Ett stödjande index kan potentiellt hjälpa till att undvika behovet av explicit sortering i frågeplanen vid optimering av T-SQL-frågor som involverar fönsterfunktioner. Genom ett stödjande index, Jag menar en med fönsterpartitionering och ordningselement som indexnyckel, och resten av kolumnerna som visas i frågan som indexinkluderade kolumner. Jag refererar ofta till ett sådant indexeringsmönster som en POC index som en akronym för partitionering , beställning, och täckning . Naturligtvis, om ett partitionerings- eller beställningselement inte visas i fönsterfunktionen, utelämnar du den delen från indexdefinitionen.
Men hur är det med frågor som involverar flera fönsterfunktioner med olika beställningsbehov? På samma sätt, vad händer om andra element i frågan förutom fönsterfunktioner också kräver att indata som beställts i planen, såsom en presentation ORDER BY-sats? Dessa kan resultera i att olika delar av planen behöver bearbeta indata i olika ordningsföljder.
Under sådana omständigheter accepterar du vanligtvis att explicit sortering är oundviklig i planen. Du kanske upptäcker att det syntaktiska arrangemanget av uttryck i frågan kan påverka hur många explicita sorteringsoperatorer får du i planen. Genom att följa några grundläggande tips kan du ibland minska antalet explicita sorteringsoperatorer, vilket naturligtvis kan ha stor inverkan på frågans prestanda.
Miljö för demos
I mina exempel kommer jag att använda exempeldatabasen PerformanceV5. Du kan ladda ner källkoden för att skapa och fylla i denna databas här.
Jag körde alla exempel på SQL Server 2019 Developer, där batch-läge på rowstore är tillgängligt.
I den här artikeln vill jag fokusera på tips som har att göra med potentialen för fönsterfunktionens beräkning i planen att förlita sig på beställda indata utan att kräva en extra explicit sorteringsaktivitet i planen. Detta är relevant när optimeraren använder en seriell eller parallell radlägesbehandling av fönsterfunktioner och när en seriell batchmode Window Aggregate-operator används.
SQL Server stöder för närvarande inte en effektiv kombination av en parallell orderbevarande indata före en parallell batch-mode Window Aggregate-operator. Så för att använda en parallell batch-mode Window Aggregate-operator måste optimeraren injicera en intermediär parallell batch-mode-sorteringsoperator, även när ingången redan är förbeställd.
För enkelhetens skull kan du förhindra parallellism i alla exempel som visas i den här artikeln. För att uppnå detta utan att behöva lägga till en ledtråd till alla frågor och utan att ställa in ett serveromfattande konfigurationsalternativ, kan du ställa in konfigurationsalternativet för databasomfattning MAXDOP till 1 , som så:
USE PerformanceV5; ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 1;
Kom ihåg att ställa tillbaka den till 0 när du är klar med att testa exemplen i den här artikeln. Jag ska påminna dig i slutet.
Alternativt kan du förhindra parallellism på sessionsnivå med den odokumenterade DBCC OPTIMIZER_WHATIF kommando, som så:
DBCC OPTIMIZER_WHATIF(CPUs, 1);
För att återställa alternativet när du är klar, anropa det igen med värdet 0 som antal CPU:er.
När du är klar med att prova alla exempel i den här artikeln med parallellism inaktiverad rekommenderar jag att du aktiverar parallellism och försöker alla exempel igen för att se vad som förändras.
Tips 1 och 2
Innan jag börjar med tipsen, låt oss först titta på ett enkelt exempel med en fönsterfunktion utformad för att dra nytta av ett supp class="border indent shadow orting index.
Tänk på följande fråga, som jag kommer att referera till som fråga 1:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1 FROM dbo.Orders;
Oroa dig inte för det faktum att exemplet är konstruerat. Det finns inget bra affärsskäl att beräkna en löpande summa av order-ID:n – den här tabellen är anständigt stor med 1MM rader, och jag ville visa ett enkelt exempel med en vanlig fönsterfunktion som en som tillämpar en löpande totalberäkning.
Efter POC-indexeringsschemat skapar du följande index för att stödja frågan:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_od_oid ON dbo.Orders(custid, orderdate, orderid);
Planen för denna fråga visas i figur 1.
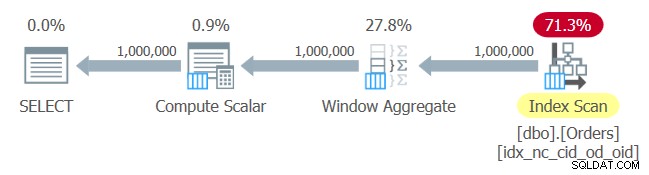 Figur 1:Plan för fråga 1
Figur 1:Plan för fråga 1
Inga överraskningar här. Planen tillämpar en indexorderskanning av indexet du just skapade, och tillhandahåller beställda data till Window Aggregate-operatören, utan behov av explicit sortering.
Tänk sedan på följande fråga, som involverar flera fönsterfunktioner med olika beställningsbehov, såväl som en presentation ORDER BY-klausul:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3 FROM dbo.Orders ORDER BY custid, orderid;
Jag hänvisar till den här frågan som fråga 2. Planen för den här frågan visas i figur 2.
 Figur 2:Plan för fråga 2
Figur 2:Plan för fråga 2
Observera att det finns fyra sorteringsoperatörer i planen.
Om du analyserar de olika fönsterfunktionerna och presentationsbeställningsbehoven, kommer du att upptäcka att det finns tre distinkta beställningsbehov:
- custid, orderdate, orderid
- orderid
- custid, orderid
Med tanke på att en av dem (den första i listan ovan) kan stödjas av indexet du skapade tidigare, skulle du förvänta dig att bara se två sorteringar i planen. Så varför har planen fyra sorter? Det ser ut som att SQL Server inte försöker vara för sofistikerad med att omorganisera bearbetningsordningen för funktionerna i planen för att minimera sortering. Den bearbetar funktionerna i planen i den ordning de visas i frågan. Det är åtminstone fallet för den första förekomsten av varje distinkt beställningsbehov, men jag kommer att utveckla detta inom kort.
Du kan ta bort behovet av några av sorterna i planen genom att tillämpa följande två enkla metoder:
Tips 1:Om du har ett index som stöder några av fönsterfunktionerna i frågan, ange dem först.
Tips 2:Om frågan involverar fönsterfunktioner med samma beställningsbehov som presentationsordningen i frågan, ange dessa funktioner sist.
Genom att följa dessa tips ändrar du ordningen på fönsterfunktionerna i frågan så här:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders ORDER BY custid, orderid;
Jag hänvisar till den här frågan som fråga 3. Planen för den här frågan visas i figur 3.
 Figur 3:Plan för fråga 3
Figur 3:Plan för fråga 3
Som du kan se har planen nu bara två sorters.
Tips 3
SQL Server försöker inte vara för sofistikerad när det gäller att omorganisera bearbetningsordningen för fönsterfunktioner i ett försök att minimera sortering i planen. Det är dock kapabelt till en viss enkel omarrangering. Den skannar fönsterfunktionerna baserat på utseendeordningen i frågan och varje gång den upptäcker ett nytt distinkt beställningsbehov, tittar den framåt efter ytterligare fönsterfunktioner med samma beställningsbehov och om den hittar dem grupperar den dem tillsammans med den första förekomsten. I vissa fall kan den till och med använda samma operatör för att beräkna flera fönsterfunktioner.
Betrakta följande fråga som ett exempel:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2 FROM dbo.Orders ORDER BY custid, orderid;
Jag hänvisar till den här frågan som fråga 4. Planen för den här frågan visas i figur 4.
 Figur 4:Plan för fråga 4
Figur 4:Plan för fråga 4
Fönsterfunktioner med samma beställningsbehov grupperas inte tillsammans i frågan. Det finns dock fortfarande bara två sorter i planen. Detta beror på att det som räknas i form av bearbetningsordning i planen är den första förekomsten av varje distinkt beställningsbehov. Detta leder mig till det tredje tipset.
Tips 3:Se till att följa tips 1 och 2 för den första förekomsten av varje distinkt beställningsbehov. Efterföljande förekomster av samma beställningsbehov, även om de inte är angränsande, identifieras och grupperas tillsammans med det första.
Tips 4 och 5
Anta att du vill returnera kolumner som är resultatet av fönsterberäkningar i en viss ordning från vänster till höger i utdata. Men vad händer om beställningen inte är densamma som ordningen som kommer att minimera sortering i planen?
Anta till exempel att du vill ha samma resultat som det som produceras av fråga 2 när det gäller kolumnordningen från vänster till höger i utdata (kolumnordning:andra kolumner, summa2, summa1, summa3), men du vill hellre ha samma plan som den du fick för fråga 3 (kolumnordning:andra kolumner, summa1, summa3, summa2), som fick två sorters istället för fyra.
Det är fullt genomförbart om du är bekant med det fjärde tipset.
Tips 4:De ovannämnda rekommendationerna gäller för utseendeordningen för fönsterfunktioner i koden, även om det är inom ett namngivet tabelluttryck som en CTE eller vy, och även om den yttre frågan returnerar kolumnerna i en annan ordning än i namngivna tabelluttryck. Därför, om du behöver returnera kolumner i en viss ordning i utdata, och det skiljer sig från den optimala ordningen när det gäller att minimera sortering i planen, följ tipsen när det gäller utseendeordning inom ett namngivet tabelluttryck, och returnera kolumnerna i den yttre frågan i önskad utdataordning.
Följande fråga, som jag kommer att referera till som fråga 5, illustrerar denna teknik:
WITH C AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Planen för denna fråga visas i figur 5.
 Figur 5:Plan för fråga 5
Figur 5:Plan för fråga 5
Du får fortfarande bara två sorteringar i planen trots att kolumnordningen i utdata är:andra kolumner, summa2, summa1, summa3, som i fråga 2.
En varning till detta trick med det namngivna tabelluttrycket är att om dina kolumner i tabelluttrycket inte refereras av den yttre frågan, exkluderas de från planen och räknas därför inte.
Tänk på följande fråga, som jag kommer att referera till som fråga 6:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3,
max2, max1, max3,
avg2, avg1, avg3
FROM C
ORDER BY custid, orderid; Här refereras alla tabelluttryckskolumner av den yttre frågan, så optimering sker baserat på den första distinkta förekomsten av varje beställningsbehov inom tabelluttrycket:
- max1:kund, orderdatum, orderid
- max3:orderid
- max2:custid, orderid
Detta resulterar i en plan med endast två sorteringar som visas i figur 6.
 Figur 6:Plan för fråga 6
Figur 6:Plan för fråga 6
Ändra nu bara den yttre frågan genom att ta bort referenserna till max2, max1, max3, avg2, avg1 och avg3, så här:
WITH C AS
(
SELECT orderid, orderdate, custid,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1,
MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3,
MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1,
AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3,
AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1,
SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3
FROM dbo.Orders
)
SELECT orderid, orderdate, custid,
sum2, sum1, sum3
FROM C
ORDER BY custid, orderid; Jag hänvisar till den här frågan som fråga 7. Beräkningarna av max1, max3, max2, avg1, avg3 och avg2 i tabelluttrycket är irrelevanta för den yttre frågan så de exkluderas. De återstående beräkningarna som involverar fönsterfunktioner i tabelluttrycket, som är relevanta för den yttre frågan, är summa2, summa1 och summa3. Tyvärr visas de inte i tabelluttrycket i optimal ordning vad gäller minimering av sorteringar. Som du kan se i planen för denna fråga, som visas i figur 7, finns det fyra sorter.
 Figur 7:Plan för fråga 7
Figur 7:Plan för fråga 7
Om du tror att det är osannolikt att du kommer att ha kolumner i den inre frågan som du inte kommer att referera till i den yttre frågan, tänk vyer. Varje gång du frågar en vy kanske du är intresserad av en annan delmängd av kolumnerna. Med detta i åtanke kan det femte tipset hjälpa till att minska sorteringen i planen.
Tips 5:I den inre frågan i ett namngivet tabelluttryck som en CTE eller vy, gruppera alla fönsterfunktioner med samma ordningsbehov tillsammans och följ tips 1 och 2 i ordningsföljden för grupperna av funktioner.
Följande kod implementerar en vy baserad på denna rekommendation:
CREATE OR ALTER VIEW dbo.MyView AS SELECT orderid, orderdate, custid, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS max1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS avg1, MAX(orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max3, SUM(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum3, AVG(1.0 * orderid) OVER(ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg3, MAX(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS max2, AVG(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS avg2, SUM(orderid) OVER(PARTITION BY custid ORDER BY ordered ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders; GO
Fråga nu vyn som endast begär resultatkolumnerna summa2, summa1 och summa3, i denna ordning:
SELECT orderid, orderdate, custid, sum2, sum1, sum3 FROM dbo.MyView ORDER BY custid, orderid;
Jag kommer att hänvisa till den här frågan som fråga 8. Du får planen som visas i figur 8 med bara två sorters.
 Figur 8:Plan för fråga 8
Figur 8:Plan för fråga 8
Tips 6
När du har en fråga med flera fönsterfunktioner med flera distinkta beställningsbehov är den vanliga visdomen att du bara kan stödja en av dem med förbeställda data via ett index. Detta är fallet även när alla fönsterfunktioner har respektive stödjande index.
Låt mig visa detta. Minns tidigare när du skapade indexet idx_nc_cid_od_oid, som kan stödja fönsterfunktioner som behöver data sorterad efter custid, orderdate, orderid, såsom följande uttryck:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING)
Anta att du förutom denna fönsterfunktion också behöver följande fönsterfunktion i samma fråga:
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING)
Denna fönsterfunktion skulle dra nytta av följande index:
CREATE UNIQUE NONCLUSTERED INDEX idx_nc_cid_oid ON dbo.Orders(custid, orderid);
Följande fråga, som jag kommer att referera till som fråga 9, anropar båda fönsterfunktionerna:
SELECT orderid, orderdate, custid, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1, SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2 FROM dbo.Orders;
Planen för denna fråga visas i figur 9.
 Figur 9:Plan för fråga 9
Figur 9:Plan för fråga 9
Jag får följande tidsstatistik för den här frågan på min dator, med resultat som kasseras i SSMS:
CPU time = 3234 ms, elapsed time = 3354 ms.
Som förklarats tidigare skannar SQL Server de fönsteruttryck i ordning de visas i frågan och siffror att den kan stödja den första med en ordnad genomsökning av indexet idx_nc_cid_od_oid. Men sedan lägger den till en sorteringsoperatör till planen för att beställa data som den andra fönsterfunktionen behöver. Detta betyder att planen har N log N-skalning. Den överväger inte att använda indexet idx_nc_cid_oid för att stödja den andra fönsterfunktionen. Du tror förmodligen att det inte kan, men försök att tänka lite utanför ramarna. Skulle du inte kunna beräkna var och en av fönsterfunktionerna baserat på dess respektive indexordning och sedan sammanfoga resultaten? Teoretiskt sett kan du, och beroende på storleken på data, tillgängligheten för indexering och andra tillgängliga resurser, kan joinversionen ibland bli bättre. SQL Server överväger inte detta tillvägagångssätt, men du kan verkligen implementera det genom att skriva anslutningen själv, som så:
WITH C1 AS
(
SELECT orderid, orderdate, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderdate, orderid ROWS UNBOUNDED PRECEDING) AS sum1
FROM dbo.Orders
),
C2 AS
(
SELECT orderid, custid,
SUM(orderid) OVER(PARTITION BY custid ORDER BY orderid ROWS UNBOUNDED PRECEDING) AS sum2
FROM dbo.Orders
)
SELECT C1.orderid, C1.orderdate, C1.custid, C1.sum1, C2.sum2
FROM C1
INNER JOIN C2
ON C1.orderid = C2.orderid; Jag hänvisar till den här frågan som fråga 10. Planen för den här frågan visas i figur 10.
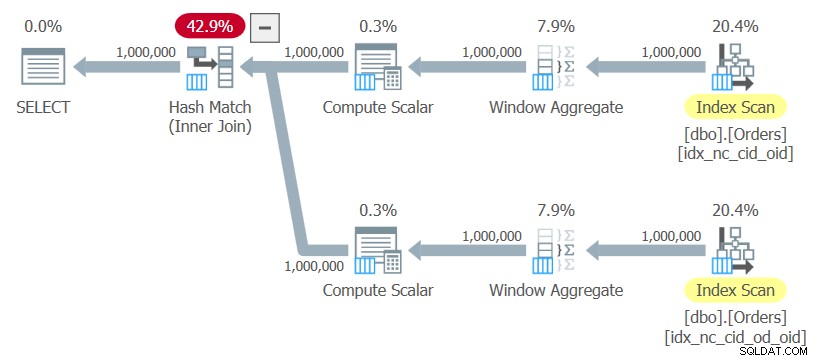 Figur 10:Plan för fråga 10
Figur 10:Plan för fråga 10
Planen använder ordnade skanningar av de två indexen utan någon som helst explicit sortering, beräknar fönsterfunktionerna och använder en hash-join för att sammanfoga resultaten. Denna plan skalas linjärt jämfört med den föregående som har N log N-skalning.
Jag får följande tidsstatistik för den här frågan på min maskin (igen med resultat som kasseras i SSMS):
CPU time = 1000 ms, elapsed time = 1100 ms.
För att sammanfatta, här är vårt sjätte tips.
Tips 6:När du har flera fönsterfunktioner med flera distinkta beställningsbehov och du kan stödja dem alla med index, prova en joinversion och jämför dess prestanda med frågan utan join.
Rengöring
Om du inaktiverade parallellism genom att ställa in konfigurationsalternativet MAXDOP med databasomfattning till 1, återaktivera parallellism genom att ställa in det till 0:
ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0;
Om du använde det odokumenterade sessionsalternativet DBCC OPTIMIZER_WHATIF med CPU-alternativet inställt på 1, återaktivera parallellism genom att ställa in det till 0:
DBCC OPTIMIZER_WHATIF(CPUs, 0);
Du kan försöka igen med alla exempel med parallellism aktiverad om du vill.
Använd följande kod för att rensa upp de nya indexen du skapade:
DROP INDEX IF EXISTS idx_nc_cid_od_oid ON dbo.Orders; DROP INDEX IF EXISTS idx_nc_cid_oid ON dbo.Orders;
Och följande kod för att ta bort vyn:
DROP VIEW IF EXISTS dbo.MyView;
Följ tipsen för att minimera antalet sorteringar
Fönsterfunktioner behöver bearbeta beställda indata. Indexering kan hjälpa till att eliminera sortering i planen, men normalt bara för ett distinkt beställningsbehov. Frågor med flera beställningsbehov involverar vanligtvis vissa sorters planer. Men genom att följa vissa tips kan du minimera antalet sorter som behövs. Här är en sammanfattning av tipsen jag nämnde i den här artikeln:
- Tips 1: Om du har ett index som stöder några av fönsterfunktionerna i frågan, ange dem först.
- Tips 2: Om frågan involverar fönsterfunktioner med samma beställningsbehov som presentationsordningen i frågan, ange dessa funktioner sist.
- Tips 3: Se till att följa tips 1 och 2 för den första förekomsten av varje distinkt beställningsbehov. Efterföljande förekomster av samma beställningsbehov, även om de inte är intilliggande, identifieras och grupperas tillsammans med det första.
- Tips 4: Ovannämnda rekommendationer gäller för utseendeordningen för fönsterfunktioner i koden, även om det är inom ett namngivet tabelluttryck som en CTE eller vy, och även om den yttre frågan returnerar kolumnerna i en annan ordning än i det namngivna tabelluttrycket. Därför, om du behöver returnera kolumner i en viss ordning i utdata, och det skiljer sig från den optimala ordningen när det gäller att minimera sortering i planen, följ tipsen när det gäller utseendeordning inom ett namngivet tabelluttryck, och returnera kolumnerna i den yttre frågan i önskad utmatningsordning.
- Tips 5: I den inre frågan i ett namngivet tabelluttryck som en CTE eller vy, gruppera alla fönsterfunktioner med samma ordningsbehov tillsammans och följ tips 1 och 2 i ordningsföljden för grupperna av funktioner.
- Tips 6: När du har flera fönsterfunktioner med flera distinkta beställningsbehov och du kan stödja dem alla med index, prova en joinversion och jämför dess prestanda med frågan utan join.