I mitt tidigare inlägg pratade jag om sätt att generera en sekvens av sammanhängande tal från 1 till 1 000. Nu skulle jag vilja prata om nästa skalnivå:generera uppsättningar med 50 000 och 1 000 000 nummer.
Genererar en uppsättning med 50 000 nummer
När jag startade den här serien var jag genuint nyfiken på hur de olika tillvägagångssätten skulle skalas till större uppsättningar av siffror. I den låga delen blev jag lite bestört när jag upptäckte att min favoritmetod – att använda sys.all_objects – var inte den mest effektiva metoden. Men hur skulle dessa olika tekniker skalas till 50 000 rader?
Siffertabell
Eftersom vi redan har skapat en Numbers-tabell med 1 000 000 rader förblir denna fråga praktiskt taget identisk:
VÄLJ TOP (50000) n FROM dbo.Number BESTÄLL EFTER n;
Planera:
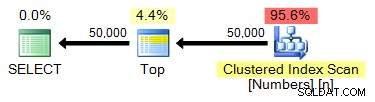
spt_values
Eftersom det bara finns ~2 500 rader i spt_values , vi måste vara lite mer kreativa om vi vill använda den som källan till vår setgenerator. Ett sätt att simulera en större tabell är att CROSS JOIN det mot sig själv. Om vi gjorde det råa skulle vi sluta med ~2 500 rader i kvadrat (över 6 miljoner). Vi behöver bara 50 000 rader, vi behöver cirka 224 rader i kvadrat. Så vi kan göra detta:
;MED x AS (VÄLJ TOP (224) nummer FRÅN [master]..spt_values)VÄLJ TOP (50000) n =ROW_NUMBER() ÖVER (ORDNING EFTER x.nummer) FRÅN x KORSA JOIN x SOM yORDNING AV n;
Observera att detta motsvarar, men mer kortfattat än, denna variant:
SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.number) FRÅN (SELECT TOP (224) nummer FRÅN [master]..spt_values) SOM xCROSS JOIN(SELECT TOP (224) nummer FRÅN [master] ]..spt_values) SOM ORDER BY n;
I båda fallen ser planen ut så här:
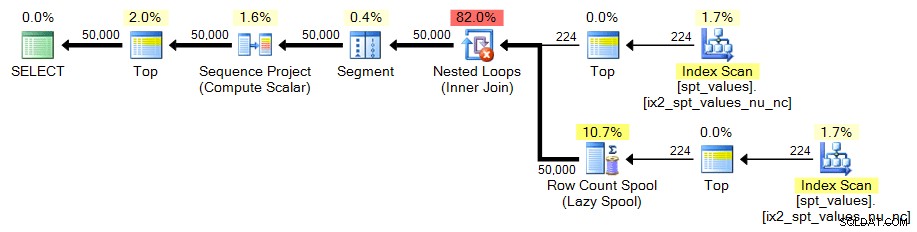
sys.all_objects
Som spt_values , sys.all_objects uppfyller inte riktigt vårt krav på 50 000 rader i sig, så vi måste utföra en liknande CROSS JOIN .
;;WITH x AS ( SELECT TOP (224) [object_id] FROM sys.all_objects)SELECT TOP (50000) n =ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x SOM y BESTÄLLNING AV n;
Planera:

Stackade CTE
Vi behöver bara göra en mindre justering av våra staplade CTE:er för att få exakt 50 000 rader:
;WITH e1(n) AS( VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1) , -- 10e2(n) AS (VÄLJ 1 FRÅN e1 CROSS JOIN e1 AS b), -- 10*10e3(n) AS (VÄLJ 1 FRÅN e2 CROSS JOIN e2 AS b), -- 100*100e4(n) AS (VÄLJ 1 FRÅN e3 CROSS JOIN (VÄLJ TOP 5 n FRÅN e1) SOM b) -- 5*10000 SELECT n =ROW_NUMBER() ÖVER (ORDNING EFTER n) FRÅN e4 ORDER BY n;
Planera:

Rekursiva CTE
En ännu mindre betydande förändring krävs för att få ut 50 000 rader från vår rekursiva CTE:ändra WHERE sats till 50 000 och ändra MAXRECURSION alternativet till noll.
;MED n(n) SOM( VÄLJ 1 UNION ALLA VÄLJ n+1 FRÅN n VAR n <50000)VÄLJ n FRÅN n ORDNING EFTER nOPTION (MAXRECURSION 0);
Planera:
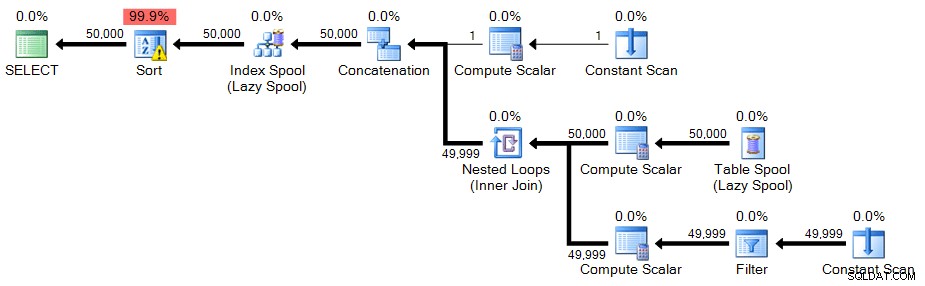
I det här fallet finns det en varningsikon på sorten - som det visar sig, på mitt system, den sort som behövs för att spilla till tempdb. Du kanske inte ser något spill på ditt system, men detta bör vara en varning om de resurser som krävs för denna teknik.
Prestanda
Som med den senaste uppsättningen tester kommer vi att jämföra varje teknik, inklusive Numbers-tabellen med både en kall och varm cache, och både komprimerad och okomprimerad:
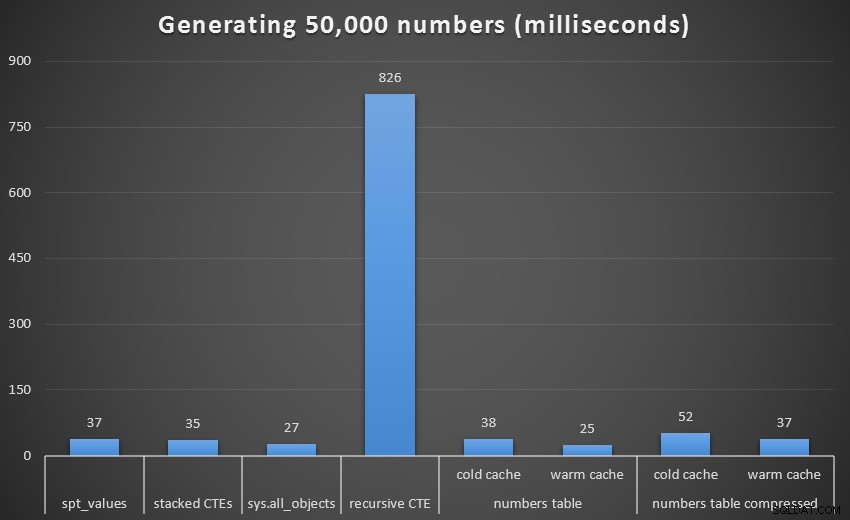
Körtid, i millisekunder, för att generera 50 000 sammanhängande tal
För att få en bättre visuell, låt oss ta bort den rekursiva CTE, som var en total hund i detta test och som snedvrider resultaten:
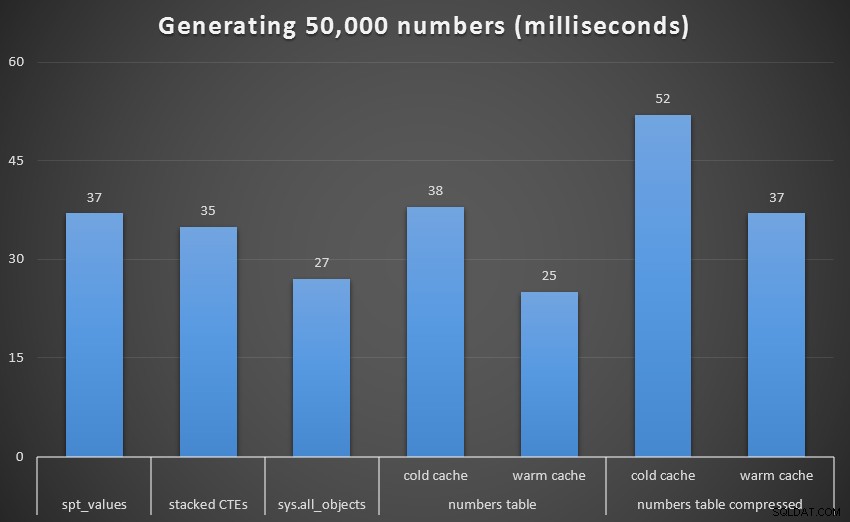
Körtid, i millisekunder, för att generera 50 000 sammanhängande tal (exklusive CTE)
Vid 1 000 rader var skillnaden mellan komprimerad och okomprimerad marginell, eftersom frågan bara behövde läsa 8 respektive 9 sidor. Vid 50 000 rader ökar klyftan en aning:74 sidor jämfört med 113. Den totala kostnaden för att dekomprimera data verkar dock uppväga besparingarna i I/O. Så vid 50 000 rader verkar en okomprimerad taltabell vara den mest effektiva metoden för att härleda en sammanhängande uppsättning – men visserligen är fördelen marginell.
Genererar en uppsättning med 1 000 000 nummer
Även om jag inte kan föreställa mig så många användningsfall där du skulle behöva en sammanhängande uppsättning siffror så här stora, ville jag inkludera den för fullständighetens skull och för att jag gjorde några intressanta observationer i denna skala.
Siffertabell
Inga överraskningar här, vår fråga är nu:
VÄLJ TOP 1000000 n FRÅN dbo.Number BESTÄLL AV n;
TOP är inte strikt nödvändigt, men det är bara för att vi vet att vår tabell med nummer och vår önskade utdata har samma antal rader. Planen är fortfarande ganska lik tidigare tester:
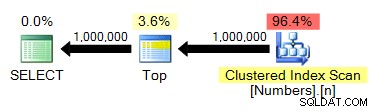
spt_values
För att få en CROSS JOIN som ger 1 000 000 rader måste vi ta 1 000 rader i kvadrat:
;WITH x AS ( VÄLJ TOP (1000) nummer FRÅN [master]..spt_values)SELECT n =ROW_NUMBER() OVER (ORDER BY x.number) FROM x CROSS JOIN x AS y ORDER BY n;
Plan:
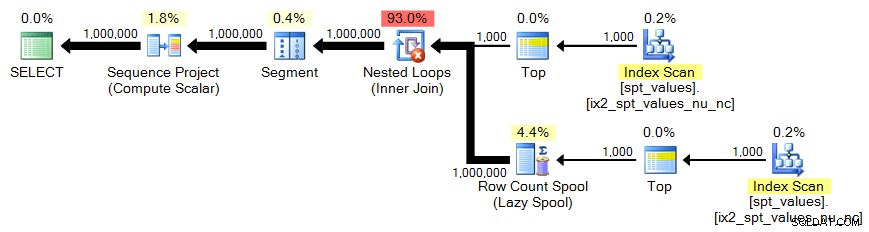
sys.all_objects
Återigen behöver vi korsprodukten av 1 000 rader:
;WITH x AS ( SELECT TOP (1000) [object_id] FROM sys.all_objects)SELECT n =ROW_NUMBER() OVER (ORDER BY x.[object_id]) FROM x CROSS JOIN x AS y ORDER BY n;Planera:
Stackade CTE
För den staplade CTE behöver vi bara en något annorlunda kombination av
CROSS JOINs för att komma till 1 000 000 rader:;WITH e1(n) AS( VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1 UNION ALLA VÄLJ 1) , -- 10e2(n) AS (VÄLJ 1 FRÅN e1 CROSS JOIN e1 AS b), -- 10*10e3(n) AS (VÄLJ 1 FRÅN e1 CROSS JOIN e2 AS b), -- 10*100e4(n) AS (VÄLJ 1 FRÅN e3 CROSS JOIN e3 AS b) -- 1000*1000 SELECT n =ROW_NUMBER() ÖVER (ORDNING EFTER n) FRÅN e4 ORDER BY n;Planera:
Vid denna radstorlek kan du se att den staplade CTE-lösningen går parallellt. Så jag körde också en version med
MAXDOP 1för att få en liknande planform som tidigare, och för att se om parallellism verkligen hjälper:
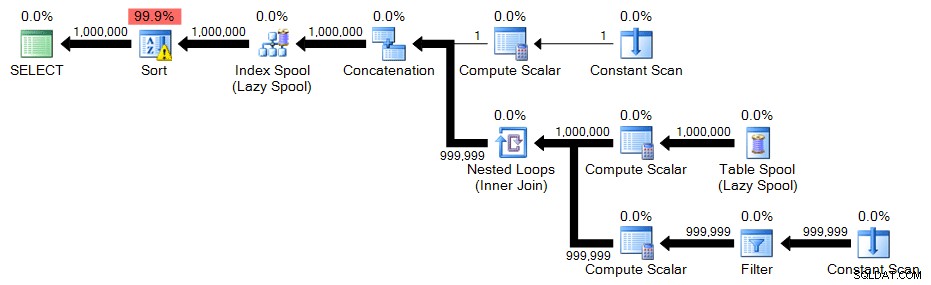
Rekursiv CTE
Den rekursiva CTE har återigen bara en mindre förändring; endast
WHEREklausul måste ändras:;MED n(n) AS( VÄLJ 1 UNION ALLA VÄLJ n+1 FRÅN n DÄR n <1000000)VÄLJ n FRÅN n ORDNING EFTER nOPTION (MAXREKURSION 0);Planera:
Prestanda
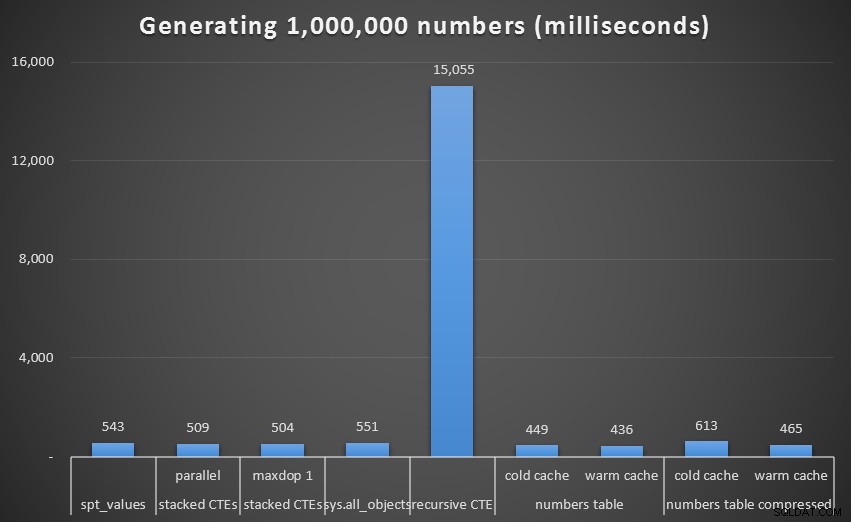
Återigen ser vi att prestandan för den rekursiva CTE är urusel:
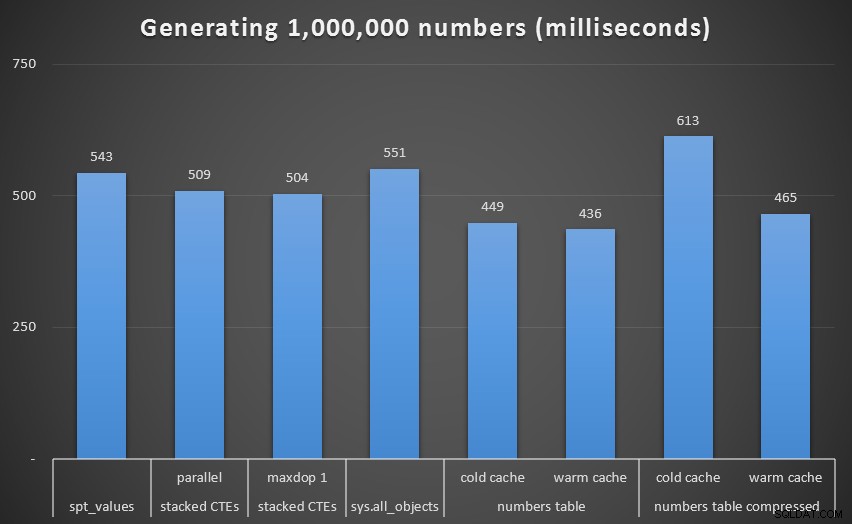
Körtid, i millisekunder, för att generera 1 000 000 sammanhängande talOm vi tar bort denna extrema från grafen får vi en bättre bild av prestanda:
Körtid, i millisekunder, för att generera 1 000 000 sammanhängande återkommande siffror (exempelvis CTE)Även om vi återigen ser den okomprimerade Numbers-tabellen (åtminstone med en varm cache) som vinnare, är skillnaden inte ens på denna skala så anmärkningsvärd.
Fortsättning följer...
Nu när vi grundligt har undersökt en handfull metoder för att generera en sekvens av tal, går vi vidare till datum. I det sista inlägget i den här serien går vi igenom konstruktionen av ett datumintervall som en uppsättning, inklusive användningen av en kalendertabell, och några användningsfall där detta kan vara praktiskt.
[ Del 1 | Del 2 | Del 3 ]
Bilaga :Antal rader
Du kanske inte försöker generera ett exakt antal rader; du kanske istället bara vill ha ett enkelt sätt att generera många rader. Följande är en lista över kombinationer av katalogvyer som ger dig olika radantal om du bara
SELECTutan enWHEREklausul. Observera att dessa siffror beror på om du är på en RTM eller ett service pack (eftersom vissa systemobjekt läggs till eller ändras), och även om du har en tom databas.



| Källa | Antal rader | ||
|---|---|---|---|
| SQL Server 2008 R2 | SQL Server 2012 | SQL Server 2014 | |
| master..spt_values | 2 508 | 2 515 | 2 519 |
| master..spt_values CROSS JOIN master..spt_values | 6 290 064 | 6 325 225 | 6 345 361 |
| sys.all_objects | 1 990 | 2 089 | 2 165 |
| sys.all_columns | 5 157 | 7 276 | 8 560 |
| sys.all_objects CROSS JOIN sys.all_objects | 3 960 100 | 4 363 921 | 4 687 225 |
| sys.all_objects CROSS JOIN sys.all_columns | 10 262 430 | 15 199 564 | 18 532 400 |
| sys.all_columns CROSS JOIN sys.all_columns | 26 594 649 | 52 940 176 | 73 273 600 |
Tabell 1:Antal rader för olika katalogvisningsfrågor