Nu har vår big data analytics community börjat använda Apache Spark i full gång för big data-bearbetning. Bearbetningen kan för ad-hoc-frågor, förbyggda frågor, grafbearbetning, maskininlärning och till och med för dataströmning.
Därför är förståelsen för Spark Job Submission mycket viktig för samhället. Förläng gärna till att dela med dig av lärdomarna om stegen som ingår i Apache Spark Job Submission.
I grund och botten har den två steg,

Skicka jobb
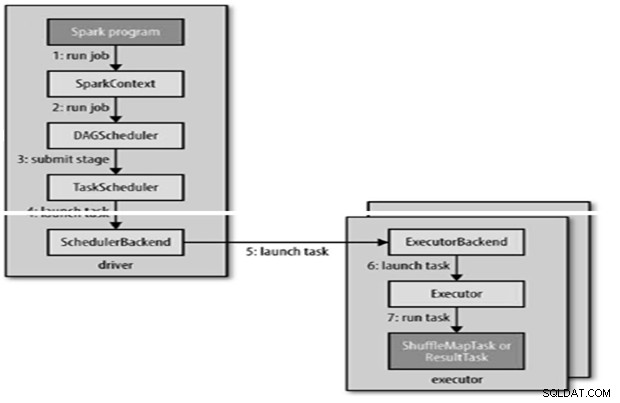
Spark-jobb skickas automatiskt när en åtgärd som count () utförs på en RDD.
Internt runJob() för att anropas på SparkContext och sedan anropa till schemaläggaren som körs som en del av härledaren.
Schemaläggaren består av två delar – DAG Scheduler och Task Scheduler.
DAG Construction
Det finns två typer av DAG-konstruktioner,

- Simple Spark-jobb är ett som inte behöver blandas och därför bara har ett enda steg som består av resultatuppgifter, som ett jobb som endast är kartan i MapReduce
- Komplext Spark-jobb involverar grupperingsoperationer och kräver en eller flera blandningssteg.
- Sparks DAG-schemaläggare gör jobbet till två steg.
- DAG-schemaläggaren är ansvarig för att dela upp ett steg i uppgifter för inlämning till uppgiftsschemaläggaren.
- Varje uppgift ges en placeringspreferens av DAG-schemaläggaren för att tillåta uppgiftsschemaläggaren att dra fördel av datalokalitet.
- Barnstadier skickas bara in när deras föräldrar har slutfört framgångsrikt.
Uppgiftsschemaläggning
- Uppgiftsschemaläggaren skickar en uppsättning uppgifter; den använder sin lista över exekutorer som körs för applikationen och konstruerar en mappning av uppgifter till executors som tar hänsyn till placeringspreferenser.
- Task scheduler tilldelar till exekutörer som har fria kärnor, varje uppgift tilldelas en kärna som standard. Det kan ändras med parametern spark.task.cpus.
- Spark använder Akka, som är en aktörsbaserad plattform för att bygga mycket skalbara händelsedrivna distribuerade applikationer.
- Spark använder inte Hadoop RPC för fjärrsamtal.
Uppgiftskörning
En exekutor kör en uppgift enligt följande,
- Det ser till att JAR- och filberoendet för uppgiften är uppdaterade.
- Avserialiserar uppgiftskoden.
- Uppgiftskoden körs.
- Uppgiften returnerar resultat till föraren, som sätts ihop till ett slutresultat för att återgå till användaren.
Referens
- The Hadoop Definitive Guide
- Analytics &Big Data Open Source Community
Denna artikel visades ursprungligen här. Återpubliceras med tillstånd. Skicka in dina upphovsrättsanspråk här.