I en perfekt värld spelar det ingen roll vilken speciell T-SQL-syntax vi valde för att uttrycka en fråga. Varje semantiskt identisk konstruktion skulle leda till exakt samma fysiska utförandeplan, med exakt samma prestandaegenskaper.
För att uppnå det skulle SQL Server-frågeoptimeraren behöva känna till alla möjliga logiska motsvarigheter (förutsatt att vi någonsin skulle kunna känna till dem alla) och ges tid och resurser för att utforska alla alternativ. Med tanke på det enorma antalet möjliga sätt vi kan uttrycka samma krav i T-SQL, och det enorma antalet möjliga transformationer, blir kombinationerna snabbt ohanterliga för alla utom de allra enklaste fallen.
En "perfekt värld" med fullständigt syntaxoberoende kanske inte verkar så perfekt för användare som måste vänta dagar, veckor eller till och med år på att en blygsamt komplex fråga ska kompileras. Så frågeoptimeraren kompromissar:den utforskar några vanliga motsvarigheter och försöker hårt undvika att lägga mer tid på kompilering och optimering än den sparar i körtid. Dess mål kan sammanfattas som att försöka hitta en rimlig genomförandeplan inom rimlig tid, samtidigt som det förbrukar rimliga resurser.
Ett resultat av allt detta är att exekveringsplaner ofta är känsliga för frågans skrivna form. Optimizern har viss logik för att snabbt omvandla några likvärdiga konstruktioner som används i stor utsträckning till en vanlig form, men dessa förmågor är varken väldokumenterade eller (i närheten av) heltäckande.
Vi kan förvisso maximera våra chanser att få en bra utförandeplan genom att skriva enklare frågor, tillhandahålla användbara index, upprätthålla bra statistik och begränsa oss till mer relationella koncept (t.ex. genom att undvika markörer, explicita loopar och funktioner som inte är inbyggda) inte en komplett lösning. Det är inte heller möjligt att säga att en T-SQL-konstruktion alltid kommer att vara skapa en bättre genomförandeplan än ett semantiskt identiskt alternativ.
Mitt vanliga råd är att börja med den enklaste relationsfrågan som uppfyller dina behov, med vilken T-SQL-syntax du än tycker är att föredra. Om frågan inte uppfyller kraven efter fysisk optimering (t.ex. indexering) kan det vara värt att försöka uttrycka frågan på ett lite annorlunda sätt, samtidigt som den ursprungliga semantiken bibehålls. Det här är den knepiga delen. Vilken del av frågan ska du försöka skriva om? Vilken omskrivning ska du prova? Det finns inget enkelt svar som passar alla på dessa frågor. En del av det beror på erfarenhet, men att veta lite om frågeoptimering och exekveringsmotorns interna delar kan också vara en användbar guide.
Exempel
Det här exemplet använder tabellen AdventureWorks TransactionHistory. Skriptet nedan gör en kopia av tabellen och skapar ett klustrat och icke-klustrat index. Vi kommer inte att modifiera uppgifterna alls; detta steg är bara för att göra indexeringen tydlig (och för att ge tabellen ett kortare namn):
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Uppgiften är att skapa en lista med produkt- och historik-ID för sex specifika produkter. Ett sätt att uttrycka frågan är:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360);
Den här frågan returnerar 764 rader med följande exekveringsplan (visas i SentryOne Plan Explorer):

Denna enkla fråga kvalificerar sig för sammanställning av TRIVIAL-plan. Utförandeplanen innehåller sex separata indexsökoperationer i en:
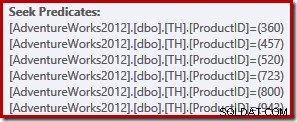
Örnögda läsare kommer att ha lagt märke till att de sex sökningarna är listade i stigande produkt-ID-ordning, inte i den (godtyckliga) ordning som anges i den ursprungliga frågans IN-lista. Faktum är att om du kör frågan själv är det ganska troligt att du kommer att se resultat som returneras i stigande produkt-ID-ordning. Frågan är inte garanterad för att returnera resultat i den ordningen naturligtvis, eftersom vi inte specificerade en ORDER BY-sats på toppnivå. Vi kan dock lägga till en sådan ORDER BY-klausul, utan att ändra den utförandeplan som skapats i detta fall:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID;
Jag kommer inte att upprepa utförandeplansgrafiken, eftersom den är exakt densamma:frågan kvalificerar sig fortfarande för en trivial plan, sökoperationerna är exakt desamma och de två planerna har exakt samma beräknade kostnad. Att lägga till ORDER BY-klausulen kostade oss ingenting, men gav oss en garanti för ordning på resultatet.
Vi har nu en garanti för att resultaten kommer att returneras i produkt-ID-ordning, men vår fråga anger för närvarande inte hur rader med samma produkt-ID kommer att beställas. När du tittar på resultaten kan du se att rader för samma produkt-ID ser ut att vara sorterade efter transaktions-ID, stigande.
Utan en explicit ORDER BY är detta bara ytterligare en observation (dvs. vi kan inte lita på denna beställning), men vi kan ändra frågan för att säkerställa att rader ordnas efter transaktions-ID inom varje produkt-ID:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
Återigen är exekveringsplanen för den här frågan exakt densamma som tidigare; samma triviala plan med samma beräknade kostnad tas fram. Skillnaden är att resultaten nu är garanterade att beställas först efter produkt-ID och sedan efter transaktions-ID.
Vissa människor kan vara frestade att dra slutsatsen att de två föregående frågorna också alltid skulle returnera rader i denna ordning, eftersom exekveringsplanerna är desamma. Detta är inte en säker implikation, eftersom inte alla exekveringsmotordetaljer exponeras i exekveringsplaner (även i XML-formuläret). Utan en explicit order by-klausul är SQL Server fri att returnera raderna i valfri ordning, även om planen ser likadan ut för oss (den kan till exempel utföra sökningarna i den ordning som anges i frågetexten). Poängen är att frågeoptimeraren känner till och kan tvinga fram vissa beteenden i motorn som inte är synliga för användarna.
Om du undrar hur vårt icke-unika icke-klustrade index på produkt-ID kan returnera rader i produkt och Transaktions-ID-order, svaret är att den icke-klustrade indexnyckeln innehåller Transaction ID (den unika klustrade indexnyckeln). Faktum är att det fysiska strukturen för vårt icke-klustrade index är exakt samma sak, på alla nivåer, som om vi hade skapat indexet med följande definition:
CREATE UNIQUE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID, TransactionID);
Vi kan till och med skriva frågan med en explicit DISTINCT eller GROUP BY och fortfarande få exakt samma exekveringsplan:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID, TransactionID;
För att vara tydlig kräver detta inte att det ursprungliga icke-klustrade indexet ändras på något sätt. Som ett sista exempel, notera att vi också kan begära resultat i fallande ordning:
SELECT DISTINCT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (520, 723, 457, 800, 943, 360) ORDER BY ProductID DESC, TransactionID DESC;
Exekveringsplanens egenskaper visar nu att indexet skannas bakåt:

Bortsett från det är planen densamma – den producerades i det triviala planoptimeringsstadiet och har fortfarande samma beräknade kostnad.
Skriv om frågan
Det är inget fel på den tidigare frågan eller exekveringsplanen, men vi kanske har valt att uttrycka frågan på ett annat sätt:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 OR ProductID = 723 OR ProductID = 457 OR ProductID = 800 OR ProductID = 943 OR ProductID = 360;
Det här formuläret specificerar helt klart exakt samma resultat som originalet, och faktiskt producerar den nya frågan samma exekveringsplan (trivial plan, flera sökningar i en, samma uppskattade kostnad). ELLER-formuläret kanske gör det lite tydligare att resultatet är en kombination av resultaten för de sex individuella produkt-ID:n, vilket kan leda till att vi provar en annan variant som gör denna idé ännu mer explicit:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 520 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 723 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 457 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 800 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 943 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 360;
Utförandeplanen för UNION ALL-frågan är helt annorlunda:
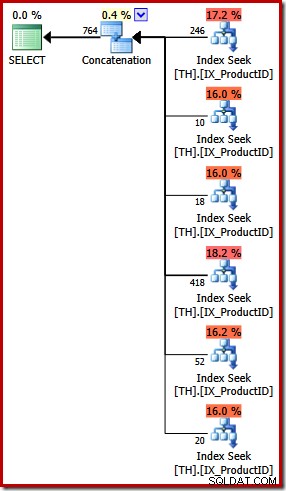
Bortsett från de uppenbara visuella skillnaderna krävde denna plan kostnadsbaserad (FULL) optimering (den kvalificerade sig inte för en trivial plan), och den beräknade kostnaden är (relativt sett) ganska mycket högre, runt 0,02> enheter mot cirka 0,005 enheter innan.
Detta går tillbaka till mina inledande kommentarer:frågeoptimeraren känner inte till alla logiska motsvarigheter och kan inte alltid känna igen alternativa frågor som anger samma resultat. Poängen jag påpekar i detta skede är att uttrycket av den här specifika frågan med UNION ALL snarare än IN resulterade i en mindre optimal exekveringsplan.
Andra exemplet
Det här exemplet väljer en annan uppsättning av sex produkt-ID:n och begär resultat i transaktions-ID-order:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
Vårt icke-klustrade index kan inte tillhandahålla rader i den begärda ordningen, så frågeoptimeraren har ett val att välja mellan att söka på det icke-klustrade indexet och sortera, eller att skanna det klustrade indexet (som enbart anges på transaktions-ID) och tillämpa produkt-ID-predikaten som en rest. Produkt-ID:n som anges råkar ha en lägre selektivitet än den tidigare uppsättningen, så optimeraren väljer en klustrad indexsökning i det här fallet:
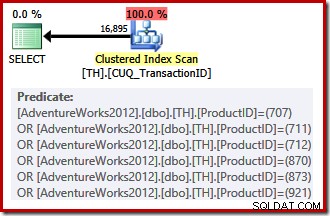
Eftersom det finns ett kostnadsbaserat val att göra, kvalificerade denna genomförandeplan inte för en trivial plan. Den beräknade kostnaden för den slutliga planen är cirka 0,714 enheter. Att skanna det klustrade indexet kräver 797 logiska läsningar vid körning.
Kanske förvånade över att frågan inte använde produktindexet, kan vi försöka tvinga fram en sökning av det icke-klustrade indexet med hjälp av ett indextips, eller genom att ange FORCESEEK:
SELECT ProductID, TransactionID FROM dbo.TH WITH (FORCESEEK) WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
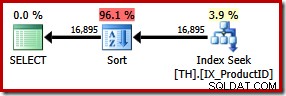
Detta resulterar i en explicit sortering efter transaktions-ID. Den nya sorteringen beräknas utgöra 96 % av den nya planens 1,15 enhetskostnad. Denna högre uppskattade kostnad förklarar varför optimeraren valde den till synes billigare klustrade indexskanningen när den lämnades till sina egna enheter. I/O-kostnaden för den nya frågan är dock lägre:när den körs förbrukar indexsökningen endast 49 logiska läsningar (ned från 797).
Vi kanske också har valt att uttrycka den här frågan med (den tidigare misslyckade) UNION ALL-idén:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Den producerar följande utförandeplan (klicka på bilden för att förstora i ett nytt fönster):

Den här planen kan tyckas mer komplex, men den har en beräknad kostnad på bara 0,099 enheter, vilket är mycket lägre än den klustrade indexsökningen (0,714 enheter) eller sök plussort (1,15 enheter). Dessutom förbrukar den nya planen bara 49 logiska läsningar vid körningstid – samma som sök + sorteringsplanen och mycket lägre än de 797 som behövs för den klustrade indexskanningen.
Den här gången gav att uttrycka frågan med UNION ALL en mycket bättre plan, både när det gäller beräknade kostnader och logiska läsningar. Källdatauppsättningen är lite för liten för att göra en verkligt meningsfull jämförelse mellan frågelängd eller CPU-användning, men den klustrade indexsökningen tar dubbelt så lång tid (26 ms) som de andra två på mitt system.
Den extra sorten i den antydda planen är förmodligen ofarlig i det här enkla exemplet eftersom det är osannolikt att det spills ut på disken, men många människor kommer ändå att föredra UNION ALL-planen eftersom den är icke-blockerande, undviker ett minnesbidrag och inte kräver en frågetips.
Slutsats
Vi har sett att frågesyntax kan påverka exekveringsplanen som väljs av optimeraren, även om frågorna logiskt anger exakt samma resultatuppsättning. Samma omskrivning (t.ex. UNION ALL) kommer ibland att resultera i en förbättring och ibland leda till att en sämre plan väljs ut.
Att skriva om frågor och prova alternativ syntax är en giltig inställningsteknik, men viss försiktighet krävs. En risk är att framtida ändringar av produkten kan leda till att det andra frågeformuläret plötsligt slutar producera den bättre planen, men man skulle kunna hävda att det alltid är en risk och mildras genom tester före uppgradering eller användning av planguider.
Det finns också en risk att bli medveten om den här tekniken:att använda "konstiga" eller "ovanliga" frågekonstruktioner för att få en plan som fungerar bättre är ofta ett tecken på att en linje har passerats. Exakt var skillnaden ligger mellan giltig alternativ syntax och 'ovanlig/konstig' är förmodligen ganska subjektivt; min egen personliga guide är att arbeta med likvärdiga relationsfrågeformulär och att hålla saker och ting så enkla som möjligt.