När jag var i Chicago för några veckor sedan för ett av våra Immersion Events fick en deltagare en statistikfråga. Jag kommer inte gå in på alla detaljer kring problemet, men deltagaren nämnde att statistiken uppdaterades med sp_updatestats . Det här är en metod för att uppdatera statistik som jag aldrig har rekommenderat; Jag har alltid rekommenderat en kombination av indexombyggnader och UPDATE STATISTICS för att hålla statistiken uppdaterad. Om du inte är bekant med sp_updatestats , det är ett kommando som körs för hela databasen för att uppdatera statistik. Men som Kimberly påpekade för deltagaren, sp_updatestats kommer att uppdatera en statistik så länge en rad har ändrats. Oj. Jag öppnade direkt Books Online och för sp_updatestats du kommer att se detta:
Nu, jag erkänner, gjorde jag ett antagande om vad "... kräver uppdatering baserat på rowmodctr-informationen i sys.sysindexes katalogvy..." betydde. Jag antog att uppdateringsbeslutet skulle följa samma logik som alternativet Auto Update Statistics följer, vilket är:
- Tabellstorleken har gått från 0 till>0 rader (test 1).
- Antalet rader i tabellen när statistiken samlades in var 500 eller mindre, och kolmodctr för den inledande kolumnen i statistikobjektet har ändrats med mer än 500 sedan dess (test 2).
- Tabellen hade mer än 500 rader när statistiken samlades in, och kolmodctr för den inledande kolumnen i statistikobjektet har ändrats med mer än 500 + 20 % av antalet rader i tabellen när statistiken samlades in ( test 3).
Denna logik följs inte för sp_updatestats . Faktum är att logiken är så otroligt enkel att den är skrämmande:Om en rad ändras uppdateras statistiken. En rad. EN RAD. Vad är min oro? Jag är orolig över kostnaden för att uppdatera statistik för en massa statistik som inte verkligen behöver uppdateras. Låt oss ta en närmare titt på sp_updatestats .
Vi börjar med en ny kopia av databasen AdventureWorks2012 som du kan ladda ner från Codeplex. Jag ska först uppdatera rader i tre olika tabeller:
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
Vi har ändrat en rad i Production.Product , 211 rader i Person.Person , och vi lade till 10 000 rader till Sales.SalesReason . Om sp_updatestats proceduren följde samma logik för uppdateringar som alternativet Automatisk uppdatering av statistik, sedan endast Sales.SalesReason skulle uppdatera eftersom det hade 10 rader att starta (medan de 211 raderna uppdaterades i Person.Person representerar ungefär en procent av tabellen). Men om vi gräver i sp_updatestats , kan vi se att logiken som används är annorlunda. Observera att jag bara extraherar påståendena från sp_updatestats som används för att avgöra vilken statistik som uppdateras.
En markör itererar genom alla användardefinierade tabeller och interna tabeller i databasen:
declare ms_crs_tnames cursor local fast_forward read_only for select name, object_id, schema_id, type from sys.objects o where o.type = 'U' or o.type = 'IT' open ms_crs_tnames fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
En annan markör går igenom statistiken för varje tabell och exkluderar högar och hypotetiska index och statistik. Observera att sys.sysindexes används i sp_helpstats . Sysindexes är en SQL Server 2000-systemtabell och är planerad att tas bort i en framtida version av SQL Server. Detta är intressant, eftersom den andra metoden för att fastställa rader uppdaterade är sys.dm_db_stats_properties DMF, som endast är tillgänglig i SQL 2008 R2 SP2 och SQL 2012 SP1.
set @index_names = cursor local fast_forward read_only for select name, indid, rowmodctr from sys.sysindexes where id = @table_id and indid > 0 and indexproperty(id, name, 'ishypothetical') = 0 order by indid
Efter lite förberedelser och ytterligare logik kommer vi till en IF uttalande som avslöjar att sp_updatestats filtrerar bort statistik som inte har uppdaterat några rader... bekräftar att även om bara en rad har ändrats kommer statistiken att uppdateras. Det finns också en bock för @is_ver_current , som bestäms av en inbyggd, intern funktion.
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
Ett par kontroller till relaterade till provtagning och kompatibilitetsnivå, och sedan UPDATE uttalandet körs för statistiken. Innan vi faktiskt kör sp_updatestats kan vi fråga sys.sysindexes för att se vilken statistik som kommer att uppdateras:
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type] FROM [sys].[objects] [o] JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id] WHERE ([o].[type] = 'U' OR [o].[type] = 'IT') AND [si].[indid] > 0 AND [si].[rowmodctr] <> 0 ORDER BY [o].[type] DESC, [o].[name];
Utöver de tre tabellerna som vi modifierade, finns det ytterligare en statistik för en användartabell (dbo.DatabaseLog ) och tre interna statistik som kommer att uppdateras:
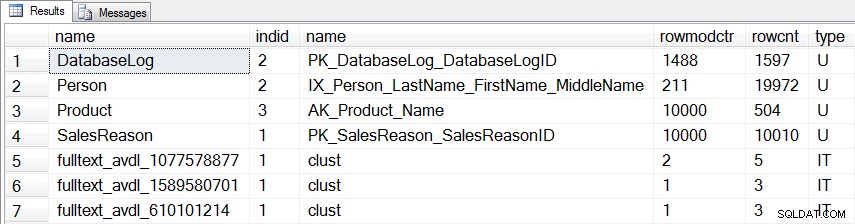
Statistik som kommer att uppdateras
Om vi kör sp_updatestats för AdventureWorks-databasen listar utdata varje tabell och uppdaterad(a) statistik(er). Utdata nedan är modifierad för att endast visa uppdaterad statistik:
Uppdaterar [sys].[fulltext_avdl_1589580701]
[klust] har uppdaterats...
1 index(er)/statistik(er) har uppdaterats, 0 krävde ingen uppdatering.
…
Uppdaterar [dbo].[DatabaseLog]
[PK_DatabaseLog_DatabaseLogID] har uppdaterats...
1 index(er)/statistik(er) har uppdaterats, 0 krävde ingen uppdatering.
…
Uppdaterar [sys].[fulltext_avdl_1077578877]
[klust] har uppdaterats...
1 index/statistik(er) har uppdaterats, 0 krävde ingen uppdatering.
…
Uppdaterar [Person].[Person]
[PK_Person_BusinessEntityID], uppdatering är inte nödvändig...
[IX_Person_LastName_FirstName_MiddleName] har uppdaterats...
[AK_Person_rowguid], uppdatering är inte nödvändig...
1 index(er)/statistik(er) har uppdaterats, 2 behövde inte uppdateras.
…
Uppdaterar [Sales].[SalesReason]
[PK_SalesReason_SalesReasonID] har uppdaterats...
1 index(er)/statistik(er) har uppdaterats, 0 krävde ingen uppdatering.
…
Uppdaterar [Produktion].[Produkt]
[PK_Product_ProductID], uppdatering är inte nödvändig...
[AK_Product_ProductNumber], uppdatering är inte nödvändig...
[AK_Product_Name] har uppdaterats...
[ AK_Product_rowguid], uppdatering är inte nödvändig...
[_WA_Sys_00000013_75A278F5], uppdatering är inte nödvändig...
[_WA_Sys_00000014_75A278F5], uppdatering är inte nödvändig...
[_WA_050_0008]>[_WA_Sys_0000000C_75A278F5], uppdatering är inte nödvändig...
1 index/statistik(er) har uppdaterats, 7 krävde ingen uppdatering.
…
Statistik för alla tabeller har uppdaterats.
Den sista raden i utgången är lite missvisande – statistiken för alla tabeller har inte uppdaterats, bara statistiken som har en rad eller flera modifierad har uppdaterats. Och återigen, nackdelen med det är att det kanske användes resurser som inte behövde användas. Om en statistik bara har en rad modifierad, bör den uppdateras? Nej. Om den har uppdaterat 10 000 rader, bör den uppdateras? Tja, det beror på. Om tabellen bara har 5 000 rader, då absolut; om tabellen har 1 miljon rader, då nej, eftersom endast en procent av tabellen har ändrats.
Uttaget här är att om du använder sp_updatestats för att uppdatera din statistik slösar du med största sannolikhet resurser, inklusive CPU, I/O och tempdb. Vidare tar det tid att uppdatera varje statistik, och om du har ett snävt underhållsfönster har du förmodligen andra underhållsuppgifter som kan utföras under den tiden, istället för onödiga uppdateringar. Slutligen ger du förmodligen inga prestandafördelar genom att uppdatera statistik när så få rader har ändrats. Fördelningsförändringen är sannolikt obetydlig om bara en liten andel av raderna har modifierats, så histogrammet och densitetsvärdena kommer inte att ändras så mycket. Kom dessutom ihåg att uppdatering av statistik ogiltigförklarar frågeplaner som använder denna statistik. När dessa frågor körs, genereras planer på nytt, och planen kommer förmodligen att vara exakt densamma som den var tidigare, eftersom det inte fanns någon signifikant förändring i histogrammet. Det kostar att omkompilera frågeplaner – det är inte alltid lätt att mäta, men det bör inte ignoreras.
En bättre metod för att hantera statistik – eftersom du behöver hantera statistik – är att implementera ett schemalagt jobb som uppdateras baserat på procentandelen rader som har ändrats. Du kan använda den tidigare nämnda frågan som frågar sys.sysindexes , eller så kan du använda frågan nedan som drar fördel av den nya DMF som lagts till i SQL Server 2008 R2 SP2 och SQL Server 2012 SP1:
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] , [ss].[name] AS [Statistic], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications] FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp WHERE [so].[type] = 'U' AND [sp].[modification_counter] > 0 ORDER BY [sp].[last_updated] DESC;
Inse att olika tabeller kan ha olika trösklar och du måste justera frågan ovan för dina databaser. För vissa tabeller kan det vara ok att vänta tills 15 % eller 20 % av raderna har ändrats. Men för andra kan du behöva uppdatera med 10 % eller till och med 5 %, beroende på de faktiska värdena och deras skevhet. Det finns ingen silverkula. Så mycket som vi älskar absoluter, finns de sällan i SQL Server och statistik är inget undantag. Du vill fortfarande lämna Auto Update Statistics aktiverat – det är en säkerhet som kommer att slå in om du missar något, precis som Auto Growth för dina databasfiler. Men det bästa är att känna till dina data och implementera en metod som låter dig uppdatera statistik baserat på procentandelen rader som ändrats.