Har du någonsin kontaktat Microsoft eller en Microsoft-partner och diskuterat med dem vad det skulle kosta att flytta till molnet? Om så är fallet kanske du har hört talas om Azure SQL Database DTU-kalkylatorn, och du kanske också har läst om hur den har omvänt konstruerats av Andy Mallon. DTU-kalkylatorn är ett kostnadsfritt verktyg som du kan använda för att ladda upp prestandastatistik från din server och använda data för att bestämma lämplig servicenivå om du skulle migrera den servern till en Azure SQL-databas (eller till en elastisk SQL Database-pool).
För att göra detta måste du antingen schemalägga eller köra ett skript manuellt (kommandorad eller Powershell, tillgänglig för nedladdning på DTU-kalkylatorns webbplats) under en period med en typisk produktionsbelastning.
Om du försöker analysera en stor miljö, eller vill analysera data från specifika tidpunkter, kan detta bli ett jobbigt. I många fall har många DBA:er en smak av övervakningsverktyg som redan samlar in prestandadata för dem. I många fall är det antagligen antingen redan att fånga de mätvärden som behövs, eller så kan den enkelt konfigureras för att fånga den data du behöver. Idag ska vi titta på hur man kan dra fördel av SentryOne så att vi kan tillhandahålla lämplig data till DTU-kalkylatorn.
Till att börja med, låt oss titta på informationen som hämtas av kommandoradsverktyget och PowerShell-skriptet som finns på DTU-kalkylatorns webbplats; det finns fyra prestandamonitorräknare som den fångar upp:
- Processor – % processortid
- Logisk disk – Disk läser/sek
- Logisk disk – Diskskrivning/sek
- Databas – Loggbytes tömda/sek
Det första steget är att avgöra om dessa mätvärden redan är infångade som en del av datainsamlingen i SQL Sentry. För upptäckt föreslår jag att du läser det här blogginlägget av Jason Hall, där han talar om hur informationen är upplagd och hur du kan fråga efter den. Jag tänker inte gå igenom varje steg i detta här, men uppmuntrar dig att läsa och lägga till ett bokmärke för hela bloggserien.
När jag tittade igenom SentryOne-databasen upptäckte jag att 3 av de 4 räknarna redan fångades som standard. Den enda som saknades var [Database – Log Bytes Flushed/sec] , så jag behövde kunna slå på det. Det fanns ett annat blogginlägg av Justin Randall som förklarar hur man gör det.
Kort sagt, du kan fråga [PerformanceAnalysisCounter] bord.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Du kommer att märka att [PerformanceAnalysisSampleIntervalID] som standard är inställd på 0 – detta betyder att den är inaktiverad. Du måste köra följande kommando för att aktivera detta. Dra bara ut ID:t från SELECT-frågan du just körde och använd den i denna UPPDATERING:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Efter att ha kört uppdateringen måste du starta om SentryOne-övervakningstjänsterna som är relevanta för detta mål, så att den nya räknardatan kan samlas in.
Observera att jag ställer in [PerformanceAnalysisSampleIntervalID] till 1 så att data fångas var tionde sekund, men du kan fånga in dessa data mer sällan för att minimera storleken på insamlad data till priset av mindre noggrannhet. Se [PerformanceAnalysisSampleInterval] tabell för en lista över värden som du kan använda.
Förvänta dig inte att data ska börja flöda in i tabellerna omedelbart; detta kommer att ta tid att ta sig igenom systemet. Du kan söka efter population med följande fråga:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
När du har bekräftat att data dyker upp bör du ha data för var och en av mätvärdena som krävs av DTU-kalkylatorn, även om du kanske vill vänta med att extrahera det tills du har ett representativt urval från en fullständig arbetsbelastning eller konjunkturcykel.
Om du läser igenom Jasons blogginlägg kommer du att se att data lagras i olika sammanslagningstabeller och att var och en av dessa sammanställningstabeller har olika kvarhållningsgrader. Många av dessa är lägre än vad jag skulle vilja ha om jag analyserar arbetsbelastningar över en tidsperiod. Även om det kan vara möjligt att ändra dessa, är det kanske inte det klokaste. Eftersom det jag visar dig inte stöds, kanske du vill undvika att mixtra för mycket med SentryOne-inställningarna eftersom det kan ha en negativ inverkan på prestanda, tillväxt eller både och.
För att kompensera för detta skapade jag ett skript som låter mig extrahera den data jag behöver för de olika sammanslagningstabellerna och lagrar den data på sin egen plats, så att jag kan kontrollera min egen lagring och inte störa SentryOne-funktionaliteten.
TABELL:dbo.AzureDatabaseDTUData
Jag skapade en tabell som heter [AzureDatabaseDTUData] och lagrade den i SentryOne-databasen. Proceduren jag skapade kommer automatiskt att generera den här tabellen om den inte finns, så det finns inget behov av att göra detta manuellt om du inte vill anpassa var den lagras. Du kan lagra detta i en separat databas om du vill, du behöver bara redigera skriptet för att göra det. Tabellen ser ut så här:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Procedur:dbo.Custom_CollectDTUDataForDevice
Detta är den lagrade procedur som du kan använda för att hämta alla DTU-specifika data på en gång (förutsatt att du har samlat in loggbyte-räknaren under en tillräcklig tid), eller schemalägga den för att regelbundet lägga till den insamlade informationen tills du är redo att skicka resultatet till DTU-kalkylatorn. Precis som i tabellen ovan skapas proceduren i SentryOne-databasen, men du kan enkelt skapa den någon annanstans, lägg bara till tre- eller fyrdelade namn till objektreferenser. Gränssnittet till proceduren är som följer:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Obs :Hela proceduren är lite lång, så den bifogas till det här inlägget (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Det finns ett par parametrar du kan använda. Var och en har ett standardvärde, så du behöver inte ange dem om du är bra med standardvärdena.
- @DeviceID – Detta låter dig ange om du vill samla in data för en specifik SQL Server eller allt. Standard är -1, vilket betyder att kopiera alla bevakade SQL-servrar. Om du bara vill exportera information för en specifik instans, leta reda på
DeviceIDmotsvarande värden i[dbo].[Device]tabell och skicka det värdet. Du kan bara skicka en@DeviceIDåt gången, så om du vill gå igenom en uppsättning servrar kan du anropa proceduren flera gånger, eller så kan du ändra proceduren för att stödja en uppsättning enheter. - @DaysToPurge – Detta representerar den ålder vid vilken du vill ta bort data. Standard är 14 dagar, vilket innebär att du bara hämtar data som är upp till 14 dagar gamla, och all data som är äldre än 14 dagar i din anpassade tabell kommer att raderas.
De andra fyra parametrarna finns där för framtidssäkring, om SentryOne-numret för räknar-ID någonsin ändras.
Ett par anteckningar om manuset:
- När data hämtas tar den maxvärdet från den trunkerade minuten och exporterar den. Det betyder att det finns ett värde per mätvärde per minut, men det är det maxvärde som fångas. Detta är viktigt på grund av hur data måste presenteras för DTU-kalkylatorn.
- Första gången du kör exporten kan det ta lite längre tid. Detta beror på att den hämtar all data den kan baserat på dina parametervärden. Varje ytterligare körning, den enda data som extraheras är den som är ny sedan den senaste körningen, så den borde vara mycket snabbare.
- Du måste schemalägga denna procedur så att den körs enligt ett tidsschema som ligger före SentryOne-rensningsprocessen. Det jag har gjort är att skapa ett SQL Agent Job för att köras varje natt som samlar in all ny data sedan kvällen innan.
- Eftersom rensningsprocessen i SentryOne kan variera beroende på mätvärde, kan du sluta med rader i din kopia som inte innehåller alla fyra räknarna under en tidsperiod. Du kanske vill börja analysera dina data först från det att du startar extraktionsprocessen.
- Jag använde ett kodblock från befintliga SentryOne-procedurer för att bestämma sammanställningstabellen för varje räknare. Jag kunde ha hårdkodat de nuvarande namnen på tabellerna, men genom att använda SentryOne-metoden borde den vara framåtkompatibel med alla ändringar av de inbyggda sammanställningsprocesserna.
När din data väl har flyttats till en fristående tabell kan du använda en PIVOT-fråga för att omvandla den till den form som DTU-kalkylatorn förväntar sig.
Procedur:dbo.Custom_ExportDataForDTUCalculator
Jag skapade en annan procedur för att extrahera data till CSV-format. Koden för denna procedur är också bifogad (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Det finns tre parametrar:
- @DeviceID – Smallint som motsvarar en av enheterna du samlar in och som du vill skicka till kalkylatorn.
- @BeginTime – Datetime representerar starttiden, i lokal tid; till exempel
'2018-12-04 05:47:00.000'. Proceduren kommer att översättas till UTC. Om det utelämnas kommer det att samlas in från det tidigaste värdet i tabellen. - @EndTime – Datetime representerar sluttiden, återigen i lokal tid; till exempel
'2018-12-06 12:54:00.000'. Om den utelämnas kommer den att samlas upp till det senaste värdet i tabellen.
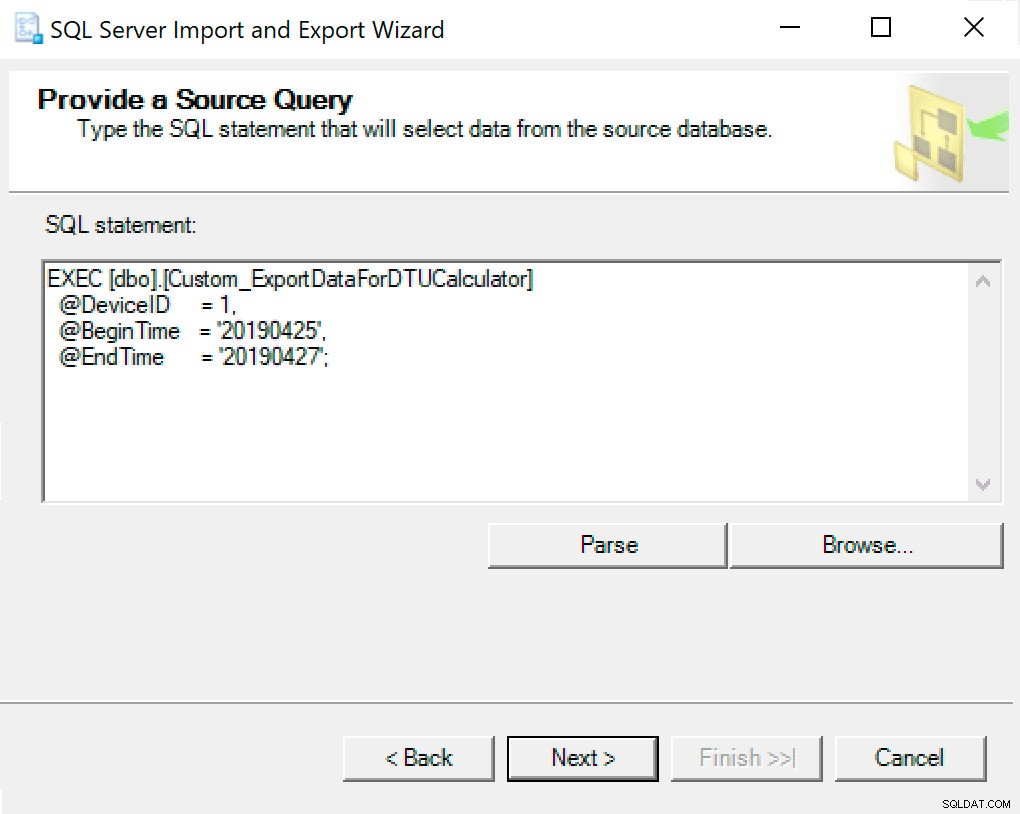
Ett exempel på exekvering, för att få all data som samlats in för SQLInstanceA mellan 4 december kl. 05.47 och 6 december kl. 12.54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Data kommer att behöva exporteras till en CSV-fil. Oroa dig inte för själva data; Jag såg till att skriva ut resultat så att det inte finns någon identifierande information om din server i csv-filen, bara datum och mätvärden.
Om du kör frågan i SSMS kan du högerklicka och exportera resultat; Du har dock begränsade alternativ här och du måste manipulera utdata för att få det format som förväntas av DTU-kalkylatorn. (Försök gärna och låt mig veta om du hittar ett sätt att göra detta.)
Jag rekommenderar att du bara använder exportguiden inbakad i SSMS. Högerklicka på databasen och gå till Uppgifter -> Exportera data. För din datakälla använd "SQL Server Native Client" och rikta den mot din SentryOne-databas (eller var du än har din kopia av data lagrad). För din destination kommer du att vilja välja "Flat fildestination." Bläddra till en plats, ge filen ett namn och spara filen som en CSV.
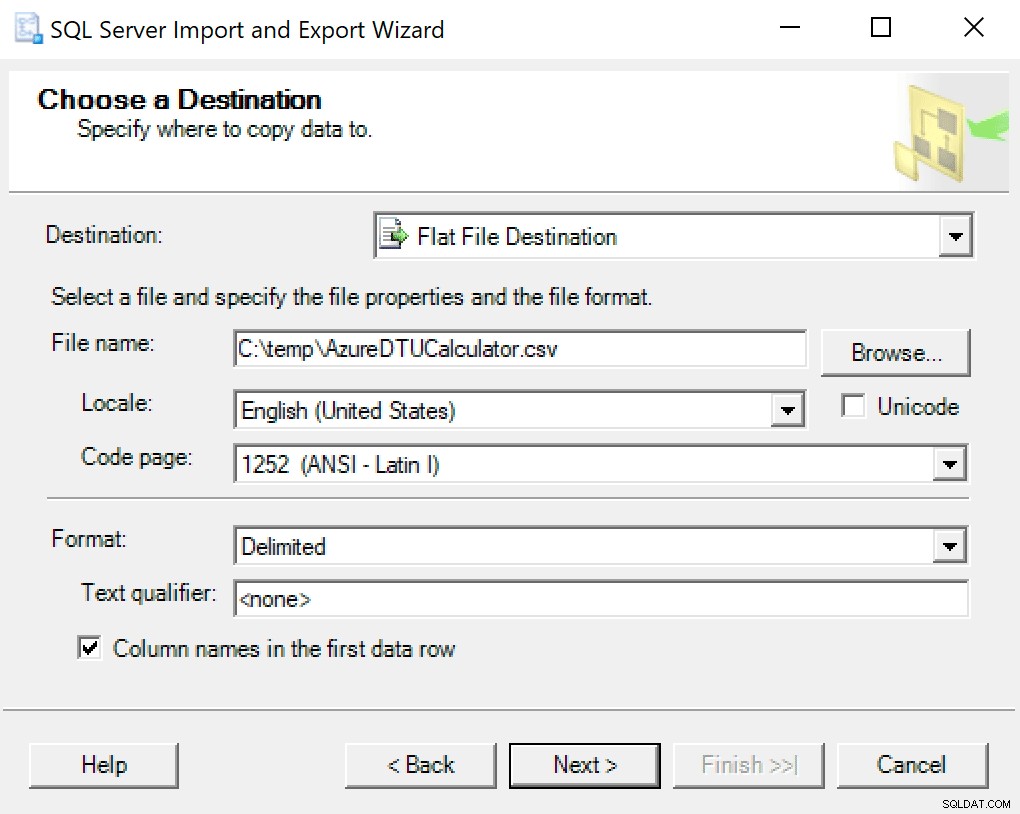
Var noga med att lämna teckentabellen ifred; vissa kan returnera fel. Jag vet att 1252 fungerar bra. Resten av värdena lämnas som standard.
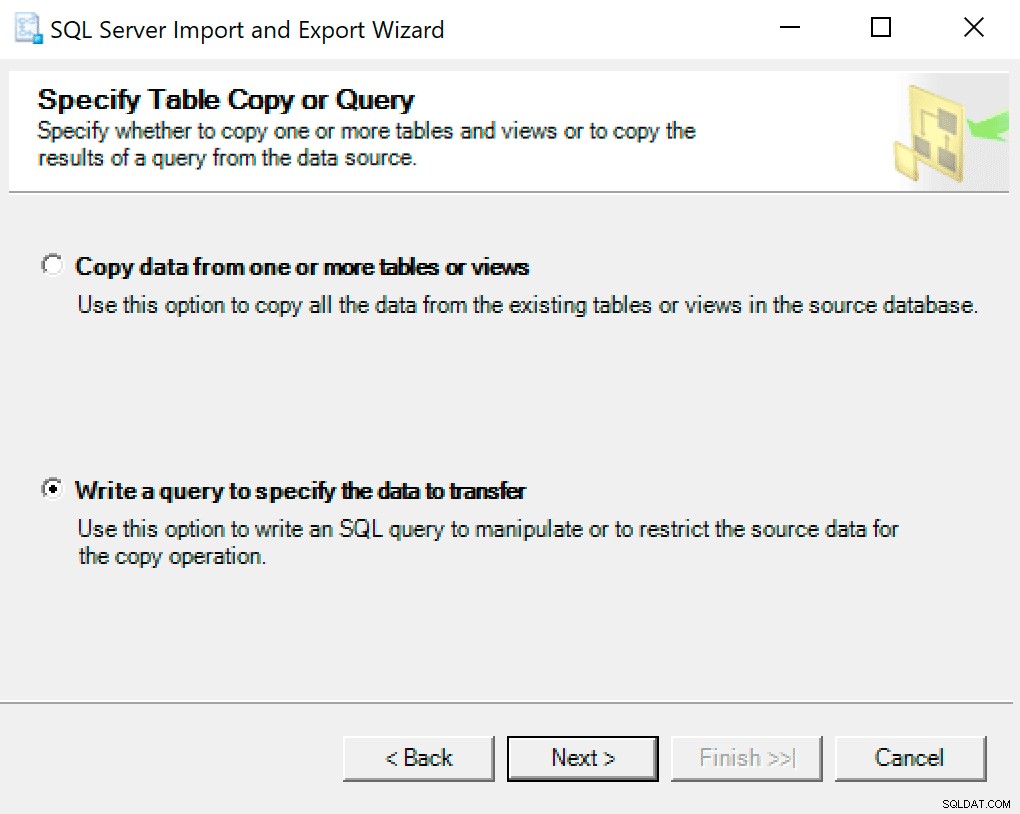
På nästa skärm väljer du alternativet Skriv en fråga för att ange vilken data som ska överföras .
I nästa fönster kopierar du proceduranropet med dina parametrar inställda i det. Klicka på nästa.
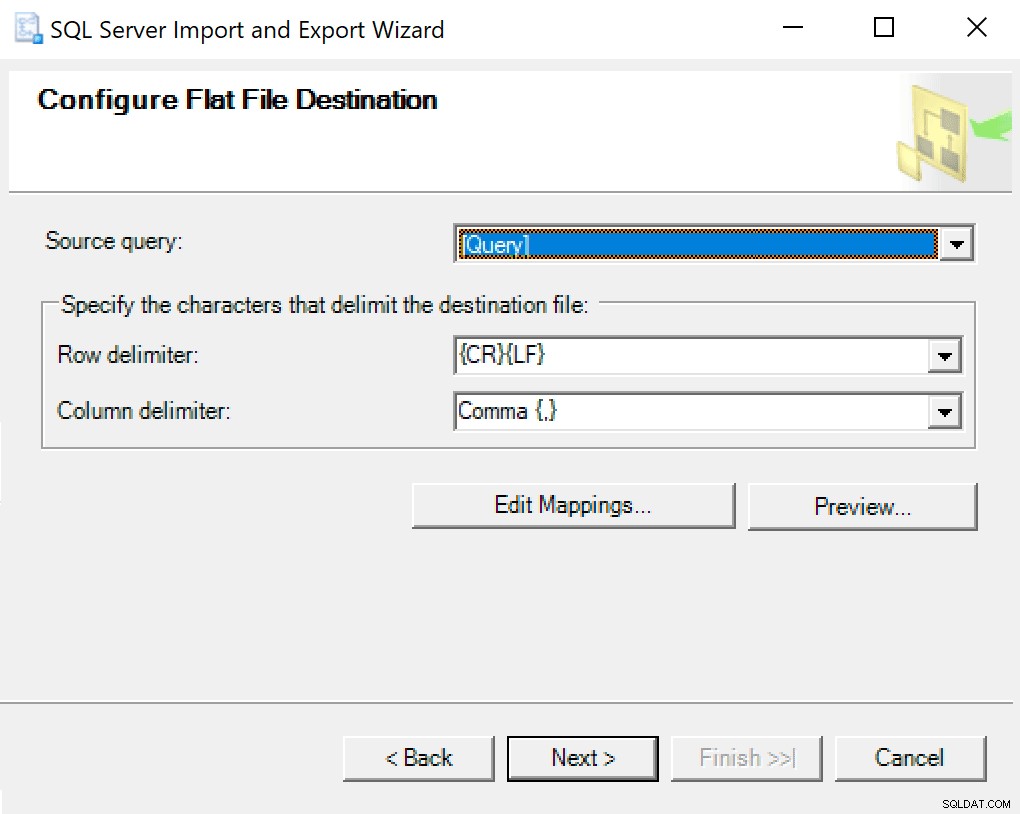
När du kommer till Configure Flat File Destination lämnar jag alternativen som standard. Här är en skärmdump om din är annorlunda:
Slå nästa och spring direkt. En fil kommer att skapas som du kommer att använda i det sista steget.
OBS :Du kan skapa ett SSIS-paket att använda för detta och sedan skicka igenom dina parametervärden till SSIS-paketet om du ska göra det här mycket. Detta skulle förhindra att du behöver gå igenom guiden varje gång.
Navigera till platsen där du sparade filen och kontrollera att den finns där. När du öppnar den ska den se ut ungefär så här:
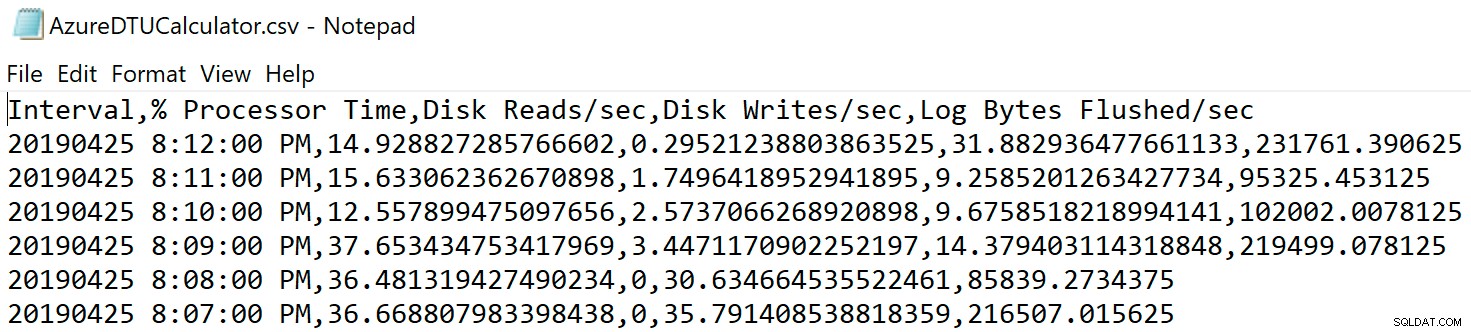
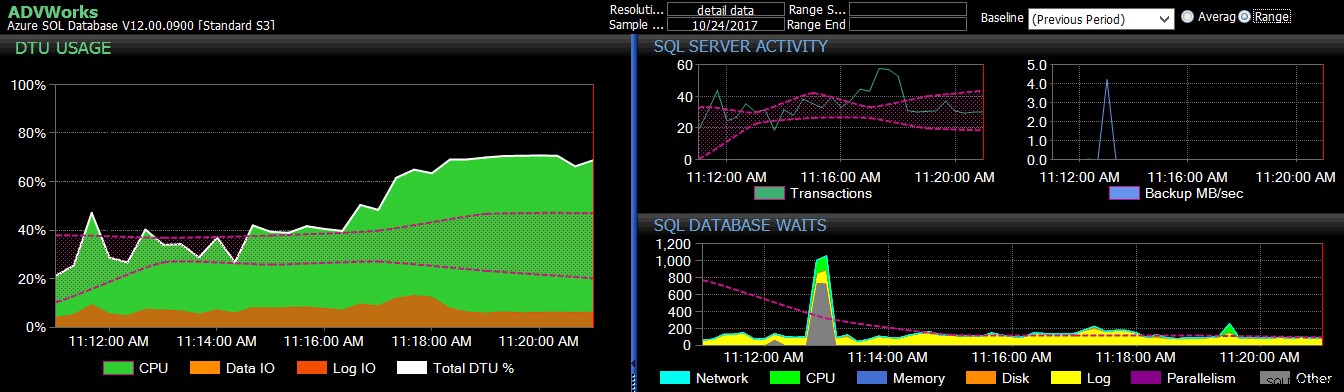
Öppna webbplatsen för DTU-kalkylatorn och scrolla ner till delen som säger "Ladda upp CSV-filen och beräkna." Ange antalet kärnor som servern har, ladda upp CSV-filen och klicka på Beräkna. Du får en uppsättning resultat så här (klicka på valfri bild för att zooma):
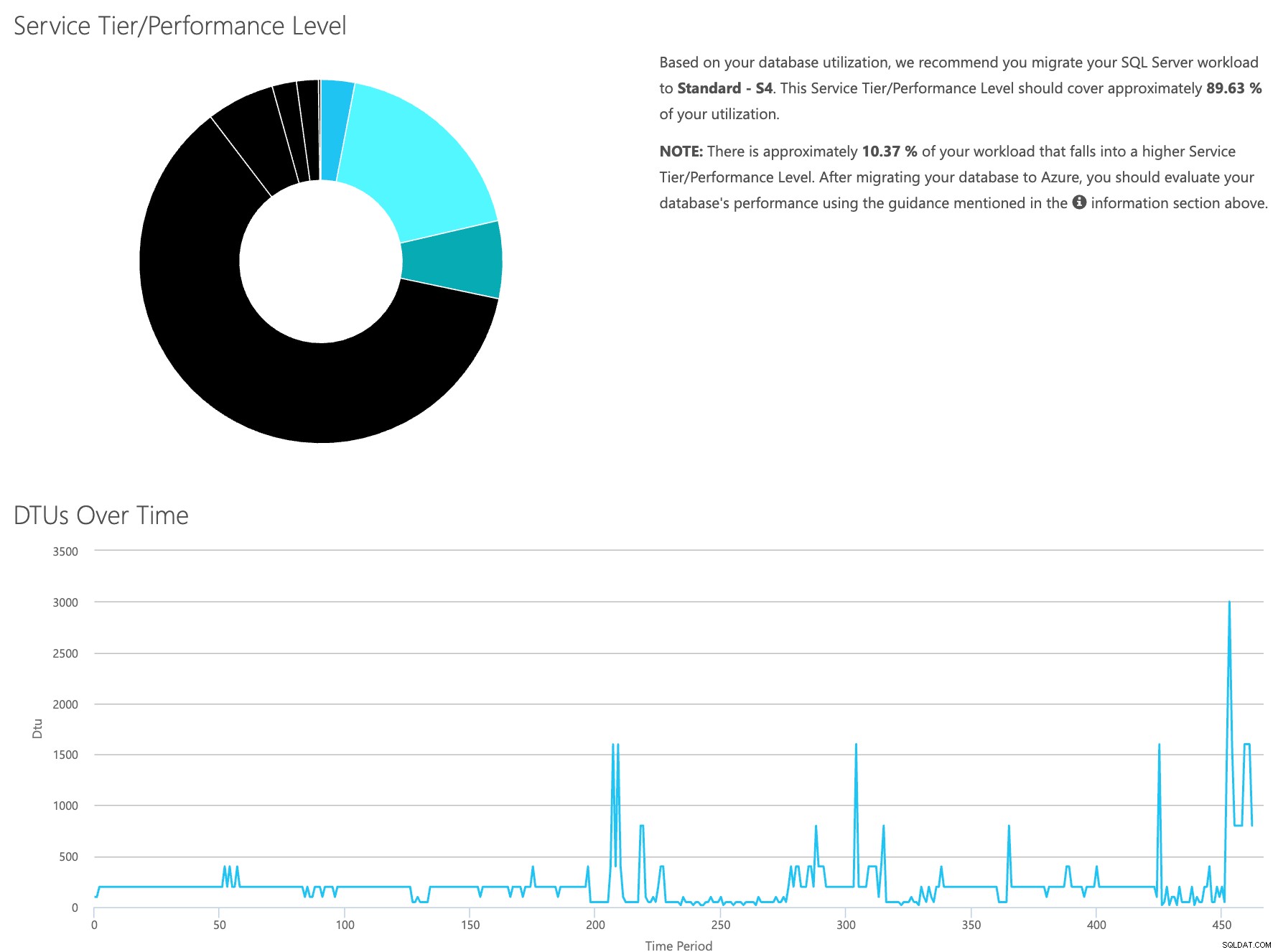
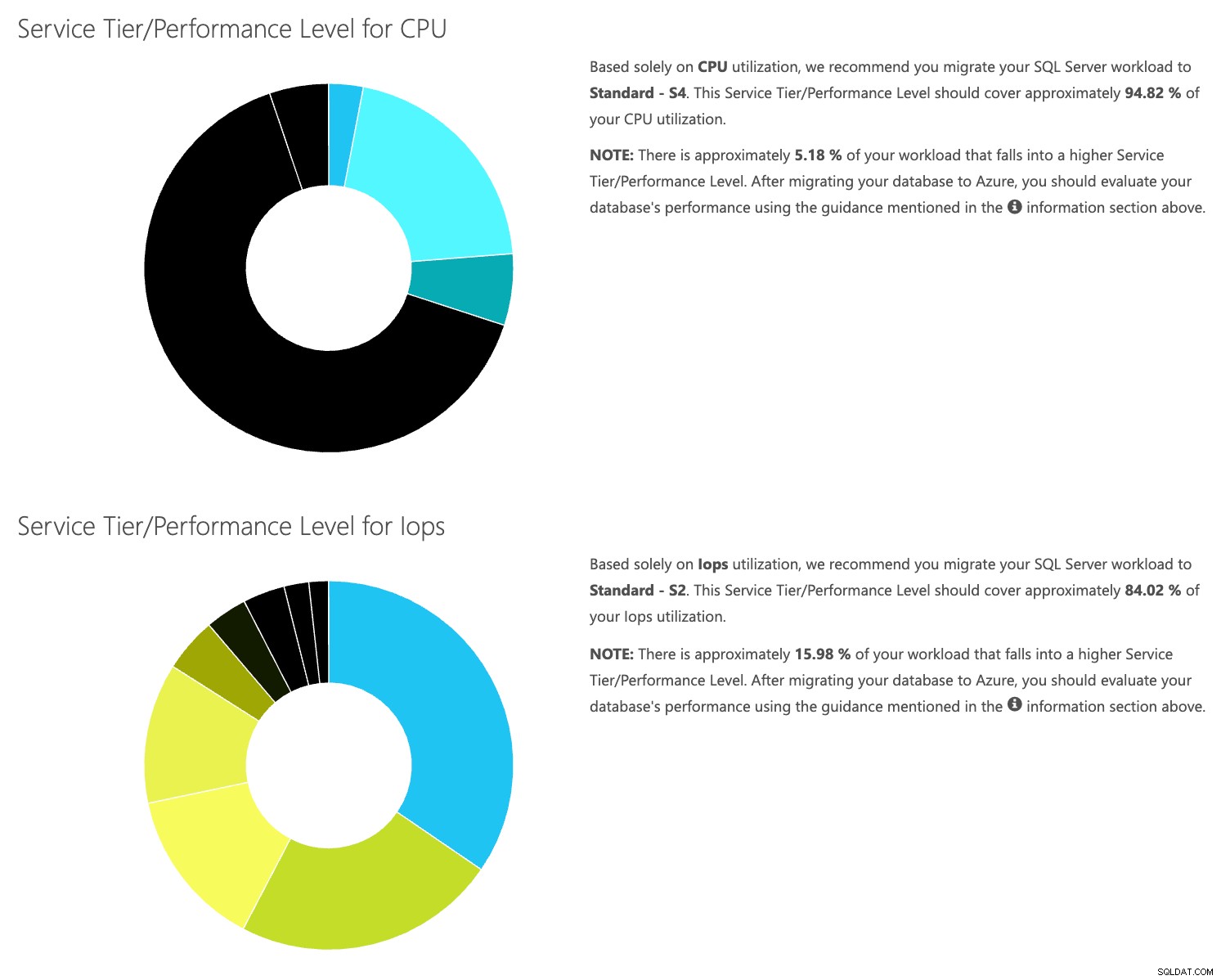
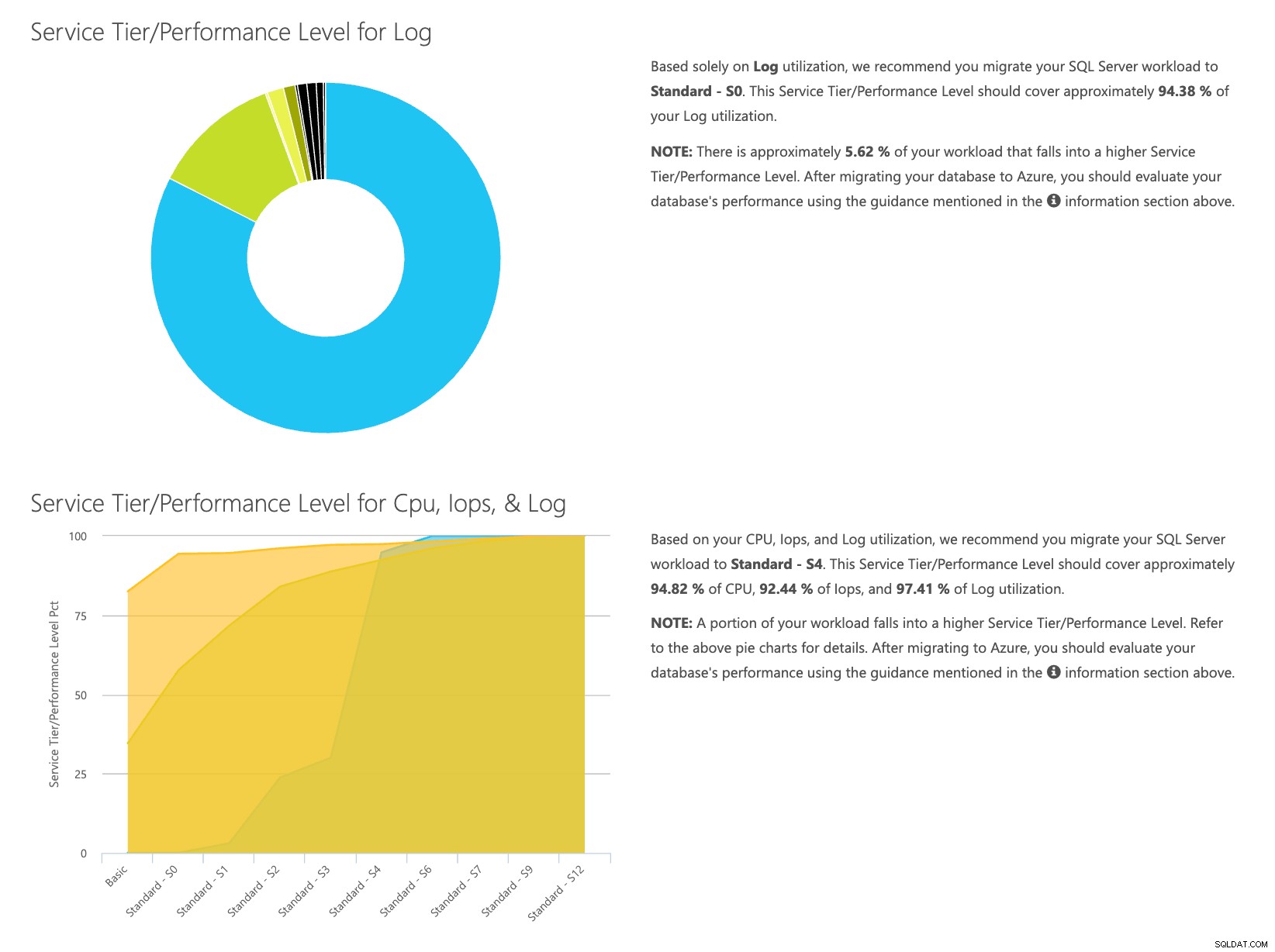
Eftersom du har data som lagras separat kan du analysera arbetsbelastningar från olika tidpunkter, och du kan göra detta utan att manuellt behöva köra\schemalägga kommandoverktyget\powershell-skriptet för en server som du redan använder SentryOne för att övervaka.
För att kort sammanfatta stegen, här är vad som behöver göras:
- Aktivera räknaren [Databas – Log Bytes Flushed/sek] och verifiera att data samlas in
- Kopiera data från SentryOne-tabellerna till din egen tabell (och schemalägg det där det är lämpligt).
- Exportera data från ny tabell i rätt format för DTU-kalkylatorn
- Ladda upp CSV-filen till DTU-kalkylatorn
För varje server/instans du funderar på att migrera till molnet och som du för närvarande övervakar med SQL Sentry, är detta ett relativt smärtfritt sätt att uppskatta både vilken typ av tjänstenivå du behöver och hur mycket det kommer att kosta. Du måste fortfarande övervaka den när den väl är där uppe; för det, kolla in SentryOne DB Sentry.
Om författaren
 Dustin Dorsey är för närvarande Managing Database Engineer för LifePoint Health där han leder ett team som ansvarar för att hantera och konstruera lösningar i databasteknologier för 90 sjukhus. Han har arbetat med och stöttat SQL Server främst inom vården sedan 2008 inom administration, arkitektur, utveckling och BI. Han brinner för att hitta sätt att lösa problem som plågar den vardagliga DBA och älskar att dela detta med andra. Han kan hittas som talar vid SQL-gemenskapsevenemang, samt bloggar på DustinDorsey.com.
Dustin Dorsey är för närvarande Managing Database Engineer för LifePoint Health där han leder ett team som ansvarar för att hantera och konstruera lösningar i databasteknologier för 90 sjukhus. Han har arbetat med och stöttat SQL Server främst inom vården sedan 2008 inom administration, arkitektur, utveckling och BI. Han brinner för att hitta sätt att lösa problem som plågar den vardagliga DBA och älskar att dela detta med andra. Han kan hittas som talar vid SQL-gemenskapsevenemang, samt bloggar på DustinDorsey.com.