika kostnader som uppvärmning/kyla, SQL Server-licenser och hårdvara. Jag har varit involverad i många projekt med organisationer för att hjälpa dem att migrera från fysiska till virtuella miljöer och har hjälpt dem att uppleva dessa fördelar.
Vad jag vill dela med dig i den här artikeln är ett märkligt problem som jag stötte på när jag arbetade med Hyper-V på Windows Server 2012 R2 med Dynamic Memory. Jag måste erkänna att det mesta av min kunskap om virtualisering har varit med VMware, men det håller på att förändras nu.
När jag arbetar med SQL Server på VMware rekommenderar jag alltid att ställa in reservationer för minne, så när jag stötte på den här Dynamic Memory-funktionen med Hyper-V var jag tvungen att göra lite research. Jag hittade en artikel (Hyper-V Dynamic Memory Configuration Guide) som förklarar många av fördelarna och systemkraven för att använda Dynamic Memory. Den här funktionen är ganska cool i hur du kan förse en virtuell maskin med mer eller mindre minne utan att den behöver stängas av.
När jag lekte med Hyper-V har jag märkt att det är enkelt och lätt att lära sig att tillhandahålla virtuella maskiner. Med liten ansträngning kunde jag bygga en labbmiljö för att simulera upplevelsen som min kund hade. Tack till min chef för att han försett mig med fantastisk hårdvara att arbeta med. Jag kör en Dell M6800 med en i7-processor, 32 GB RAM och två 1 TB SSD:er. Den här besten är bättre än många servrar jag har arbetat på.
Med VMware Workstation 11 på min bärbara dator skapade jag en Windows Server 2012 R2-gäst med 4 vCPU:er, 24 GB RAM och 100 GB lagringsutrymme. När gästen väl skapats och patchats lade jag till Hyper-V-rollen och satte en gäst under Hyper-V. Den nya gästen byggdes med Windows Server 2012 R2 med 2 vCPU:er, 22 GB RAM och 60 GB lagringsutrymme som kör SQL Server 2014 RTM.
Jag körde tre uppsättningar av tester, var och en med dynamiskt minne. För varje test använde jag Red Gates SQL Data Generator mot AdventureWorks2014-databasen för att fylla upp buffertpoolen. För det första testet började jag med 512MB för Startup RAM-värdet eftersom det är den minsta minnesmängden för att starta Windows Server 2012 R2 och buffertpoolen slutade öka med cirka 8GB.
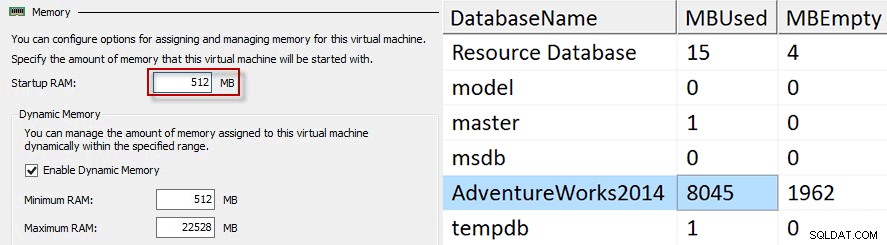
För varje test skulle jag trunkera min testtabell, stänga av gästen, ändra minnesinställningarna och starta gästen igen. För det andra testet ökade jag startminnet till 768 MB och buffertpoolen ökade bara till drygt 12 GB.
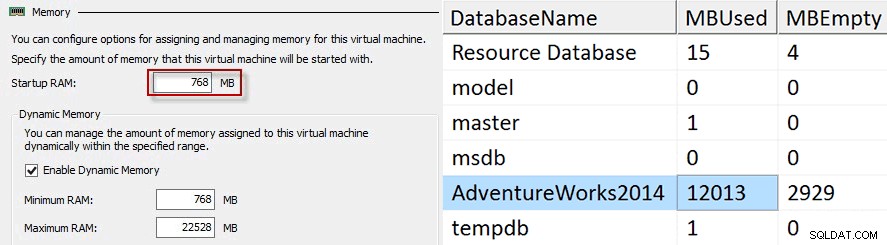
För det tredje och sista testet ökade startminnet till 1024 MB, körde datageneratorn och buffertpoolen kunde öka till strax under 16 GB.
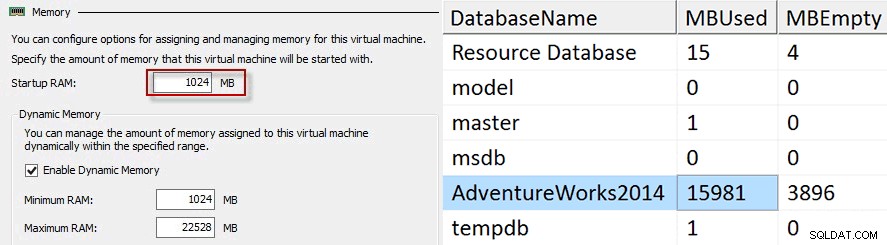
Att göra lite matte på dessa värden visar att buffertpoolen inte kan växa mer än 16 gånger start-RAM. Detta kan vara mycket problematiskt för SQL Server om start-RAM-minnet är mindre än 1/16 av storleken på det maximala minnet. Låt oss tänka på en Hyper-V-gäst med 64 GB RAM-minne som kör SQL Server med ett start-RAM-värde på 1 GB. Vi har observerat att buffertpoolen inte skulle kunna använda mer än 16 GB med den här konfigurationen, men om vi ställer in Startup RAM-värdet till 4096 MB så skulle buffertpoolen kunna öka 16 gånger så att vi kan använda alla 64 GB.
De enda referenserna jag kunde hitta om varför buffertpoolen är begränsad till 16 gånger Startup RAM-värdet fanns på sidorna 8 och 16 i whitepaper, Best Practices for Running SQL Server with HVDM. Det här dokumentet förklarar att eftersom buffertcachevärdet beräknas vid uppstart är det ett statiskt värde och växer inte. Men om SQL Server upptäcker att Hot Add Memory stöds ökar den storleken reserverad för det virtuella adressutrymmet för buffertpoolen med 16 gånger startminnet. Det här dokumentet anger också att detta beteende påverkar SQL Server 2008 R2 och tidigare, men mitt test utfördes på Windows Server 2012 R2 med SQL Server 2014 så jag kommer att kontakta Microsoft för att få dokumentet med bästa praxis uppdaterat.
Eftersom de flesta produktions-DBA:er inte tillhandahåller virtuella maskiner eller arbetar hårt i det utrymmet, och virtualiseringsingenjörer inte studerar den senaste och bästa SQL Server-tekniken, kan jag förstå hur denna viktiga information om hur buffertpoolen hanterar dynamiskt minne är okänd för många Av människor.
Även att följa artiklarna kan vara vilseledande. I artikeln Hyper-V Dynamic Memory Configuration Guide lyder beskrivningen för Startup RAM:
Anger mängden minne som krävs för att starta den virtuella maskinen. Värdet måste vara tillräckligt högt för att gästoperativsystemet ska kunna starta, men bör vara så lågt som möjligt för att möjliggöra optimalt minnesutnyttjande och potentiellt höga konsolideringsförhållanden.Optimalt minnesutnyttjande för vem, värden eller gästen? Om en virtualiseringsadministratör läste detta, skulle de sannolikt fastställa att det betyder det minsta minnet som tillåts för att starta operativsystemet.
Att vara ansvarig för SQL Server innebär att vi behöver känna till andra tekniker som kan påverka vår miljö. Med introduktionen av SAN och virtualisering behöver vi till fullo förstå hur saker i dessa miljöer kan påverka SQL Server negativt och, ännu viktigare, hur man effektivt kommunicerar problem till de personer som är ansvariga för dessa system. En DBA behöver inte nödvändigtvis veta hur man tillhandahåller lagring i ett SAN eller hur man tillhandahåller eller kan administrera en VMWare- eller Hyper-V-miljö, men de bör känna till grunderna om hur saker fungerar.
Genom att veta grunderna om hur ett SAN fungerar med lagringsarrayer, lagringsnätverk, multi-pathing och så vidare, samt hur hypervisorn arbetar med schemaläggning av CPU:er och lagringsallokering inom virtualisering, kan en DBA bättre kommunicera och felsöka när problem uppstår . Under åren har jag framgångsrikt arbetat med ett antal SAN- och virtualiseringsadministratörer för att bygga standarder för SQL Server. Dessa standarder är unika för SQL Server och gäller inte nödvändigtvis för webb- eller applikationsservrar.
DBA:er kan inte riktigt lita på SAN- och virtualiseringsadministratörer för att fullt ut förstå bästa praxis för SQL Server, oavsett hur trevligt det skulle vara, så vi måste utbilda oss så gott vi kan om hur deras expertområden kan påverka oss.
Under mitt testande använde jag en fråga från Paul Randals blogginlägg, Performance issues from wasted buffer pool memory, för att avgöra hur mycket buffertpool som AdventureWorks2014-databasen använde. Jag har inkluderat koden nedan:
SELECT
(CASE WHEN ([database_id] = 32767)
THEN N'Resource Database'
ELSE DB_NAME ([database_id]) END) AS [DatabaseName],
COUNT (*) * 8 / 1024 AS [MBUsed],
SUM (CAST ([free_space_in_bytes] AS BIGINT)) / (1024 * 1024) AS [MBEmpty]
FROM sys.dm_os_buffer_descriptors
GROUP BY [database_id]; Den här koden är också bra för att felsöka vilken av dina databaser som förbrukar större delen av din buffertpool så att du kan veta vilken databas du bör fokusera på att ställa in de höga kostnadsfrågorna. Om du är en Hyper-V-butik, kolla med din administratör för att se om Dynamic Memory kan konfigureras på ett sådant sätt att det påverkar din server negativt.