När folk hör vad jag gör tenderar folk att ställa samma fråga till mig:Kan du utveckla ett system som förutsäger fotbollsmatchresultat? Eller OS-medaljresultat? Personligen tror jag inte mycket på förutsägelser. Ändå, om vi hade en stor mängd historisk data och relevanta indikatorer, skulle vi säkert kunna designa ett system som hjälper oss att komma med mer exakta antaganden. I den här artikeln kommer vi att överväga en modell som kan lagra resultaten från matcher och turneringar.
Denna modell är främst inriktad på europeisk fotboll (fotboll) matcher, statistik och resultat, men den kan lätt anpassas för att passa många andra sporter. Min främsta motivering för den här artikeln var årets två stora fotbollsevenemang:UEFA Euro 2016 Championship som just hände och 2016 sommar-OS som äger rum just nu.
Vad vet vi innan turneringen börjar?
Innan turneringen startar vet vi nästan allt om den — förutom det viktigaste:vem som vinner. Låt oss kort ange exakt vad vi redan vet:
- De datum då turneringen startar och slutar
- Platserna där matcherna kommer att äga rum
- De exakta tiderna som matcherna börjar
- Vilka lag har kvalificerat sig till turneringen
- Spelarna i vart och ett av dessa lag
- Varje spelares tidigare prestationer och deras nuvarande form
Vilka matchningsdetaljer vill vi lagra?
Turneringar består av flera matcher. Innan vi lagrar matchdetaljer måste vi:
- Relatera varje match med turneringen
- Spela in turneringsstadiet när matchen spelades (t.ex. gruppspel, semifinaler)
Vi behöver också lagra detaljer för enstaka matchningar, inklusive:
- Lagen som är inblandade i matchen
- Startuppställningar och byten
- Matchhändelser (i fotboll är dessa:mål, straff, foul, gult kort, etc.)
- Slutresultat
- Spelarnas handlingar under matchen
Vi kommer att använda denna data för att fånga alla viktiga matchhändelser. Att jämföra en spelares prestation före och under matchen kan leda till vissa slutsatser. Kanske skulle vi inte kunna förutsäga de slutliga resultaten av deras prestation (dvs. en vinst eller en förlust), men statistik kan verkligen hjälpa oss att göra antaganden med en viss grad av tillförlitlighet.
Vi presenterar modellen
Modellen är indelad i fyra huvudområden:
Tournament detailsMatch detailsEventsIndicators and Performance
Tabellerna utanför dessa områden är ordböcker (sport , phase , position ), kataloger (sport_event , team , player ) och en enda många-till-många-relation (plays ).
Vi kommer att beskriva de okategoriserade tabellerna först och sedan titta närmare på varje område.
De okategoriserade tabellerna
Dessa tabeller är viktiga eftersom tabeller från alla fyra områden använder dem som ordböcker eller kataloger.

sport Tabellen listar alla sporter vi kommer att lagra i vår databas. Vi kommer förmodligen bara att ha en sport här, herrfotboll, men den här tabellen ger oss flexibiliteten att lägga till liknande sporter (t.ex. damfotboll) om det behövs.

I sport_event tabell, kommer vi att lagra evenemang som är kopplade till vår(a) sport(er). Ett exempel skulle vara "OS 2016".
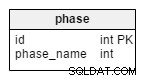
phase table är en ordbok som innehåller alla möjliga turneringsstadier. Den innehåller värden som "gruppstadiet" , "omgång 16" , "kvartsfinaler" , “semifinaler” , "final" .
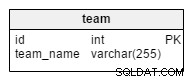
team tabellen är, som du kan gissa, en enkel lista över alla lag. Möjliga värden är "Kroatien" , "Polen" , “USA” etc. Om vi använder databasen för att lagra information om klubb- eller ligatävlingar, skulle vi också ha värden som “Barcelona” , “Real Madrid” , “Bayern” , “Manchester United” etc.
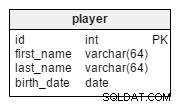
I player tabellen lagrar vi register för alla spelare som tillhör de relevanta lagen.
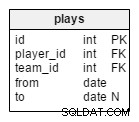
plays tabellen är vår enda många-till-många-relation, och det relaterar spelare och lag. En spelare kan tillhöra mer än ett lag samtidigt (t.ex. landslaget och en klubb), men under en turnering kommer de uppenbarligen bara att spela för ett lag.
Slutligen har vi position tabell. Denna enkla ordbok kommer att lagra en lista över alla nödvändiga positioner. Inom fotboll inkluderar dessa målvakt, mittback, anfallare, etc.
Turneringsdetaljer
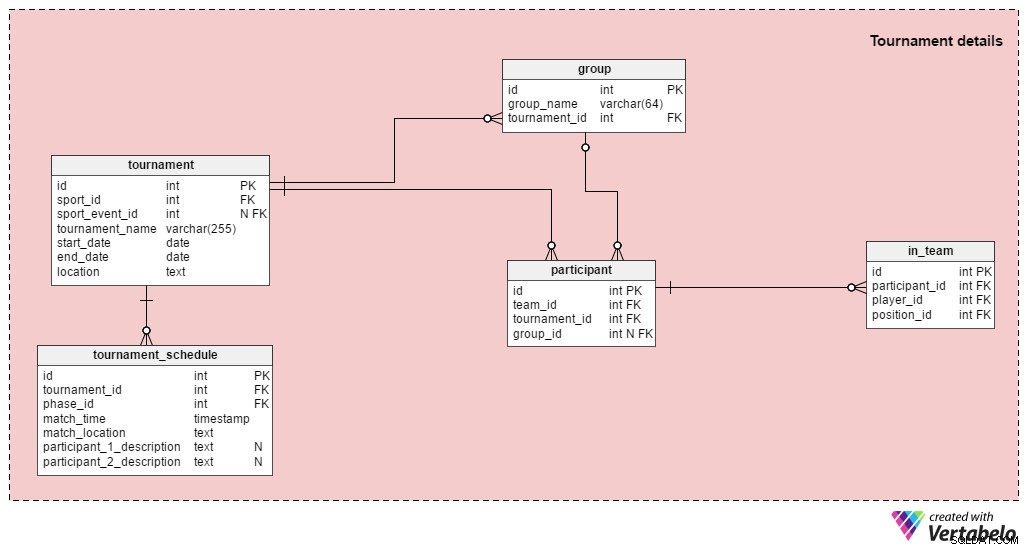
Obs! Om du bara vill lagra resultaten från enstaka matcher behöver du inte använda det här avsnittet.
En turnering består av mer än en match; både UEFA Euro 2016 och fotbollsevenemangen i olympiska sommarspelen 2016 är turneringar. Som vi sa tidigare kan vi lagra en enda match i vår databas, men vi kan även relatera matcher till deras relevanta turneringar. Tabellerna i turneringssektionen är:
tournament– Det här innehåller alla grundläggande turneringsdata:sporten, startdatum, slutdatum, etc. Vi måste också lagra turneringens namn och en beskrivning av var den äger rum.sport_event_idattribut är valfritt eftersom en turnering inte behöver vara kopplad till ett större evenemang (som OS).group– Det här listar alla grupper i den turneringen. UEFA Euro 2016 hade sex grupper, A till F.participant– Det här är lagen som spelar i turneringen; varje deltagare kan tilldelas en grupp. De flesta turneringar börjar med ett gruppspel och fortsätter sedan till ett utslagssteg (t.ex. UEFA Euro, UEFA World Cup, olympisk fotboll). Vissa turneringar kommer bara att ha ett gruppspel (t.ex. nationella ligor), medan andra bara kommer att ha ett utslagssteg (t.ex. nationella cuper).in_team– Den här tabellen ger en många-till-många-relation som lagrar information om spelarna som är registrerade för den turneringen och deras förväntade positioner.tournament_schedule– Enligt min mening är det här den mest intressanta tabellen i det här avsnittet. Listan över alla spel som spelas under denna turnering lagras här.tournament_idattributet anger vilken turnering varje match tillhör ochphase_idattribut definierar den fas under vilken matchen kommer att äga rum. Vi lagrar även matchplatsen och tiden när den börjar. Båda deltagarna kommer att beskrivas med textfält. När gruppspelet är slut vet vi alla matcher för elimineringsrundan. Till exempel, i början av UEFA Euro 2016 visste vi att vinnaren av grupp E (1E) kommer att spela mot grupp D tvåan (2D). Efter att alla tre omgångarna i gruppfasen spelats var detta par Italien mot Spanien.
Matchdetaljer
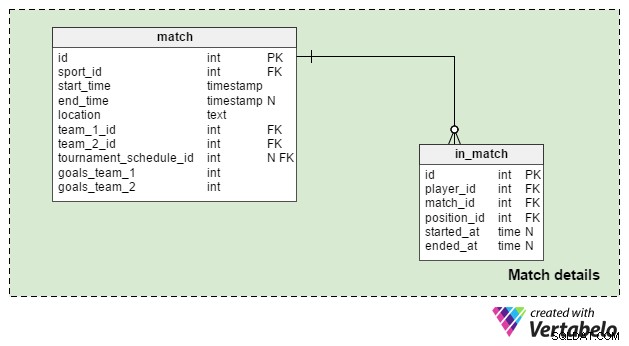
Match details område används för att lagra data för enstaka matchningar. Vi använder två tabeller:
match– Det här innehåller alla detaljer om en enda match; den här matchen kan relateras till en turnering, men det kan också vara ett enskilt spel. Alltsåtournament_schedule_idattributet är valfritt och vi lagrarsport_id,start_timeochlocationattribut igen här. Om matchen är en del av en turnering,tournament_schedule_idkommer att tilldelas ett värde.team_1_idochteam_2_idattribut är referenser till de lag som är inblandade i matchen.goals_team_1ochgoals_team_2attribut innehåller resultatet av matchen. De är obligatoriska och bör ha "0" som standardvärde för båda.in_match– Den här tabellen är en lista över alla spelare som är registrerade för den matchen; spelare som inte deltar kommer att ha en NULL istarted_atattribut, medan spelare som kom in som byten kommer att hastarted_at> 0 . Om en spelare ersattes har de enended_atattribut som matcharstarted_atattribut för spelaren som ersatte dem. Om spelaren stannade kvar under hela matchen, derasended_atattribut kommer att ha samma värde somend_timeattribut.
Matchhändelser
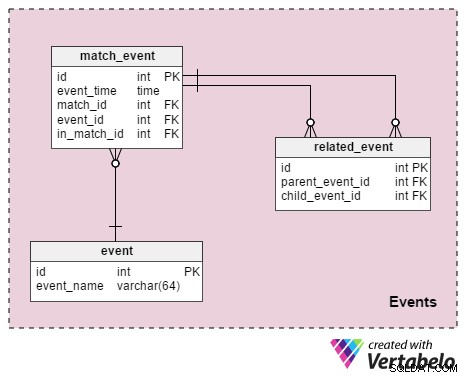
Det här avsnittet är avsett att lagra alla detaljer eller händelser som hände under spelet. Och tabellerna är:
event– Det här är en ordbok som listar alla händelser vi vill lagra. Inom fotboll är dessa värderingar som "brottsligt begått" , "fel lidit" , "gult kort" , “rött kort” , "frispark" , "straff" , "mål" , “offside” , “substitution” , ”spelare utvisad från match” .match_event– Det här relaterar händelser med matchen. Vi lagrarevent_timesamt spelarinformation relaterad till den händelsen (in_match_id).related_event– Det är detta som sammanför händelseinformation. För att förklara, låt oss titta på ett exempel när spelare A gör fel på spelare B. Vi infogar en post imatch_eventtabell som indikerar att spelare A begått ett regelbrott och en annan som indikerar att spelare B begått ett regelbrott. Vi lägger också till en post irelated_eventtabell, där den "begärda foulen" kommer att vara föräldern och den "drabbade foulen" kommer att vara barnet. Vi kommer också att registrera resultatet av regelbrottet:ett gult kort, en frispark eller en straffspark, och kanske ett mål.
Indikatorer och prestanda
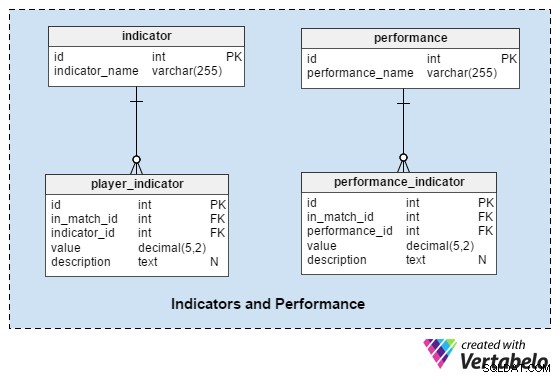
Det här avsnittet ska hjälpa oss att analysera spelare och lag före och efter matchen.
indicator tabellen är en ordbok med en fördefinierad uppsättning indikatorer för varje spelare före varje match. Dessa indikatorer ska beskriva spelarens nuvarande form. Den här listan kan innehålla värden som:"antal mål under de senaste 10 matcherna" , "genomsnittligt tillryggalagt avstånd under de senaste 10 matcherna" , "antal räddningar för GK under de senaste 10 matcherna" .
performance ordboken är mycket lik indicator , men vi kommer att använda den för att endast lagra värden som är relaterade till den enskilda matchningen:"avstånd tillryggalagt" , "exakta pass" , etc.
player_indicator och performance_indicator tabeller delar en nästan identisk struktur:
in_match_id– syftar på att spelaren deltar i en viss matchindicator_id/performance_id– refererar tillindicatoreller ”performance ordböckervalue– lagrar värdet för den indikatorn (t.ex. en spelare tillryggalagt 10,72 km)description– innehåller en ytterligare beskrivning om det behövs
Vad hände under matchen?
Med all denna data inlagd kunde vi enkelt få matchdetaljer, händelser och statistik för varje match i vår databas.
Denna enkla fråga skulle returnera grundläggande detaljer för en kommande match:
SELECT team_1.`team_name`, team_2.`team_name`, `match`.`start_time`, `match`.`location` FROM `match`, `team` AS team_1, `team` AS team_2 WHERE `match`.`team_1_id` = team_1.`id` AND `match`.`team_2_id` = team_2.`id`
För att få en lista över alla in-play-händelser under en viss match använder vi frågan nedan:
SELECT `event`.`event_name`, `match_event`.`event_time`, `player`.`first_name`, `player`.`last_name` FROM `match`, `match_event`, `event`, `in_match`, `player` WHERE `match_event`.`match_id` = `match`.`id` AND `event`.`id` = `match_event`.`event_id` AND `in_match`.`id` = `match_event`.`in_match_id` AND `player`.`id` = `in_match`.`player_id` AND `match`.`id` = @match ORDER BY `match_event`.`event_time` ASC
Det finns många ytterligare frågor som jag kan komma på; det är lätt att göra en analys när du har data. Om du har mätt och lagrat ett stort antal indikatorer och spelarprestationsdata, kanske du kan relatera dessa parametrar till ett slutresultat. Jag personligen tror inte på sådana förutsägelser; det finns turfaktorn under matcher, plus många andra faktorer som du inte kan veta förrän spelet startar. Ändå, om du har en stor datamängd och många parametrar, ökar din chans att göra mer exakta förutsägelser.
Modellen som presenteras i den här artikeln låter oss lagra matcher, matchdetaljer och en historik över varje spelares prestation. Vi kan även ställa in formindikatorer för varje spelare inför matchen. Att lagra tillräckligt med detaljer borde ge oss fler parametrar att basera våra antaganden på. Jag säger inte att vi skulle kunna förutsäga resultatet av spelet, men vi skulle kunna ha kul med det.
Vi kan också enkelt anpassa den här modellen för att lagra data för andra sporter. Dessa förändringar bör inte vara för komplicerade. Lägga till ett sport_id attribut till ordböckerna borde göra susen. Ändå tror jag att det skulle vara klokt att ha en ny instans för varje sport.