Innehållsförteckning
Vad är Oracle index clustering factor (CF)?
Klustringsfaktorn är ett tal som representerar i vilken grad data är slumpmässigt fördelad i en tabell jämfört med den indexerade kolumnen. Enkelt uttryckt är det antalet "blockomkopplare" när du läser en tabell med hjälp av ett index.
Det är en viktig statistik som spelar en viktig roll vid optimeringsberäkning. Den används för att vikta beräkningen för indexintervallsskanningarna. När klustringsfaktorn är högre är kostnaden för indexintervallsökning högre
En bra klustringsfaktor är lika med (eller nära) värdena för antalet block i tabellen.
En dålig klustringsfaktor är lika med (eller nära) antalet rader i tabellen.
Hur beräknas CF?
Oracle beräknar klustringsfaktorn genom att göra en fullständig genomsökning av indexet och gå bladblocken från ände till ände. För varje post i varje blad kontrollerar Oracle det absoluta filnumret och block-id, som erhålls från det indexerade värdets ROWID. Den håller en löpande räkning av hur många "olika" block som innehåller datarader som pekas på av indexet. Blockadressen från den första posten jämförs med blockadressen från den andra posten. Om det är samma tabellblock ökar inte Oracle räknaren. Om tabellblocken är olika lägger Oracle till ett till antalet. Den här räkneprocessen fortsätter från post till post och jämför alltid den tidigare posten med den nuvarande.
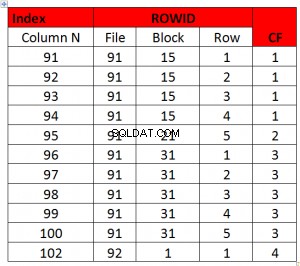
Ovanstående är ett bra CF-exempel eftersom CF är lika med antalet block
Exempel på dålig klustringsfaktor
Här är klustringsfaktorn lika med antalet rader
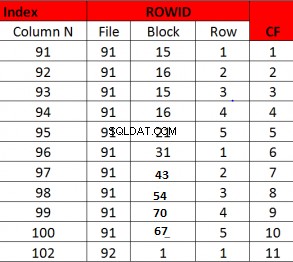
Denna metod för räkning har sitt eget oväntade resultat. Anta att data råkar fyllas i över en liten uppsättning block, men inte i ordning med hänvisning till indexnyckeln, då kan en uppsättning rader tyckas ligga över en stor uppsättning block när det kanske bara finns ett fåtal verkligt distinkta block . Så CF skulle vara högre men i själva verket rör det väldigt få block. Det här problemet kan mildras i 12c genom att använda tabellinställningar och ange det tabellerade cachade blocket.
hur man förbättrar klustringsfaktorn i Oracle
En ombyggnad av index skulle inte ha någon effekt på klustringsfaktorn. Tabellen måste sorteras och byggas om för att sänka klustringsfaktorn.
Fråga för att fastställa klustringsfaktorn
CF lagras i dataordboken och kan ses från dba_indexes (eller user_indexes).
Faktum är att all indexstatistik finns där
SELECT index_name, index_type, uniqueness, blevel, leaf_blocks, distinct_keys, avg_leaf_blocks_per_key,
avg_data_blocks_per_key, clustering_factor, num_rows, sample_size, last_analyzed, partitioned
FROM dba_indexes
WHERE table_name = 'ORDERS' ;
Hur påverkar Oracle-indexklustringsfaktorn optimeringsplanen?
Klustringsfaktorn är den primära statistik som optimeraren använder för att vikta indexåtkomstvägar. Det är en uppskattning av antalet LIO till tabellblock som krävs för att få alla rader som uppfyller frågan i ordning. Ju högre klustringsfaktor, desto fler LIO:er kommer optimeraren att uppskatta. Ju fler LIO:er som krävs, desto mindre attraktivt och därmed dyrare blir användningen av indexet.
Relaterad artikel
Oracle-partitionsindex :Förstå Oracle-partitionsindex, vad är globala icke-partitionerade index?, Vad är lokala prefixindex, lokalt index utan prefix
hitta index på en tabell i Oracle :kolla in den här artikeln för att hitta frågor om hur för att hitta index på en tabell i oracle, lista alla index i schemat, indexstatus, indexkolumn
typer av index i oracle :Denna sida består av oracle indexinformation, olika typer av index i oracle med ett exempel, hur skapa/släppa/ändra indexet i Oracle
Virtual Index i Oracle :Vad är Virtual Index i Oracle? Användningar, begränsningar, fördelar och hur man använder för att kontrollera förklara plan i Oracle-databas, dolda parameter _USE_NOSEGMENT_INDEXES