Nuförtiden är det vanligt att se en stor mängd data i ett företags databas, men beroende på storleken kan det vara svårt att hantera och prestandan kan påverkas under hög trafik om vi inte konfigurerar eller implementerar det på ett korrekt sätt . I allmänhet, om vi har en enorm databas och vi vill ha en låg svarstid, vill vi skala den. PostgreSQL är inte undantaget från denna punkt. Det finns många tillgängliga metoder för att skala PostgreSQL, men låt oss först lära oss vad skalning är.
Skalbarhet är egenskapen hos ett system/databas för att hantera en växande mängd krav genom att lägga till resurser.
Orsakerna till denna mängd krav kan vara tidsmässiga, till exempel om vi lanserar en rabatt på en rea, eller permanent, för en ökning av kunder eller anställda. I vilket fall som helst bör vi kunna lägga till eller ta bort resurser för att hantera dessa förändringar på krav eller ökad trafik.
I den här bloggen kommer vi att titta på hur vi kan skala vår PostgreSQL-databas och när vi behöver göra det.
Horisontell skalning vs vertikal skalning
Det finns två huvudsakliga sätt att skala vår databas...
- Horisontell skalning (utskalning):Det utförs genom att lägga till fler databasnoder som skapar eller ökar ett databaskluster.
- Vertikal skalning (uppskalning):Det utförs genom att lägga till fler hårdvaruresurser (CPU, minne, disk) till en befintlig databasnod.
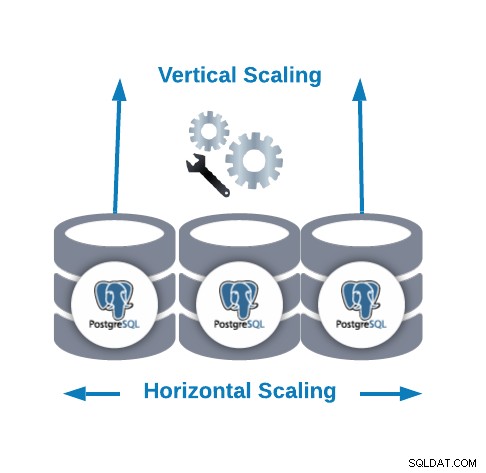
För horisontell skalning kan vi lägga till fler databasnoder som slavnoder. Det kan hjälpa oss att förbättra läsprestandan och balansera trafiken mellan noderna. I det här fallet måste vi lägga till en lastbalanserare för att distribuera trafik till rätt nod beroende på policyn och nodens tillstånd.
För att undvika en enda felpunkt genom att bara lägga till en lastbalanserare bör vi överväga att lägga till två eller flera lastbalanseringsnoder och använda något verktyg som "Keepalived", för att säkerställa tillgängligheten.
Eftersom PostgreSQL inte har inbyggt stöd för flera master, om vi vill implementera det för att förbättra skrivprestandan måste vi använda ett externt verktyg för denna uppgift.
För vertikal skalning kan det behövas att ändra någon konfigurationsparameter för att tillåta PostgreSQL att använda en ny eller bättre hårdvarururs. Låt oss se några av dessa parametrar från PostgreSQL-dokumentationen.
- work_mem:Anger mängden minne som ska användas av interna sorteringsoperationer och hashtabeller innan skrivning till temporära diskfiler. Flera löpsessioner kan göra sådana operationer samtidigt, så det totala minnet som används kan vara många gånger värdet av work_mem.
- maintenance_work_mem:Anger den maximala mängden minne som ska användas av underhållsoperationer, som VACUUM, CREATE INDEX och ALTER TABLE ADD FOREIGN KEY. Större inställningar kan förbättra prestanda för dammsugning och för att återställa databasdumpar.
- autovacuum_work_mem:Anger den maximala mängden minne som ska användas av varje autovacuum-arbetarprocess.
- autovacuum_max_workers:Anger det maximala antalet autovacuumprocesser som kan köras samtidigt.
- max_worker_processes:Anger det maximala antalet bakgrundsprocesser som systemet kan stödja. Ange gränsen för processen som dammsugning, kontrollpunkter och fler underhållsjobb.
- max_parallel_workers:Anger det maximala antalet arbetare som systemet kan stödja för parallella operationer. Parallella arbetare tas från poolen av arbetsprocesser som fastställts av föregående parameter.
- max_parallel_maintenance_workers:Anger det maximala antalet parallella arbetare som kan startas av ett enda verktygskommando. För närvarande är det enda parallella verktygskommandot som stöder användningen av parallella arbetare CREATE INDEX, och endast när man bygger ett B-trädindex.
- effective_cache_size:Ställer in planerarens antagande om den effektiva storleken på diskcachen som är tillgänglig för en enda fråga. Detta tas med i uppskattningar av kostnaden för att använda ett index; ett högre värde gör det mer sannolikt att indexskanningar kommer att användas, ett lägre värde gör det mer sannolikt att sekventiella skanningar kommer att användas.
- shared_buffers:Anger mängden minne som databasservern använder för delade minnesbuffertar. Inställningar som är betydligt högre än minimum krävs vanligtvis för bra prestanda.
- temp_buffers:Anger det maximala antalet temporära buffertar som används av varje databassession. Dessa är sessionslokala buffertar som endast används för åtkomst till tillfälliga tabeller.
- effective_io_concurrency:Anger antalet samtidiga disk I/O-operationer som PostgreSQL förväntar sig kan exekveras samtidigt. Att höja detta värde kommer att öka antalet I/O-operationer som varje enskild PostgreSQL-session försöker initiera parallellt. För närvarande påverkar den här inställningen bara bitmappshögskanningar.
- max_connections:Bestämmer det maximala antalet samtidiga anslutningar till databasservern. Genom att öka denna parameter kan PostgreSQL köra fler backend-processer samtidigt.
Vid det här laget finns det en fråga som vi måste ställa. Hur kan vi veta om vi behöver skala vår databas och hur kan vi veta det bästa sättet att göra det?
Övervakning
Att skala vår PostgreSQL-databas är en komplex process, så vi bör kontrollera några mätvärden för att kunna bestämma den bästa strategin för att skala den.
Vi kan övervaka CPU, minne och diskanvändning för att avgöra om det finns något konfigurationsproblem eller om vi faktiskt behöver skala vår databas. Om vi till exempel ser en hög serverbelastning men databasaktiviteten är låg, behövs det förmodligen inte för att skala den, vi behöver bara kontrollera konfigurationsparametrarna för att matcha den med våra hårdvaruresurser.
Att kontrollera diskutrymmet som används av PostgreSQL-noden per databas kan hjälpa oss att bekräfta om vi behöver mer disk eller till och med en tabellpartitionering. För att kontrollera diskutrymmet som används av en databas/tabell kan vi använda någon PostgreSQL-funktion som pg_database_size eller pg_table_size.
Från databassidan bör vi kontrollera
- Anslutningsmängd
- Köra frågor
- Indexanvändning
- Uppsvällning
- Replikeringsfördröjning
Dessa kan vara tydliga mätvärden för att bekräfta om skalningen av vår databas behövs.
ClusterControl som ett skalnings- och övervakningssystem
ClusterControl kan hjälpa oss att hantera både skalningssätt som vi såg tidigare och att övervaka alla nödvändiga mätvärden för att bekräfta skalningskravet. Låt oss se hur...
Om du inte använder ClusterControl ännu kan du installera den och distribuera eller importera din nuvarande PostgreSQL-databas genom att välja alternativet "Importera" och följa stegen för att dra nytta av alla ClusterControl-funktioner som säkerhetskopiering, automatisk failover, varningar, övervakning, och mer.
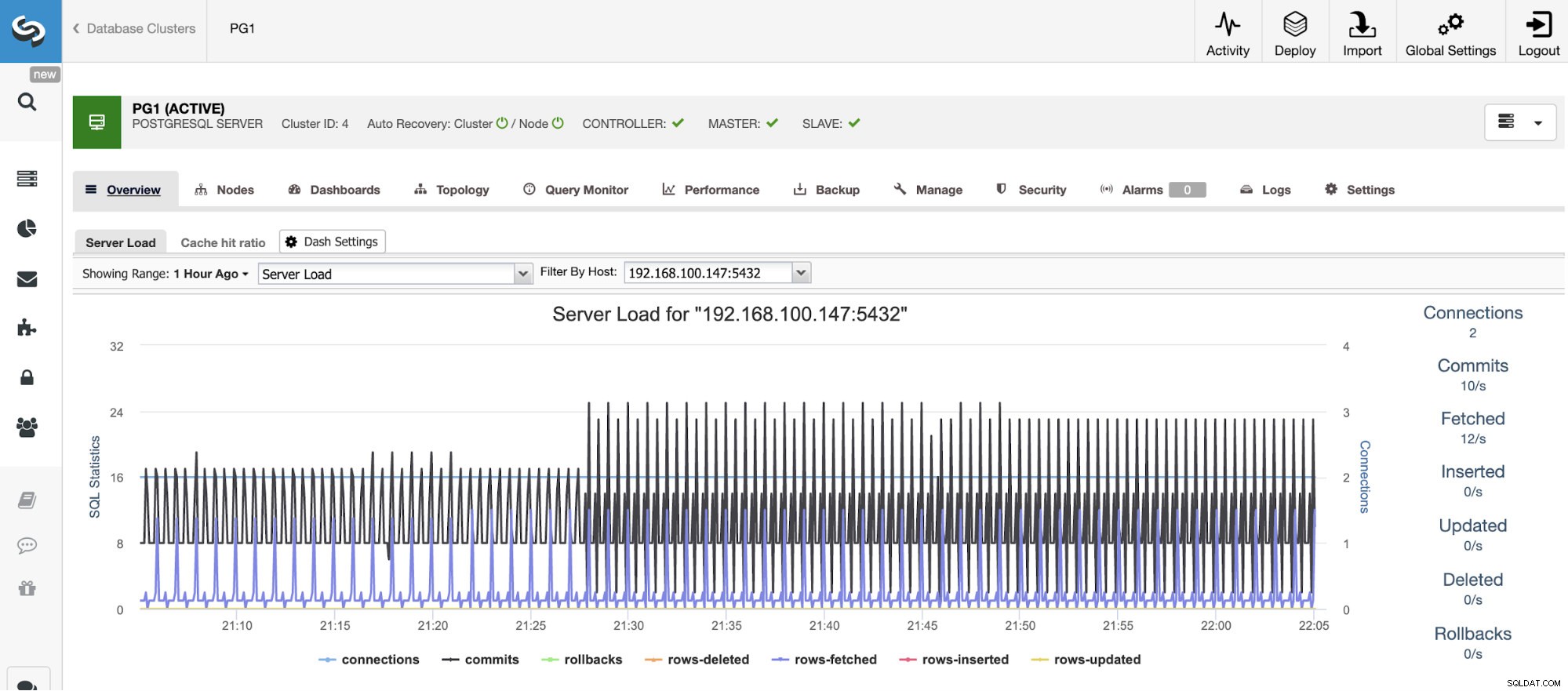
Horisontell skalning
För horisontell skalning, om vi går till klusteråtgärder och väljer "Lägg till replikeringsslav", kan vi antingen skapa en ny replik från början eller lägga till en befintlig PostgreSQL-databas som en replik.
Låt oss se hur det kan vara en väldigt enkel uppgift att lägga till en ny replikeringsslav.
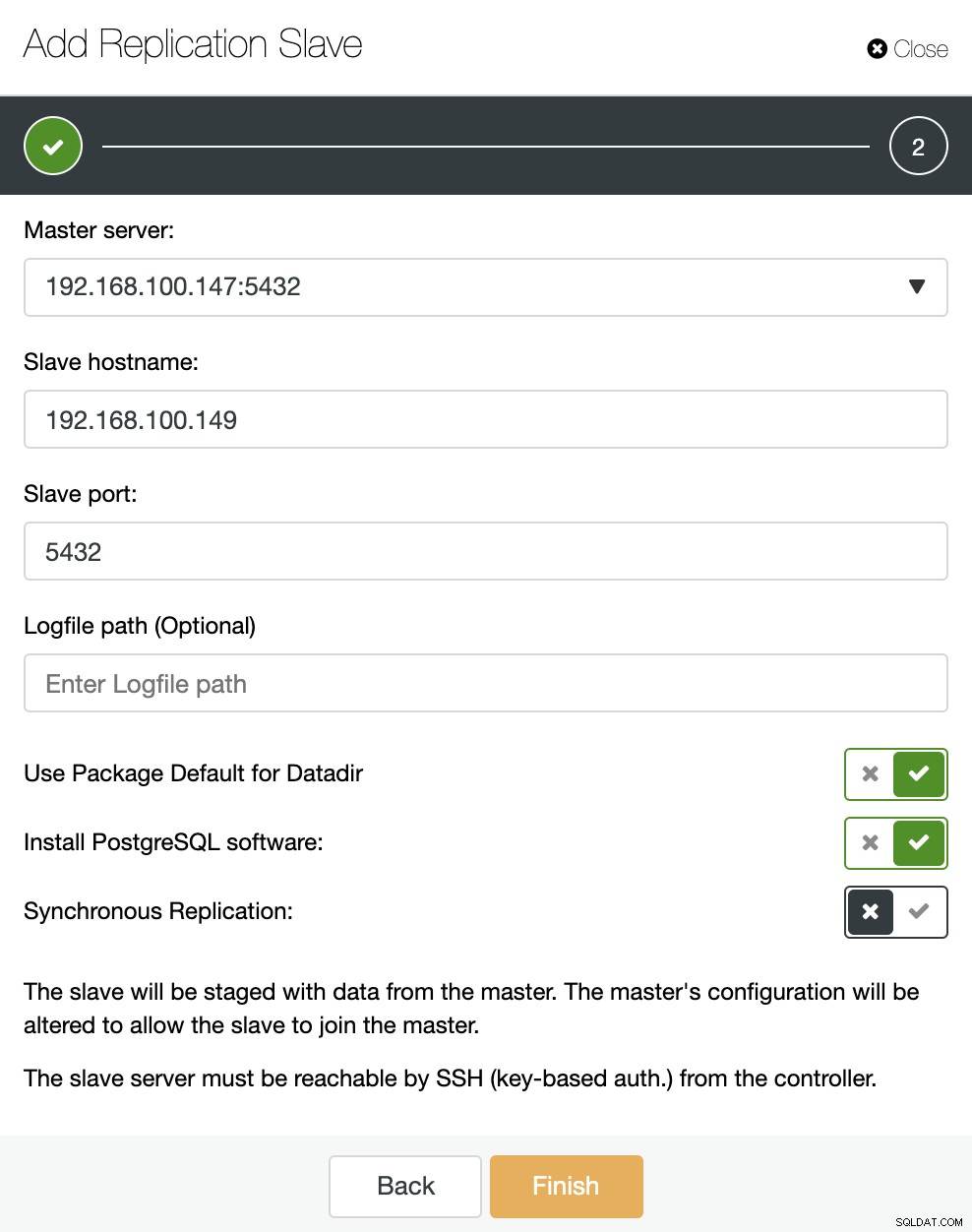
Som du kan se på bilden behöver vi bara välja vår Masterserver, ange IP-adressen för vår nya slavserver och databasporten. Sedan kan vi välja om vi vill att ClusterControl ska installera programvaran åt oss och om replikeringsslaven ska vara Synchronous eller Asynchronous.
På så sätt kan vi lägga till så många repliker som vi vill och sprida lästrafik mellan dem med en lastbalanserare, som vi också kan implementera med ClusterControl.
Om vi nu går till klusteråtgärder och väljer "Lägg till lastbalanserare", kan vi distribuera en ny HAProxy Load Balancer eller lägga till en befintlig.
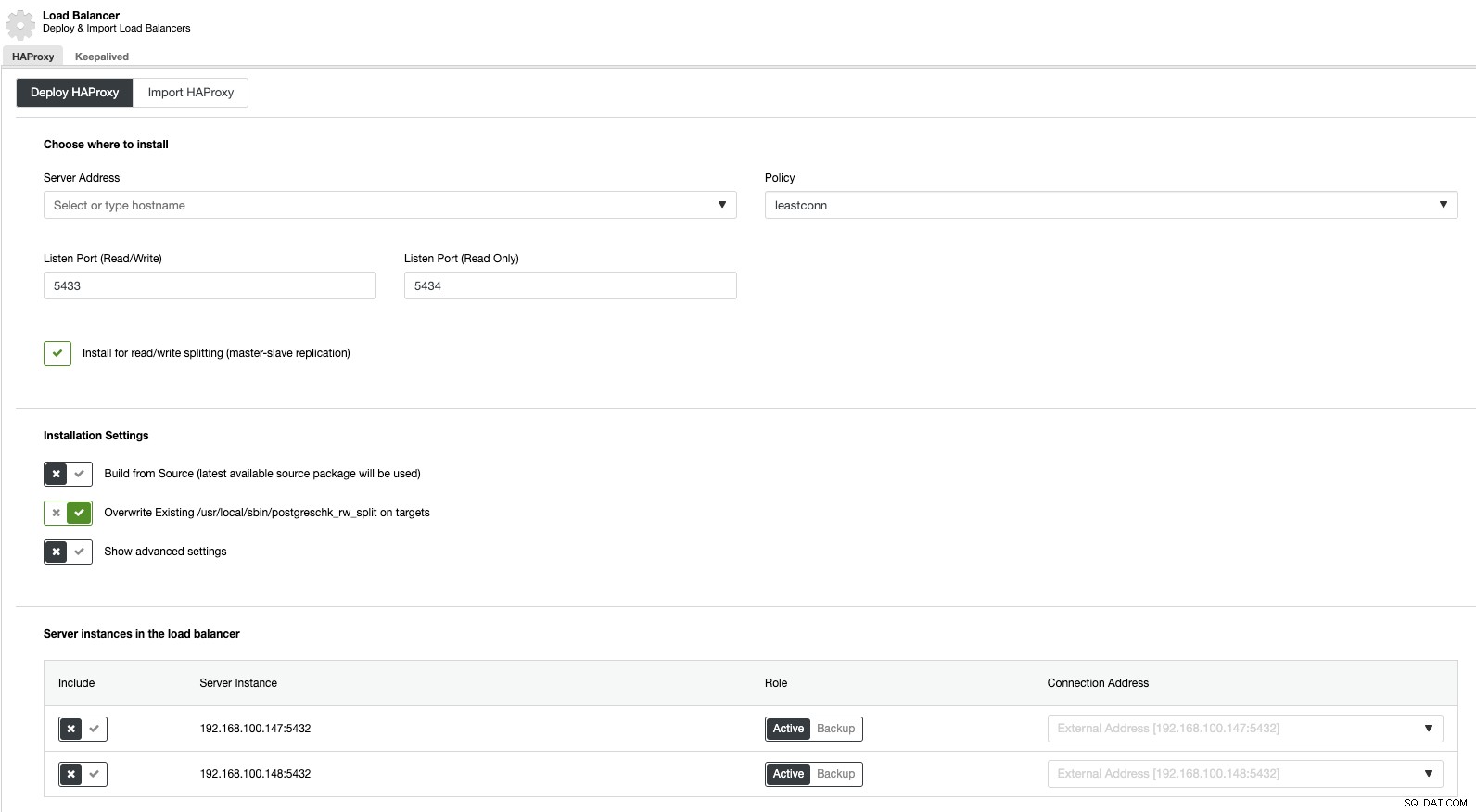
Och sedan, i samma lastbalanseringssektion, kan vi lägga till en Keepalved-tjänst som körs på lastbalanseringsnoderna för att förbättra vår miljö med hög tillgänglighet.
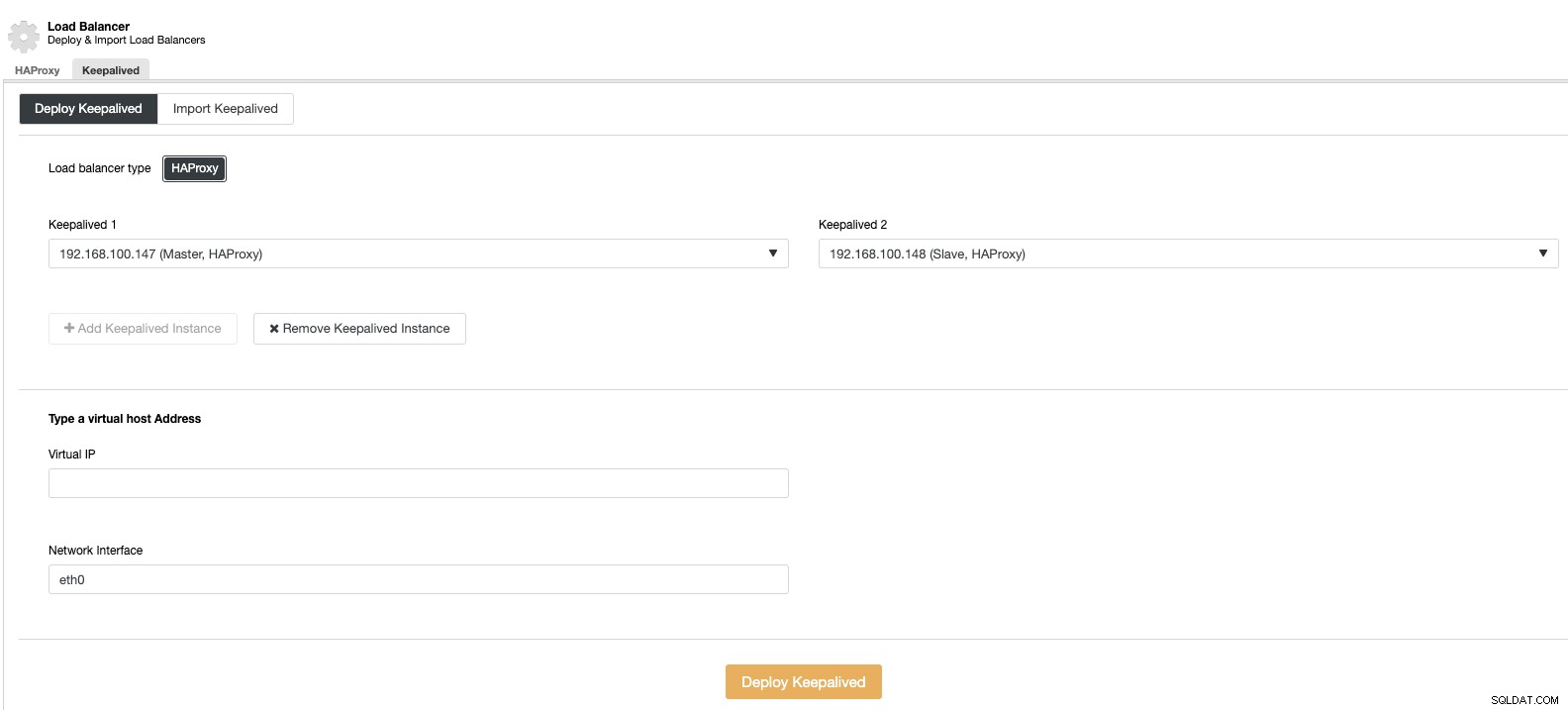
Vertikal skalning
För vertikal skalning kan vi med ClusterControl övervaka våra databasnoder från både operativsystemet och databassidan. Vi kan kontrollera vissa mätvärden som CPU-användning, minne, anslutningar, vanliga frågor, körfrågor och ännu mer. Vi kan också aktivera avsnittet Dashboard, vilket gör att vi kan se mätvärdena mer detaljerat och på ett vänligare sätt våra mätvärden.
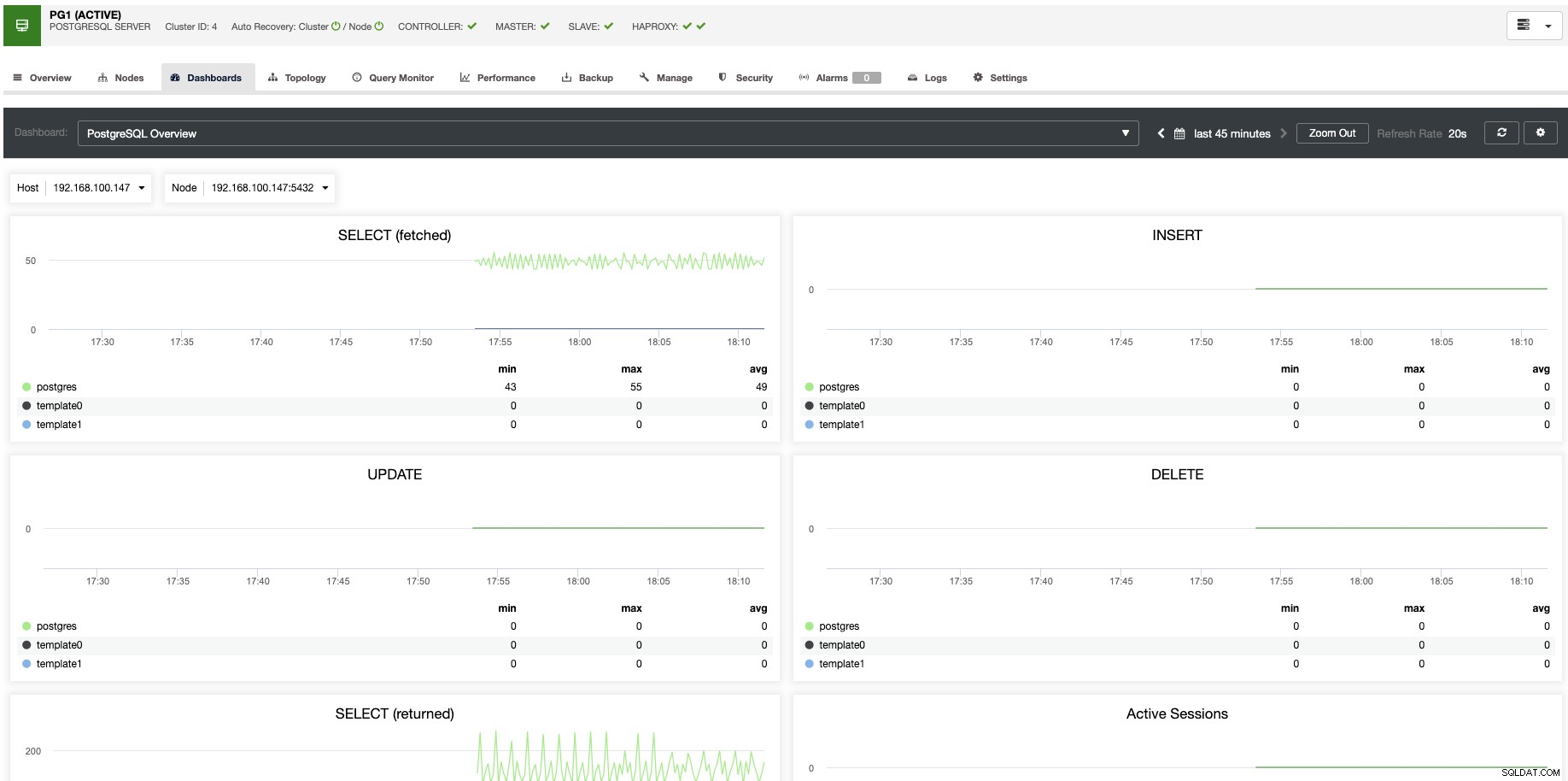
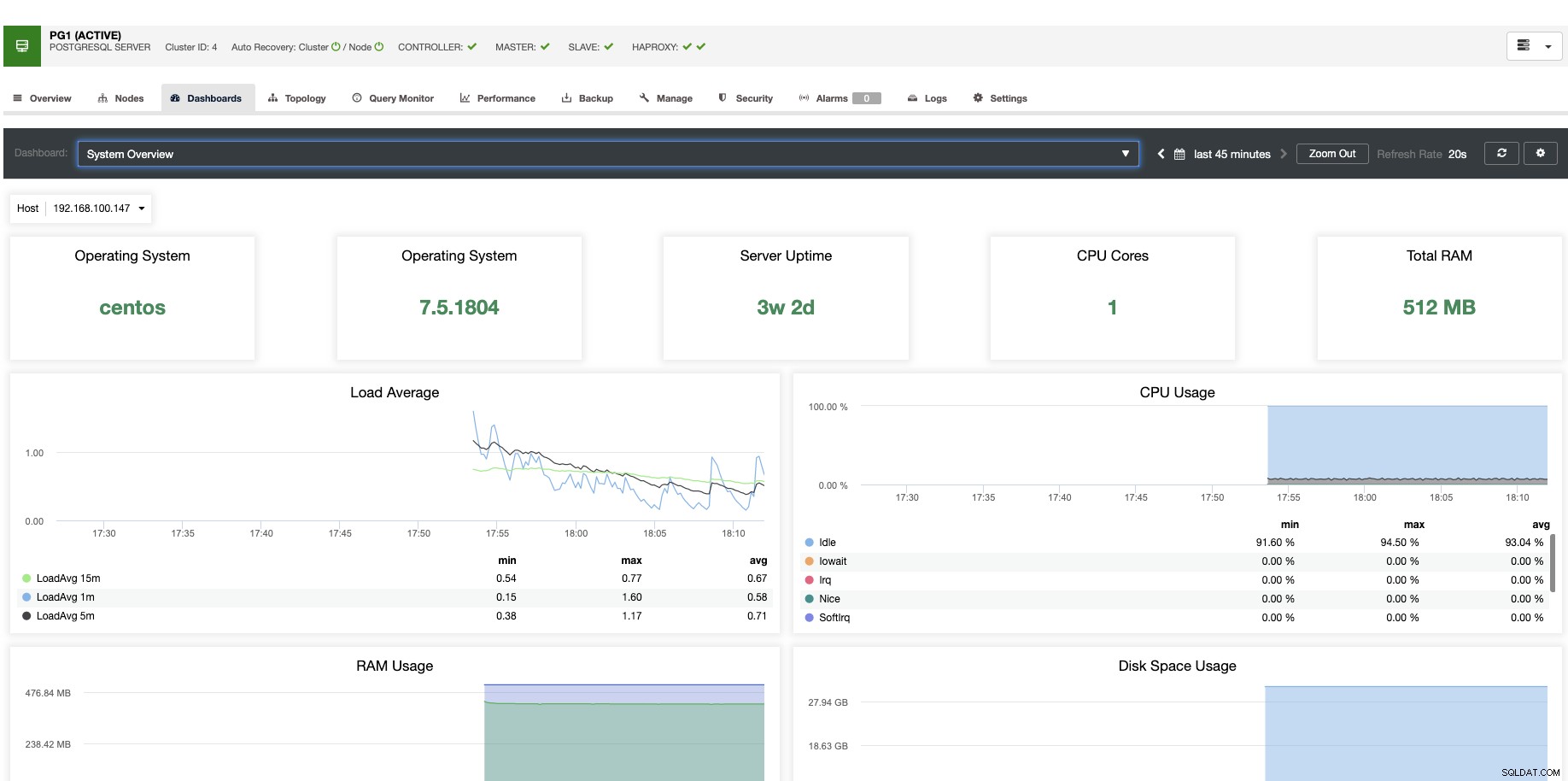
Från ClusterControl kan du också utföra olika hanteringsuppgifter som Reboot Host, Rebuild Replication Slave eller Promote Slave, med ett klick.
Slutsats
Att skala ut PostgreSQL-databaser kan vara en tidskrävande uppgift. Vi måste veta vad vi behöver skala och vad det bästa sättet är att göra det. I slutändan blir det ganska betungande att hantera och skala kluster manuellt efter en viss punkt, så de flesta vänder sig till verktyg som vårt.
Om du väljer den manuella rutten, kolla in när du bör överväga att lägga till en extra nod till ditt kluster. Vill du slippa krånglet? Utvärdera ClusterControl gratis i 30 dagar för att se hur dess funktioner gör det enkelt och effektivt att hantera storskalig öppen källkod.
Hur du än vill hantera och skala dina databaser, följ oss på Twitter eller LinkedIn, eller prenumerera på vårt nyhetsbrev för att få de senaste nyheterna och bästa praxis när du hanterar öppen källkodsbaserad databasinfrastruktur, så ses vi snart!