Medan Jeff Atwood och Joe Celko tycks tycka att kostnaden för GUID inte är någon större grej (se Jeffs blogginlägg, "Primary Keys:IDs versus GUIDs," och denna nyhetsgruppstråd, med titeln "Identity vs. Uniqueidentifier"), andra experter – mer specifikt index- och arkitekturexperter som fokuserar på SQL Server-utrymmet – tenderar att inte hålla med. Till exempel går Kimberly Tripp över några detaljer i sitt inlägg, "Diskutrymme är billigt – DET ÄR INTE POINT!", där hon förklarar att effekten inte bara är på diskutrymme och fragmentering, utan ännu viktigare på indexstorlek och minne fotavtryck.
Det Kimberly säger är verkligen sant – jag stöter på "diskutrymmet är billigt" motiveringen för GUIDs hela tiden (exempel från bara förra veckan). Det finns andra skäl för GUID, inklusive behovet av att generera unika identifierare utanför databasen (och ibland innan raden faktiskt skapas), och behovet av unika identifierare över separata distribuerade system (och där identitetsintervall inte är praktiska). Men jag vill verkligen skingra myten att GUID:er inte kostar så mycket, för det gör de, och du måste väga in dessa kostnader i ditt beslut.
Jag gav mig ut på det här uppdraget för att testa prestandan för olika nyckelstorlekar, givet samma data över samma antal rader, med samma index och ungefär samma arbetsbelastning (att spela om *exakt* samma arbetsbelastning kan vara ganska utmanande). Jag ville inte bara mäta de grundläggande sakerna som indexstorlek och indexfragmentering, utan även effekterna som dessa har längre fram, som:
- påverkan på buffertpoolanvändning
- frekvens av "dåliga" siddelningar
- övergripande inverkan på realistisk arbetsbelastningslängd
- påverkan på genomsnittliga körtider för enskilda frågor
- påverkan på körtidens varaktighet för efterutlösare
- påverkan på tempdb-användning
Jag kommer att använda en mängd olika tekniker för att undersöka denna data, inklusive utökade händelser, standardspårningen, tempdb-relaterade DMV:er och SQL Sentry Performance Advisor.
Inställningar
Först skapade jag en miljon kunder att lägga in i en seed-tabell med hjälp av lite inbyggd SQL Server-metadata; detta skulle säkerställa att de "slumpmässiga" kunderna skulle bestå av samma naturliga data under varje test.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMARY KEY CLUSTERED, FirstName NVARCHAR(64), AfterName NVARCHAR(64), EMail NVARCHAR(320) NOT NULL UNIQUE, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAX(a), n =MAX(NEWID()) FRÅN ( VÄLJ fn, ln, em, a, r =ROW_NUMBER() ÖVER (PARTITION BY em ORDER BY em) FROM ( VÄLJ TOP (2000000) fn =LEFT(o.name, 64), ln =LEFT(c.name, 64), em =LEFT(o.name, LEN(c.name)%5+1) + '.' + LEFT(c. name, LEN(o.name)%5+2) + '@' + RIGHT(c.name, LEN(o.name+c.name)%12 + 1) + LEFT(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =FALL NÄR c.name SOM '%y%' DÅ 0 ANNAT 1 SLUT FRÅN sys.all_objects AS o CROSS JOIN sys.all_columns SOM C ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GROUP BY fn, ln, em ORDER BY n) AS z ORDER BY rn;GO VÄLJ TOP (10) * FRÅN dbo.CustomerSeeds BESTÄLL EFTER rn;GO
Din körsträcka kan variera, men på mitt system tog denna population 86 sekunder. Tio representativa rader (klicka för att förstora):
 Exempelkunder
Exempelkunder
Därefter behövde jag tabeller för att inkludera frödata för varje användningsfall, med några extra index för att simulera någon form av verklighet, och jag kom på korta suffix för att göra alla typer av diagnostik enklare senare:
| datatyp | standard | komprimering | använd suffix |
|---|---|---|---|
| INT | IDENTITET | ingen | Jag |
| INT | IDENTITET | sida + rad | Ic |
| STORT | IDENTITET | ingen | B |
| STORT | IDENTITET | sida + rad | Bc |
| UNIQUEIDENTIFIER | NEWID() | ingen | G |
| UNIQUEIDENTIFIER | NEWID() | sida + rad | Gc |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | ingen | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | sida + rad | Sc |
Tabell 1:Användningsfall, datatyper och suffix
Åtta tabeller alla berättade, alla hämtade från samma mall (jag skulle bara ändra kommentarerna för att matcha användningsfallet och ersätta $use_case$ med lämpligt suffix från tabellen ovan):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( CustomerID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), FirstName NVARCHAR(64) NOT NULL, Efternamn NVARCHAR(64) NOT NULL, EMail NVARCHAR(320) NOT NULL BIT NOT NULL DEFAULT 1, Skapad DATETIME NOT NULL DEFAULT SYSDATETIME(), Uppdaterad DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMARY KEY (CustomerID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE_$_useEeE_Cusse C_CasON C_CaS Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ PÅ dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --GOCIONRE =DATA_COMPRESS); INDEX C_Name_Customers_$use_case$ PÅ dbo.Customers_$use_case$(LastName, FirstName) INKLUDERA (E-post) --WITH (DATA_COMPRESSION =PAGE);GONär tabellerna skapades fortsatte jag att fylla i tabellerna och mäta många av de mätvärden som jag anspelade på ovan. Jag startade om SQL Server-tjänsten mellan varje test för att vara säker på att de alla startade från samma baslinje, att DMV:er skulle återställas osv.
Obestridda inlägg
Mitt slutliga mål var att fylla tabellen med 1 000 000 rader, men först ville jag se vilken inverkan datatypen och komprimeringen har på råa inlägg utan några diskussioner. Jag genererade följande fråga – som skulle fylla tabellen med de första 200 000 kontakterna, 2 000 rader åt gången – och körde den mot varje tabell:
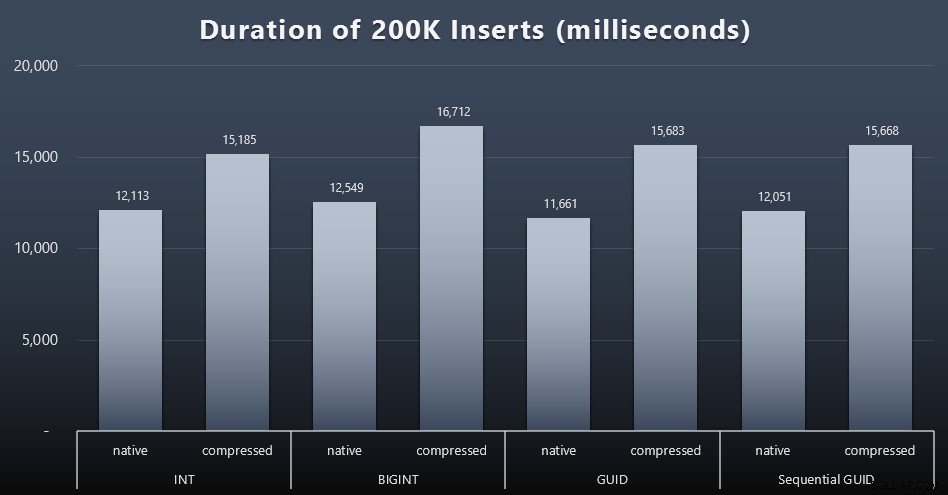
DECLARE @i INT =1;MED @i <=100BÖRJA INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) VÄLJ FirstName, LastName, Email, Active FROM dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RADER HÄMTA NÄSTA ENDAST 2000 RADER; SET @i +=1;ENDResultat (klicka för att förstora):
Varje fall tog cirka 12 sekunder (utan komprimering) och 16 sekunder (med komprimering), utan någon tydlig vinnare i något av lagringslägena. Effekten av komprimering (främst på CPU-overhead) är ganska konsekvent, men eftersom detta körs på en snabb SSD är I/O-effekten för de olika datatyperna försumbar. Faktum är att komprimeringen mot BIGINT verkade ha den största effekten (och detta är vettigt, eftersom varje enskilt värde mindre än 2 miljarder skulle komprimeras).
Mer omtvistad arbetsbelastning
Därefter ville jag se hur en blandad arbetsbelastning skulle konkurrera om resurser och generellt prestera mot varje datatyp. Så jag skapade dessa procedurer (ersätter
$use_case$och$data_type$lämpligt för varje test):-- slumpmässiga singleton-uppdateringar av data i mer än ett indexCREATE PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN SÄTT INGEN COUNT PÅ; UPPDATERA dbo.Customers_$use_case$ SET Efternamn =COALESCE(STUFF(Efternamn, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- läser ("paginering") - stöder flera sorterar-- använd dynamisk SQL för att spåra frågestatistik separat SKAPA PROCEDUR [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBÖRJAN STÄLLA IN NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT Kund-ID, Förnamn, Efternamn, E-post, Aktiv, Skapad, Uppdaterad FRÅN dbo.Customers_$use_case$ BESTÄLL EFTER ' + @sort + N' OFFSET ((@pn-1)*@ ps) RADER HÄMTA NÄSTA @ps ENDAST RADER;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGOSedan skapade jag jobb som skulle anropa dessa procedurer upprepade gånger, med små förseningar, och även – samtidigt – slutföra fyllandet av de återstående 800 000 kontakterna. Det här skriptet skapar alla 32 jobb och skriver även ut utdata som kan användas senare för att anropa alla jobb för ett specifikt test asynkront:
ANVÄND msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT) '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(name SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(name, cmd) VALUES(N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BÖRJA VÄLJ TOP (1) @CustomerID =Kund-ID FRÅN dbo.Customers_$use_case$ ORDER BY NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@Customer00DELAY:''0TFOR :01''; SET @i +=1; END'),( N'Populate customers', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Förnamn, Efternamn, E-post, Aktiv) VÄLJ Förnamn, Efternamn, E-post, Aktiv FRÅN dbo.CustomerSeeds ENLIGT BESTÄLLNING EFTER rn OFFSET 2000 * (@i-1) RADER HÄMTA NÄSTA 2000 RADER ENDAST; 01''; SET @i +=1; END'),( N'Paging arbetsbelastning 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sortera efter Kund-ID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Kund-ID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'),( N'Paging arbetsbelastning 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sortera efter Efternamn, Förnamn SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''LastName, FirstName'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'); DECLARE @n SYSNAME, @c NVARCHAR(MAX); DEKLARERA c MARKör LOCAL FAST_FORWARD FORSELECT namn =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FRÅN @typ AS t CROSS JOIN @jobs AS j; ÖPPEN c; HÄMTA c I @n, @c; MEDAN @@FETCH_STATUS <> -1BÖRJA OM FINNS (VÄLJ 1 FRÅN msdb.dbo.sysjobs WHERE name =@n) BÖRJA EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'IDs'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(lokal)'; SKRIV UT 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; HÄMTA c INTO @n, @c;ENDAtt mäta jobbtiderna i varje fall var trivialt – jag kunde kontrollera start-/slutdatum i
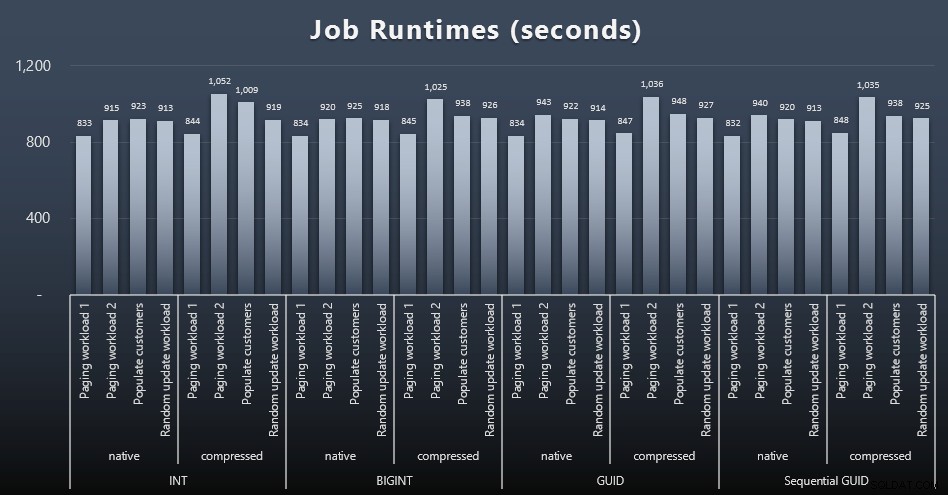
msdb.dbo.sysjobhistoryeller hämta dem från SQL Sentry Event Manager. Här är resultaten (klicka för att förstora):
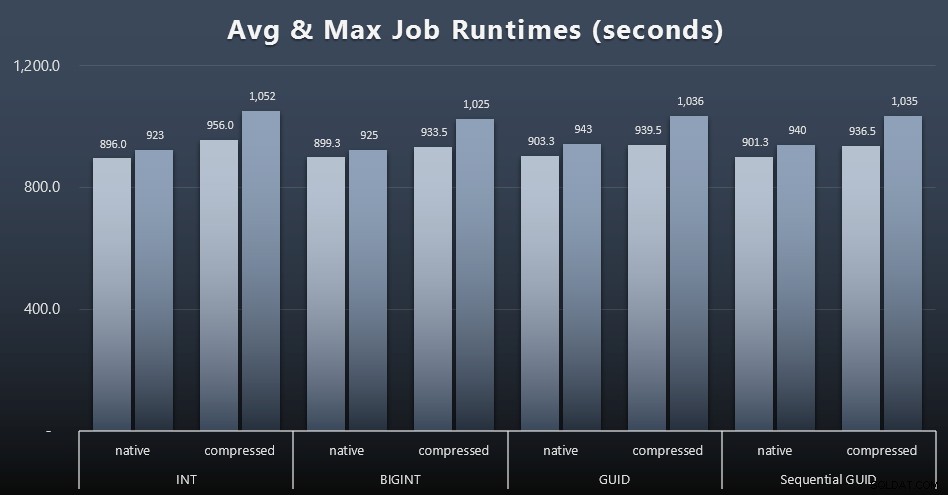
Och om du ville ha lite mindre att smälta, titta bara på den genomsnittliga och maximala körtiden för de fyra jobben (klicka för att förstora):
Men även i den här andra grafen finns det inte riktigt tillräckligt med varians för att göra ett övertygande argument för eller emot någon av tillvägagångssätten.
Frågekörningstider
Jag tog några mätvärden från
sys.dm_exec_query_statsochsys.dm_exec_trigger_statsför att avgöra hur lång tid individuella frågor tog i genomsnitt.
Befolkning
De första 200 000 kunderna laddades ganska snabbt – under 20 sekunder – på grund av inga konkurrerande arbetsbelastningar. När väl de fyra jobben kördes samtidigt fick det dock en betydande inverkan på skrivtiden på grund av samtidighet. De återstående 800 000 raderna krävde i genomsnitt minst en storleksordning längre tid att slutföra. Här är resultaten av ett genomsnitt av varje 2 000 kundbilaga (klicka för att förstora):
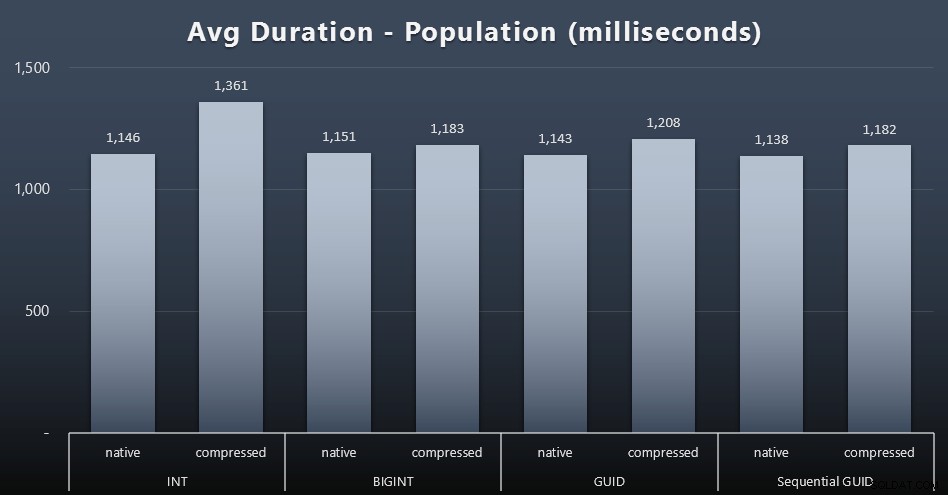
Vi ser här att komprimering av en INT var den enda verkliga avvikelsen – jag har några teorier om det, men inget avgörande än.
Paging-arbetsbelastningar
De genomsnittliga körtiderna för personsökningsfrågorna verkar också ha påverkats avsevärt av samtidighet jämfört med mina testkörningar isolerat. Här är resultaten (klicka för att förstora):
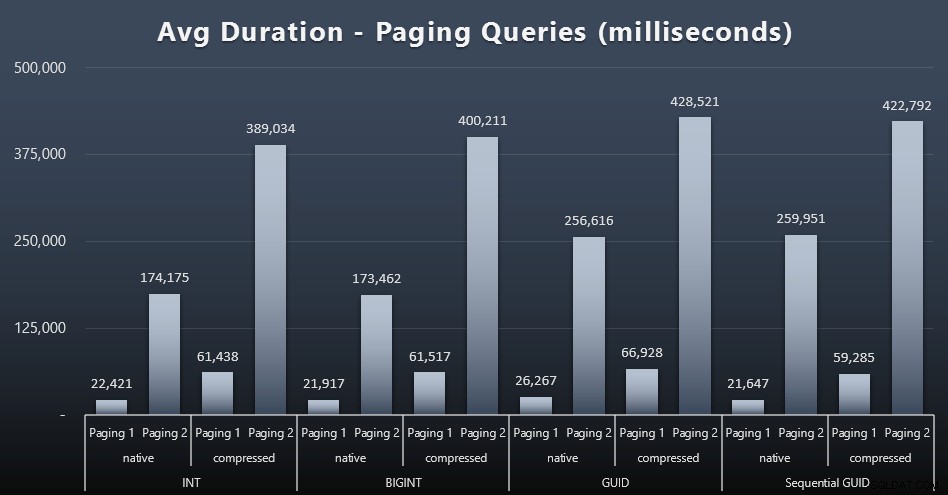
(Paging 1 =order by CustomerID, Paging 2 =order by LastName, FirstName.)
Vi ser att för både Paging 1 (beställning efter kund-ID) och Paging 2 (beställning efter namn) finns det en betydande inverkan på körtiden på grund av komprimering (upp till ~700%). Båda GUID:erna verkar vara de långsammaste hästarna i detta lopp, med NEWID() som presterar sämst.
Uppdatera arbetsbelastningar
Singleton-uppdateringarna var ganska snabba även under kraftig samtidighet, men det fanns fortfarande några märkbara skillnader på grund av komprimering, och till och med några överraskande skillnader mellan datatyper (klicka för att förstora):
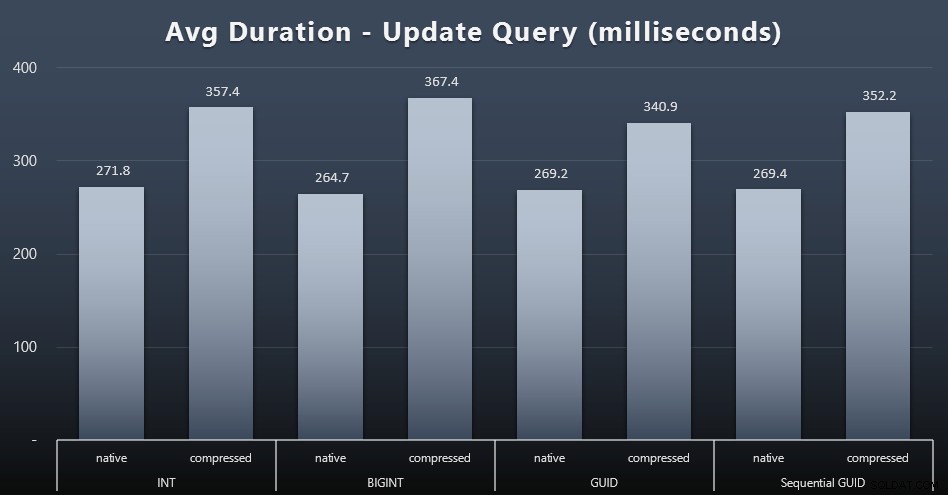
Framför allt var uppdateringarna av raderna som innehöll GUID-värden faktiskt snabbare än uppdateringarna som innehåller INT/BIGINT, när komprimering användes. Med inbyggd lagring var skillnaderna mindre anmärkningsvärda (men INT var fortfarande en förlorare där).
Triggerstatistik
Här är de genomsnittliga och maximala körtiderna för den enkla utlösaren i varje fall (klicka för att förstora):
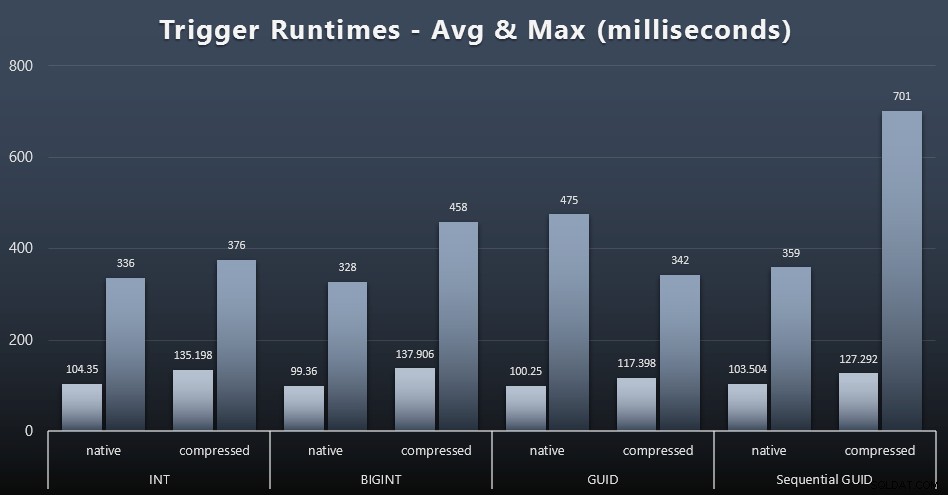
Komprimering verkar ha en mycket större inverkan här än valet av datatyp (även om detta sannolikt skulle vara mer uttalat om en del av min uppdateringsbelastning hade uppdaterat många rader istället för att enbart bestå av enradssökningar). Maxvärdet för sekventiell GUID är helt klart en extremvärde av något slag som jag inte undersökte (du kan se att det är obetydligt baserat på att genomsnittet fortfarande ligger i linje över hela linjen).
Vad väntade dessa frågor på?
Efter varje arbetsbelastning tog jag också en titt på de översta väntetiderna på systemet, och kastade bort uppenbara kö-/timerväntningar (som beskrivs av Paul Randal) och irrelevant aktivitet från övervakningsprogramvara (som TRACEWRITE ). Här var de tre bästa väntarna i varje fall (klicka för att förstora):
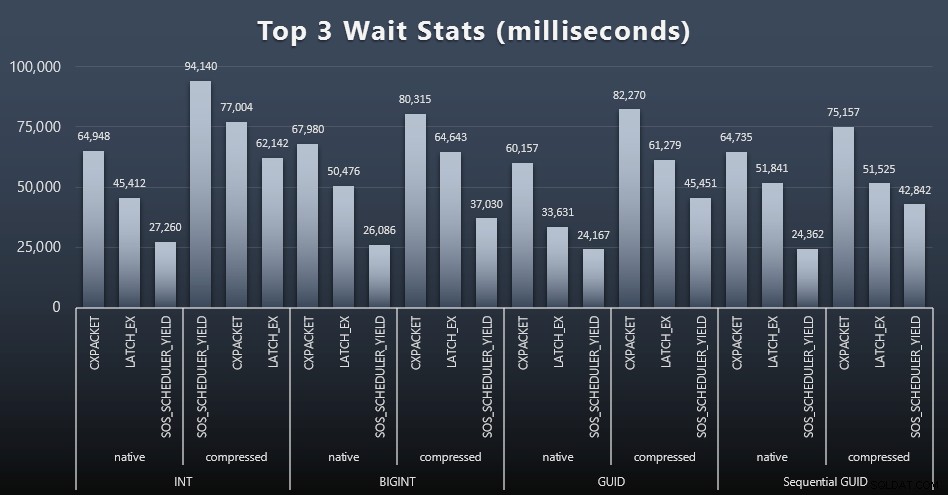
I de flesta fall var väntan CXPACKET, sedan LATCH_EX, sedan SOS_SCHEDULER_YIELD. I användningsfallet med heltal och komprimering tog dock SOS_SCHEDULER_YIELD över, vilket för mig innebär en viss ineffektivitet i algoritmen för att komprimera heltal (som kan vara helt orelaterade till algoritmen som används för att klämma in BIGINTs i INT). Jag undersökte inte detta ytterligare, och jag hittade inte heller någon motivering för att spåra väntan per enskild fråga.
Diskutrymme/fragmentering
Även om jag tenderar att hålla med om att det inte handlar om diskutrymme, är det fortfarande ett mått värt att presentera. Även i detta mycket förenklade fall där det bara finns en tabell och nyckeln inte finns i alla andra relaterade tabeller (vilket säkert skulle finnas i en riktig applikation), är skillnaden betydande. Låt oss först titta på den reserved kolumn från sp_spaceused (klicka för att förstora):
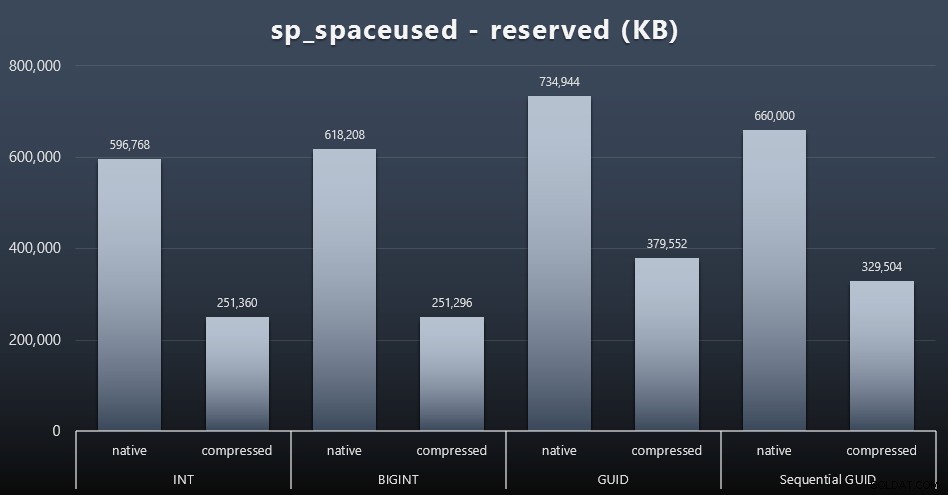
Här tog BIGINT bara lite mer plats än INT, och GUID hade (som förväntat) ett större hopp. Sekventiell GUID hade en mindre betydande ökning av utrymme som användes och komprimerade mycket bättre än traditionella GUID också. Återigen, inga överraskningar här – en GUID är större än ett nummer, punkt. Nu kan GUID-förespråkare hävda att priset du betalar i form av diskutrymme inte är så mycket (18 % över BIGINT utan komprimering, runt 50 % med komprimering). Men kom ihåg att detta är en enda tabell med 1 miljon rader. Föreställ dig hur det kommer att extrapoleras när du har 10 miljoner kunder och många av dem har 10, 30 eller 500 beställningar – dessa nycklar kan upprepas i ett dussin andra bord och ta upp samma extra utrymme på varje rad.
När jag tittade på fragmentering efter varje arbetsbelastning (kom ihåg att inget indexunderhåll utförs) med den här frågan:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Resultaten gav mycket mindre intressanta bilder; alla icke-klustrade index var fragmenterade över 99 %. De klustrade indexen var dock antingen mycket mycket fragmenterade eller inte fragmenterade alls (klicka för att förstora):
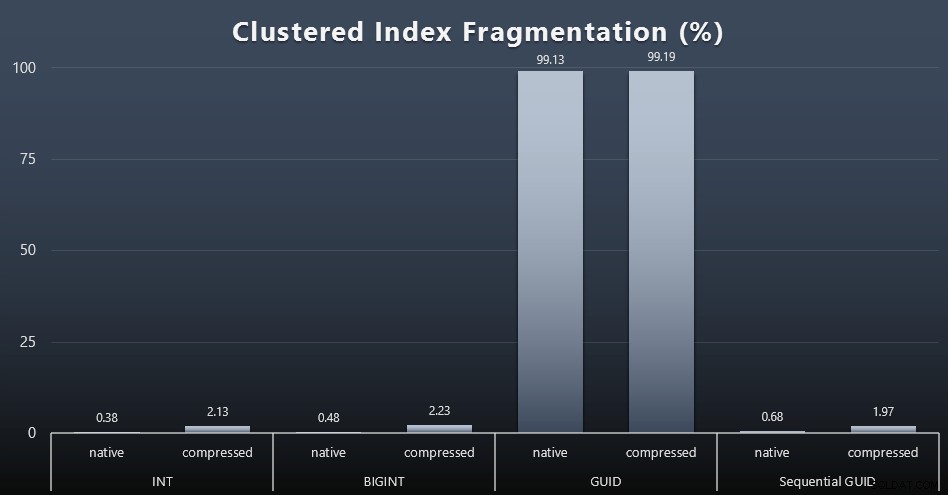
Fragmentering är ett annat mått som ofta betyder mycket mindre när vi pratar om SSD-enheter, men det är ändå viktigt att notera, eftersom inte alla system har råd att vara lyckligt omedvetna om vilken inverkan fragmentering kan ha på I/O-mönster. Jag tror att om man använder icke-sekventiella GUID, på ett mer I/O-bundet system, skulle effekten av enbart denna fragmentering förstärkas drastiskt på de flesta andra mätvärden i detta test.
Användning av buffertpool
Det är här det verkligen lönar sig att vara klok på hur mycket diskutrymme som används av dina bord – ju större dina bord är, desto mer utrymme tar de upp i buffertpoolen. Att flytta data in och ut ur buffertpoolen är dyrt, och återigen är detta ett mycket förenklat fall där testerna kördes isolerat och det inte fanns andra applikationer och databaser på instansen som konkurrerade om dyrbart minne.
Detta är ett enkelt mått på följande fråga i slutet av varje arbetsbelastning:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Resultat (klicka för att förstora):
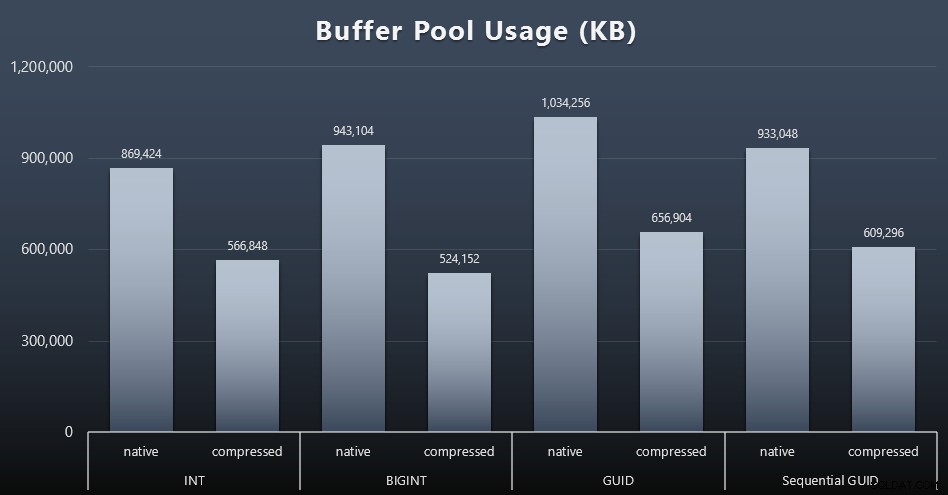
Även om det mesta av denna graf inte alls är förvånande – GUID tar mer utrymme än BIGINT, BIGINT mer än INT – tyckte jag det var intressant att en Sequential GUID tog mindre plats än en BIGINT, även utan komprimering. Jag har gjort en anteckning om att utföra en kriminalteknik på sidnivå för att avgöra vilken typ av effektivitet som sker här under täcket.
tempdb-användning
Jag är inte säker på vad jag förväntade mig här, men efter varje arbetsbelastning samlade jag in innehållet i de tre tempdb-relaterade DMV:erna för utrymmesanvändning, sys.dm_db_file|session|task_space_usage . Den enda som verkade visa någon volatilitet baserat på datatyp var sys.dm_db_file_space_usage s extent_allocation_page_count . Detta visar att – åtminstone i min konfiguration och denna specifika arbetsbelastning – GUID:er kommer att sätta tempdb genom ett lite mer grundligt träningspass (klicka för att förstora):
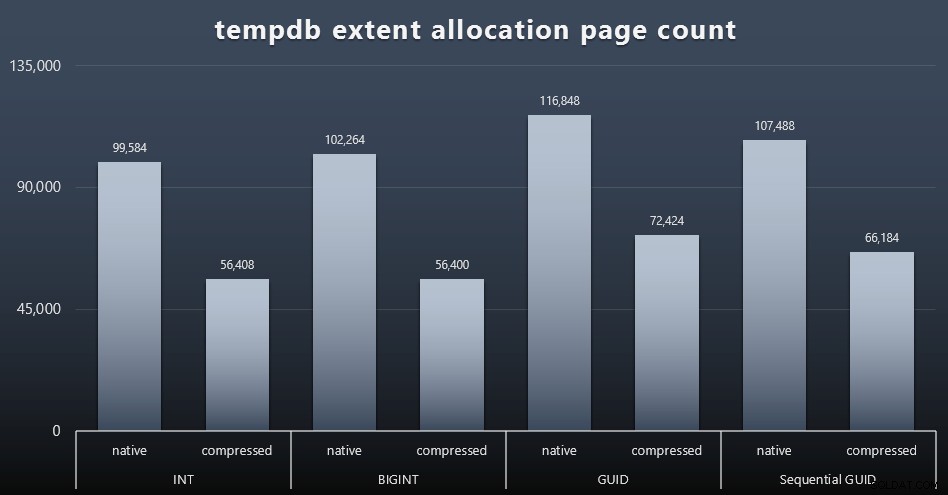
"Dåliga" siddelningar
En av de saker jag ville mäta var effekten på siddelningar – inte normala siddelningar (när du lägger till en ny sida) utan när du faktiskt måste flytta data mellan sidor för att göra plats för fler rader. Jonathan Kehayias berättar mer om detta i sitt blogginlägg, "Tracking Problematic Pages Splits in SQL Server 2012 Extended Events – No Really This Time!", som också utgör grunden för Extended Events-sessionen som jag använde för att fånga data:
SKAPA EVENT SESSION [BadPageSplits] PÅ SERVER ADD EVENT sqlserver.transaction_log (WHERE operation =11 AND database_id =10) LÄGG TARGET paket0.histogram (SET filtering_event_name ='sqlserver.transaction_log', source_type ='alloc0', source_type ='alloc0', source_type );GOALTER EVENT SESSION [BadPageSplits] PÅ SERVER STATE =START;GO
Och frågan jag använde för att plotta den:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address =WHERE s.Spage_name . ='histogram' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') as q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p . container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GROUP BY t.name; Och här är resultaten (klicka för att förstora):
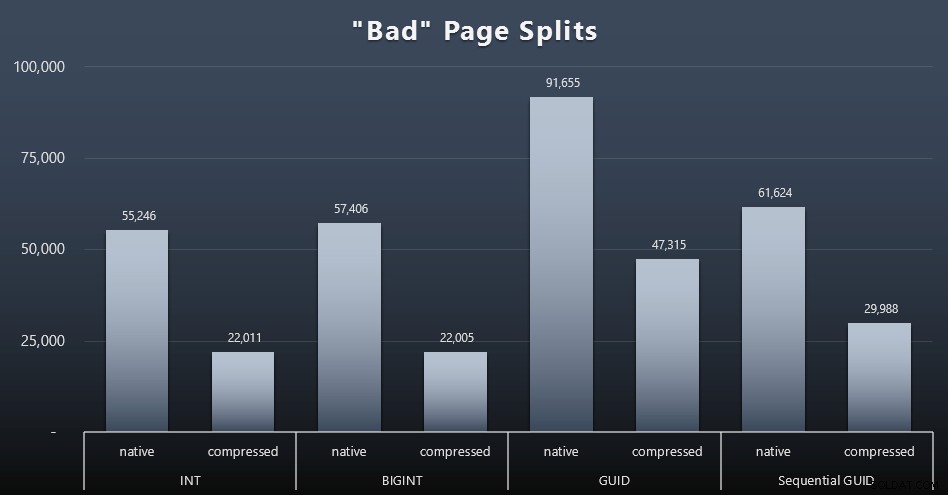
Även om jag redan har noterat att i mitt scenario (där jag kör på snabba SSD-enheter) påverkar den obestridliga skillnaden i I/O-aktivitet inte direkt den totala körtiden, är detta fortfarande ett mått du bör överväga – särskilt om du inte har SSD-enheter eller om din arbetsbelastning redan är I/O-bunden.
Slutsats
Även om de här testerna har öppnat mina ögon lite mer om hur långvariga uppfattningar jag har haft har förändrats av modernare hårdvara, är jag fortfarande ganska starkt emot att slösa utrymme på disk eller minne. Medan jag försökte visa en viss balans och låta GUID:er lysa, finns det väldigt lite här ur ett prestationsperspektiv för att stödja byte från INT/BIGINT till någon av formerna av UNIQUEIDENTIFIER – om du inte behöver det av andra mindre påtagliga skäl (som att skapa nyckeln i applikationen eller bibehålla unika nyckelvärden över olika system). En snabb sammanfattning som visar att NEWID() är det sämsta valet i många av mätvärdena där det fanns en betydande skillnad (och i de flesta av dessa fall var NEWSEQUENTIALID() en nära tvåa)):
| Mätvärde | Rensa förlorare? |
|---|---|
| Obestridda inlägg | – rita – |
| Samtidig arbetsbelastning | – rita – |
| Enskilda frågor – Population | INT (komprimerad) |
| Enskilda frågor – Personsökning | NEWID() / NEWSEQUENTIALID() |
| Enskilda frågor – Uppdatera | INT (native) / BIGINT (komprimerad) |
| Enskilda frågor – EFTER trigger | – rita – |
| Diskutrymme | NEWID() |
| Klustrerad indexfragmentering | NEWID() |
| Användning av buffertpool | NEWID() |
| tempdb-användning | NEWID() |
| "Dåliga" siddelningar | NEWID() |
Tabell 2:Största förlorarna
Testa gärna dessa saker själv; Jag kan sätta ihop hela min uppsättning skript om du vill köra dem i din egen miljö. Det kortfattade syftet med hela det här inlägget är ganska enkelt:det finns många viktiga mått att ta hänsyn till förutom den förutsägbara inverkan på diskutrymmet, så det bör inte användas ensamt som ett argument i någon riktning.
Nu vill jag inte att den här tankegången ska begränsas till nycklar i sig. Det bör verkligen tänkas på närhelst val av datatyp görs. Jag ser datetime väljs ofta, till exempel när endast ett date eller smalldatetime behövs. På transaktionstabeller kan detta också leda till mycket slöseri med diskutrymme, och detta rinner ner till några av dessa andra resurser också.
I ett framtida test skulle jag vilja jämföra resultat för en mycket större tabell (> 2 miljarder rader). Jag kan simulera detta med INT genom att ställa in identitetsfröet till -2 miljarder, vilket tillåter ~4 miljarder rader. Och jag skulle vilja att jämförelser av arbetsbelastning och diskutrymme/minnesavtryck omfattar mer än en enda tabell, eftersom en av fördelarna med en smal nyckel är när den nyckeln finns representerad i dussintals relaterade tabeller. Jag övervakade efter autogrow-händelser, men det fanns inga, eftersom databasen var tillräckligt stor i förväg för att rymma tillväxten och jag tänkte inte mäta faktisk logganvändning i den befintliga loggfilen, så jag skulle vilja testa igen med standardinställningarna för loggstorlek och autotillväxt, och denna gång mäter man DBCC SQLPERF(LOGSPACE); . Skulle också vara intressant att ta tid på ombyggnader och mäta logganvändning som ett resultat av dessa operationer också. Slutligen skulle jag vilja göra I/O till en mer relevant faktor genom att hitta en server med mekaniska hårddiskar – jag vet att det finns många där ute, men i vissa butiker är de ganska få.